
基于M-Copula-EGARCH-M-GED模型的相关风险度量及投资组合优化
2015-12-24 07:15宗钦原申建平
重庆理工大学学报(社会科学) 2015年2期
宗钦原,申建平
(重庆大学数学与统计学院,重庆 401331)
一、引言
相关风险度量和最优组合投资是投资者和资产管理者非常关心的问题。Copula函数是在1959年由Sklar[1]提出的,从90年代开始被应用在金融领域中,Rockinger等[2]提出可以运用 Copula函数建立多变量时间序列模型来替代向量GARCH模型;Patton[3]构造了马克-美元和日元-美元汇率的对数收益的二元 Copula模型,并与相应的BEKK模型作比较,结果表明Copula能更好地描述金融市场的相关关系;Romano[4]提出应用Copula处理金融的组合风险,同时利用多元函数极值,通过使用Monte Carlo方法来刻画市场风险;Hu[5]在Gumble、Clayton和FrankCopula函数的基础上,构建了一种新的Copula函数,即混合Copula函数(M-Copula),它是以上三种函数的线性组合,权重参数反应变量间的相关程度;韦艳华等[6]利用MCopula与GARCH相结合对金融市场相关程度和相关模式进行了研究;战雪丽等[7]用Copula-SV模型对投资组合资产的相关风险进行了分析;刘志东[8]运用Copula-GARCH-EVT模型研究了资产投资组合的最优投资比;史道济等[9]利用Copula函数对股票市场的VaR和最优投资组合进行了分析计算;包卫军等[10]利用多维的 t-Copula函数,对投资组合的CVaR进行了分析。这些研究表明Copula函数与条件异方差模型相结合是一种较为实用的金融量化分析方法,但存在三点不足:(1)为了减少实证中模型参数估计难度,当前的大部分论文对连接函数Copula的选择主要集中在Gumble、Clayton 和 FrankCopula 函数中的一种,而 Hu[5]的研究表明单一的Copula函数,对资产间的相关性描述是有局限性的;(2)对单个金融资产收益率的建模,主要以GARCH和EGARCH模型为主,但在现实中存在收益率的风险调整和风险补偿,而这两个模型不能刻画这一特征;(3)利用Copula和条件异方差模型进行最优组合计算之前,没有对VaR和CVaR的计算结果进行有效性检验。
因此,本文构建了能刻画风险溢价的EGARCH-M模型,对各单个资产收益率进行建模,选用M-Copula作为联合分布函数,用遗传算法对模型中参数进行计算,用基于GED分布的CVaR度量风险,最终利用Monte Carlo方法模拟求得不同投资比例和置信水平下的VaR和CVaR值,求出不同期望收益和置信水平下的最优组合投资权重。.实证表明,该建模方法效果良好,能有效地解决Copula函数与条件异方差模型相结合存在的不足。
(一)Copula函数的相关理论
定理 1.1(Sklar定理)[1]令 H(·,·)为具有边缘分布函数F(·)和G(·)的联合分布函数,那么存在一个 Copula函数 C(·,·),满足:
H(x,y)=C(F(x),G(y)) (1)若 F(·)和 G(·)连续,则 C(·,·)唯一确定;反之,若 F(·)和 G(·)为一元分布函数,C(·,·)为相应的Copula函数,那么由式(1)定义的函数H(·,·)是具有边缘分布F(·)和G(·)的联合分布函数。
Gumble、Clayton和FrankCopula函数是三类常用的二元阿基米德Copula函数,以下简要介绍他们在相关性分析中的应用特点。
(1)Gumble Copula 函数[11-12]的分布函数和密度函数分别为:

Gumble Copula函数的密度函数具有非对称性,其密度分布呈“J”字形,即上尾高,下尾低。分布函数对分布变量在分布上尾部的变化十分敏感,能够快速地捕捉到上尾相关的变化,而在分布的下尾部,由于变量是渐进独立的,函数对变量在分布下尾部的变化不敏感,难以捕捉到下尾的相关的变化。
(2)Clayton Copula 函数[11-12]的分布函数和密度函数分布为:

Clayton Copula的密度函数具有非对称性,其分布呈“L”字形,即上尾低,下尾高。故函数对变量在分布下尾的变化十分敏感,能够快速捕捉到下尾相关的变化,而在分布的上尾部,由于变量是渐进独立的,其上尾的变化不敏感,难以捕捉到上尾的相关的变化。
(3)Frank Copula 函数[11-12]可以描述变量间的负相关关系,它的分布函数和密度函数分布为:

其中,λ为相关参数,λ≠0。λ>0表示随机变量u、v正相关,λ→0表示随机变量u,v趋向于独立,λ>0表示随机变量u、v互相关。Frank Copula的密度分布呈“U”字形,具有对称性,因此无法捕捉到随机变量间非对称的相关关系。因此此函数只适合于描述具有对称相关结构的变量之间的相关关系。
(二)M-Copula函数的构建
用前面三者的线性组合来构建混合Copula函数,记作 M-Copula 函数[13],其表达式为:

