
基于混合蚁群遗传算法的Hadoop集群作业调度
2015-03-13 01:38杜文才钟杰卓
海南大学学报(自然科学版) 2015年4期
楼 涛,杜文才,2,钟杰卓
( 1.海南大学 信息科学技术学院,海南 海口 570228 ; 2.澳门城市大学,澳门)
基于混合蚁群遗传算法的Hadoop集群作业调度
楼 涛1,杜文才1,2,钟杰卓1
( 1.海南大学 信息科学技术学院,海南 海口 570228 ; 2.澳门城市大学,澳门)
提出了一种基于蚁群与遗传算法融合的自适应作业调度机制,将遗传算法全局收敛、快速搜索的优点与蚁群算法正反馈、高求精率的优势相结合,以变异策略来加快局部寻优,提高收敛速度.实验结果表明本文算法可快速找到最适合当前作业的节点,有效提高Hadoop集群作业调度的效率.
蚁群算法; 遗传算法; Hadoop集群
Hadoop作为海量数据分布式处理的软件框架,整合了包括数据库、云计算管理和数据仓储等一系列平台,可靠、高效、可伸缩等特点使其成为工业界和学术界进行云计算应用和研究的标准平台,被广泛应用于FaceBook,Twitter,Yahoo! 等公司.通常情况下,Hadoop集群包括数以千计的服务器和数以万计的CPU,在如此庞大的集群中运行着大量不同类型的作业,作业之间可能还存在依赖关系,作业调度机制直接关系到Hadoop平台的整体性能和系统资源的利用情况.笔者通过研究关于Hadoop作业调度算法,提出了一种在遗传蚁群混合算法基础上的作业调度机制,从而解决现有算法的不足.
1 Hadoop平台的作业调度
Hadoop分布式系统基础架构由2个核心部分组成:分布式文件系统HDFS和分布式计算引擎MapReduce.其中,HDFS有着高容错性的特点,可部署在低廉的硬件上,提供高吞吐量访问应用程序的数据,HDFS是一个主从结构的体系,由NameNode节点和DataNode节点组成;MapReduce作为大规模集群上的简单数据处理方式,由JobTracker节点和TaskTracker节点组成[1].MapReduce计算架构的系统架构如图1所示.
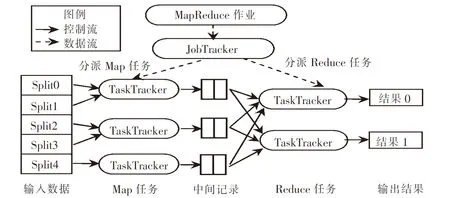
图1 MapReduce计算架构的系统架构图
1.1 Hadoop平台的作业调度流程将作业中划分成几个子任务并且分配到不同且合适的任务节点(TaskTracker)被称为 Hadoop 平台下的作业调度.Hadoop提供了Job方法[2],作业提交方法中包含了执行此任务所需的类、文件分块的相关信息以及有关的作业配置(如输入输出格式的类型等).JobClient将请求传送给JobTracker,JobTracker将请求加入作业队列中,同时产生JobInProgress对象,用于维护此作业的所有信息.
TaskTracker每隔10 s与JobTracker通讯一次,通过heartbeat()方法向JobTracker发送心跳信号.JobTracker根据TaskTracker的新任务心跳请求,调用分配算法,获取作业队列,确定任务可分配的作业队列,将该任务通过心跳答复传给TaskTracker执行.
1.2 现有作业调度算法在 Hadoop 0.19 版本之后,任务调度器的设计采用的是插件机制,即作业调度器是动态加载的、可插拔的,同时第三方可以开发自己的任务调度器替代Hadoop默认的调度器.目前,Hadoop的作业调度器主要包括:默认的FIFO算法、由Facebook提出的公平调度算法和由雅虎公司提出的计算能力调度算法.
FIFO算法采用一个FIFO队列进行调度,由JobTracker 根据预定义的作业优先级选择将被执行的作业,虽然实现非常简单、调度过程快,但只适用于单用户和单类型作业,处理多用户共享运行多类型作业时效率很低.
