
基于情感挖掘的图书评价方法
2015-03-07 08:10裴锦隆石家庄第二医院050051
学周刊 2015年34期
裴锦隆(石家庄第二医院050051)
张利宽(北京交通部科学研究院100000)
基于情感挖掘的图书评价方法
裴锦隆(石家庄第二医院050051)
张利宽(北京交通部科学研究院100000)
本文通过抓取某电子商务网站医学图书客户评价和某医院图书馆读者评语,然后构建了基于投票机制的情感挖掘模型,并对此模型进行实验验证,使用此模型对读者评语进行了评价分析,为图书馆图书评价,图书选择提供了客观的支持。
情感挖掘图书模型
一、引言
用户评价在产品体验中扮演着越来越重要的角色,随着大数据时代的到来,人们逐渐地认识到,通过对用户评语的分析,进而能够判断消费者对产品的认可度。在医院图书管理方面也不例外,如今许多医院都建立了在线图书馆,并提供读者对数据的评论平台,这样为通过分析读者评语而挖掘读者喜好,客观判断图书的受欢迎程度提供了可能。本文试图通过构建读者评语的情感挖掘模型,判断读者对图书的喜好,进而对医院图书馆所购图书的受欢迎度进行衡量。
二、情感挖掘模型
(一)情感挖掘研究现状
情感挖掘是指通过分析挖掘文本所隐含的语义和情感信息,将文本划分为支持和反对(正性情感和负性情感)的两类[1]。情感挖掘是一种特殊的文本分类,作为自然语言处理的一个重要部分,由于在商务智能、公众意见分析中的实用性,情感挖掘已经成为自然语言处理领域的一个热点,得到了众多学者的重视。
现有情感挖掘的研究方法主要有两种,基于情感词典的方法和基于机器学习的方法。基于情感词典的方法主要是通过已经标注好的情感词的词库,依照情感词库中词语的情感等级,通过比对的方式对文本进行情感分类。
(二)情感挖掘模型构建
情感挖掘的中文文本处理过程主要包括分词、特征选择、分类模型设计实验验证等步骤。图2-1展示了情感挖掘的主要步骤。(见附图)
(三)文本预处理
由于汉语语言的复杂性,需要对初始数据进行去停用词、中文分词等操作。本文采用的分词工具是中科院计算所推出的ICTCLAS[2,ICTCLAS是一个基于隐马尔科夫模型的一个汉语分词系统。在歧义词识别和新词识别上都得到了很大的提升,分词精度达到98.45%。
(四)特征选择及权重计算
特征抽取分为两个步骤:一是特征词的选取;二是已选特征词的权重确定。
特征词的选取采用情感词典与测试语料集匹配选取的方法。即选择一个已有情感词典,逐个情感词典中的特征词,将其与已经分好词的中文语料集进行字符匹配,若匹配成功,则该特征词入选。为尽可能扩大情感词典的词库规模,本文将汉语自然语言处理最优秀的两个情感词典进行联合,得到一个联合情感词典。本文选择的情感词典是中国知网整理的“情感分析用词语集[3]”和台湾大学整理的中文通用情感词典NTUSD[4]。
设D为情感词库,且D={t1,t2,...tn},正向情感的文档子集为D1,负向情感文档子集为D2。另设有一个文档dj=(w1j,w2j,…,wnj),其中wij为情感词的权重。在本文中wij定义为:
wij=wtd(ti,dj)×wts(ti)(2-1)
其中,Wtd(ti,dj)为词项ti在文档dj中的重要性,Wts(ti)为词项ti表达情感上的重要性。
对于词项在文档中的重要性Wtd(ti,dj)的计算本文采用词频的两倍归一化方法,将权重控制在0.5到1之间。
W↓td(t↓i,d↓j)=0.5+(0.5×f↓ij)/max|m|f↓kj|(2-2)
式中fij是是词项fi在文档dj中的出现频率。
在完成特性选择和权重计算后,我们对分类模型进行了设计。在前人的研究中,最常用的三种机器学习的分类模型有支持向量机SVM、朴素贝叶斯NB、和最近邻KNN三种分类方法[5]。为达到更好的分类准确性,本文在利用三种最常用的分类器基础上,设计了基于投票机制的集成分类方法。即将分类输入分别用三种常用分类器进行分类,最后将输出结果按照投票的机制决定。实践证明这种分类方法取得了较好的效果。
三、实验验证
我们分别使用了两个预处理好的语料集对情感挖掘模型进行实验验证,第一个数据集是从某著名的在线图书电子商务网站抓取的医学类书籍的顾客评语。第二个是从医院图书馆网站搜集的院内读者的图书评语数据集。
实验验证过程本文将支持向量机、朴素贝叶斯和最近邻三种算法的分类结果与本文设计的集成模型分类结果进行比较。
评价指标采用文本分类常用的评价指标查准率,查全率和F-measure。
图3-1和图3-2为本文推荐方法与其他数据挖掘方法在不同数据集上的分析结果。(见附图)
结果证明,通过在两种不同测试集上分别使用四种不同的分类器进行实验验证,最终从实验结果我们可以分析出,两种测试结果中,最低值高于0.8,说明四种分类模型对文本情感挖掘都具有较好的分析效果,两个数据集中,投票集成模型F-measure值均取得最高值。这说明投票集成模型有效性明显高于其他三种模型。
[1]宗成庆.统计自然语言处理(第二版).北京:清华大学出版社,2013.
[2]张华平.ICTCLAS中文分词系统.http:// www.nlpir.org/. [3]HowNet,http://www.keenage.com/. [4]NTUSD,http://nlg18.csie.ntu.edu.tw:
8080/opinion/pub1.html.
[5]胡泽文,王效岳,白如江.国内外文本分类研究计量分析与综述.图书情报工作,2011: 78-81.
(责编张敬亚)
附
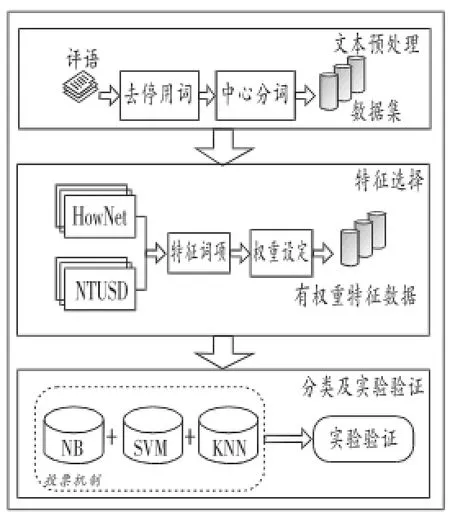
图2 -1 图书评语情感挖掘数据处理框架图

图3 1某电子商务网站数据集分析结果

图3 2医院图书馆数据集分析结果
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
四川文学(2020年11期)2020-02-06
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
语文教学与研究(2014年9期)2014-02-28
语文教学与研究(2014年7期)2014-02-28
当代修辞学(2013年4期)2013-01-23
外语学刊(2011年3期)2011-01-22