其中 wC,wCl,wF≥0,wG+wCl+wF=1。对应的密度函数为:

MC3表示由三个Copula函数的线性组合组成的混合 Copula 函数,CG、CCl、CF分别表示 Gumble、Clayton 和 Frank Copula 函数,wC,wCl,wF为相应的Copula函数的权重系数。由式(2)、(4)、(6)、(8)可知,MC3包含六个参数,其中的相关参数向量(α,θ,λ)可以度量变量之间的相关程度,而线性组合的系数即权重参数向量(wG,wCl,wF)则反映变量之间的相关模式。
由此而见,可以用M-Copula来描述具有各种模式的变量之间的相关关系,与单个Copula函数相比更为灵活,能够描述具有复杂相关关系的事物,如金融市场之间的相关关系,因此,本文采用应用更为广泛、使用性也更强的M-Copula函数来描述深市和上市两者间的相关性。
二、M-Copula-EGARCH-M-GED模型的建立
(一)EGARCH-M模型的建立
Nelson[14]提出了指数 GARCH(EGARCH)模型,它能够充分捕获高频金融时间序列的尖峰厚尾性。EGARCH(p,q)模型形式为

这里,正的εt-i对对数波动率的贡献为αi+γi,而负的 εt-i对对数波动率的贡献为 αi- γi,参数γi表示 εt-i的杠杆效应。Engle、Lilien 和 Robins将基本的ARCH模型加以扩展,允许序列的均值不独立于条件方差,这类模型被称为ARCH-M模型,其基本观点是风险厌恶的投资者会在持有风险资产时要求相应的风险补偿。由于一项资产的风险可以用收益的方差来衡量,风险溢价就是收益条件方差的增函数[15]。将持有一项有风险资产所带来的超额收益描述为

其中,yt表示持有金融资产所带来的超额收益率;μt代表足以使风险厌恶的投资者持有金融资产的风险溢价;εt表示对金融资产收益率的不可预测的冲击。而持一项长期金融资产收益必须恰好等于风险溢价[16],也就是说

假设风险溢价是εt的条件方差的增函数,即,收益率的条件方差越大,使投资者持有长期资产所需的风险溢价就越大。即,如果σ2t是 εt的条件方差,则风险溢价就可以表述为

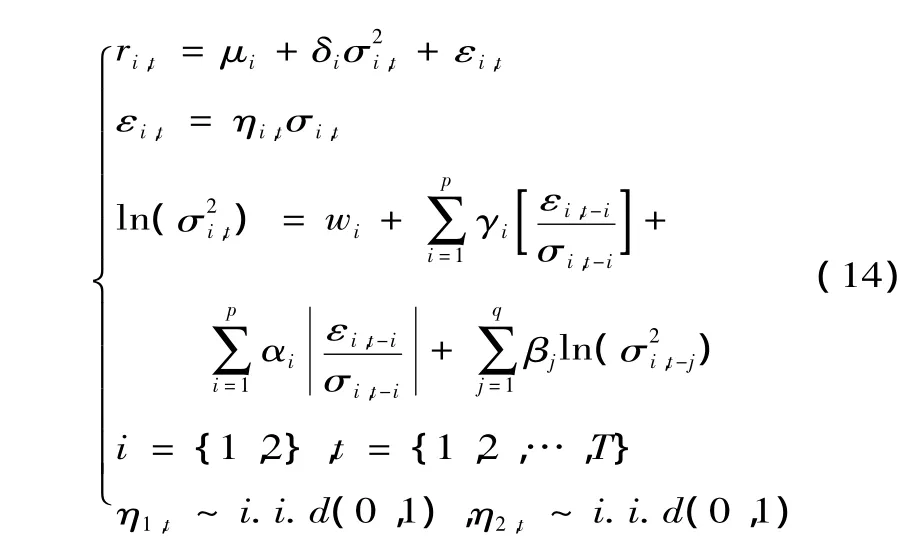
其中,μi为收益率的无条件期望值,系数δi反映了风险和收益之间的替代关系,即为风险溢价参数,εi.t为扰动为随时间变化的的条件方差,ηi,t为独立同分布的标准残差,αi为滞后参数,βj为方差参数。常用γi来说明金融市场中价格的非对称影响,当γi≠0时,说明各种干扰对价格的影响是非对称的;当γi<0时,说明价格波动受负外部冲击的影响大于受正外部冲击的影响;当γi>0时,正的外部冲击大于负的外部冲击,此种现象称之为“杠杆效应”。
(二)M-Copula-EGARCH-M-GED模型的建立
假设标准残差 ηt=(η1,t,η2,t)独立同分布,t=1,2,3,…,T,其联合分布函数为 G(z1,z2),边际分布函数分别为Fi(zi),i=1,2。为了更加灵活地刻画变量之间的相关关系及序列间的相关结构,采用M-Copula函数建模,建立M-Copula-EGARCHM-GED模型:

