
局部保持的稀疏表示字典学习*
2014-08-16 07:59陈思宝赵令罗斌
华南理工大学学报(自然科学版) 2014年1期
陈思宝 赵令 罗斌
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601;2.安徽省工业图像处理与分析重点实验室,安徽 合肥 230039)
稀疏编码[1]理论和算法已成功应用于图像恢复[2]和压缩传感[3]领域.近年来,稀疏表示技术在图像分类方面(如人脸识别(FR)[4]、数字和纹理分类[5]等)也取得了不错的效果.在稀疏表示分类中,利用最小化l0或l1范式,一个高维图像测试样本可以被其同一类的少量具有代表性的训练图像样本线性地表示或编码,进而进行分类和识别.
稀疏表示可以预先定义字典,如Wright 等[4]所提出的稀疏表示分类(SRC),使用所有类的训练样本作为一个字典,并通过最小重构误差来实现待查询人脸图像的分类.最初训练样本的不确定性以及噪声方面的因素,使很多情况下的最初训练样本并不能有效地表示所要查询的图像.即使是使用最初的训练样本作为所要学习的字典,也不能充分地利用隐含在训练样本中的判别信息.此外,现有的基础分析设计字典(如Huang 等[5]将Haar 小波和Gabor小波用作字典)并不适用于特定类型的图像(如人脸、数字和纹理图像).如果将所有的训练样本均作为字典且训练样本非常多,那么会增大编码的复杂度.因此,需要根据训练样本学习出一个较小的且更加适合分类的字典.
字典学习(DL)是指在训练样本中学习一个字典以更好地表示原始的训练样本,从而便于后期的压缩编码和分类识别.近年来,出现了许多针对图像处理[2]和分类[5]的DL 方法.Yang 等[6]提出了基于Fisher 判别准则的稀疏表示字典学习(FDDL)方法.该方法利用不同类别训练样本之间的判别信息,使学习出的字典中不同类别的字典原子具有最小的类内离散度和最大的类间离散度,从而让字典具有更强的判别能力.
然而,字典是为了用较少的原子更好地表示原始训练样本,其原始训练样本的局部数据结构至关重要.增加Fisher 判别约束并不能得出保持局部信息的字典.保局投影(LPP)[7]是流形数据线性化降维的经典方法,LPP 不仅能保持原始数据的局部结构,而且能使变换后的数据更加具有判别信息,其局部保持的准则被证明是Fisher 判别准则的某种推广形式.为使所学习的字典更加保持原始训练样本的局部信息,文中借助LPP 的局部保持特性,在稀疏表示的字典学习中增加局部保持的约束,提出了一种基于局部保持准则的稀疏表示字典学习(LPDL)方法,并通过实验验证了所提LPDL 方法的有效性.
1 稀疏表示分类简介
SRC 最早由Wright 等[4]提出并应用于鲁棒性人脸识别.假定有c 个类别的训练集A=(A1,A2,…,Ac),Ai是第i 类的训练样本子集,x 是测试样本,则SRC 寻求x 基于训练样本的稀疏线性重构,并根据各类的重构误差最小进行分类,其过程如下:
(1)利用l1范式最小化稀疏编码x,即

式中,调节参数γ>0 .
(2)分类

2 LPDL 的目标函数
在训练样本比较多时,SRC 求解稀疏系数非常耗时.因此,出现了很多字典学习的方法(如KSVD[8])来为稀疏表示学习原子数较少但又能充分表示原始训练样本集的字典.
为提高现有字典学习的性能,且希望学习出的字典保持局部信息,文中提出了基于局部保持准则的稀疏表示字典学习方法.设稀疏表示字典D=[D1D2… Dc],Di是对应于第i 类的子字典,训练样本集为A,Y 为训练样本A 在字典D 上的编码系数矩阵,Y= [Y1Y2… Yc],即A ≈DY,Yi是Ai在D 上的编码系数子矩阵.希望D 不仅具有A 的有效重构能力,而且具有保持A 中样本的局部信息能力.因此,文中提出如下的LPDL 模型:
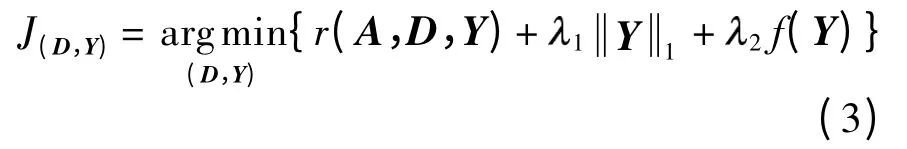
2.1 判别保真项
由前面定义可知,Yi是Ai在D 上的表示,记为,其中是Ai在子字典Dj上的编码系数.设Ai在子字典Dj上的表示为Rj=Dj.首先,Ai可以由D 表示,即
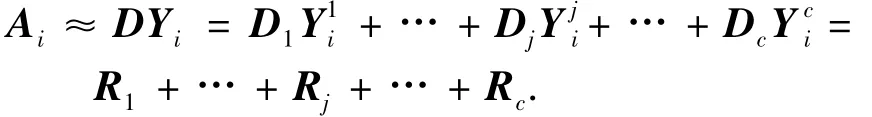
其次,因为Di是对应于第i 类的子字典,所以希望Ai能更好地由Di表示,而不是由Dj(j ≠i)表示.也就是说,希望系数接近于0,即足够小.而所有有效的系数均在中,故也足够小.因此,文中定义最小判别保真项:

2.2 局部保持约束项

Nk(xi)为xi的k 近邻集合.为使经过编码后的系数yi保持原数据点xi的局部信息,文中采用如下最小的目标函数:

即如果xi和xj在原始空间中的距离较近,那么希望编码后的系数yi与yj的距离也很近。
记L= S -W,为边权矩阵W 的拉普拉斯矩阵,对角矩阵,则
定义字典学习中的局部保持约束项f(Y)为tr(YLYT),则f(Y)是非负定的.为了使f(Y)是正定的且更加平滑,文中在f(Y)中加入一个平滑项,则f(Y)可表示为

式中,Y= [y1y2… yn],调节参数η>0 .此f(Y)是一个凸函数.
2.3 LPDL 模型
将式(4)和(5)代入式(3)中,可得到如下LPDL目标函数:
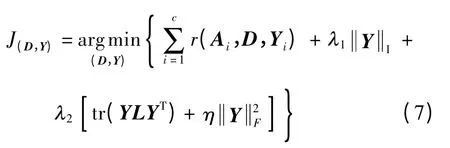
尽管式(7)中的目标函数J 相对于(D,Y)并不总是凸的,但当其他的项均被固定时,就D 和Y 中的每一个元素来说,它是凸的.因此,可以交替地迭代优化字典D 和稀疏系数矩阵Y,即将LPDL 目标函数(式(7))划分为两个子问题:固定D 来更新Y和固定Y 来更新D.
3 LPDL 的优化求解
文中采用如下方法来交替迭代优化求解字典D和稀疏系数矩阵Y.
首先,固定字典D 求解系数矩阵Y .可通过将式(7)中的目标函数J(D,Y)简化为一个稀疏编码问题来求解Y=[Y1Y2… Yc].文中通过类与类之间的关系来计算Yi.当计算Yi时,所有的Yj(j ≠i)均固定,因此式(7)的目标函数可进一步简化为

其次,固定系数Y 求解字典D.即通过类与类之间的关系来更新Di.当更新Di时,所有的Dj(j ≠i)均固定.因此,式(7)的目标函数可简化为
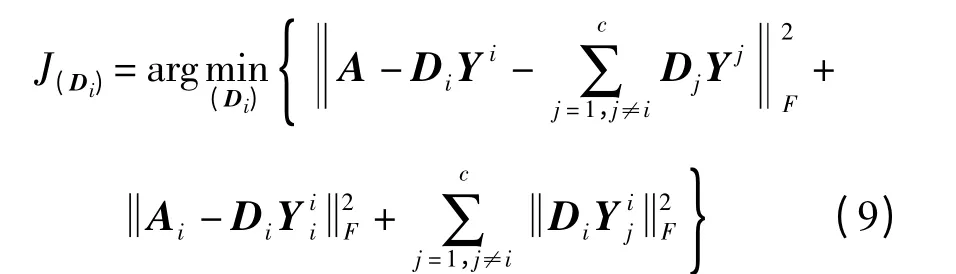
其中,Yi是A 在Di上的编码系数.
一般来说,要求字典Di的每一列dli 都是一个单位向量,即.式(9)是一个二次规划问题,可通过MLSRC[10]中的算法来求解,即通过原子与原子之间的关系来更新字典Di.
整个LPDL 优化迭代算法步骤如下:
(1)初始化字典D,以随机向量初始化字典Di中的每一个原子;
(2)更新稀疏系数矩阵Y=[Y1Y2… Yc],即固定字典D,利用IPM[9]方法最小化式(8)来求解Yi(i= 1,2,…,c);
(3)更新字典D,即固定稀疏系数矩阵Y,使用MLSRC[10]中的算法来更新字典Di(i=1,2,…,c);
(4)若相邻迭代中的J(D,Y)之间的误差小于阈值s,或者已经达到了最大迭代次数T,则算法停止,否则,转步骤(2).
4 实验结果与分析
4.1 参数的选择
LPDL 方法最重要的一个参数是字典Di中的原子数pi.为简化实验,文中将所有类别的原子数pi(i= 1,2,…,c)均设为相等,并以SRC 为基准方法,分析LPDL 方法在取不同原子数pi时的分类性能.以在COIL20 数据库[11]上实现的图像分类为例,其中SRC 使用最初的训练样本作为字典,在每一类训练样本中随机选择pi个作为字典原子,并进行10 次实验得到平均识别率Ri,LPDL、FDDL[6]、SRC[4]方法取不同字典原子数时的识别率如图1 所示.从图中可以看出,LPDL 方法的识别率较FDDL 方法提升了约3%,较SRC 提升了约6%,尤其是当字典原子数pi=8 时,LPDL 方法较FDDL 和SRC 方法有更高的识别率;LPDL方法的识别率波动程度小于FDDL 和SRC 方法.这表明LPDL 方法能够计算出一个紧凑的且具有代表性的字典,从而使LPDL 方法的运算量较FDDL和SRC 方法少,识别率更高.

