
机会网络中高效的数据分发机制
——CRLNC
2014-09-17 10:26乔晋龙刘亚翃谭春花
电视技术 2014年1期
乔晋龙,高 媛,刘亚翃,谭春花
(中北大学电子与计算机科学技术学院,山西太原 030051)
机会网络中高效的数据分发机制
——CRLNC
乔晋龙,高 媛,刘亚翃,谭春花
(中北大学电子与计算机科学技术学院,山西太原 030051)
针对如何提高机会网络中数据分发效率的问题,提出了一种数据分簇和随机线性网络编码结合的数据分发机制——CRLNC。其核心思想是先将数据分成几簇,然后在簇内分成相同数量的数据块,源节点发送一簇中的数据块,中间节点运用随机线性编码算法将其中的数据块编码转发出去,目标节点接收到其中的编码数据块后采用高斯—约旦消元法将数据渐进还原。在这种数据分发机制中,针对节点缓存空间的冗余问题提出一种基于簇号和线性相关性的节点缓存策略。理论分析和仿真结果证明,与传统的数据分发相比,该算法可以有效地提高网络吞吐量,减小端到端的时延。
机会网络;数据分发;随机线性网络编码;线性相关性
【本文献信息】乔晋龙,高媛,刘亚翃,等.机会网络中高效的数据分发机制——CRLNC[J].电视技术,2014,38(1).
机会网络是一种不需要源节点和目标节点间存在完整的通信链路,利用节点移动带来的相遇机会实现通信的自组织网络[1-2]。数据分发指源节点将数据通过某种机制转发到目标节点的过程,是机会网络研究的热点之一。由于其节点移动剧烈、网络链路频繁断裂等特点使基于存储转发的数据分发技术不能实现数据的理论传输容量,且具有高延迟、低数据率的特点,为了确保数据的可靠传输,研究一种适合机会网络的数据分发机制很有意义。
网络编码[3](Network Coding,NC)由R.Alshwede等首次提出,其原理为网络中节点对接收到的多个数据块进行编码,编码后的数据再由中间节点转发,其最直接的应用就是数据分发。
针对上述问题,本文提出一种基于分簇的随机线性网络编码(Clustering-Based Random Linear Network Coding,CRLNC)数据分发机制。目标节点在解码时运用高斯—约旦消元法,使接收编码数据块和解码同时进行来减小时延。数据块在网络中滞留的时间会很长,而节点缓存区有限,在数据量较大的情况下容易产生节点缓存区溢出的情况。因此,本文相继提出一种基于簇号及线性相关性的节点缓存模型。当中间节点缓存区满时,以“簇号”为索引优先存储属于同一簇的数据块进行编码。然后中间节点对同一簇的数据块进行线性相关性检测,决定数据块的保留与丢弃。
1 研究现状
通信网络端到端的最大数据流,是由通信网络中有向图的最小割决定的[4]。传统的机会网络数据分发方式大多基于洪泛的传染扩散方法,虽然可以适应网络的拓扑动态性,却几乎不可能达到网络数据流的上界。早期的数据分发策略主要依赖于数据发送者,例如有作者提出了一种Stored-GeoCast分发策略[5],在该策略中发送者为准备发送的每个数据指定目标区域和有效期,在目标区域内的节点都可接收到数据。这种算法没有注重数据的分类,同一条消息的副本过多,造成网络负载增长过快从而使带宽利用率较低。在后来提出的以内容为中心的数据分发方法LMDC中[6],数据按内容种类进行分层,可以使用户选择自己感兴趣的数据。该方法采用HEC,即源节点结合复制技术和EC处理后将数据发送出去。无论是哪种数据分发方式,中间节点对数据的操作只是存储与转发。
