
logistic回归中连续型自变量离散化为二分类变量时适宜分界点的确定*
2015-03-09 11:13中山大学公共卫生学院医学统计与流行病学系510080何贤英温兴煊公为洁张晋昕
中国卫生统计 2015年2期
中山大学公共卫生学院医学统计与流行病学系(510080) 何贤英 赵 志 温兴煊 公为洁 黄 波 张晋昕
logistic回归中连续型自变量离散化为二分类变量时适宜分界点的确定*
中山大学公共卫生学院医学统计与流行病学系(510080) 何贤英 赵 志 温兴煊 公为洁 黄 波 张晋昕△
目的提出logistic回归中连续型自变量离散化为二分类变量时的双界点OR值最大化分类法(简称双界点OR值最大法),通过模拟研究评价该法与其他离散化方法的模型拟合效果,并用实例数据进行验证。方法应用R软件中的“SmeiPar”包对连续型自变量与logitπ间是否呈单调变化性进行判定;对不满足单调变化关系的自变量,采用连续型变量法(或称原始取值法)、中位数法、单界点P值最小法、双界点OR值最大法对原始数据进行处理后,分别拟合logistic回归模型;从拟合优度、变异的解释程度方面评价模型拟合效果。结果模拟数据和实例数据分析结果均可见,双界点OR值最大法相对于单界点P值最小法能够更合理地反映影响因素和结局的关联,并且与连续型变量法和中位数分类法相比其模型拟合优度、变异的解释程度效果更好。结论在拟合logistic回归模型时,若连续型自变量与logitπ之间呈非单调变化关系时,建议使用双界点OR值最大法对数据进行离散化。
logistic回归模型 连续型自变量分界点OR值
logistic回归模型适用于分类的反应变量与多个影响因素之间关系的研究,在医学研究中有着相当广泛的应用[1]。拟合logistic回归模型时,要求连续型自变量与logitπ之间符合线性关系[2]。如果两者之间的关系是非线性的,参数估计将发生偏差,从而导致研究结论不可靠。而在实际应用中,两者线性关系的判定是一个经常被研究者忽视的问题[3]。本文对判定连续型自变量与logitπ之间是否满足线性关系的方法给予简单介绍,并就在连续型自变量和logitπ为非单调变化关系时,如何寻找适宜的分界点将连续型自变量转化为二分类变量进行了探讨。
原理与步骤
1.logistic回归模型
设某事件在影响因素x1,x2,…,xm的作用下发生的概率为π,不发生的概率为1-π,则由式(1)所定义的模型为logistic回归模型:
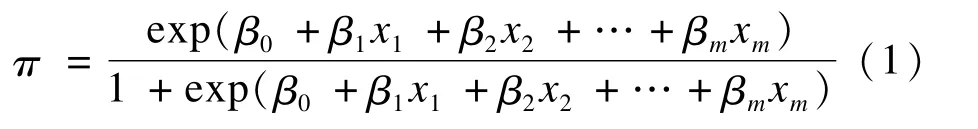
其中β0为截距,β1,β2,…,βm为回归系数。事件发生的概率π和未发生的概率1-π之比为优势比(odds ratio,OR),logitπ为OR的自然对数:

2.连续型自变量与logitπ线性关系的判断
国内研究者陈长生、徐勇勇等于2001年通过模拟实验,说明半参数回归模型较传统的线性模型有更好的适应性[4],Wand等于2003年对半参数回归模型进行了系统描述[5],并编制R软件中的“SemiPar”包用于半参数回归模型分析[6]。SmeiPar包中的半参数回归模型是一种使用了2m-1次样条平滑的混合模型,其一般表达式为[6]:

本研究采用半参数回归模型对自变量与logitπ间的函数关系进行判断,根据自由度是否大于2[7],判定自变量与logitπ之间是否满足单调变化性。