图1 LPDL 和FDDL、SRC 方法在不同原子数下的识别率Fig.1 Recognition accuracy of LPDL,FDDL and SRC methods with different numbers of dictionary atoms
文中采用扩展YaleB[12]、AR[13]和COIL20[11]数据库进行实验,以验证所提出的LPDL 方法的性能.如果没有特别说明,LPDL 方法的调节参数和所比较方法的参数均是通过5 倍交叉实验得到的,从而有效地避免了过度学习.LPDL 方法的参数设置如下:①在扩展YaleB[12]人脸库上,1= 0.005,2= 0.050,γ= 0.005,η=0.500;②在AR[13]人脸库上,1=0.005,2=0.050,γ=0.005,η=0.500;③在COIL20[11]图像库上,1=2=0.005,γ=0.001,η=0.050.
4.2 图像分类
4.2.1 扩展YaleB 数据库
该数据库包含了不同光照条件下38 人的2 414幅正面图像.所有的人脸图像经过手工剪裁并被缩放到32 ×32 大小.文中根据文献[12]方法,将该数据库划分成5 个子集:子集1 包含了自然光照条件下的266 幅图像(每人7 幅),子集2 和3 分别包含了中等、轻度光照条件下每人的12 幅图像,子集4(每人14 幅)和5(每人19 幅)则分别包含了在严重光照和较严重光照条件下的图像,如图2 所示.
图2 扩展YaleB 数据库的子集划分图例Fig.2 Samples of subsets divided from extended YaleB database
采用子集1 作为训练集,其他子集作为测试集.LPDL、FDDL[6]、SRC[4]、PCA[14]、ICA-I[15]方法的分类结果如表1 所示.可以看出:在中等亮度光照条件下,LPDL、FDDL 和SRC 方法的识别率达到了100%,优于PCA 和ICA-I 方法约2.00%;在轻度光照条件下,LPDL 和FDDL 方法的识别率均为89.43%,优于SRC 方法约0.22%,优于PCA 和ICA-I 方法约9.40%;在严重的光照条件下,LPDL方法的识别率较FDDL、SRC、PCA、ICA-I 方法分别提升了约0.20%、0.40%、72.00%、72.00%;在较严重的光照条件下,LPDL 方法的识别率较FDDL、SRC、PCA、ICA-I 方法分别提升了约0.30%、1.50%、2.60%、5.00%.

表1 各种方法在扩展YaleB 数据库上的识别率Table1 Recognition accuracy of various methods on extended YaleB database %
4.2.2 AR 数据库
AR 数据库包括126 人的4 000 幅正面人脸图像.其中,每人的26 幅图像均拍摄于两个不同的场景.参考文献[4]方法,选择子集1 作为训练集,该子集包括50 个男性和50 个女性拍摄于不同光照和不同表情变化条件下的7 幅图像;子集2 包括和子集1 相同背景条件下每人的7 幅图像,用作测试集.所有的人脸图像经过手工剪裁并被缩放到60×43 大小.
在该数据库上LPDL、FDDL[6]、SRC[4]、NN[16]和SVM[17]方法的分类识别率分别为93.85%、92.00%、88.80%、71.40%、87.10%,LPDL 方法的识别率较FDDL、SRC、NN、SVM 方法分别提升了约1.85%、5.00%、22.40%、6.70%,即LPDL 方法 是最优的,FDDL方法稍次于LPDL 方法.
4.2.3 COIL20 数据库
COIL20 图像库包含20 个物体的1440 幅图像,每个物体旋转一周,每隔5°采集一幅图像,共有72幅图像.图3 是COIL20 图像库中的部分样本.

