
反熔丝FPGA布线算法研究❋
2014-07-01 23:45杨大为
微处理机 2014年1期
杨大为
(中国电子科技集团公司第四十七研究所,沈阳110032)
反熔丝FPGA布线算法研究❋
杨大为
(中国电子科技集团公司第四十七研究所,沈阳110032)
国内外学术界对目前广泛采用的SRAM型FPGA布线算法均有大量研究,对于特殊用途反熔丝FPGA的研究却很少。首先介绍了反熔丝FPGA及其布线算法的研究现状,接着讨论了目前最为流行的FPGA布线算法——路径搜索算法的基本原理与实现方式,并且建立了反熔丝延时模型,然后针对反熔丝FPGA的结构对布线算法进行了改进,最后在CAD实验平台上实现了该改进算法。实验表明,该改进算法可以提高反熔丝FPGA布线的效率及电路速度。
反熔丝;路径搜索;布线算法;FPGA
1 引 言
FPGA(现场可编程门阵列)是与CPU和DSP并列的目前半导体市场上最重要的三类核心数字器件之一。自从上世纪80年代中期被发明出来以后,它对电子产业产生的影响越来越大。根据编程结构,FPGA可分为三种,分别是基于SRAM、FLASH和反熔丝(antifuse)的FPGA[1-4]。
SRAM型FPGA对单粒子效应敏感性限制了它在太空中的应用,特别是在太空中随着辐射量的增加和辐射时间的增加,SRAM失效的可能性大大提高,而反熔丝FPGA却能够正常工作。因此在航空航天宇航等恶劣环境应用中,反熔丝型FPGA具有不可替代的作用,成为空间领域使用的主流FPGA。
半导体工艺尺寸已经进入深亚微米领域,促使FPGA的逻辑容量大幅上升,使之能适合于实现更大规模的设计。为了充分利用这些深亚微米工艺技术,必须重新构建FPGA硬件结构和相应的CAD工具。以下三个要素决定了FPGA的性能:将电路映射到FPGA的CAD工具质量,FPGA硬件结构特性和FPGA电路设计水平。因此开发高效灵活的CAD软件,对于设计FPGA也是至关重要的。布局布线是FPGA芯片设计中最耗时的阶段,也对电路性能有着关键影响[1]。设计出更加快速、更小面积、延时少、低功耗的算法是学术界研究的热点和趋势。
反熔丝编程开关是无源器件(融通型)[2],占用的版图面积很小,所以反熔丝结构的FPGA有非常丰富的布线资源。同等芯片面积下,反熔丝FPGA的布线资源比SRAM FPGA多很多,其布线资源占芯片面积的大部分,因此布线相对耗时更多,对设计电路的速度影响也更大。目前主流的FPGA都是基于SRAM单元的,这是因为反熔丝FPGA的应用很特殊,并且反熔丝制造困难,需要特殊工艺,只有国外少数公司掌握了该技术。因此目前工业界和学术界流行的FPGA布线算法都是针对岛形和层次结构的SRAM-FPGA的。反熔丝FPGA通常采用的基于行[3]的逻辑架构(Row-based Architecture)研究较少,缺乏相关的文献和工具,必须进行充足的研究,才能确定设计方案。现有算法对于开发反熔丝FPGA布线算法有很好的指导意义,但是其对于FPGA的结构具有很强的针对性,并没有考虑到反熔丝FPGA的一些结构上的特点。只有在修改这些算法后才能应用在反熔丝FPGA的CAD软件上,如何提高反熔丝FPGA的布线速度和质量是本文研究的主要内容。
2 反熔丝FPGA布线算法
2.1 基本布线算法
常见的FPGA布线器可以分为两大类[1],其中一种是全局兼详细组合布线,这种布线方式一步就可以完成FPGA的布线。另一种方法是分为两步实现布线:第一步运行全局布线决定每条线网所使用的每个逻辑单元的引脚和可以使用的可分割线通道,第二步运行详细布线,根据第一步的结果,在允许使用的可分割通道中连接各个线网。因为FPGA布线的灵活性有限,并且全局布线限制了各线网所能使用的通道线段,所以FPGA详细布线器经常不能或者很困难地完成布线任务。因为全局兼详细布线器能够避免这种限制,所以它能更好的优化布线。
迷宫布线器用来连接各条线网的各个终点,而迷宫布线器其核心又是采用Dijkstra算法,即在布线资源图[4]中寻找连接线网源端和漏端的最短路径(最小成本)。在各种算法中,为了衡量布线结果的好坏而提出成本函数(Cost Function)[1]的概念,通常值越低表示布线结果越好,而对于不同的布线优先目标,成本函数也相应不同。