公平调度算法和计算能力调度算法都提供了配置文件,可以实现对资源的动态分配,提高资源的利用率.但是,Hadoop 集群中往往有着大量 MapReduce 作业和TaskTracker,管理员要对 TaskTracker上可以同时运行的最大任务数进行正确设置,就必须详细掌控 MapReduce 作业的资源需求情况和每个TaskTracker 的资源占用情况,这是很难做到的,而且容易出错;此外,为了保证每个作业都能得到所需资源,管理员需要同每个用户协商,才能够正确设置作业池和作业队列的资源配额,而在面向海量用户的情况下同样难以实施.
同现有任务调度算法对比,本文提出的算法不需要管理员进行预设置,而是通过监控每个TaskTracker 负载以及作业提交和完成的情况,自动地完成任务的选择及分配,以JobClient所提交的资源需求为基础,最终实现任务都能分配到适当的TaskTracker 节点上执行.
2 基于混合蚁群遗传算法的Hadoop任务调度
2.1 混合蚁群遗传算法基本思想蚁群算法(Ant Colony Algorithm,ACA)适用于求解单目标和多目标优化问题,但在搜索初期由于缺少信息素会导致信息素积累时间较长,求解速度较慢.遗传算法(Genetic Algorithm,GA)以“物种靠不断的演化而生成最适合生存的物种”的进化论观点为依据,对即定问题寻求最优解,能够实现快速的全局搜索[3],但由于该算法没有利用系统中的反馈信息,会导致大量冗余迭代,降低求精确解的效率.为了克服以上2种算法各自的缺陷,形成优势互补,笔者针对Hadoop平台下作业调度的特点和需求,基于对蚁群算法和遗传算法融合(Mixed Ant Algorithm&Genetic Algorithm, MAG)的思想[4-5],研究了一种高速收敛蚁群算法,算法的核心是动态信息素更新、最优节点选择和变异策略.
MAG算法的基本思想是首先利用遗传算法全局收敛性、快速搜索、随机性等特点生成初始信息素分布,根据信息素分布求得任务调度的最优解[6-7].
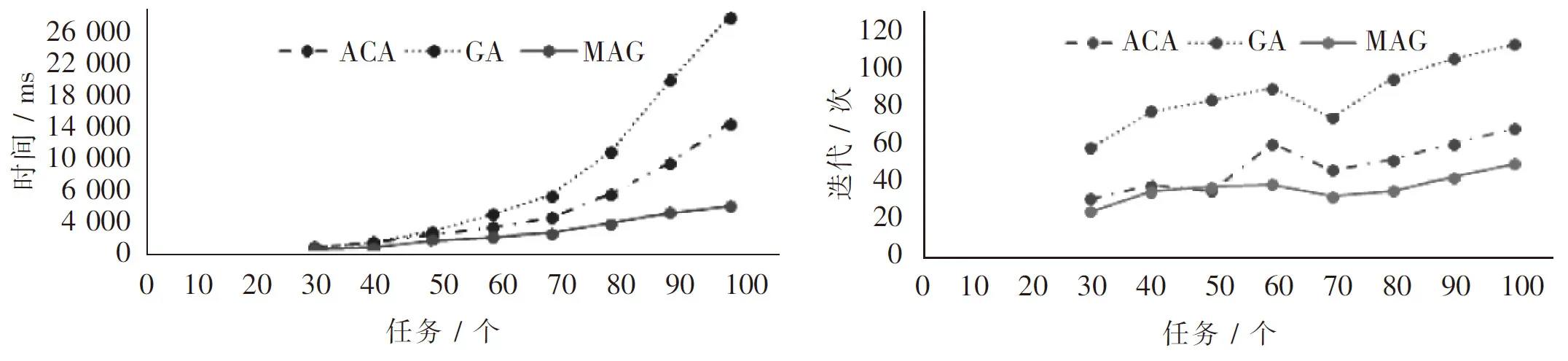
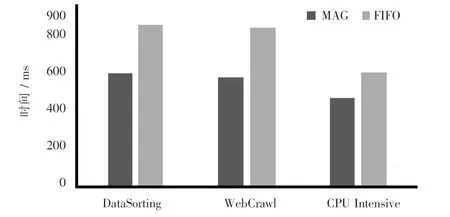
2.2 Hadoop作业调度的问题描述在Hadoop平台下,将n个相互独立的子任务分配到m个TaskTracker节点上执行(m 1)n个任务集表示为P={p1,p2, …,pn},pi(i=1, 2, …,n)表示第i个子任务; 2)m个TaskTracker节点集表示为T={t1,t2, …,tm},tj(j=1, 2, …,m)表示第j个TaskTracker节点; 3)设ETCij为子任务pj在节点ti上的期望执行时间,则对应的任务在节点上分配关系可构成m×n的ETC[m,n]矩阵 (1) 其中,ETCij表示第i个任务在第j个TaskTracker节点上运行的期望执行时间[8]. 2.3 遗传算法规则 2.3.1 遗传编码 染色体的编码方式很多,其中实数编码精度高,便于大空间搜索,因此采用一个实数串表达资源分配情况,作为遗传算法的染色体.假设有5个任务将分配在2个TaskTracker节点上,随机产生的分配方案为 t1:{p2,p4,p5} , t2:{p1,p3}, 则对应的实数编码串可表示为染色体A1:{2, 1, 2, 1, 1}.由于任务p2,p4,p5分配在t1节点上,因此在A1串中其对应的2,4,5位置上置为1.任务p1,p3分配在t2节点上,因此在A1串中其对应的1,3位置上置为2. 2.3.2 初始种群 初始种群的生成可表示为在从1到n的每一位上产生一个[1, m]的随机数,其含义是将n个任务随机分配到m个TaskTracker节点上. 2.3.3 适应度函数 本算法将目标函数定义为Sbest=argminTimes,适应值函数定义为fitness(s)=1/Times,其中Times表示调度时间[9-10]. 2.3.4 遗传操作 为了避免遗传过程的收敛时间过长,本文算法将群体大小设定为50.