
基于优势度的序信息系统属性重要性度量
2015-03-14 09:50王利东李晓庆
海南热带海洋学院学报 2015年5期
李 敬,王利东,李晓庆
(大连海事大学 数学系, 辽宁 大连 116026)
基于优势度的序信息系统属性重要性度量
李 敬,王利东,李晓庆
(大连海事大学 数学系, 辽宁 大连 116026)
属性约简在某种指标下最大限度保留信息系统的主要信息,使所获得的知识简化,其有利于获取有效的决策规则.针对序信息系统约简问题,本文构建了两种基于优势度的属性重要性度量方法及探索其相关数学性质,并将其应用于企业发展能力信息系统获得属性约简集合.实例分析表明了所构建方法能有效地利用数据的分布信息来反映出对象之间的差别程度,更客观体现出属性的重要程度.
序信息系统; 优势度; 属性约简
0引言
在实际生活中,描述物体需要使用多个特征指标,相对而言它们并非同等重要的,甚至有些特征是可以忽略的.这种现象在信息系统里称为属性约简,它可以确定属性子集且保持该系统的分类能力不变,从而简化信息系统.在实际问题进行决策的过程,如教学质量评估,本科专业评估和风险分析等所面对的信息系统的属性值往往是有序的.因此,研究序信息系统的属性重要性度量及属性约简具有实际意义.
属性重要度函数的构建对于属性约简是至关重要的,设计高效的属性重要度函数利于知识获取[1].经典的粗糙集理论在属性重要性度量和知识获取等问题研究中发挥着重要角色,但它以等价关系为根基,具有一定的局限性.
Greco S, Matarazzo B, Slowinski R等用优势关系替换经典粗糙集的不可分辨关系(等价关系),提出了优势粗糙集理论(DRSA)[2].国内外学者利用该理论研究序信息系统的属性约简问题,并取得了丰富的研究成果[3-6].在文献[7]中,徐伟华和张文修从矩阵角度给出了序决策信息系统约简算法.针对不协调序决策信息系统,徐伟华和张文修利用优势关系对条件属性和决策属性进行划分,并先后提出分配和近似约简的方法及相关判定定理[8]、分布约简方法及相关判定定理[9].为减少决策规则不确定性,方连花和李克典将文献[10]中决策属性划分改为基于等价关系划分,并建立相应的基于等价-优势关系的约简方法.袁修久和何华灿先后建立了不协调决策表的上、下近似约简方法[11-12],并指出了它们与经典粗糙集约简方法之间的不同之处.陈娟、王国胤和胡军在不协调序信息系统中提出正域约简的概念,并给出基于属性重要性的正域约简算法[13].莫京兰、吕跃进和李金海从矩阵角度给出基于β优势关系的近似约简的概念及约简方法[14].近来,扩展形式序信息系统的属性约简已引起广泛关注.王虹和石慧娟将分配约简方法扩展到区间型不协调序决策信息系统属性约简中[15].吴磊、杨善林和郭庆给出了直觉模糊数型决策系统的属性约简方法[16].杨习贝,张艳芹等分别研究了不完备区间型序信息系统和直觉模糊序信息系统上粗糙集模型及约简问题[17-18].徐伟华详细分析了序信息系统与粗糙集研究现状并指出未来发展的几个方向[19].
基于优势关系的粗糙集理论(DRSA)在一定程度上弥补了经典粗糙集的不足[2].但其仅考虑对象之间的偏序关系,没有体现对象间的差别程度.例如在下文表3.1.1中,若将对象x5在可持续增长率指标上的值改为10,可发现它不会影响优势粗糙集中类的变化,因此不能有效体现出数据分布特性.如果充分考虑样本(方案)在指标上的序关系以及相差程度,可以更好地利用数据包含着的客观信息.本文在基于优势粗糙集等相关研究基础上,建立基于优势度和排序熵的序信息系统属性重要性度量及约简方法.
1 基础知识
本章将介绍有关序信息系统的基本概念.
1.1序信息系统
定义1.1.1[20]信息系统I≤=(U,AT,F)是一个三元集合,其中,U={x1,x2,…,xm}为论域,AT={a1,a2,…,an}为属性集,F:{fl∶U→V1(l≤n)}为对象与属性的关系集,Vl为属性al的有限值域.称≥a为相对于属性a具有优势,x≥ay表示x在a上的值大于或等于y.x≥Ay⟺∀a∈AT,x≥ay.
信息系统中属性值间具有优势关系时,称信息系统为序信息系统.
1.2 优势关系与优势类
定义1.2.1[2]I≤=(U,AT,F)为一个序信息系统,Vl为属性al的有限值域,且为偏序的.对于任意的属性子集B⊆AT,记