Katti等提出基于机会的网络编码方法(COPE)[7],首次研究了网络编码在无线环境协议层面上的具体实现问题。COPE协议中每个节点对传输媒体进行侦听,获得它邻居节点的状态信息,决定编码机会,并在本地的FIFO缓存结构内进行编码,然后进行基于机会的路由。但是该协议需要节点存储数据包并进行编码,如果网络出现拥塞,可能就会耗费较多的节点存储空间。
码构造算法是在数据分发系统中部署和实现网络编码的核心,R.Koeettr和M.Mdeard提出的代数法码构造方式[8],以及S.Jaggi等人提出的信息流法[9],都要求在已知整个网络拓扑信息的情况下,用一个系统转移矩阵来描述源节点输出的数据和目标节点接收到的数据的关系,通过构造符合要求的系统转移矩阵来实现网络编码。机会网络中的节点是随机高速移动的,网络的拓扑信息经常变化,这种方法代价很大。为使得网络编码在机会网络中具有实际可用性,Li等人提出了线性网络编码的概念,证实节点进行线性网络编码运算,具有可行性,能够达到最大流传输理论极限[10]。Ho等人提出了有限域下随机线性网络编码的思想,并证实其有效性[11]。之后,随机线性网络编码被应用于各个方面的研究,用于提高网络吞吐量和能量利用率。
2 相关研究工作
2.1 CRLNC数据分发机制的数学模型
定义1(网络模型):图G=(V,E)表示机会网络,其中V表示所有节点的集合,源节点为S,目标节点的集合为R,任一目标节点表示为Ri∈R,E表示此刻所存在的所有链路的集合。
定义2(数据流向量):源节点S发出的数据,链路e∈E上传输的数据,目标节点Ri∈R接收到的数据,均以向量的形式取之于有限域GF,该向量成为数据流(Data Flow)。假设源节点要发送的数据块数目为n,则数据流向量为b=(b1,b2,…,bn),每个目标节点接收到的数据块可用向量 r=(r1,r2,…,rn)表示。
定义3(系数矩阵):中间节点接收到数据块后对其进行线性组合时随机在有限域GF内选取的数称为随机系数,表示为cij,i,j∈[1,n]。由随机系数cij组合而成的矩阵为系数矩阵,表示为C。当目标节点接收到r时,若C满秩(Full Rank),就能通过矩阵逆运算bT=C-1r解出源节点发送的数据流向量b。
定义4(转移矩阵):系数矩阵C称为随机线性网络编码相对于目标节点的转移矩阵(Transfer Matrix)。
机会网络CRLNC数据分发机制中各链路传输的数据、节点接收的数据和节点发出的数据均可表示为源节点发出数据流向量b中各元素的线性组合。因此,对于目标节点收到的任一数据块ri∈r,有ri=ci1b1+ci2b2+…+cinbn,i∈[1,n],矩阵形式为

2.2 CRLNC数据分发机制的算法实现
CRLNC数据分发机制的核心思想是利用机会网络中节点的高运算能力,源节点将原始数据先分簇再分块后将一簇内的数据块顺序发送出去。中间节点接收到数据块后将其随机线性编码组合,目标节点收到满足可解性条件的编码数据块后运用高斯—约旦消元法解码获得原始数据。目标节点具备可解性的条件是:目标节点接收到的线性编码组合的编码向量矩阵(即由编码参数组成的矩阵)的秩大于或者等于所含数据块的数量。
图1表示了每个在机会网络中传输的编码数据块结构,包含簇号CID、块号ID、编码向量和编码信息。其中簇号CID表示该编码块属于哪一簇,块号ID是来标识该数据块属于某一簇的第几块,编码向量的选取原则是从有限域GF(28)中随机选取,编码信息表示对原始数据或者已编码数据进行线性组合的结果。

图1 CRLNC数据分发机制的数据块结构