此外,考虑到交叉概率Pc和变异概率Pm对遗传算法性能和收敛性的影响,采用了自适应遗传算法,使得Pc和Pm随着适应度的变化自动改变.Pc和Pm按如下公式进行自适应调整 (2) (3) 2.4 蚁群算法规则 2.4.1 各节点的信息素表示 本算法中用节点上的资源能力与通过遗传算法中得到各节点上的任务预计执行时间相结合,来衡量该节点的信息素. 通过TaskTracker与JobTracker之间通信时所提交的心跳信息,可获知每个TaskTracker节点所拥有的硬件资源情况,用CPU处理能力p,m,d,b分别代表内存、磁盘和带宽的容量的信息素,为避免节点超负载,需为每个参数设置一个阈值,分别为p0,m0,d0,b0,可将各信息素初始化为 CPU计算能力信息素 τip(0)=p/p0×100%. 内存的信息素 τim(0)=m/m0×100%. 磁盘的信息素 τid(0)=d/d0×100%. 带宽的信息素 τib(0)=b/b0×100%. 节点i的信息素是各信息素的带权和,其中,a,b,c,d代表的是对于不同的任务,所需资源的权重.例如,对于CPU密集型任务,可适当增加CPU计算能力信息素所对应的权重,CPU计算能力较强的节点更容易被选中. τi(0)=aτip(0)+bτim(0)+cτid(0)+dτib(0), (4) a+b+c+d=1. 结合遗传算法阶段对各节点上分配任务的执行时间预计情况,可将节点i上的信息素初始化为 τi(t)=τi(0)+τiG(t) , (5) 其中,τiG(t)是从遗传算法求解结果转换而来的信息素值. 通常作业调度算法只考虑本次调度,选择将资源分配至某些最优资源节点,使该节点过于繁忙,而某些节点可能一直没有被分配任务而处于资源闲置.为了实现负载均衡,本算法加入计算负载系数其计算公式v=Uc/Usum,其中,Uc代表已完成的任务量,Usum代表所有任务量.据此控制i节点信息素的更新 τi=v×τi(t) . (6) 2.4.2 任务期望执行时间 分布式计算的作业调度比其他调度更需要关注任务的最小完成时间,在使用蚁群调度时需计算出在所有资源上每个任务的期望执行时间ETC,生成ETC矩阵,并将其作为蚁群算法的启发信息之一.随着算法的不断进行,节点上要完成的任务会减少,任务完成时间也会减少,因此,需用以下公式更新各节点上任务的预计执行时间 (7) 其中,ETCjn predict(Jpredict(t2))表示t2时刻j节点上运行新任务Jpredict所需的预计执行时间,npredict表示j节点在t2所运行的任务数(即节点的负载大小). 设置一个区间,规定如果新任务在某个节点上的预计完成时间在该区间范围内,该节点就是有效节点.如果存在一个节点从没有被分配过任务,则算法根据节点上的资源自动生成预计完成时间,若该时间在有效时间区间内,则该节点是有效节点[11-12]. 2.4.3 蚁群算法的节点选择 蚂蚁将按如下公式选择下一跳节点 (8) 经过时间n,所有蚂蚁对有效节点进行遍历以后,当前蚂蚁所在的节点将置入tabuk,准备下一次遍历.此时,计算每只蚂蚁所有走过的路径Lk,并保存最佳路径(所需时间最短的路径)Lkmin(Lkmin=minLk,k=1,…,m),作业调度器选择一个信息素最多的节点,将任务分配给其. 2.4.4 信息素的改变 当节点上资源使用率增大即被分配新任务后,信息素会相应减小,可规定此时信息素按如下公式更新 τi(t1)=τi(t)-λτi(t) 0<λ<1 , (9) 其中,τi(t1)是在t1时刻,新任务到达i节点时节点上的信息素浓度,τi(t)表示i节点在时刻t的信息素浓度,λ为调节因子. 随着某任务在t2时刻运行成功或失败,该任务所在节点的负载都将减轻(任务执行失败时将从当前节点被调离),此时可按以下公式增加信息素浓度,从而保证节点负载平衡 τi(t2)=τi(t1)-λ1τi(t1) 0<λ1<1. (10) 此外,成功完成任务的节点,可增加该节点的信息素浓度作为奖励,而任务失败的节点也应减少其信息素予以惩罚,以便引导前向蚂蚁接下来的选择.因此可增加一个用于增加或减少节点信息素浓度的调节因子 τi(t2)=(1+λ2)(τi(t1)+λ1τi(t1)) 0<λ1<1, (11) 若任务运行成功,则0<λ2<1;若任务运行失败则-1<λ2<0. 