
语音识别的SVM模型选择分析
2015-12-08 13:10赵海君
电脑知识与技术 2015年25期
赵海君

摘要:针对现有SVM模型选择方法中,人为指定核函数类型可能使得SVM性能难以达到最优化,分析了现有核函数类型对语音分类率的影响。并把K-交叉验证思想与网格搜索法、遗传算法、粒子群优化算法相结合进行参数寻优,应用到语音识别中。并对语音特征数据处理问题进行了研究。分析结果表明[-1,1]内对语音特征参数归一化,且采用径向基核函数、网格搜索法对参数寻优,能达到最优的语音分类率。
关键词:语音识别;语音特征参数;SVM(支持向量机);模型选择;归一化;交叉验证
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2015)25-0133-02
Speaker Recognition Model Selection Analysis Based on SVM
ZHAO Hai-jun
(College of Information, Shanxi Agricultural University, Taigu 030800, China)
Abstract: For existing SVM model selection method, specified the type of man-made kernel may make it difficult to optimize the performance of SVM, it analyses the impact of existing kernel type to speech classification. Combining K-fold cross validation with grid searching and GA and PSO are used parameter optimization in speech recognition. Also it studies speech characteristic processing problem .Analysis results show that the normalization of [-1, 1] and using Radial Basis Function(RBF) and grid searching can achieve the best speech classification rate.
Key words: speaker recognition; voice feature parameter; Support Vector Machine(SVM); model selection; normalization; cross validation
1概述
语音识别(speaker recognition,SR)技术(也成声纹识别技术),是生物认证技术的一种,是一项根据语音波形中反映说话人生理和行为特征的语音参数,自动识别说话人身份的技术[1]。语音识别技术的核心是通过预先录入说话人的样本,提取说话人独一无二的语音特征并保存在数据库中,应用时将待验证的声音和数据库中的特征进行匹配,从而决定说话人的身份。语音识别技术以其独特的方便性、经济性和准确性受到世人瞩目。
在语音识别中最常用的特征参数是基于声道的LPCC、运用基于等响度曲线和临界带的PLP以及基于听觉特性的MFCC[2-3],本文选取MFCC特征进行仿真实验。首先分析了对特征参数的预处理问题,接着将现有的核函数类型对语音分类率的影响作了分析,然后还对分类器训练中惩罚因子c和核函数参数[γ]进行优化,从而来提高语音分类率。
2支持向量机原理
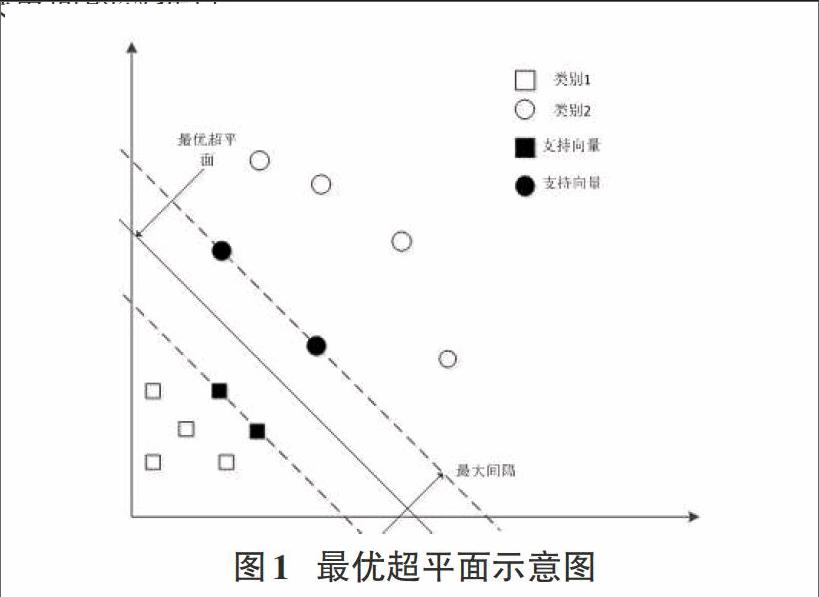
