
科学知识网络自相似性的实证研究
2015-12-27 08:48林德明陈璐璐
科学与管理 2015年1期
林德明,陈璐璐
(大连理工大学 科学学与科技管理研究所WISE实验室,大连 116023)
科学知识网络自相似性的实证研究
林德明,陈璐璐
(大连理工大学 科学学与科技管理研究所WISE实验室,大连 116023)
科学计量学的研究都是以科学知识的自相似性作为理论假设的,尤其是科学知识图谱更是以科学文献等在空间上的自相似性为前提,因此对科学知识网络自相似性的检验与证明是必不可少的。应用科学计量学与复杂网络分析的方法,选取网络的平均聚类系数、平均最短路径和平均度三个特征指标,建立科学知识网络的自相似模型,并对合作网络、共词网络与共被引网络的自相似性进行定性与定量的分析,从而验证了科学文献的网络拓扑结构的局部与整体具有自相似。
科学文献;科学知识网络;自相似性;科学计量学;知识图谱
1 引言
科学计量学是应用数理统计和计算机技术等方法对科学技术本身进行定量分析的一门交叉学科,其定量分析的对象为科学知识,文献等是科学知识的重要载体。但是在实际研究过程中获取所有知识总体是不现实的,因此利用选取期刊或是关键词检索获得数据样本,成为科学计量学研究的最主要途径 。这种途径是建立在科学知识具备自相似性的假设前提下的,即样本和总体的相似。
伴随着科学技术的迅猛发展,科学知识也在大规模地扩张,例如每年SCI数据库的文献增长量就达到100多万篇,巨大而复杂的科学知识数据,为科学计量学提出了极大的挑战。然而,复杂网络分析、计算机技术、信息可视化等相关技术和方法的发展为科学计量学注入了新鲜的血液[1][2],使得科学知识图谱[3][4]与知识可视化技术[5]成为了科学计量学的新航向,并在反恐主义研究领域分析[6]、科技期刊引文环境[7]等诸多领域得到广泛应用。然而,对于某一学科领域来说数据量过于庞大,展现所有数据的知识图谱是现有技术无法实现的,所以知识图谱的绘制只能选择一部分高被引或其他告知标志的文献,正是由于自相似性假设的存在,使得高被引文献的知识图谱也能反映总体的一部分特征。
因此,无论是科学计量学还是科学知识图谱的研究都以科学知识自相似性的存在作为理论前提的。1990年Van Raan意识到科学知识的相似性,率先验证了科学知识的分形结构,并证明了随着共被引文献规模的增加,其分数维数呈指数分布形式增加[8][9][10]。随后Brunk GG[11]、Bailon-Moreno R[12]等在此基础上,对科学知识系统的分形结构进行了探讨。以上研究都局限于分形结构的研究,关注科学论文在时间上的扩散与增长,对于其它自相似结构尤其是共被引网络等空间结构的自相似并没有涉及,并且缺乏对自相似性的检验与证明。除此之外,通过文献的大量检索鲜见科学知识自相似性的研究,在国内的文献中并没有检索到相关研究。
同时,自相似性在数据通信[13]、人类生物网络[14]以及复杂网络等诸多领域被研究,C.M.Song与S.Havlin[15]等人利用重构化理论来揭示复杂网络的自相似分形特征;R.Guimera 与L.Danon[16]在研究中利用邮件系统来揭示社区结构的自相似分形特征;陶少华[17][18]等分别研究了基于信息维数与容量维数的复杂网络的自相似性,建立了基于自相似分型特征的网络演化模型,并且说明动态增长的复杂网络的确是自相似的,这些研究为本项目提供了启示与参考。
本文主要研究科学文献在空间上的自相似性,选取科学文献所组成的知识网络中平均聚类系数、平均最短路径、平均度三个基本指标,随着网络规模的变化情况,建立模型验证科学文献在网络拓扑空间中的自相似性,从而为解释科学规律,明确科学计量学中的数据选择尺度提供参考。
2 科学知识网络的自相似模型
2.1 指标选取
自相似性是指某一物体的局部可能在一定条件下或过程中,在某一方面例如状态、结构、信息、功能、时间、能量等都表现出与整体的相似性,即具有尺度不变性。空间自相似性是一种非常普遍的现象,通常被理解为系统的部分和整体在空间形态和结构上存在某种相似性。而科学文献空间的自相似性是指由科学文献的作者、关键词或者参考文献等所组成的空间结构的局部与整体具有某种相同的性质。目前,在科学文献的计量分析中,科学知识网络,包括合作网络、共词网络、共被引网络等是科学文献空间上拓扑结构最好的表现形式。
随着对复杂网络研究的深入,研究者提出了许多特征指标,来描述各种不同类型的复杂网络的共同特征,同时也用来衡量各种复杂网络演化模型的准确性和有效性。目前,研究比较充分的统计特性有平均聚类系数、平均最短路径、平均度等[19]。
(1)平均聚类系数:假设网络中的一个节点i有ki条边将它与其它节点相连,这ki个节点称为节点i的邻居节点,在这ki个邻居节点之间最多可能有ki(ki-1)/2条边。节点i的ki个邻居节点之间实际存在的边数Ni和最多可能有的边数ki(ki-1)/2之比就定义为节点i的聚类系数,记为Ci。整个网络的聚类系数定义为网络中所有节点i的聚类系数Ci的平均值,记为C。聚类系数用来衡量网络中节点间连接的紧密程度。
(2)平均最短路径:网络中任何两个节点i和j之间的距离pij为从其中一个节点出发到达另一个节点所要经过的连边的最少数目。网络的平均最短距离P为网络中所有节点对之间距离的平均值。网络的平均最短路径D主要用来衡量网络的传输效率。
(3)平均度:网络中某个节点i的度ki定义为与该节点相连接的其它节点的数目,也就是该节点的邻居数。通常情况下,网络中不同节点的度并不相同,所有节点i的度ki的的平均值称为网络的(节点)平均度,记为
2.2 模型建立