(三)M-Copula-EGARCH-M-GED模型的参数估计
上述模型(15)的参数估计包含两部分,一部分是EGARCH模型的参数,另一部分是M-Copula的相关参数,本文采用两步极大似然估计进行参数估计。首先EGARCH模型的参数通过极大似然估计去获得,相应得到标准误差 ηi,t的估计,然后对 M-Copula的相关参数采用遗传算法进行估计。
(四)M-Copula-EGARCH-M-GED模型检验
1.M-Copula函数的拟合度检验
Hu[5]在研究欧美外汇与股票市场相关关系时,采用一个服从χ2分布的M经验统计量来评价Copula函数的拟合优度,从而确定选定的Copula函数是否适合,其具体步骤如下。
令{ut}和{vt},t=1,2,…,T,都是服从 i.i.d.(0,1)均匀分布序列,它们是根据估计得到的边缘分布,对观测序列{xn}和{yn},t=1,2,…,T 进行概率积分变换之后得到。构造一个包含k×k个单元格的表格G,表格中处于第i行、第j列的单元格记作G(i,j),表示一个下界为,上界为的概率组合,其中k的选取可以根据样本的总数和观测点的总数来确定,既要保证有足够多的单元格用于模型拟合度的评价,又要保证每个单元格中都有足够的观测点。对于任何一点,若,则点(ut,vt)∈G(i,j),若用 Ai,j表示落在单元格 G(i,j)内的实际观测点个数,用Bi,j表示由Copula模型预测得到的落在单元格G(i,j)的点的个数,即预测频数,其中 i,j=1,2,…,k,则评价 Copula 函数拟合度的χ2检验统计量M可表示为
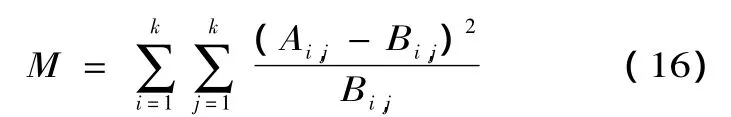
其中统计量M服从自由度为(k-1)2的χ2分布。
2.EGARCH-M模型的检验
为了验证 EGARCH-M的合理性,本文采用Ljung-Box Q检验法[17]对EGARCH-M模型的残差序列的相关性进行检验,利用K-S检验法[17]对EGARCH-M模型误差分布的拟合度进行检验。
三、基于M-Copula-EGARCH-M-GED模型的CVaR计算和投资组合优化
定义 2 CVaR(Conditional Value at Risk),即条件期望值,是继VaR之后产生的一种风险度量方法。根据 Rockafella[18]的定义,CVaR 是指在一定的置信水平下,某一资产或资产组合的损失超过VaR的尾部事件的期望值。CVaR用数学公式可以定义为
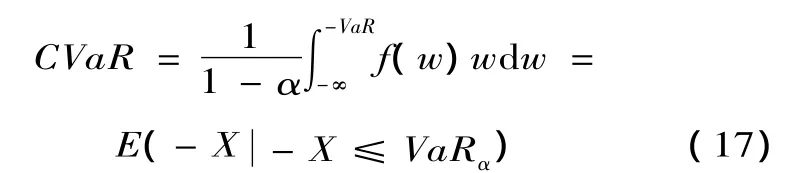
其中,α为置信水平;w为资产或资产组合的价值;f(w)为概率密度函数;VaRα为置信水平α的风险值。
利用M-Copula计算CVaR时,运用蒙特卡洛模拟需要构造二维的随机向量(X,Y)的随机数,若已知X,Y的边际分布函数F1(x)和F2(x),设其M-Copula函数为C(u,v),令 U=F1(x)并且 V=F2(x),则 U,V 都服从[0,1]上的均匀分布,由Copula函数的性质可知,在给定 U=u∈[0,1]为固定值时,随机变量 V对 u的条件分布函数在v∈[0,1]内是单调非减,若令k=Cu(v),则k服从[0,1]上的均匀分布,从而,我们可以得到随机数u和k,然后可以根据条件分布函数Cu(v)的反函数求得另一个随机数v=,这样就可以构造伪随机数对(u,v)。若金融资产为,就可得到随机数对(x,y),经过n次的模拟我们可得到n组模拟的收益率数对(xi,yi),i=1,2,…,n。由此我们获得了n个投资组合收益率的模拟数zi=wxi+(1-w)yi,再对{zi},i=1,2,…,n 由小到大进行排序,排序后的序列不妨设为{si},则在置信水平为1-α时:

(一)MonteCarlo模拟方法的算法步骤
本文进行MonteCarlo模拟计算VaR和CVaR,主要目的是验证所建模型对风险的预测能力,以便使相关风险最小化的最优投资组合比更具实在价值。
假设金融资产组合有两种资产X和Y,其收益率分别为x,y,组合中他们所占的比例分别为ω和1-ω,则资产的总收益率为ωx+(1-ω)y。
(1)根据我们选取的M-Copula函数做Monte-Carlo[19]模拟,模拟6 000 个数据,则我们得到6 000个随机数据对{(un,vn)},n=1,2,…,6 000,则(un,vn)~ C(u,v)。
(2)设两列标准残差序列的分布函数为标准GED 分布 Fη1和 Fη2,对每一组数据对(un,vn),我们令,可得到标准残差序列{(η1,n,η2,n)}。
(3)运用Eviews对EGARCH模型进行参数估计时可得到两个均值为和两列条件异方差序列,取1,…,T,我们有为6 000维的列向量i=1,2。
(4)由于我们所分析的收益率为对数收益率rt=lnpt-lnpt-1,用Rt=pt/pt-1-1来将其正常收益率形式,则Rt=ert-1,由此对第k次模拟我们可以得到正常的组合收益率Rt=ω(er1,k-1)+(1-ω)(er2,k-1),Rk也为 6 000 维的列向量。
(5)我们对(4)中Rk得到的6 000个数进行升序排列,则对置信度(1-α),我们取第6 000×α+1个数的绝对值即为相关置信度的VaR,对前6 000×α个数求算术平均值后为相应置信度的CVaR。
为了对所估算VaR和CVaR的值进行效果检验,本文选用DLC的返回检验,而DLC表示实际损失的期望值与CVaR的期望值之差的绝对值,定义如下:

(二)基于最小化CVaR建立最优投资组合模型
与VaR相比,CVaR满足次可加性、正齐次性、单调性及传递不变性,因此可以将CVaR作为风险指标[20],通过使用线性规划来进行优化;陈科燕[21]应用遗传算法对最优证劵投资组合模型进行研究;Rackafellar[20]利用CVaR作为风险指标来讨论资产组合最优化问题。考虑到中国市场的不允许卖空,因此在下面模型中我们加入了不允许卖空的限制。假设市场有n个风险资产,ri为投资期内风险资产i的收益率,wi为投资者在风险资产i上的投资比例。那么组合收益率可以表示为

以CVaR来测度投资风险,损益服从广义误差分布(GED)的CVaR的计算公式:

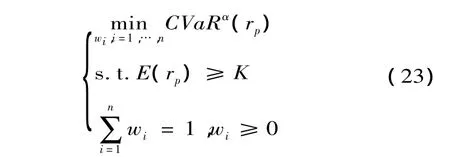
其中K>0,为投资者最低预期收入水平,β为置信度。
四、实证分析
(一)数据选取及其基本分析
本文选取样本数据为1998年9月28日到2012年3月23日中国股票市场上的上证综指与深证成指的收盘价,总样本数目为3 260个,通过公式rt=lnpt-lnpt-1计算两个指数的收益率。本文使用的软件为Eviews 6.0和MatlabR 2010a进行计算。
由图1和图2我们可以看出上证综指和深证成指的收益率具有波动率聚集性,与金融时间序列的特征吻合。另一方面从整体来看,两者收益率的波动性都很剧烈,说明对股票市场的风险管理的必要性。

图1 上证综指的收益率
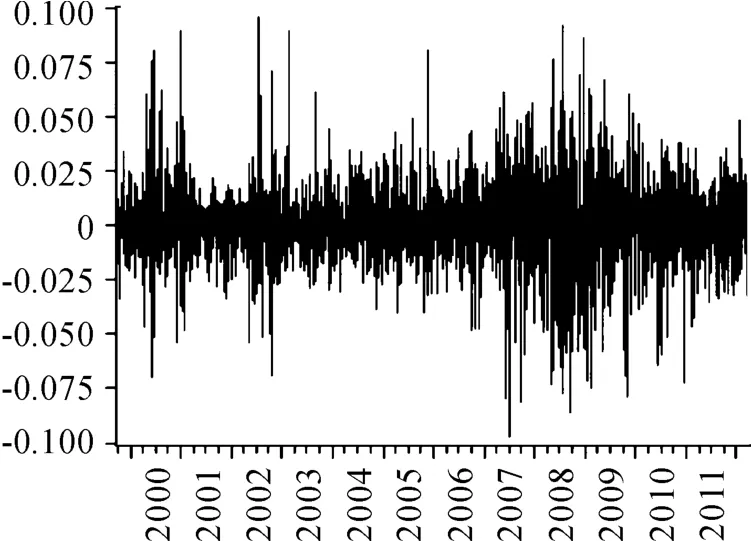
图2 深证成指的收益率
图3与图4分别为上证综指和深证成指对数收益率序列的基本统计量,可以看出上证综指与深证成指对数收益率序列具有以下特征:(1)样本峰度都远大于3,表明上证综指与深证成指对数收益率呈现明显的尖峰厚尾性;(2)Jarque-Bera正态统计量的值远大于临界值5.99,表明序列的分布不是正态分布;(3)波动具有聚集性和左偏性。
(二)EGARCH-M-GED模型参数估计
使用EGARCH-M-GED模型对两个指数收益率序列的边缘分布进行建模,其残差服从GED(广义误差分布),其模型的估计结果见表1、表2。