因为FPGA电路的速度很重要,所以我们主要研究有关时序驱动的布线算法。目前最流行的基本算法是拥挤度和延时兼顾的路径搜索算法[5](Path finder),它采用了一种使用连线关键度控制连线拥挤度和延时兼顾的折中方法。也就是,时序关键的线网使用延时最短的路径进行布线,即使这是一条拥挤路径,而时序不关键的线网将占有不拥挤的长路径。
路径搜索算法反复地拆线,重布电路中的各条线网,直到所有的拥挤度问题都得到解决。每次重布电路中的一条线网,就称为一次布线迭代。在第一次布线迭代中,每条连线均已最小延时为目标进行布线,即使会导致布线资源的拥挤或重用。重用的布线资源是无效的,一根线不可能被两个不同的线网使用。因此,一次布线迭代后存在重用,必须再执行一次,直到解决拥挤问题。每次布线迭代之后都要增加重用布线资源的成本,从而解决布线拥挤问题。每次布线迭代后,都可能得到完整的但是可能无效的布线结果。因此,能从这次布线中确定线网的延时,并且进行完整的时序分析以计算各源点和漏点间的延时裕量。在下一轮布线迭代中,这些裕量就可以用于控制减少连线延时或避免拥挤度的力度。
从线网的源端i到漏端j的连线关键度定义为

公式(1)中,Dmax是电路关键路径的延时,slack(i,j)是在不影响电路关键路径前提下的延时裕量。因此Crit(i,j)的值介于0和1之间。把布线资源节点n作为(i,j)的部分连接的成本是:
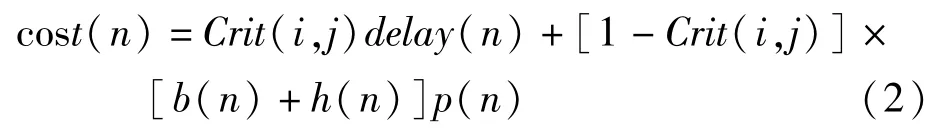
公式(2)中第一项是延时项,是这条连接的关键度乘以该节点的自身延时。第二项是拥挤度项。b(n)是节点n的基本成本。h(n)是节点n的历史拥挤度成本,每次节点n被重用,h(n)就会增加,布线器会保留“拥挤记录”。p(n)是节点n的当前拥挤度成本,如果在一次布线迭代中,该节点只被使用一次,p(n)就为1,它随着节点重用次数的增加而增加。p(n)也是已经运行的布线迭代次数的函数:在初始迭代中,p(n)随着当前节点n的重用缓慢增加,在末期迭代中,p(n)随着节点n的重用迅速增加[1]。
路径搜索器的优越性主要归功于两方面的创新,包括允许布线资源的重用,通过成本函数使得拥挤度逐步得到解决,并且直接优化时序。随着布线迭代次数的增加,位于关键路径上的连接占用最快路径,而非关键路径避免使用重用连接并逐步占用慢速路径。
直接搜索算法又称A*算法[6],是人工智能中一种典型的启发式搜索算法。启发式搜索就是在状态空间中的搜索对每一个搜索位置(节点)进行评估,得到认为最好的位置,再从这个位置进行搜索直到目标。这样可以省略大量无谓的搜索路径,提高了效率。在启发式搜索中,对位置的估价是十分重要的。采用不同的估价可以有不同的效果。
路径搜索算法的启发式搜索算法改进算法可以在不影响布线质量的前提下,快速提高运行布线速度。这是通过在节点成本中加入了对节点到目标漏端预期成本的方法实现的。具体将在时序驱动布线算法中详细介绍。
2.2 反熔丝FPGA延时模型
FPGA中线网延时包括逻辑块的内部延时和连接延时。在本延时模型中分别对这两种延时采用不同的计算方法:对于逻辑块内部,由于其路径的有限性,可以通过SPICE模拟仿真得到逻辑块内部所有路径的延时;连接线网延时是FPGA延时的主要部分。线网延时是指从线网的源端到该线网的终端之间的延时,其目的是决定布线后的电路速度、决定布线时的不同线网拓扑结构的延时。理想情况下,通过SPICE仿真可以得到精确的仿真值,但是布线线网数目有成千上万条,用SPICE仿真是不明智的,因此采用在布线中广泛应用的延时模型Elmore模型[7]。采用Elmore模型进行连线延时计算时,对FPGA布线资源中的传输晶体管,缓冲器及金属线进行RC电路的等效替换,以得到布线资源线网的RC树(RC Tree)。
反熔丝烧通后其电阻为一个线性电阻,为双向导通,且不会隔离下游电容,因此其Elmore延时模型可用传输管模型代替。如图1(a)为反熔丝等效电路,图1(b)为输出缓冲器等效电路,输出缓冲器具有本征延时和电阻,且会隔离下游电阻电容。图1(c)为布线等效电路。

图1 Elmore延时模型
通过对缓冲器反熔丝和线建立RC模型后,可以计算源端到漏端路径的Elmore延时是:
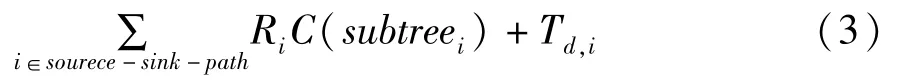
RC树的Elmore延时能够在线性时间内计算出来,即使Elmore延时有点不准确,它依然有较高的可信度,也就是它仍然能够对不同的布线拓扑结构电路进行正确排序。这个特征十分有用,它意味着基于Elmore延时的布线器能够通过不同拓扑结构的相对比较而做出正确的排序。