3.连续型自变量参与拟合logistic回归模型时的4种预处理方法
当连续型自变量和logitπ为非单调变化关系时,分别采用目前常用的3种处理方法及本文提出的双界点OR值最大法对原始数据进行预处理,进而拟合logistic回归模型。
(1)连续型变量法[8],也称原始变量法,即对连续型自变量不进行任何处理直接纳入回归模型分析。
(2)中位数法[9],以原始数据所得中位数为分界点,将连续型自变量转化为二分类变量纳入回归模型分析。
(3)单界点P值最小法[10],该方法以自变量的每一个取值作为潜在分界点,将原始数据一分为二,再拟合回归模型。通过分析比较,选择使P值达到最小的自变量取值为分界点,将连续型自变量转化为二分类变量纳入回归模型分析。
(4)双界点OR值最大法,首先,绘制自变量与logitπ之间的曲线关系,如图1(a)和2(a)所示。其次,在形如图1(a)和2(a)的“logitπvs自变量取值”的二维图中从logitπ的最大值点出发,用平行于x轴的直线横切曲线并向下平移。每次横切得到两个交点,直线上方的曲线覆盖的自变量范围对应于高风险段,直线下方的曲线覆盖的自变量范围对应于低风险段。然后,按照高、低风险对应的自变量范围将其重新赋值为二分类变量,再进行logistic回归分析,得到OR值。最后,比较每次平移处得到的OR值,从中选择使OR值达到最大值时两个交点对应的自变量取值作为最终的分界点。
4.模型效果的评价
模型效果的评价主要考虑模型的拟合优度和变异的解释程度。其中拟合效果的评价采用最小信息准则,即AIC准则(Akaike information criterion)、-2 Log likelihood;变异的解释程度采用NagelkerkeR2系数进行评价。
模拟研究及实例分析结果
1.模拟数据及实例数据来源
在R i386 3.0.3环境下产生包含连续型自变量X和因变量Y的模拟数据集,其中X~N(45,10),Y~B(500,0.25)。
实例数据来自一项有关广州市社区居民乳腺癌防治知、信、行的现况研究。选取预防乳腺癌相关知识得分作为因变量,年龄作为自变量,通过实例数据比较4种方法处理数据后拟合logistic回归模型的效果。
2.自变量和logitπ线性关系判定
图1(a)和2(a)分别对模拟数据和实例数据采用半参数回归模型拟合得到自变量和logitπ的函数关系图,其中两个自由度均有df>2,说明自变量和logitπ不满足线性关系。进一步通过如图1(b)和2(b)所示一阶导数和二阶导数图,判断自变量和logitπ函数关系的单调变化性。设函数f(x)在点X0处有二阶导数且f′=0,f″≠0。那么当f″<0时,函数f(x)在点X0处取得极大值;当f″>0时,函数f(x)在点X0处取得极小值。通过一阶导数和二阶导数,进一步说明自变量和logitπ为非单调变化关系。

图1 半参数回归模型拟合自变量和logitπ的函数关系图及其一阶导数、二阶导数图
3.用4种分类方法处理连续型自变量并拟合logistic回归模型的效果
表1、表2分别为模拟数据、实例数据采用上述4种方法处理自变量后拟合logistic回归模型的比较结果。
模拟数据分析结果显示,连续型变量法、中位数法拟合logistic回归模型,自变量X均无统计学意义(P=0.645和P=0.337);使用单界点P值最小法分类后的自变量有统计学意义(P=0.004、OR=0.451);使用双界点OR值最大法分类后拟合模型自变量亦有统计学意义(P=0.024、OR=3.322)。