如图2所示,源节点S先将原始数据分成若干簇,再在每簇内分成大小相等的3个数据块B1,B2,B3后,将其发送给目标节点R1和R2。下面描述机会网络的中间节点如何运用随机线性网络编码来完成到目标节点R1和R2的数据分发。其中,一簇数据块传输完毕后再进行下一簇数据的线性组合、传输。编码后的数据块可表示为B'=∑ciBi。其中,ci为中间节点选择的随机系数,随机系数的选取原则是从有限域GF(28)中随机选取,Bi为原始数据块。
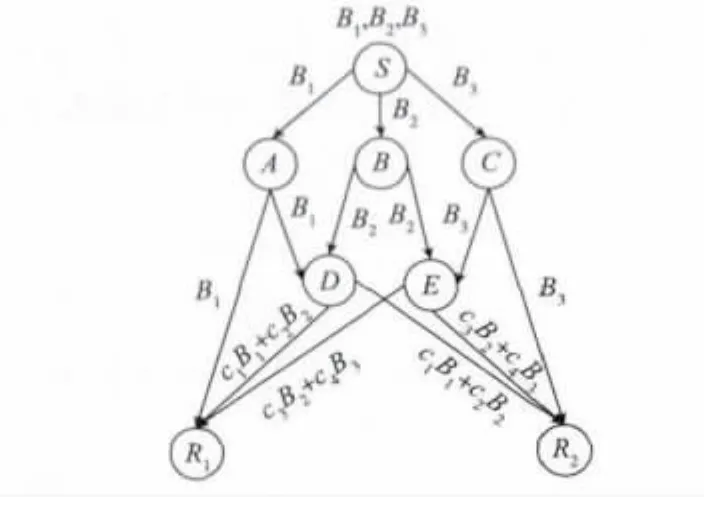
图2 CRLNC数据分发模型
源节点S将数据块B1,B2,B3逐一发送出去,节点A,B,C,D,E是中间节点。其中节点A接收到数据块B1,节点B接收到数据块B2,节点C接收到B3。节点D接收到由节点A和B发送来的数据块B1和B2后将其线性组合为c1B1+c2B2;节点E接收到由节点B和C发送来的数据块B2和B3后将其线性组合为c3B1+c4B2,然后分别将编码数据块发送出去。目标节点R1只需接收到来自节点A的数据块B1,来自节点D的编码数据块c1B1+c2B2或者来自节点E的编码数据块c3B2+c4B3的任意一个即可运用高斯—约旦消元法进行渐进式解码来获得原始数据块B1,B2,B3。对于目标节点R2来说,同理可解码出原始数据块。
对于目标节点R1开说,若某时刻接收到3个线性无关的编码数据块B1,c1B1+c2B2和c3B2+c4B3,则可以得出三元方程组,即
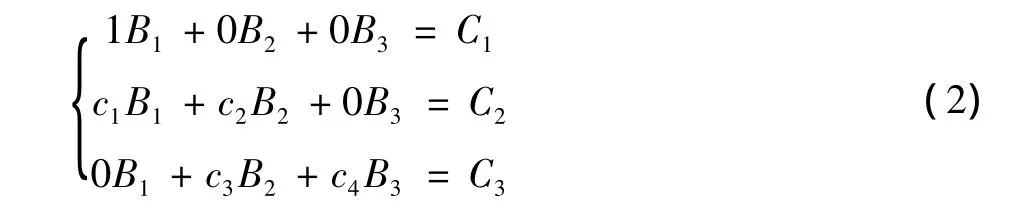
目标节点接收到3个编码数据块后的编码向量矩阵情况为

目标节点将编码向量矩阵通过高斯—约旦消元法解码原始数据块B1,B2,B3。
高斯—约旦消元法属于逐步解码,也称为渐进解码。目的是为了减少解码时间对端到端传输总体性能的影响,基本思想是使解码和接收数据块同时进行,从而节省时间。渐进解码的具体方法是:每收到一个线性组合,使用初等行变换将由系数和线性组合而成的增广矩阵化简一次,使其变为行约简阶梯形矩阵,如

收到第3个线性组合并成功化简后,增广矩阵的左右两侧分别为3阶单位矩阵和解码出的原始数据分块,如

式(5)所示增广矩阵的右侧即是通过高斯—约旦消元法解码出的原始数据块,结果为
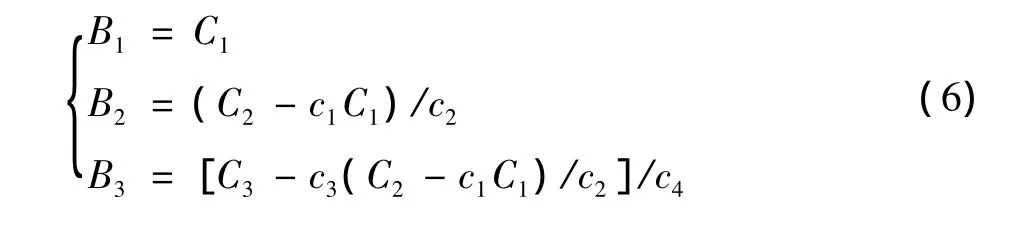
下列伪码描述了上述基于分簇的随机线性网络编码数据分发机制的实现过程:

2.3 基于簇号及线性相关性的混合节点缓存机制
在CRLNC数据分发机制中,由于中间节点接收到的编码数据块可能是冗余数据,如果经常在节点间传输这种冗余数据,则会严重浪费带宽和节点的计算资源,而且这种冗余数据会被其他中间节点重新进行随机线性网络编码,在机会网络中进行大范围的传播,导致整个网络的数据分发效率极低。针对这个问题提出一种基于簇号及线性相关性的节点缓存机制,若接收到的编码数据块的编码向量与节点已有的编码数据块向量线性相关,则节点直接丢弃接收到的编码数据块;否则,节点缓存该数据块。机会网络中节点执行该机制的伪代码如下:

中间节点接收到编码数据块后,在该编码块和之前到达的编码块进行比较。如果传送给中间节点的数据块的簇号和该节点里其他编码数据块的簇号相同,那么检测接收到的编码数据块对应的编码向量是否已经存在于该节点,或者该编码向量是否与该节点已经存在数据块包含的编码向量线性相关。若线性相关,则说明该数据块是冗余数据,节点直接丢弃该编码数据块;否则,说明该编码块携带有新的数据,节点将缓存该编码数据块并再次进行线性编码并转发。总而言之,这种缓存机制能够有效降低各中间节点执行编码的计算消耗,同样也缓解了机会网络中的节点缓存矛盾。