图3 上证综指收益率序列的基本统计量图

图4 深证成指收益率序列的基本统计量图
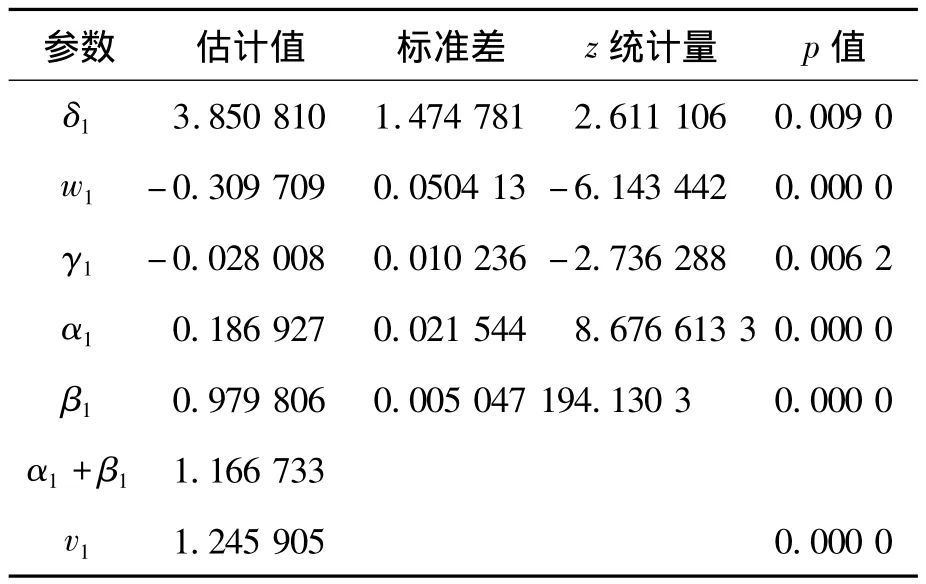
表1 上证综指收益率序列参数估计结果

表2 深证成指收益率序列参数估计结果
由表1和表2知,(1)γi都小于0,在上证综指中(表1)为 -0.028 008,深证成指中(表2)为-0.019 015,而且都是显著的,这也说明了两市中都存在杠杆效应,即坏消息引起的波动要比同等大小的好消息引起的波动要大;(2)模型估计αi均大于0,说明股市波动呈现集聚现象,过去的扰动对未来的波动有着正面的影响,较大幅度的波动后面紧跟着较大幅度的波动,股市参与者的投机性较强;(3)αi+βi都稍微大于1,则衰减速度越慢,波动的持续性越强,说明在模型下的当前信息对预测未来的条件方差都很重要;(4)沪深两市均值方程中的条件方差项GARCH的系数估计分别为3.850 810和5.048 627,而且都是显著的,这反应了收益与风险正相关,说明收益有正的风险溢价,深圳股市的风险溢价要高于上海,深圳股市的投资者更加厌恶风险,要求更高的风险补偿。
标准化残差{ηi,t}的Ljung-Box统计量为统计量为Q(10)=11.38,p值为0.33。因此,在5%的显著水平下,式(14)的EGARCH-M模型能充分地描述给定数据的条件异方差性。
(三)M-copula函数的参数估计
利用EGARCH-M-GED模型中得到的两个标准残差序列对混合Copula函数的参数进行极大似然估计,估计方法是遗传算法[22],在 MatlabR 2010a环境中编程完成。如表3所示。
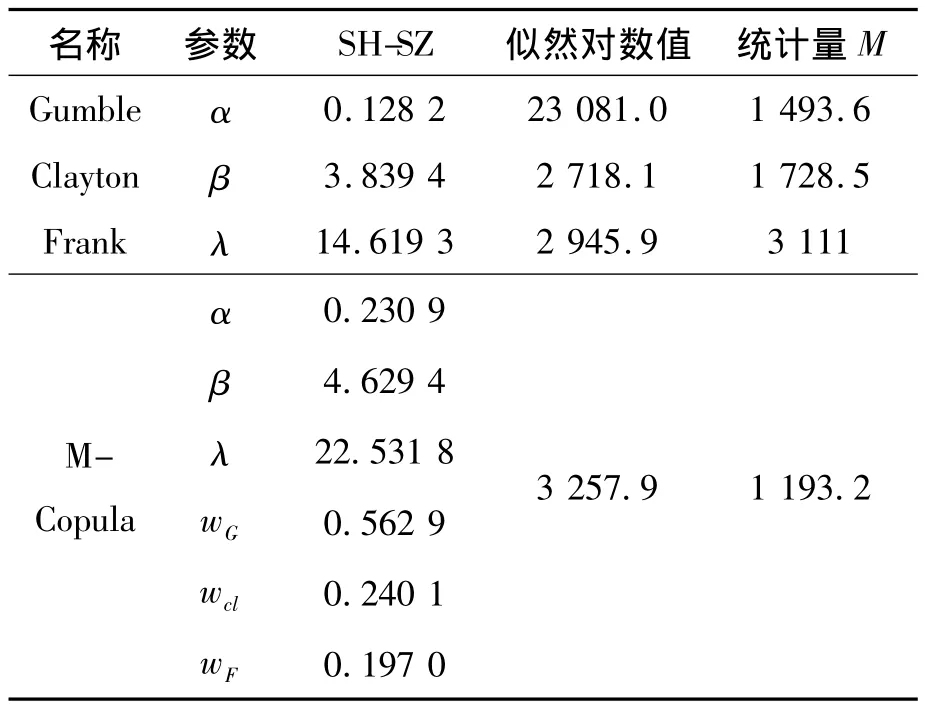
表3 Copula函数的参数估计结果
拟合统计量M的值说明了:copula函数选取的不同,对两个市场指数收益率相关程度与相关模式的刻画能力相差非常大,M-copula函数对样本的拟合度是最好的,其次就是Gumble copula函数,剩下的两个copula函数拟合度相对较差。
比较图5、图6、图7、图8可知,GumbleCopula函数分布低估下尾的相关程度,明显高估了上尾的相关程度;ClaytonCopula函数分布明显低估上尾的相关程度;和FrankCopula函数分布不仅低估上下尾相关程度,而且不能反映两个市场的非对称的相关模式;M-copula的分布函数最接近经验联合分布,能够比较全面和准确地捕捉各个时期上海和深圳股票市场之间相关程度变化,且能够正确地反映两个市场之间非对称的相关模式。
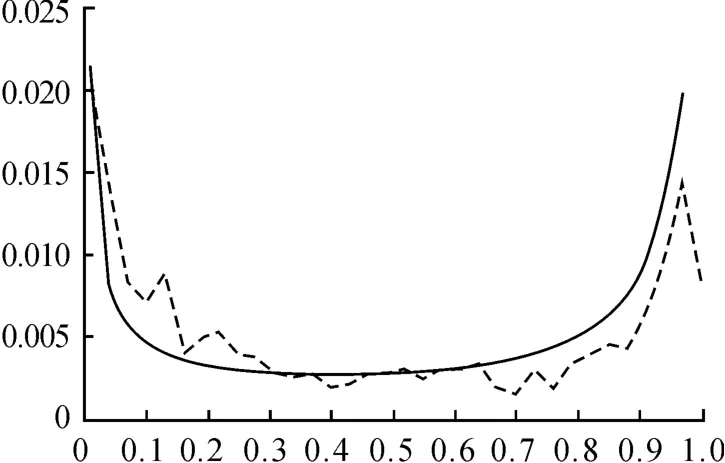
图5 Gumble