实例数据分析结果显示,采用连续型变量法和中位数法分析,年龄均无统计学意义(P=0.172和P=0.451);使用单界点P值最小法分类后的自变量有统计学意义(P=0.003、OR=0.479),由此结果获得的提示是35岁以上个体对乳腺癌相关知识的了解程度低于35岁以下个体。使用双界点OR值最大法分类后拟合模型年龄具有统计学意义(P=0.019、OR=12.073),说明中青年个体较低年龄和高年龄的个体对乳腺癌相关知识得分高。
模拟研究和实例分析均可见,对于自变量和logitπ为非单调变化关系的数据,基于OR值最大化的分类方法均能更好地捕捉到与结局有关联关系的影响因素。与单界点P值最小法相比,双界点OR值最大法能够更合理地量化自变量和结局之间的联系,且模型的拟合优度、变异的解释程度均比目前常用的连续型变量法和中位数分类法效果好。
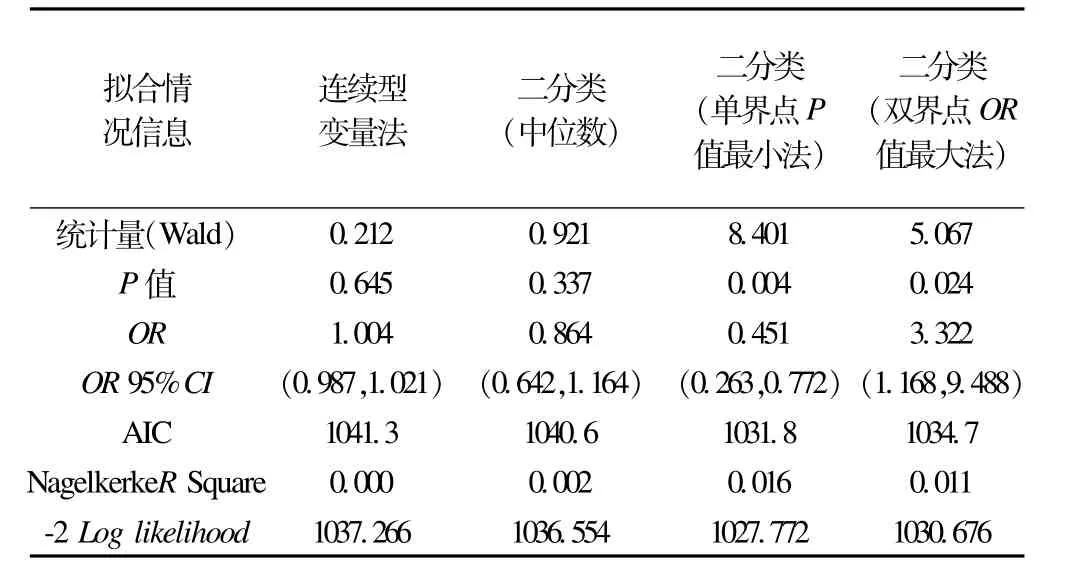
表1 模拟数据拟合logistic回归模型信息汇总表
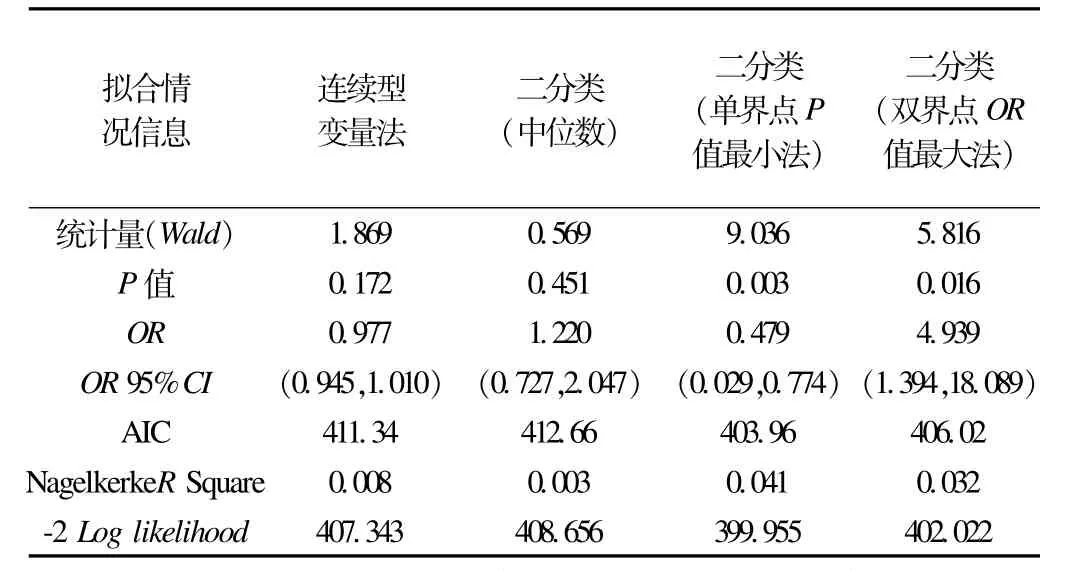
表2 实例数据(乳腺癌知识调查)拟合logistic回归模型信息汇总表
讨论与建议
在医学研究中连续型自变量很常见,如年龄、肿瘤大小等。研究者常利用这些变量,采用多因素回归模型刻画其与结局间的关联,进而探索疾病的危险因素、估计预后、指导治疗等[11]。研究者从临床应用的角度考虑,经常将连续型的自变量转化为二分类变量后拟合回归模型[10],目前最常用的分类方法为中位数法[12]。基于不同的研究数据,可得到不同的中位数估计值。因此,中位数法会导致不同的研究有不同的分界点,从而使各研究结果横向对比困难[13]。为了解决这一问题,Lausen等提出了单界点P值最小法[14],试图利用客观的统计指标去寻找分界点。因为连续型变量转化为分类变量后,被分到同一组内的个体均具有相同(或相近)的概率风险[15-16],而单界点P值最小法会使具有相同(或相近)概率风险的个体被分到不同组,从而造成不同组进行比较时高低风险有所抵消。
针对连续型自变量如何选择分界点的问题,为了使不同研究结果具有可比性,同时能够兼顾不同个体发生结局事件的概率风险,本文提出双界点OR值最大法,其要旨在于将OR值最大化作为寻找分界点的判定原则。之所以选择OR值,是因为其不仅能反映自变量和结局有无关系,而且能够充分概括这种关系的强弱;当筛选多个影响因素时,可以根据OR值的大小排序,对应于各影响因素的风险高低,便于在制定干预措施时把握轻重缓急,做到有的放矢。对于连续型自变量和logitπ为非单调变化关系的数据类型,建议借助OR值最大化的原则,对连续型自变量进行分类后拟合logistic回归模型。
1.Bagley SC,White H,Golomb BA.Logistic regression in the medical literature:standards for use and reporting,with particular attention to one medical domain.Journal of Clinical Epidemiology,2001,54(10):979-985.