3 仿真实验与性能评价分析
实验将在时延和网络吞吐量性能方面分别对基于存储和转发的传统的数据分发机制、一般的网络编码以及CRLNC机制进行性能评价,仿真软件采用事件驱动的NS2仿真平台,该软件可以根据需要添加相关协议来确定节点的行为和节点之间数据传输的方式。
仿真场景为100 m×100 m的区域,随机分布着1个源节点、2个目标节点和50个中间节点,原始数据长度L=10 Mbyte,在运用随机线性网络编码时将原始数据分成10簇。
3.1 时延性能评价
在进行3种数据分发机制的时延性能分析时,根据每簇中的数据分块数的变化来分析,将每一簇分别分为如图3所示的数据块数目。从图中可以明显看出,无论采用哪种数据分发机制,当每簇的分块数为4时,即每个数据块大小为256 kbyte时数据分发时延最小。因为若每簇的分块数较小,则每块的数据量较大,在发送过程中极可能由于数据丢失而重新传输;若每簇的分块数较大,则每块的数据量较小,这样会增加数据发送的次数。这两种情况都会导致高时延问题。在最开始发送数据量最大时,3种数据分发的时延都比较大,但是总体而言,网络编码机制要优于传统的基于存储和转发的数据分发机制。本文提出的基于分簇的随机线性网络编码数据分发机制在节点缓存问题上采用了不同的基于簇号及线性相关性的节点缓存策略,所以不会由于节点缓存满,数据丢失后重传而造成时延增大;目标节点在解码时运用高斯—约旦消元法可以将接收数据和解码数据并行执行,所以在很大程度上缩短了时延。
3.2 网络吞吐量性能评价
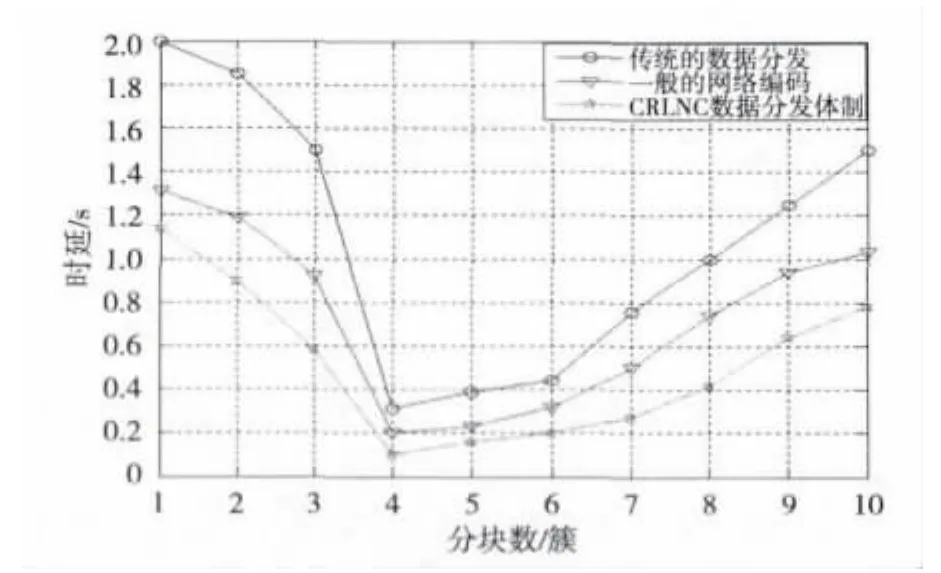
图3 数据分发机制时延性能评价
在进行3种数据分发机制的网络吞吐量性能分析时,将每一簇分为4块数据块,即每块大小为256 kbyte来进行仿真。如图4所示的数据分发网络吞吐量性能评价图,从图中可以看出,传统的基于存储和转发的数据分发机制中,由于各链路上传输的数据不能被叠加,所以其吞吐量要远远低于两种基于网络编码的数据分发机制,无法实现理论上的容量。而一般的网络编码对原始数据进行简单的编码操作然后发送出去,这种数据分发机制的吞吐量比传统的数据分发机制要高很多,但是在数据量较大的情况下性能会降低。而基于分簇的随机线性网络编码数据分发机制在数据量很大的情况下将原始数据分簇再分块,减少了单次要传输的数据量,所以可实现高达9 Mbit/s的网络吞吐量。

图4 数据分发机制网络吞吐量性能评价
由上述仿真结果分析可知,CRLNC在端到端延迟和网络吞吐量性能指标上均表现良好,很好地解决了机会网络中数据分发的问题。
4 小结
本文提出了一种机会网络中基于分簇的随机线性网络编码的数据分发机制,理论分析和仿真结果表明:与传统的数据分发机制相比,CRLNC可以弱化甚至消除数据分发效率对原始数据大小的依赖,有效减少了单次要传输的数据量,提高了传输效率;基于簇号和线性相关性的节点缓存机制可以保证节点之间传输的编码数据块总是有效的,可以提高网络带宽利用率,节约节点的计算资源。总之,本文提出的数据分发模型能够在一定程度上提高网络编码的执行效率,降低网络编码所需的计算消耗,进一步提升数据分发的性能。在今后的工作中,在拥有高效率网络编码的同时要进一步针对低复杂性的网络编码进行更深入的研究。
:
[1]熊永平,孙利民,牛建伟,等.机会网络[J].软件学报,2009,20(1):124-137.