图6 Clayton

图7 Frank

图8 M-Copula
以上为经验联合分布和4类Copula函数分布在u=v处的频率分布图(实线指Copula函数分布,虚线指经验联合分布)
(四)VaR和CVaR的Monte Carlo模拟计算及分析
图9为用历史数据通过模型拟合而成的上证综指和深证成指的相关离散点图,图10为通过模型对两个市场的T+1时刻预测的6 000个数据的离散点图,两图说明模型能对未来的两市场的相关性变动进行合理正确的预测。下面我们将对历史数据的风险值和模型预测的风险进行比较,以便说明本文所建模型对相关风险预测的准确性。
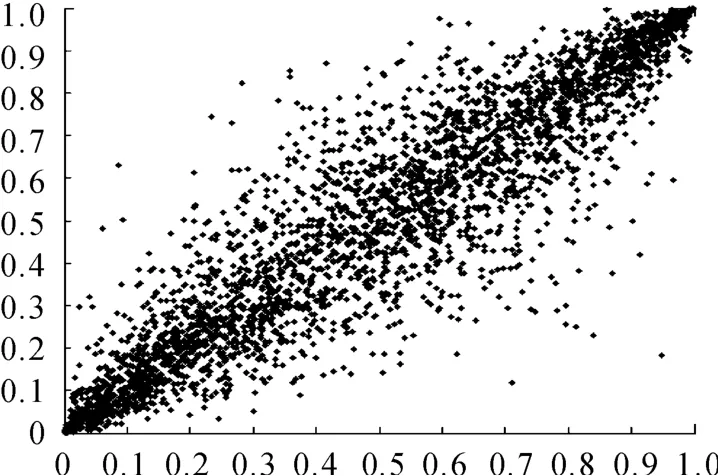
图9 相关离散点图