2.Jewell NP.Statistics for Epidemiology.Boca Raton:Chapman and Hall/CRC,2003:179-198.
3.冯国双,陈景武,周春莲.logistic回归应用中容易忽视的几个问题.中华流行病学杂志,2004,25(6):544-545.
4.陈长生,徐勇勇,夏结来.半参数回归模型及模拟实例分析.中国卫生统计,2001,18(6):338-340.
5.Ruppert D,Wand MP,Carroll RJ.Semiparametric Regression.New York:Cambridge University Press,2003:186-192.
6.Wand MP,Coull BA,French JL,et al.(2005).SemiPar 1.0.R package.http://cran.r-project.org.
7.Wand H,Ramjee G.Analyzing continuous measures in HIV prevention research using semiparametric regression and parametric regression models:how to use data to get the(right)answer?.AIDS and Behavior,2012,16(6):1448-1453.
8.Schellingerhout JM,Heymans MW,et al.Categorizing continuous variables resulted in different predictors in a prognostic model for nonspecific neck pain.Journal of Clinical Epidemiology,2009,62(8):868-874.
9.Knüppel L,Hermsen O.Median split,k-group split,and optimality in continuous populations.Advances in Statistical Analysis,2010,94(1):53-74.
10.Williams B,Mandrekar J,Mandrekar S,et al.Finding Optimal Cutpoints for Continuous Covariates with Binary and Time-to-Event Outcomes.In Technical Reports Series#79Rochester,MN:Department of Health Science Research,Mayo Clinic,2006.
11.Sauerbrei W,Royston P.Continuous variables:to categorize or to model?.Eighth International Conference on Teaching Statistics-Data and context in statistics education:Towards an evidence-based society,2010.
12.Maccallum RC,Zhang S,Preacher KJ,et al.On the practice of dichotomization of quantitative variables.Psychological Methods,2002,7(1):19-40.
13.Baneshi MR,Talei AR.Dichotomisation of continuous data:review of methods,advantages,and disadvantages.Iranian Journal of Cancer Prevention,2011,4(1):26-32.
14.Berthold Lausen,Martin Schumacher.Maximally selected rank statistics.Biometrics,1992,73-85.
15.Abdolell M,Leblanc M,Stephens D,et al.Binary partitioning for continuous longitudinal data:categorizing a prognostic variable.Statistics in Medicine,2002,21(22):3395-3409.
16.Schulgen G,Lausen B,Olsen JH,et al.Outcome-oriented cutpoints in analysis of quantitative exposures.American Journal of Epidemiology,1994,140(2):172-184.
(责任编辑:郭海强)
广东省高等教育教学改革重点项目(2013-113-11)
△通信作者:张晋昕,E-mail:zhjinx@mail.sysu.edu.cn
猜你喜欢
课程教育研究(2021年27期)2021-04-13
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
统计与决策(2018年9期)2018-05-22
浙江大学学报(工学版)(2015年2期)2015-05-30
读与写·下旬刊(2014年6期)2014-08-07
中央民族大学学报(自然科学版)(2014年2期)2014-06-09
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