[2]HU Q,ZHENG J.Weight pick:an efficient packet selection algorithm for network coding based multicast retransmission in mobile communication networks[J].Wireless Networks,2013,19(3):363-372.
[3]AHLSWEDE R,CAI N,LI S Y R,et al.Network information flow[J].IEEE Transactions on Information Theory,2000,46(4):1204-1216.
[4]ELIAS P,FEINSTEIN A,SHANNON C E.A note on the maximum flow through a network[J].IEEE Transactions on Information Theory,1956,2(4):117-119.
[5]MAIHOFER C,FRANZ W J,EBERHARDT R.Stored geocast[C]∥Proc.Kommunikation in Verteilten Systemen(KiVS).[S.l.]:Springer Verlag,2003:257-268.
[6]CHEN L J,YU C H,TSENG C L,et al.A content-centric framework for effective data dissemination in opportunistic networks[J].IEEE Journal on Selected Areas in Communications,2008,26(5):761-772.
[7]KATTI S,HU W,RAHUL H,The importance of being opportunistic:practical network coding for wireless enviroments[EB/OL].[2013-01-01].https://www.cl.cam.ac.uk/research/srg/netos/papers/2005-allerton-netcoding.pdf.
[8]HO T,LUN D S.Network coding:AN Introduction[D].Cambridge:Cambridge University,2008.
[9]JAGGI S,LANGBERG M,KATTI S,et al.Resilient network coding in the presence of byzantine adversaries[J].IEEE Transactions on Information Theory,2008,54(6):2596-2603.
[10]LI S Y R,HO S T.Ring-theoretic foundation of convolutional network coding[C]//Proc.Fourth Workshop on Network Coding,Theory and Applications.Hong Kong:IEEE Press,2008:1-6.
[11]HO T,KOETTER R,MEDARD,M,et al.A random linear network coding approach to multicast.IEEE Trans.Inform.Theory,2006,52(10):4413-4430.
[12]黄辰,王芙蓉,戴彬,等.基于网络编码的无线自组织网数据分发机制[J].电子学报,2010(8):1852-1857.
CRLNC:Efficient Data Dissemination Mechanism For Opportunistic Network
QIAO Jinlong,GAO Yuan,LIU Yahong,TAN Chunhua
(Colleage of Computer Science and Technology,North University of China,Taiyuan 030051,China)
Aiming at improving the efficiency of data dissemination in opportunistic network,an efficient data dissemination mechanism combined with clustering and random linear network coding is proposed.The core idea is dividing the data into several clusters firstly,and then dividing each cluster into the same number of data blocks,the source node sends the data blocks in each cluster,the intermediate node encodes the data blocks with random linear coding algorithm and then forwards the encoded data block,the destination node uses Gauss-Jordan elimination method to restore the data progressively after receiving the encoded data blocks.Aiming at the redundancy of node cache space,this data dissemination mechanism proposes a node caching strategy based on cluster number and linear correlation.Theoretical analysis and simulation results show that CRLNC outperforms the traditional data dissemination mechanism,CRLNC mechanism effectively improves network throughput and reduces the end-to-end delay.
opportunistic network;data dissemination;random liner network coding;linear relevance
TN915;TP393
B
责任编辑:许 盈
2013-03-12
猜你喜欢
China Report Asean(2022年8期)2022-09-02
中国石油石化(2022年12期)2022-07-16
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
物联网技术(2020年12期)2021-01-27
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
疯狂英语·新读写(2018年3期)2018-11-29