图10 离散点图
由表4-6可知,置信水平1-α=0.99或者1-α=0.95,VaR都比较接近 α,表现相当不错,但还是具有一定激进性;而通过统计量DLC,我们可以看到CVaR对风险的度量比较好。下面我们将对CVaR最小化为目标函数,进行投资组合的最优化的计算结果。
由表7可知,用模型对时间点T+1的收益率进行预测,知上证综指的平均收益率为0.000 6,深证成指平均收益率为0.001 4,但在5%的分位数下,上证综指和深证成指的CVaR分别为0.039 6和0.023 4,由于上证综指的收益率小且条件风险值大,故在分位数为5%时,要使在固定收益CVaR最小,只有将资金绝大部分投入深圳证劵市场;而当分位数取10%时,上证综指和深证成指的CVaR分别为0.030 7和0.069 6,显然深证成指的条件风险值远远大于上证综指,故资金在收益率低时,应将其大部分投放在上海证劵市场,随着收益率的升高,上海市场的投资比例降低,深证市场的资金比例上升,同时CVaR的值升高,符合高风险高收益,但是对二者的固定收益率超过13%时,最优解将不存在,与金融市场的多变性吻合。通过本模型,我们可以通过对不同分位数的选择来扩大风险范围,增加收益,来对不同风险厌恶程度的投资者进行投资指导,使得风险得到有效管理。
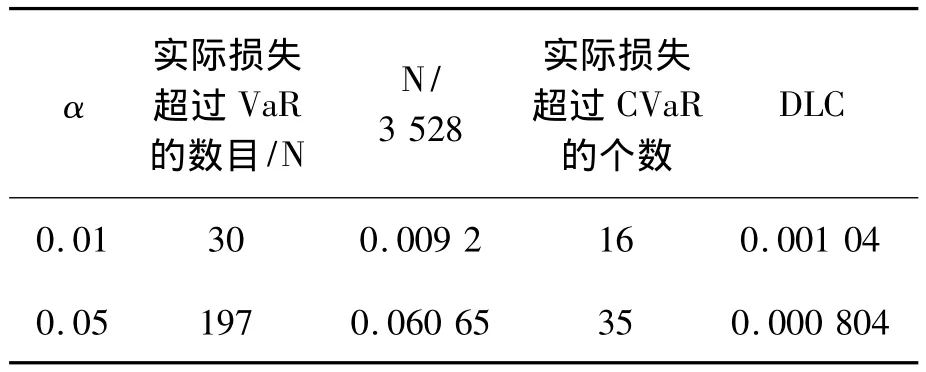
表4 数据总数为3 258个,投资比例w=1/3的模拟数据统计结果
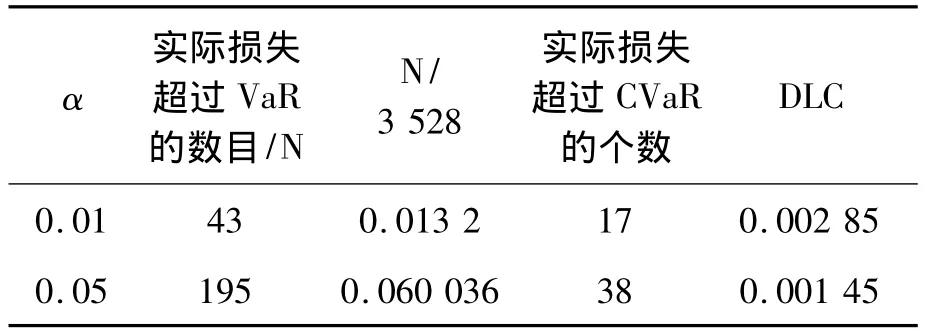
表5 数据总数为3 258个,投资比例w=1/2的模拟数据统计结果
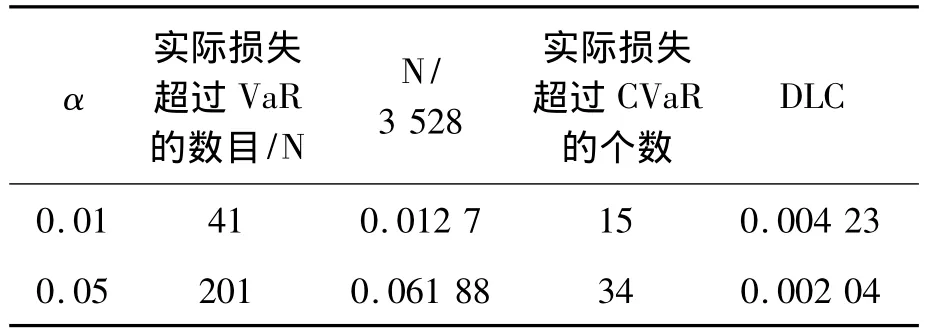
表6 数据总数为3 258个,投资比例w=3/4的模拟数据统计结果