2.5 算法流程基于MAG算法的Hadoop任务调度流程如下 Step1初始化遗传算法控制参数,读取JobTracker上的作业队列以及各TaskTracker节点通过心跳信号提交的任务执行和资源负载情况; Step2设置遗传算法结束条件; Step3随机生成初始种群A(0); Step4计算A(0)中个体的适应度及ETCij; Step5根据个体适应度和选择策略确定A(g)代解群,其中g为遗传代数; Step6根据式(2)所示的交叉概率Pc执行内部交叉操作; Step7根据公式执行变异操作; Step8计算ETCij和A(g+1)的个体适应度.保留最优解g+1; Step9重复Step5~8,直到满足遗传算法结束条件; Step10从A(g)中选择适应度值高的前n%个个体,放入集合,作为优化解集合;生成ETC矩阵并根据集合中的优化解,转换出各节点的信息素参数 ; Step11初始化蚁群算法控制参数,根据式(6)设置各节点上的信息素; Step12设置蚁群算法结束条件; Step13将n只蚂蚁随机发送到m个资源节点上; Step14每只蚂蚁根据式(7)所示的期望时间阈值限制,和式(8)所示的节点选择概率选择下一节点; Step15完成所有任务调度后,根据适应度的值通过式(11)更新全局信息素.否则,跳转至Step14; Step16直到算法达到最大迭代次数输出最优解,否则转至Step13. 2.6 算法复杂度分析在蚁群算法中,可以分析得到影响算法的复杂度的因素为节点数n,蚂蚁数量m,迭代次数T,时间复杂度time=n×(n-1)×m×T/2,一般来说在具体实验中,m是n的2/3,T是n的倍数,分别设为m=n×2/3,T=k×n,于是time=n×(n-1)×n×2/3×n×k/2,当n趋于无穷大时,k远小于n,time约等于n4,因此蚁群算法时间复杂度为O(n4),同理可得空间复杂度为O(n2).同理分析可得遗传算法属于一个二重迭代,时间复杂度为O(n2). 本文提出的基于MAG算法从流程分析可知该算法的复杂度为O(n). 3.1 MAG算法仿真实验为了检验本算法的优越性,首先在MATLAB中进行了MAG算法与GA,ACA算法完成搜索最求解的仿真实验.模拟环境以20~100个任务,10个资源点为例进行测试.其中,GA算法和ACA算法中控制参数的设置与MAG中相应的设置相同,为了保证实验结果不失一般性,仿真数据在10个资源点上同时进行. 图2 时间-任务曲线图3 迭代-任务曲线 图2显示了MAG,GA和ACA算法在调度30~100个任务时所消耗的时间情况.GA在处理前50个任务时的搜索能力较强,搜索时间较短,但随着迭代次数增多,搜索时间也越来越长.与之相反,ACA算法在搜索的初期由于缺少信息素,搜索速度缓慢,但随着信息素的积累搜索最优解的速度迅速提高,时间增加幅度小于GA算法.图3给出了3种算法在调度30~100个任务时获得最优解所需要迭代的次数,通过对3组数据的比较可见,GA算法的迭代次数最多,计算势必耗费大量时间.相比之下,MAG算法在搜索的前期借助GA算法能够快速获得初始信息素分布,在达到最佳点之后再结合ACA算法可高效求得任务调度的最优解,无论是时间上还是迭代次数上都表现出较明显的优势. 3.2 基于Hadoop平台的作业调度测试为了测试MAG算法在Hadoop平台下对作业调度的影响,笔者在海南大学云计算实验室配置了30个测试节点,基本配置:4个处理核心,8G内存,1TB硬盘.其中一个节点作为主控节点,同时承担HDFS文件系统的NameNode节点以及MapReduce集群的JobTracker节点角色,另外29个节点作为工作节点(DataNode及TaskTracker节点),每个计算节点分配6个Map计算槽、2个Reduce计算槽,主要实验参数如表1所示. 表1 Hadoop 参数设置 实验通过模拟真实作业来评估算法的使用情况,选择了3种基于Hadoop平台下的典型应用 DataSorting:实现了对文本数据的全局排序. WebCrawl:模仿爬虫行为,抓取网页内容并生成索引,属网络密集型应用. CPUIntensive:对输入的每个key-value对进行一次大整数乘法计算,属于CPU密集型. 