(1)

(2)
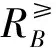


(3)

(4)

2 属性重要性度量及约简
属性约简的一个关键问题是建立属性质量的评价函数.粗糙集、优势粗糙集和模糊粗糙集使用依赖性函数评价属性的重要性.本节在文献[20-22]基础上,采用保序原则进行评价属性的重要性和属性约简.
2.1基于优势度的属性重要性度量
注意到公理模糊集[21]中的隶属测度能有效反映出样本之间的差别程度,故将其引入作为样本的优势度计算公式,进一步确定属性的重要性的度量.
定义2.1.1[21]信息系统I≤=(U,AT,F)是一个序信息系统,定义优势度公式为

(5)
由定义2.1.1直接可以得到以下结论:
性质2.1.1 设I≤=(U,AT,F)为序信息系统.R≤,S≤为I≤的两个劣势关系,则有:

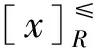
依据式(5)计算优势度及删除属性后的优势度,进而引入属性重要性定义.

依据属性的重要性可以进一步进行属性约简.
2.2基于排序熵的属性重要性度量及属性约简
信息熵表征了信源整体的统计特征,是总体的平均不确定性的量度,也是确定权重的一个重要工具.为反应出基于优势关系的有序分类的不确定性,胡清华等学者定义了升序和降序排序熵[6,20].
定义2.2.1[6,20]设I≤=(U,AT,F)为序信息系统,信息系统就属性B而言的升序排序熵定义为:
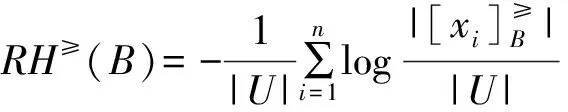
以及降序排序熵定义为:

.
例如在表2.2.1中,可以看出在属性a1下,数据无差别,可提供的对象间差别信息少,因此升序排序熵为0.而在属性a2下,差别明显,体现在此升序排序熵为1.1428.可见,升序/降序排序熵反映了对象集根据属性提供的信息进行排序的一致性程度.
本章结合定义2.1.1, 2.2.1,定义新的向下降序排序熵:
定义2.2.2I≤=(U,AT,F)是一个序信息系统,定义如下向下降序熵为:

根据定义2.2.2可推得如下性质:
性质2.2.1 设I≤=(U,AT,F)为序信息系统.R≤,S≤为I≤的优势关系.若|U/R≤|=|U/S≤|,则RH≤(R≤)=RH≤(S≤).
性质2.2.2 设I≤=(U,AT,F)为序信息系统.R≤,S≤为I≤的两个优势关系,若R≤≤S≤,则RH≤(R≤)≤RH≤(S≤).
定义2.2.3 定义属性a相对于属性集B的重要性:
SigB(a)=RH≤(B-a)-RH≤(B) .
SigB(a)越大,说明a相对于属性集B的重要性越大.属性依据属性的重要性可以进一步进行属性约简和权重确定.
3 基于优势度的属性约简
在企业发展能力和专业评估等领域综合评价中,各方案在某一评价指标上的值之间常常都存在偏序关系,即评价信息表可以形成序信息表.指标权重是确定影响因素的重要程度,与之相随的一个问题是属性约简.本文以企业发展能力综合评价为例,采用公式(5)考虑样本(方案)在指标上的序关系以及相差程度,并结合优势度和排序熵度量属性的重要性.
3.1 实例简介
本节采用文献[22]所选取的反映企业发展能力的信息表,如表3.1.1所示,其包括四项评价指标AT={a1,a2,a3,a4},六家参评企业U={x1,x2,x3,x4,x5,x6}.评价指标均是效益型指标,每个企业关于评价指标的数值分别用3,2,1表示,即指标取值越大,表明企业的在该项指标上发展能力越好.根据定义2.1.1-2.1.2及定义2.2.1-2.1.3,可得到各个指标的重要性,见表3.1.2.
从表3.1.2可以看出删除a2后变化性最小,即a2的重要性最小,约简集可定义为{a1,a3,a4}.实验结果和文献[22]结论一致,属性重要性最小.所构建的两类方法能够反映对象集根据属性提供的信息进行排序的一致性程度.例如在表3.1.1中将f(x5,a3)=3改为f(x5,a3)=10,这种变化对文献[22]的属性约简过程没有影响,但它会体现在优势度上.若在表3.1.1中将f(x2,a3)=2改为f(x2,a3)=2.01,这种变化对文献[22]的属性约简过程可产生影响,利用优势度可减少结果易于受到噪声影响.
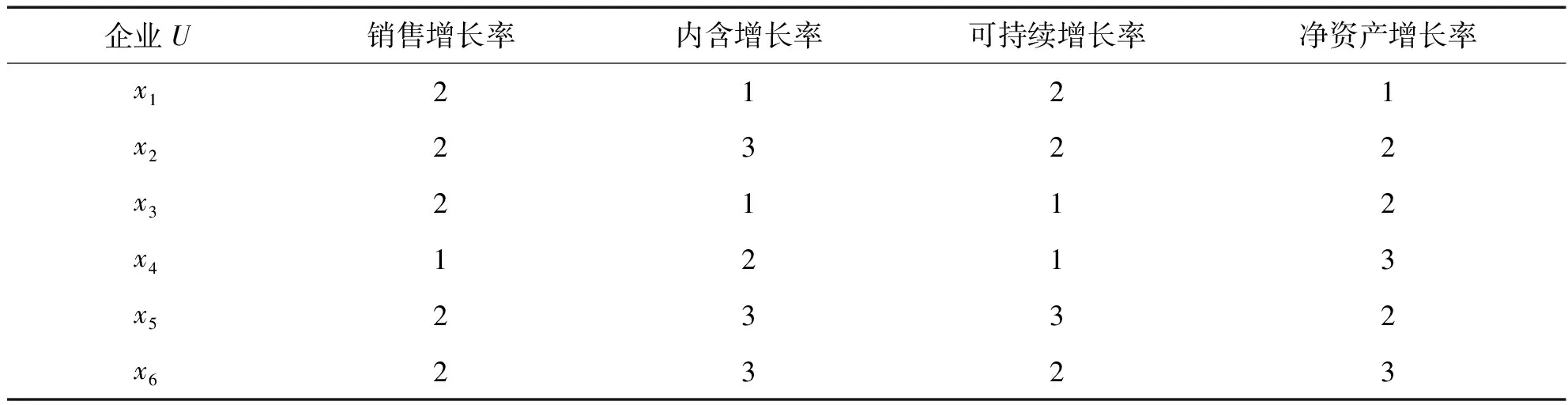
表3.1.1 企业发展能力信息表[22]

