
从文献请求传递数据中科学挖掘读者需求
2015-12-21 03:05朱克亮,王一兵,汤雪唯等
大学图书情报学刊 2015年4期
从文献请求传递数据中科学挖掘读者需求
朱克亮,王一兵,汤雪唯,吴攀,陈巧莲
(安徽理工大学,淮南 232001 )
摘要:文章提出以读者在区域资源共享平台中请求文献传递的日志记录为基础,辅以页面信息采集程序,再将数据整理及统计分析,科学地获得读者真实需求,为采购数字资源提供科学的数据支撑。
关键词:知识发现平台;数字资源采购;需求分析;文献传递日志;数据挖掘
中图分类号:G252.0
基金项目:2013年度安徽省高等学校图书情报工作委员会
作者简介:朱克亮,男,副研究馆员。
收稿日期:2015-01-20
Scientifically mining the readers’ needs from the data deliveries requested
ZHU Ke-liang, WANG Yi-bing, TANG Xue-wei, WU Pan, CHEN Qiao-lian
(Anhui University of Science and Technology, Huainan232001, China)
Abstract:Based on the daily records of document transfer requested by readers, the library should also pay attention to the online acquisition program, make a statistical analysis of the data collected, get rid of the coarse and obtain the true needs of readers so as to provide scientific data support for the purchase of digital resources.
Key words: knowledge discovery platform; purchase of digital resources; demand analysis; joural of document transfer; data mining
1问题的提出
各图书馆都希望引进使用频率高、受读者欢迎的数字资源,目前各馆的普遍做法有如下几种:一是图书馆根据本校学科建设情况,对欲引进数字资源的价格、使用口碑等方面的情况进行综合分析,自己决定购买意向;二是召开资源需求座谈会,对需求意见相对集中的某些数字资源,由图书馆决定购买意向;三是发放问卷调查表,综合评估需求比较集中的数字资源,若符合订购要求,则予以考虑引进[1]。以上三种订购数字资源的方法各有其优缺点,但都不能全面反映读者的真实需求,在大数据时代,图书馆如何用科学的方法挖掘出读者对数字化资源的真实需求,是当前各高校图书馆亟待解决的问题,本文就这个问题展开讨论。
2基于文献请求传递数据支撑的读者需求挖掘
2.1 读者文献传递需求信息挖掘的意义
区域共享与文献传递知识发现平台已在大多数图书馆应用,该知识发现平台以其全面性、方便性、易用性深受广大读者欢迎。目前,读者大都习惯了在知识发现平台中检索所需的文献资源,如果本馆所购的资源存在,则直接下载阅读,如果本馆所购资源中不存在,则申请文献传递。
从现行读者获取数字资源的思路及方式中可以看出,只有本馆没有购买的数字资源,读者才会在知识发现平台中申请文献传递,也就是说,读者申请文献传递的数字资源,大都是该图书馆缺失的数字资源,也是读者真实需求的客观反映。如果把一个学校在一个时间周期内读者申请文献传递的信息全部汇集起来,用数学方法加以分析,就可以从中挖掘出许多有价值的信息,为图书馆以后订购数字化资源提供可靠的数据支撑。
2.2 读者请求文献传递数据获取的模式
由于读者是在个人电脑上使用知识发现平台进行文献传递的,地理上有较大的分散性,时间上也是分散的,要想得到读者在平台中申请文献传递的详细数据信息并不容易。目前主要的获取模式有两种:一是在校园网核心交换机出口上截取包数据流,对指定IP地址的数据包进行分析,得出需要的信息。其优点是数据来源准确,时效性好;缺点是包数据流的信息量庞大,分析工作量大,还需要购买第三方的审计软件,费用较高。二是在知识发现服务平台的数据库中获取本校读者申请文献传递的信息。其优点是信息处理量相对第一种方法要小得多,数据来源也是准确的[3]。其缺点是数据来源需要与数据商协调,数据中有些字段并不能完全满足对数据分析的需求。
2.3 文献传递数据的加工及整理
准确获取本校单位时间内在该知识发现平台中请求传递的详细信息,挖掘出题名与源数据库名之间的关联,整理出单位时间内本校读者向共享平台请求数据资源的分布与频度,形成以饼图、折线图、柱状图等多种图表为主的分析研究报告,为图书馆下年订购数字化资源提供决策支持。
经过与安徽省区域共享与文献传递知识发现平台管理员协调,从后台数据库中得到安徽理工大学2013年读者请求文献传递全部数据,其数据的字段见表1所示:

表1 读者请求数据字段
表1的字段中,其“标题”字段告诉我们读者请求传递了什么文献;“文献类型”字段告诉我们传递的文献中期刊论文、学位论文、会议论文、专利、标准等文献所占的比例,对我们分类型订购数字资源有指导意义;“文献语种”字段告诉我们在传递的文献中,中文文献、外文文献所占的比例,对我们在订购数字资源时文种的选择也具有参考价值。“读者单位名称”字段都是统一的安徽理工大学,其他字段如:提交时间,回复时间,IP,用户评价等,并不是我们所关心的字段。
从后台数据库中得到的数据中字段虽然很多,但唯独没有文献出处字段,而单位时间内被请求的数字资源频次及其出处正是我们所重点关注的。如何由文献标题得到文献出处呢?在知识发现平台中,如果在标题字段中输入检索词检索后,其检索结果页面中都会存在文献出处的信息,只要从该页面中提取该信息,就可以实现由文献标题到文献出处的一一关联。但是由于一个学校一年内读者请求文献传递的数据较为可观,靠人工完成关联显然是不现实的,所以只能考虑编写数据采集应用程序来实现。
用通用的PHP、Java或C#等编程软件编写数据采集应用程序,进行Web页面的信息采集。先生成一标题列表文件,这个列表文件仅由 “标题”字段组成,我们把2013年我校读者请求文献传递全部数据中的“标题”字段下所有记录拷贝到列表文件的“标题”字段中。由数据采集程序自动打开区域共享与文献传递知识发现平台,数据采集程序用列表文件中的“标题”字段中的记录逐条做检索,在返回页面中,把文献“标题”与“文献出处”信息一一对应的写入新的文件中,完成全部由标题到文献出处的一一关联。
数据采集程序的主要代码如下所示:
Begin
if标题列表文件是否存在 then
rfp <- open(标题列表文件,r)
if rfp是否为真 then
wfp <- open(存放查询结果文件,w)
if wfp是否为真 then
do while eof(rfp)
keyword <- get(rfp->row())
textline <- get(seek(keyword))
if textline不为空 then
@fromline <- split(/出处:/, textline)
comefrom <- fromline[1]
write(wfp, keyword+comefrom)
else
write(wfp, keyword+"未找到")
end if
end do
close(wfp)
end if
close(rfp)
end if
end if
end
其程序流程图见图1。

图1 页面数据挖掘程序流程
2.4 文献传递数据结果处理与分析
我们从海量的全省文献传递数据中得到了安徽理工大学全校读者2013年在共享平台请求文献传递的基本数据,通过人工整理,删去对文献分析无用的字段及数据,并使用页面数据挖掘软件,实现了文献标题与文献出处相一一关联,再通过常用的数据统计分析软件(如Excel等),得出以下分析数据结果。
2013年全校读者在省共享平台中请求文献总数量为5408篇,其中中文文献请求量为4350篇,占文献请求总量的80.44%,外文文献请求量为1058篇,占文献请求总量的19.56%[4]。
由图2可以看出,该校请求文献传递的资源中,以中文数字资源为主,外文资源只有不到20%,其原因是近年来该校图书馆引进了一批如SD、SCI、EI、ACS、IEL 、ASCE、ASME等高质量的外文资源数据库,基本满足了本校读者的需求。