图3 COIL20 图像库中的部分样本图Fig.3 Some sample images in COIL20 database
所有的物体图像经手工剪裁并被缩放到32 ×32 大小,即用一个1024维的向量表示.文中仅选取每个物体的前10 幅图像作为训练集,其余图像作为测试集.LPDL 和FDDL 方法的分类识别率分别为59.68% 和59.44%,LPDL 方法的识别率略优于FDDL方法.
5 结论
文中提出了一种基于局部保持准则的稀疏表示字典学习(LPDL)方法.LPDL 方法旨在学习一个结构化的字典,其子字典不仅有详细的类标签,而且保持了原始训练数据的局部信息.从实验结果可以看出,LPDL 方法的判别能力是双重的:每个特定类的子字典对相关类的训练样本均有很好的表示能力,而对不相关类则有差的表示能力;LPDL 方法将局部保持准则附加在编码系数上,使得相近数据点的编码系数也保持近邻关系,从而保持数据矩阵的局部信息.在扩展YaleB、AR 和COIL20 数据库上的实验结果表明,LPDL 方法的分类识别结果优于其他方法.随着核技巧在稀疏表示中的应用,今后将致力于研究核化的稀疏表示字典学习。
[1]Olshausen B A.Emergence of simple-cell receptive field properties by learning a sparse code for natural images[J].Nature,1996,381(6583):607-609.
[2]Elad M,Aharon M.Image denoising via sparse and redundant representations over learned dictionaries[J].IEEE Transactions on Image Processing,2006,15(12):3736-3745.
[3]Candès E J.Compressive sampling[C]∥Proceedings of the International Congress of Mathematicians.Madrid:European Mathematical Society,2006:1433-1452.
[4]Wright J,Yang A Y,Ganesh A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[5]Huang K,Aviyente S.Sparse representation for signal classification[M]∥Advances in Neural Information Processing Systems 19.Cambridge:MIT Press,2007:609-616.
[6]Yang M,Zhang L,Feng X,et al.Fisher discrimination dictionary learning for sparse representation [C]∥Proceedings of 2011 IEEE International Conference on Computer Vision.Barcelona:IEEE,2011:543-550.
[7]He Xiaofei,Niyogi Partha.Locality preserving projections[M]∥Advances in Neural Information Processing Systems 16.Cambridge:MIT Press,2003:152-160.
[8]Zhang Q,Li B.Discriminative K-SVD for dictionary learning in face recognition[C]∥Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition.San Francisco:IEEE,2010:2691-2698.
[9]Rosasco L,Verri A,Santoro M,et al.Iterative projection methods for structured sparsity regularization [R/OL].(2009-10-14).http:∥hdl.handle.net/1721.1/49428.
[10]Yang M,Zhang L,Yang J,et al.Metaface learning for sparse representation based face recognition[C]∥Proceedings of the 17th IEEE International Conference on Image Processing.Hong Kong:IEEE,2010:1601-1604.
[11]Nene S A,Nayar S K,Murase H.Columbia object image library (coil-20)[R/OL].(1996-01-01)[2013-05-20].http:∥www.cs.columbia.edu/CAVE/software/softlib/coil-20.php.
[12]Naseem I,Togneri R,Bennamoun M.Linear regression for face recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(11):2106-2112.
[13]Martinez A,Benavente R.The AR face database[R].Columbus:the Ohio State University,1998.
[14]Jolliffe I T.Principal component analysis [M].New York:Springer-Verlag,1986.
[15]Comon P.Independent component analysis,a new concept?[J].Signal Processing,1994,36(3):287-314.
[16]Beyer K S,Goldstein J,Ramakrishnan R,et al.When is“nearest neighbor”meaningful?[C]∥Proceedings of the 7th International Conference on Database Theory.London:Springer-Verlag,1999:217-235.
[17]Cortes C,Vapnik V.Support vector machine[J].Machine Learning,1995,20(3):273-297.
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
计算机工程(2020年3期)2020-03-19
南京大学学报(数学半年刊)(2020年1期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