表3.1.2 指标重要性结果
4 结论
本文在结合优势度和排序熵的基础上,构建了基于优势度的属性重要性度量和基于排序熵的属性重要性度量及属性约简方法.同时,对这两种度量方法的一些数学性质加以研究.此外,将所构建方法应用于企业发展能力信息评价中,获得每个属性的重要性及属性约简集.该方法有效地利用数据的分布信息反映出对象之间的差别程度,是文献[22]的属性约简的一个推广.
[1]杨习贝,戚湧,宋晓宁,祁云嵩,杨静宇.决策单调约简的启示[J].琼州学院学报, 2014, 21(5):17-25.
[2]GrecoS,MatarazzoB,SlowinskiR.Roughsetstheoryformulti-criteriadecisionanalysis[J].EuropeanJournalofOperationalResearch, 2001, 129: 1-47.
[3]菅利荣,刘思峰,方志耕等.基于优势粗糙集的教学研究型大学学科建设绩效评价[J].管理工程学报,2007, 21(3): 132-136.
[4]邓维斌,王国胤.基于优势关系粗糙集的电信客户价值评价方法[J].计算机应用研究, 2015, 32(6):1634-1636.
[5]刘力凯,王国胤,邓维斌.优势关系粗糙集的移动用户换机预测方法[J].小型微型计算机系统, 2015, 36: 1789-1794.
[6]胡清华,于达仁.应用粗糙计算[M].北京: 科学出版社, 2012.
[7]徐伟华,张文修.基于优势关系下不协调目标信息系统的知识约简[J].计算机科学, 2006, 33(2):182-184.
[8]徐伟华,张文修.基于优势关系下信息系统分配约简的矩阵算法[J].计算机工程, 2007, 33(14):182-184.
[9]徐伟华,张文修.基于优势关系下不协调目标信息系统的分布约简[J].模糊系统与数学, 2007, 21(4):124-131.
[10]方连花,李克典.基于优势-等价关系下不协调目标信息系统的分布约简[J].模糊系统与数学, 2013, 27(3):182-189.
[11]袁修久,何华灿.优势关系下的相容约简和下近似约简[J].西北工业大学学报(自然科学版), 2006, 24(5):604-608.
[12]袁修久,何华灿.优势关系下广义决策约简和上近似约简[J].计算机工程与应用, 2006, 42(10):4-7.
[13]陈娟,王国胤,胡军.优势关系下不协调信息系统的正域约简[J].计算机科学, 2008, 35(13):216-218.
[14]莫京兰,吕跃进,李金海.不完备序信息系统的模型扩展及其属性约简[J].南京大学学报(自然科学版),2015, 51(2): 430-437.
[15]王虹,石慧娟.基于优势关系的不协调区间值目标信息系统的分配约简[J].模糊系统与数学, 2014, 28(4):152-158.
[16]吴磊,杨善林,郭庆.优势关系下直觉模糊目标信息系统的上近似约简[J].模式识别与人工智能, 2014, 27(4):300-304.
[17]YangXB,YuDJ,YangJY,WeiLH.Dominance-basedroughsetapproachtoincompleteinterval-valuedinformationsystem[J].Data&KnowledgeEngineering, 2009, 68(11):1331-1347.
[18]ZhangYQ,YangXB.Intuitionisticfuzzydominance-basedroughsetapproach:modelandattributereductions[J].JournalofSoftware, 2012, 7(3):551-563.
[19]徐伟华.序信息系统与粗糙集介绍及研究综述[J].琼州学院学报, 2014, 21(5):12-16.
[20]HuQH,GuoMZ,YuDR,LiuJF.Informationentropyforordinalclassification[J].ScienceinChinaSeriesF:InformationSciences, 2010, 53(6):1188-1200.
[21]LiuXD,PedryczW.Axiomaticfuzzysettheoryanditsapplications[M].Heidelberg:Springer, 2009.
[22]吕跃进,张旭娜,韦碧鹏.基于优势关系粗糙集的模糊综合评价的权重确定[J].统计与决策, 2011, 20:1002-6487.
MeasureofAttributeImportanceBasedonDominantDegreefortheOrderedInformationSystem
LI Jing, WANG Li-dong, LI Xiao-qing
(Department of Mathematics, Dalian Maritime University, Dalian Liaoning, 116026, China)
Attribute reduction can preserve main information for the information system with respect to some indexes, from which some simplified knowledge can be obtained for decision makers. In order to address the attribute reduction in ordered information system, two methods of attribute reduction are proposed based on dominance degree. In addition, the mathematical properties of dominance degree and dominance sort entropy are studied in the current research. The proposed methods effectively reflect the degree of difference between objects by using dominance degree. An example is experimented on the information system of business development and shows that the proposed method is effective for attribute reduction.
ordered information system; dominance degree; attribute reduction
2015-09-07
国家自然科学基金(61203283);辽宁省自然科学基金(2014025004);中央高校基本科研业务项目(3132014036,3132014324)
李敬(1992-), 女, 山东济南人, 大连海事大学数学系2015级应用数学硕士研究生,研究方向为多属性决策,数据处理与信息提取.
王利东(1979-), 男,辽宁喀左人, 大连海事大学数学系副教授,博士,研究方向为粒计算,多属性决策.
TP18,O236
A
1008-6722(2015) 05-0017-05
10.13307/j.issn.1008-6722.2015.05.05
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
科教导刊·电子版(2021年6期)2021-05-06
数学年刊A辑(中文版)(2019年3期)2019-10-08
成都信息工程大学学报(2019年2期)2019-08-28
测控技术(2018年11期)2018-12-07
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