图2 请求资源中中文文献与外文文献所占比例
2013年,该校图书馆Elsevier-SD下载量达54463篇,Springer下载量达10366篇,EBSCO下载量达3520篇,IEL下载量达12022篇,10个主要外文数据库共下载资源量已10多万篇,有力地支撑了教学科研活动。
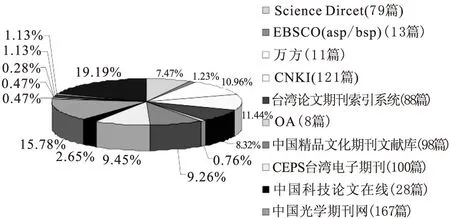
图3 外文资源各数据库比例
由图3分析如下:该校图书馆2007年以前的ScienceDirect资源没有购买,所以有79篇的请求量,数据说明SD中07年以前的资源使用量并不大,文献传递的方式完全可以满足读者的需求;EBSCO数据库属于已购资源,有13篇的文献请求量应属于多余请求,也可能是由于共享平台检索元数据不准确造成;台湾期刊论文索引系统、中国光学期刊网、CEPS台湾电子期刊和中国精品文化期刊文献库是本馆没有购买的电子资源,也有一定的文献传递请求量,请求数量各占外文资源总量的10%左右,由文献传递服务补充非常恰当[4]。万方和CNKI中有些纯英文的文献,该校也有10%左右的文献请求量,共享平台把这些文献归属于外文文献,其实它们属于中文资源数据库,对其有10%文献请求量的原因见以下分析。
由图4可知,在中文资源里CNKI、万方和维普三大中文数据库文献请求量最大,占整个文献请求量的90%以上。万方和CNKI都是该馆已购数据库,为什么还有60.62%的文献传递请求呢?通过分析得知,一部分为本馆没有购买的学位论文、会议论文、专利或标准等特种文献,一部分文献为不在本馆采购年限内的资源,还有一小部分请求为读者的多余请求。另外分析数据中显示,维普数据库的需求量占29.77%,而该资源本馆并未购买,这为本馆下一年度采购电子资源时提供了参考依据。

图4 中文资源各数据库比例

图5 各文献类型所占比例
由图5可知,在读者请求传递的文献类型中,期刊论文占文献传递总量的57.36%,成为主体;学位论文占32.21%,会议论文占5.27%,专利、标准和报纸占5.16%,学位论文占了约三分之一。由于该校是以理工科为主的大学,从本科生到博士后各个层次的读者都有,读者在毕业环节大量地参考期刊论文及学位论文,这两种类型的文献需求量大也在情理之中。以该校镜像资源为例,2013年度万方数据期刊论文下载量是233445篇次,学位论文下载量为44948篇次;CNKI期刊论文下载量是254899篇次,学位论文下载量为39686篇次。这些数据告诉我们,要重视期刊及学位论文数据库的采购[5]。
3结语
利用区域共享平台后台数据库提供的某单位读者在全年中请求文献传递的数据,辅以数据采集程序,再加上数据统计及分析,即可得到该单位读者需求的数据库名称、请求的频次等数据;利用统计分析软件,得出准确的读者需求,为以后采购新的数字资源提供科学的数据支持。
参考文献:
[1] 袁颖.图书馆电子资源读者需求分析与营销策略研究[J].商场现代化,2008,(35):118-119.
[2] 黄咏梅.读者需求分析中的数据挖掘技术[J].大学图书情报学刊,2006,24(04):48-50.
[3][4] 汤雪唯,朱克亮.基于用户需求文献传递利用现状及对策分析[J].中国科技信息,2014,(15):179-180.
[5] 邵晶,阎晓弟,周琴,张静.电子资源流量控制需求分析及其解决方案[J].大学图书馆学报,2012,(04):11-13.
(责任编辑:王靖雯)
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电力与能源(2017年6期)2017-05-14
中国中医药信息杂志(2016年7期)2016-12-01
科教导刊·电子版(2016年26期)2016-11-21
艺术科技(2016年9期)2016-11-18
科教导刊(2016年27期)2016-11-15
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
价值工程(2016年29期)2016-11-14
企业导报(2016年20期)2016-11-05
信息通信技术(2015年6期)2015-12-26