表7 下表为分位数为5%和10%,固定收益率下的最优投资比例
五、结论与展望
通过上面的模型分析,本文得出以下结论:
(1)上海和深圳股票市场的收益率均存在明显的波动集聚性、条件异方差性和杠杆效应,模型估计αi均大于0,说明股市波动呈现集聚现象,过去的扰动对未来的波动有着正面的影响,较大幅度的波动后面紧跟着较大幅度的波动,股市参与者的投机性较强;而αi+βi都稍微大于1,即衰减速度越慢,波动的持续性越强。
(2)沪深两市均值方程中的条件方差项GARCH的系数估计分别为3.850 810和5.048 647,而且都是显著的,这反应了收益与风险正相关,说明收益有正的风险溢价,深圳股市的风险溢价要高于上海,深圳股市的投资者更加厌恶风险,要求更高的风险补偿。
(3)M-copula函数对样本的拟合度是最好的,其分布函数最接近经验联合分布,不仅能够比较全面和准确地捕捉各个时期上海和深圳股票市场之间相关程度变化,而且能够正确地反映两个市场之间非对称的相关模式;其次就是Gumble Copula函数,剩下的两个 copula函数拟合度相对较差。
(4)在分位数为5%时,要获得固定收益,同时CVaR最小,需将资金绝大部分投入深圳证劵市场;在分位数取10%时,目标收益率较低时,应将其大部分投放在上海证劵市场,目标收益率较高时,上海市场的投资比例应降低,深证市场的资金比例应上升,同时CVaR的值升高,符合高风险高收益。
(5)当二者的目标收益率超过13%时,最优解将不存在,与金融市场的多变性稳合。通过本模型,我们可以通过对不同分位数的选择来扩大风险范围,增加收益,来对不同风险厌恶程度的投资者进行投资指导,使得风险得到有效管理;在置信水平1-α=0.99或者1-α=0.95,风险值VaR都比较接近α,表现相当不错,但还是具有一定激进性,而CVaR对风险的度量比较好。
由于本文主要是对二元资产进行了建模,所以下一步我们可以将这一模型扩展到多元的情况。
[1]Sklar A.Functions derepartition an dimensions leurs marges[J].Publ.Inst.Paris,1959(8):9-13.
[2]Rockinger M,Jondeau E.Conditional dependency:an application of copula[Z].Department of Finance,HEC School of Management,Paris,2001.
[3]Patton A J.Modeling time-varying exchange rate dependence using copula[Z].Department of Economics,University of California,San Diego,2001.
[4]Romano C.Applying copula function to risk mangement[J].Working Paper of University of Rome“LaSapienza”,2002(1):1-11.
[5]Hu L.Essays in Economics applications in macroeconomic modelling[D].New Haven:Yale University,2002.
[6]WEI Yan-hua,ZHANG Shi-ying.GUO Yan.Research on degree and patterns of dependence in financial markets[J].Journal of Systems Engineering,2004(19):355-362.
[7]ZHANG Xue-li,ZHANG Shi-ying.Risk Analysis of Financial Portfolio Based on Copula-SV Model[J].Journal of Systems & Management,2007,16(3):302-306.
[8]LIU Zhi-dong.A Portfolio Selection Model on Copula-GARCH-EVT Based and Its Hybrid Genetic Algorithm[J].Systems Engineering-Theory Applications,2006,15(2):149-157.
[9]SHI Dao-ji.LI Fan.Research on the VaR and optimal portfolio of stock markets based on Copula[J].Journal of Tianjin University of Technology,2007,23(3):54-60.
[10]BAO Wei-jun,XUE Cheng-xian.CVaR analysis based on multidimensional the function of t-Copula portfolio[J].Statistics and Decision,2008(15):40-45.
[11]Frees E W,Valdez E A.Understanding relationships using Copula[J].North American actuarial journal,1998,2(1):11-25.
[12]Patton A.Skewness,Asymmetric dependence,and portfolios[Z].London:London School of Economics& Political Science,2002.
[13]WEI Yan-hua,ZHANG shi-ying.Copula theory and its in financial analysis[M].Beijing:Tsinghua University press,2008:80-85.
[14]Nelsen D B.Conditional in asset returns:A new approach[J].Econometrica,1991(59):347-370.
[15]Blanchard,Oliver,Danny Quah.The Dynamic Effects of Aggregate Demand and Supply Disturbances[J].American Economic Review,1989,79:655-673.
[16]Bollerslev T.Generalized autoregressive conditional[J].Journal of Economics,1986(31):9-20.
[17]WANG Chun-feng.The risk management of financial[M].Tianjin University press,2001.
[18]Rockafeller,Alexander S.Minimizing CVaR and VaR for a portfolio of derivatives[J].Journal of Banking & Finance,2006,48:583-602.
[19]XUE Zhong-ji.Monte Carlo method[M].Shanghai:Shanghai science and technology press,1985.
[20]Rockafeller T,Urvasev S.Conditional value-at-risk for general loss distribution[J].Journal of Banking & Finance News,2000,2(3):1-5.
[21]CHEN Ke-yan.The Research of the Optimal Model for Portfolio Investment bases on Genetic Algorithm[J].Journal of Nanjing Institute of Meteorology,2003,26(5):72-81.
[22]WANG Xiao-ping,CAO Li-xin.Genetic Algorithm theory and software realization[M].Xi’an:Xi’an jiaotong University press,2002:56-78.
猜你喜欢
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
投资有道(2018年6期)2018-07-10
沈阳工业大学学报(社会科学版)(2018年1期)2018-03-07
初中生世界·九年级(2017年10期)2017-11-08
债券(2016年11期)2017-01-12
债券(2016年11期)2017-01-12
债券(2016年10期)2016-11-28
债券(2016年10期)2016-11-28