3 反熔丝FPGA布线算法的改进
3.1 成本函数的改进
由于在FPGA布线算法中,能够在FPGA布线资源上布通电路永远都处于优先考虑的位置,因此在FPGA时序驱动布线中,我们需要采用延时和拥挤度综合考虑算法。在算法中通过每种连接的拥挤度与延时折中度来控制节点的选取,而每种连接的拥挤度与延时折中度是由与其关键路径相比的危险程度(critical)来控制的,即关键路径的连接采用尽可能短的延时路径,即使这种情况会产生其他节点拥挤度问题,而对非关键路径的线网就用长一点却不会产生拥挤度问题的路径连接。
考虑时序的布线算法需要对节点Cost进行修改,使Cost中包含节点的时序信息,以便在布线搜索中优先考虑时延小的节点,修改后的代价函数表达式如公式(4)。

其中Cost(n)和基于布通率的代价函数表达式一样,包含节点的基本代价、上一次拥挤度、当前拥挤度;公式中Dmax为关键路径时延,slack(i,j)为第i条线网源与第j个终节点的松弛时间,MaxCrit表示该连接的时延与拥挤度折中系数。当公式(5)-(7)中的MaxCrit=1、η=1时,这种情况表示具有0松弛时间,即关键路径上的连接可以完全忽略拥挤的费用,而当MaxCrit=0时,算法完全忽略所有线网连接延时,而仅仅考虑拥挤度费用,算法就变成了基于布通率的布线算法。经验表明,MaxCrit=0.99比MaxCrit=l具有更好的布通率且不影响电路延时;而当MaxCrit=l时,有两条关键路径上的节点共享一个节点,将没办法解决布通率问题。
接下来还要定义一个路径成本的概念,路径费用表示已布线资源路径1到节点n的成本值总和,其表达式如公式(6):
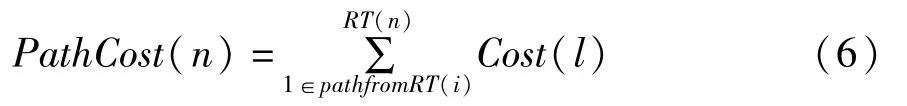
当每次找到线网的一个sink时,Crit(i,j)和delay(n)都会发生变化,因此当一个sink到达时对于优先队列中存储的每个PathCost值都将变得无效,因此不能采用基于布通率中提到的将已布线路径上节点作为下次扩展的源节点,即将所有路径上节点Cost设置为0的方法。因为在基于时序驱动的布线算法完成时,即每当一个sink到达时,优先队列被清空,而不能继续作为扩展的节点使用,算法需要重新计算每个节点Cost后再进行搜索,这样会导致搜索速度变慢。因此在时序驱动的布线算法中,我们采用直接搜索算法,在每一次节点扩展时对节点进行评估,减小没有必要的搜索。
为了在布线中使用直接搜索算法,需要预计出从当前节点到目标节点总共的估计费用值ExpectedCost(n),对于源节点和逻辑块输出节点定义其估计费用值为0,因为一条线网只有一个源节点、大多数情况下输出节点在MAZE扩展中不需要进行尝试搜索。为计算ExpectedCost(n),假定:①从当前节点n出发,连接目标节点J,使用与n具有相同类型的可分割线;②沿最短路径上的各个节点不存在拥挤度问题,即对于所有节点P(m),h(n)均等于1。由于当前布线节点(n)和目标节点(j)都在FPGA芯片资源表示的范围内,通过计算连接目标节点和当前布线节点中,所使用的与当前节点具有相同类型的可分割线的总数,根据该信息,我们可以计算出连接两节点所使用的所有开关,因此可以计算出目标节点的Elmore延时;作为目标估计费用,使用如下公式计算出节点n的总费用。

其中α表示采用直接搜索的程度,α=0即变成宽度优先搜索算法。RT(i):当前处理的线网net(i)中节点n的集合,同时储存了这些节点的延时信息。
由于烧通后的反熔丝电阻电容相对较大,反熔丝型FPGA的线网通路过的反熔丝不能过多,最好不超过三个反熔丝。虽然反熔丝FPGA所采用的行结构设计已经很大程度上避免了这个问题,但是实际随着电路规模的增加,线网长度增加还是很有可能出现这种情况的,因此需要修改布线算法,并加以约束。
在改进的反熔丝FPGA布线器中,布线迭代结束的判断标志不仅是布通与否,也应包括有没有线网通过超过四个反熔丝。由于布线算法是靠成本函数来控制布线资源节点的选择,从路径搜索算法得到的启发,因此修改也是基于对布线资源节点成本的动态修改来实现的。在原来的成本函数非时序成本上乘一个新的成本因子pass(n),这表明是线网通过反熔丝的个数影响成本。新的成本函数如公式(8)和公式(9)所示。