数字1~10代表资源使用量,各作业的估计资源使用值如表2所示. 表2 各作业估计资源使用值 在Hadoop平台下常用的作业调度方法中,公平调度算法和计算能力调度算法需由管理员权衡作业的资源使用情况和集群中各TaskTracker节点的资源负载情况,手工设定配置文件相关参数,无法实现作业的自适应调度,与本文所设计的自适应算法没有可比性.因此仅针对Hadoop默认的FIFO作业调度器进行了比较测试,3种不同类型作业在2种调度方式下完成时间情况如图4所示. 图4 MAG 与FIFO 算法作业调度时间比较 在FIFO调度机制下不考虑不同作业不同用户的在资源需求和占用上的差别,而只是按照提交作业的时间顺序来进行调度,会严重降低系统资源利用率,例如当一个CPU密集型作业长时间占用计算资源时,会造成随后提交的某些交互型作业无法得到快速反馈,影响用户体验[17].基于MAG的调度算法虽然在作业调度初期会耗费一些时间搜集信息素并进行迭代操作,但能够根据作业需求和节点上资源负载的情况,得出任务调度的最优解.整体时间相比FIFO算法有着明显优势. 针对Hadoop集群作业调度方式的展开研究,提出一种基于遗传算法和蚁群算法融合求解任务分配最优解的方法,实现根据Hadoop集群各节点的负载情况以及对子任务完成时间的预计,将任务调度到最适合的节点上执行.本算法相对于目前应用于Hadoop平台的3种常用调度器,不仅提高了作业调度的效率,而且由于其自适应的特点,可以降低管理员对TaskTracker节点的管理成本,除Hadoop集群管理平台外,本算法也可应用于其他云计算环境下的作业调度. [1]HadoopWT.TheDefinitiveGuide[M].[S.l.]:O’Reilly, 2009:1-60. [2]ApacheHadoop[EB/OL].[2015-05-15].http://hadoop.apache.org [3] 王小平, 曹立明.遗传算法—理论、应用与软件实现[M]. 西安:西安交通大学出版社, 2002. [4]DebK,BeyerHG.Self-adaptivegeneticalgorithmswithsimulatedbinarycrossover[J].EvolutionaryComputation, 2001,9(2):137-221. [5]DorigoM,CaroGD.Antcolonyoptimizationanewmeta-heuristic:proceedingsofthe1999CongressonEvolutionaryComputation,WashingtonD.C.,July6-9,1999[C].[S.l.]:IEEE, 1999. [6]BonabeauE,DorigoM,TheraulazG.SwarmIntelligence:fromnaturaltoartificialsystem[M].Oxford:OxfordUniversityPress, 1999. [7]LämmelR.Google’sMapReduceprogrammingmodel-Revisited[J].ScienceComputerProgram, 2008,70(1):22-30. [8]LamC.HadoopinAction[M].Stamford:ManningPublications, 2010:86-110 [9] 李士勇.蚁群优化算法及其应用研究进展[J].计算机测量与控制, 2003, 11(12): 911-913. [10] 李鑫,张鹏.Hadoop集群公平调度算法的改进与实现[J].电脑知识与技术, 2012,8(1): 166-168. [11] 许丞, 刘洪,谭良.Hadoop云平台的一种新的任务调度和监控机制[J].计算机科学, 2013(1):112-117. [12] 贺晓丽. 一种用于任务调度的广义遗传算法[J].计算机工程,2010(17):184-186. [13] 刘琨,肖琳,赵海燕.Hadoop中云数据负载均衡算法的研究及优化[J].微电子学与计算机, 2012(9):18-22. [14] 宋昕,宋欢欢. 