对于非线性可分问题,SVM的基本思想是:利用核函数将输入特征的样本点映射到高维特征空间中,数据被超平面分割,在高维空间中变得线性可分,转化为线性可分模式,然后再对应于低维空间的非线性分类[4]。
对于线性可分模式,考虑训练样本[xi,yiNi=1],其中[xi]是输入模式的第[i]个样本,[yi∈-1,+1]。设用于分离的超平面:[w?x+b=0]其中w是超平面的法向量,b是超平面的常数项。SVM的主要思想是建立一个超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化。即最优分类超平面等价于求最大间隔。满足下面条件的特殊数据点[xi,yi]称为支持向量:[w?xi+b=-1,yi=-1]or[w?xi+b=1,yi=1]。支持向量是那些最靠近决策面的数据点。
3实验结果与分析
Timit Database语音数据库中,选取6个不同男性的声音,都是说的相同的话。对每个语句提取相应的MFCC参数,且选取前400组变换参数数据,其中350组样本数据作为实验训练样本,50组样本数据作为实验测试样本。识别模型为SVM支持向量机;MFCC特征维数为20;mel滤波器的组数为24;测试人数:2、4、6人;测试次数:每次识别运行10次。
实验1
本实验部分采用SVM默认下径向基核函数,用不同归一化方式[5]作对比,最后测试集预测分类准确率如表1所示:
表1 不同归一化方式对比表
从表1中数据可以看出,需要对原始数据先进行归一化处理,才能提高最后的分类准确率,而且不同的归一化方式对最后的准确率也会有一定影响。[-1,1]归一化处理下2、4、6人的语音分类率比[0,1]归一化处理的分别提高了4.84%、6.29%、9.03%。
实验2
对于SVM中不同的核函数[6-8],测试集预测分类率的对比(统一采用[-1,1]归一化)如表2所列:
4结束语
本文采用SVM方法用于语音分类,对提取的MFCC参数是否数据预处理进行了分析,并且对SVM的两个关键要素:核函数、核参数问题进行了分析。由于语音特征参数的训练样本参数多、维数高,在样本特征空间上分布广,因此选择径向基核函数较为合适。本文把K-CV与网格搜索法、GA、PSO结合比较,也说明了网格搜索法运用到高维数、大样本的语音数据中有明显的优势。
参考文献:
[1] 吴朝晖,杨莹春.说话人识别模型与方法[M].北京:清华大学出版社,2009.
[2] 余建潮,张瑞林.基于MFCC和LPCC的说话人识别[J]. 计算机工程与设计,2009,30(5):1189-1191.
[3] CAO H,GAO L M.Research on sound fields generated by laster-induced liquid breakdown[J].Optica Applicata,2010,40(4):897-907.
[4] 李书玲,刘蓉,刘红,等.基于改进型SVM算法的语音情感识别[J].计算机应用,2013,33(7):1938-1941.
[5] 史峰,王辉,郁磊,胡斐,等.MATLAB智能算法30个案例分析[M].北京:北京航空航天大学出版社,2010,112-132.
[6] 陈刚,王宏琦,孙显.基于核函数原型和自适应遗传算法的SVM模型选择方法[J].中国科学院研究生院学报,2012,29(1):62-69.
[7] 刘华福.支持向量机Mercer核的若干性质[J].北京联合大学学报,2005,19(1):45-56.
[8] 李盼池,许少华.支持向量机在模式识别中的核函数特性分析[J].计算机工程与设计,2005,26(2):302-304.
猜你喜欢
中国新通信(2016年21期)2017-01-06
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年12期)2016-06-14
物联网技术(2015年9期)2015-09-22
物联网技术(2015年3期)2015-03-31