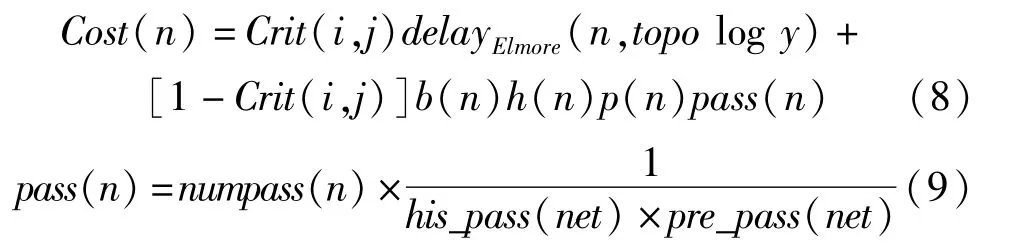
因为这是一个非延时成本,所以只在非延时项乘了pass(n),该成本函数会实时跟踪当前线网扩张时通过反熔丝的情况。在每次布线之后,布线器还会记录每个线网通过的反熔丝数目,下次布线时根据线网通过上次布线的反熔丝数目和历史记录线网通过反熔丝数目。公式4-13是pass(n)的表达式,numpass(n)是当前线网通过反熔丝的数目,his_ pass(net)是线网布线通过超过三次的次数,如果线网当前布线扩展通过的反熔丝数目越多则numpass(n)越大,这使得布线器选择通过反熔丝少的路径。若上次布线线网通过反熔丝的数目越多则pre_pass(net)越大,pass(n)越小,这样使得通过反熔丝多的线网使用节点的成本变小。随着布线迭代,线网反熔丝通过数目超过三个的次数的增加,his_pass(net)会逐渐增加,pass(n)逐渐减小。这样让布线器逐步选择通过反熔丝较多的路径逐渐占用通过反熔丝少的路径,即使该路径很拥挤,以期减少反熔丝的通过量。
通过监控线网路径通过的反熔丝数目,每次布线迭代时布线器总是寻找通过反熔丝少的路径。这样在布线迭代中,布线器会减少盲目的布线扩展,因为通过反熔丝太多的线网是不会被采用的。这在很多情况下会大大提高软件的布线速度,因为布线扩展是非常耗时的,尤其当FPGA规模很大的时候。
3.2 线网布线顺序的改进
根据布线算法的普遍研究和实验[1],线网布线顺序对布线结果的影响很大。这是因为布线资源节点存在一个重用成本的问题,布线资源节点被线网使用后,成本就会变高。因此将通过反熔丝数目多的线网先布线,会减少通过的反熔丝数目。因此程序必须在每次布线迭代之后都要记录下每条线网通过的反熔丝数目,并在下一次布线时对线网进行排序。同样对于存在多扇出的线网,扇出的线网布线顺序不同对布线结果也是有影响的,因此改进的布线算法也记录下了线网的不同扇出所经过的反熔丝。在对每条线网布线时,布线器根据不同扇出所经过的反熔丝数目,对其进行排序,将经过反熔丝数目多的扇出进行优先布线,这也大大减少了线网经过的反熔丝数。
3.3 实验结果
为了验证改进算法的可行性,本文提出了一个4×8的行结构反熔丝FPGA,借助反熔丝FPGA CAD平台进行布线实验。图2是全加器电路在实验FPGA布线完成后的图形显示,通过图形显示可以很清楚的看到关键路径可以方便电路设计者修改电路提高速度。四组对比实验结果表明,修改后的算法布线速度平均提高20%,电路速度平均提高了15%(见表1)。

图2 全加器布线结果

表1 四组测试电路布线结果
4 结束语
首先介绍了学术界流行的FPGA布线算法,包括其主要思想和实现方式,还阐述了成本函数的选择和关键路径的分析。为了进行时序驱动布线,又对布线结果进行时序分析,提出了反熔丝FPGA的时序模型。根据反熔丝FPGA的特点,对传统布线算法的成本函数和布线速度进行了修改,以促进布线器尽量减少线网中的反熔丝数目并提高布线速度。最后,在反熔丝FPGA CAD实验平台实现了改进布线算法,成功对四组实验电路进行了布线。实验结果表明这些改进可以大幅提高布线的效率和电路速度。本文所提出的改进还需要更多的理论和实验研究来验证,特别是需要提高实验FPGA的规模以对更多典型电路进行测试。
[1]Vaughn B,Jonathan R,Alexander M.Architecture and CAD for deep-submicron FPGAs[M].US,springer,1999:10-50.
[2]Jonathon G,Esmat H,Sam B.Antifuse field programmable gate arrays[J].Proceedings of the IEEE,1993.
[3]Actel Corporation,Introduction to ACTEL FPGA architecture[J].Application Note AC165,1997.
[4]Carl E,Larry MM,Scott H.Placement and routing tools for the Triptych FPGA[J].IEEE Transactions on VLSI Systems,Department of Computer Science and Engineering,University ofWashington,Seattle,1995.