云计算环境下的流量控制和负载均衡策略[J].电子设计工程, 2011(12):112-115. [15] 许昌,常会友,徐俊,等. 一种新的融合分布估计的蚁群优化算法[J].计算机科学, 2010(2):186-190. [16] 李德启,田素贞.一种基于云环境下蚁群优化算法的改进研究[J].陕西科技大学学报(自然科学版), 2012(1):64-67. [17] 李彬.基于Hadoop框架的TF-IDF算法改进[J].微型机与应用, 2012(7):14-16. Hadoop Clusters of Job Scheduling Based on Mixed Ant Algorithm Genetic Algorithm Lou Tao1, Du Wencai1,2, Zhong Jiezhuo1 (1. College of Information Science and Technology, Hainan University, Haikou 570228, China; 2. City University of Macau, Macau, China) In our report, a kind of self-adaptive job scheduling mechanism based on ant algorithm and genetic algorithm was proposed, which integrated the advantages of genetic algorithm, the global convergence and fast search, with the characteristics of ant algorithm, the positive feedback and efficient refinement, and the mutation strategy was performed to accelerate the speed of local optimization and convergence. The results indicated that the algorithm can obtain the most suitable nodes for current jobs and effectively improve the efficiency of job scheduling on Hadoop clusters. Ant Algorithm; Genetic Algorithm; Hadoop Clusters 2015-06-03 国家自然科学基金(61162010);海南大学青年基金(Qnjj1186) 楼涛(1991-),男,浙江绍兴人,2013级硕士研究生,研究方向:数据与知识工程,无线移动计算等,E-mail:lou19910526@163.com 杜文才(1953- ),男,江苏徐州人,博士,教授,主要研究方向:e-Service,云计算,网络通信等,E-mail:georgedu@cityu.edu.mo,wencai@hainu.edu.cn 1004-1729(2015)04-0340-07 TP 311 A DOl:10.15886/j.cnki.hdxbzkb.2015.0060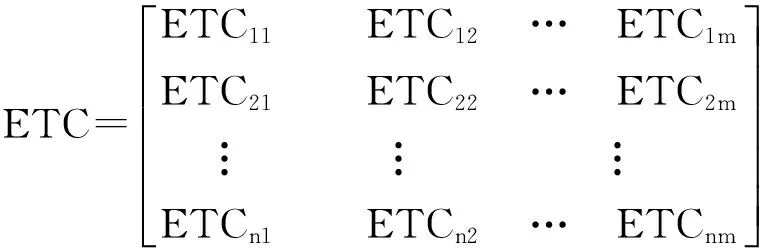
3 实验与分析


4 结束语
猜你喜欢
铁道通信信号(2020年10期)2020-02-07
北京航空航天大学学报(2019年9期)2019-10-26
成都信息工程大学学报(2019年3期)2019-09-25
三门峡职业技术学院学报(2019年1期)2019-06-27
制造技术与机床(2019年4期)2019-04-04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
现代防御技术(2016年1期)2016-06-01
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