[5]Larry MM,Carl E.PathFinder:A Negotiation-Based Performance-Driven Router for FPGAs[C].Third International ACM Symposium on Field-Programmable Gate Arrays(FPGA'95),Monterey,California,USA,1995.
[6]Russell T.Negotiated A*routing for FPGAs*[J].The Fifth Canadian Workshop on Field-Programmable Devices,MIT Laboratory for Computer Science Cambridge,1998.
[7]Wang Y,Wang L,Han R.A delay model for SRAMBased FPGA interconnections[J].49th IEEE International Midwest Symposium on,2006.
Research on the Routing Algorithm of Antifuse FPGA
YANG Da-wei
(The 47th Research Institute of China Electronics Technology Group Corporation,Shenyang 110032,China)
Routing algorithm based on SRAM FPGA is very popular in the academia,however the special antifuse FPGA is rarely discussed.This paper presents the current status of the development of antifuse FPGA and its routing algorithm.Then fundamental principles and implementationmethods of the most popular Pathfinder routing algorithm are discussed,and the antifuse FPGA delay models are also introduced.Afterward two improvements of the algorithm targeting antifuse FPGA are described,and the modified algorithm is realized in the antifuse CAD platform.The result of several experiments shows that themodified algorithm can optimize routing efficiency and circuit speed implemented on antifuse FPGA.
Antifuse;Path finder;Routing algorithm;FPGA
10.3969/j.issn.1002-2279.2014.01.013
TN4
:A
:1002-2279(2014)01-0046-05
总装“核高基”重大专项:高可靠反熔丝FPGA设计技术研究
杨大为(1977-),男(回族),山东省济阳县人,高级工程师,主研方向:集成电路设计。
2013-08-26
猜你喜欢
图学学报(2022年2期)2022-05-09
家庭影院技术(2020年2期)2020-03-25
汽车维护与修理(2019年9期)2019-11-08
铁道通信信号(2019年5期)2019-10-10
铁道通信信号(2019年12期)2019-05-21
铁道通信信号(2019年2期)2019-03-26
通信电源技术(2018年3期)2018-06-26
电子工业专用设备(2016年9期)2016-10-18
汽车维护与修理(2014年10期)2014-02-28
智能建筑与智慧城市(2012年12期)2012-08-15