图1 合作网络的子网络图
以合作网络为例,图1为某一领域节点数分别为600和1000时的合作网络的子网络图。可以清楚直观地看出,两个网络图的整体结构是相似的,随着节点的增加,B的结构并没有实质的改变。我们可以说当N达到600时,网络已经呈现平稳的态势,这时节点的增加并不会改变整体网络的性质,可以说明局部与整体具有自相似性。
根据以上定义,对于指标y,如果网络N具有自相似性,则y随网络规模的变化趋势

3 实证分析
选取材料处理技术作为案例,从Web of Science中下载该领域1990年到2010年的文献,共11609篇,然后利用Bibexcel分别形成合作网络,共词网络和共被引网络,应用以上模型对三类科学知识网络进行分析。
合作网络是科学文献的作者通过合作关系建立的科学知识网络,网络中的节点可以是作者、机构、国家等科学知识的生产者,如果两个作者、机构、国家在文献的作者中出现,则他们存在合作,记;可以表示他们的合作次数或强度,且。本文中的合作网络为作者合作网络,图2中横坐标为网络的节点数即作者数,其中作者按照发文量由大到小排列,例如n=10表示只选取发文量前10所组成的合作网络;纵坐标分别为平均聚类系数、平均最短路径和平均度三个网络特征指标。

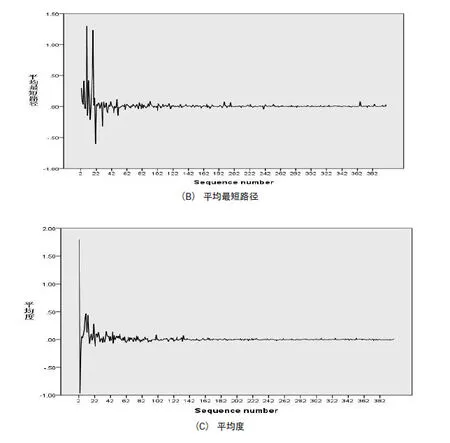
图2 合作网络的特征指标差分序列的变化曲线

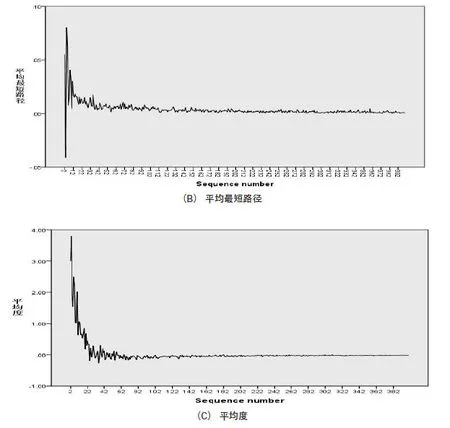
图3 共词网络的特征指标差分序列的变化曲线
共词网络是科学文献中的关键词或主题词通过共现关系建立的科学知识网络,词是是对科学知识最直接的描述,共词网络中的节点可以是文献中标注的关键词,亦可以是来自于文献的题目、摘要甚至文献内部中的、能够清晰描述知识内容的主题词。
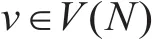
如果两个词在同一篇文献中出现,则,他们在网络存在边的连接;可以表示他们共同出现的频次或强度。本文中的共词网络为关键词共现网络,图3中横坐标为网络的节点数即关键词数,其中关键词按照频次由大到小排列,例如n=10表示出现频次前10所组成的共词网络;纵坐标分别为平均聚类系数、平均最短路径和平均度三个网络特征指标。
从图3可以看出,共词网络的平均聚类系数、平均最短路径与平均度都与分别在n=62、n=132和n=132以后趋近于0,所以共词网络具备自相似性。

图4 共被引网络的特征指标差分序列的变化曲线
从图4可以看出,共被引网络的平均聚类系数、平均最短路径与平均度都与分别在 n=72、n=112 和n=132 以后围绕着0上下波动,虽然波动的幅度比较大,但是序列的均值仍近似为0,并且方差非常小,所以共被引网络基本具备自相似性。
4 结论
由于科学知识规模的大规模扩张,科学计量学受到了极大的挑战。无论是科学计量学方法还是新兴的科学知识图谱都是以科学知识的自相似性为理论前提的,但是通过对国内外文献的检索发现,对科学文献相似性的检验与深入研究并不多见。本文以科学文献所组成的科学知识网络在空间的自相似性为研究对象,首先建立科学知识网络的自相似性模型,然后在此基础上提出网络特征指标收敛性检验的自相似性验证方法,最后以材料处理技术领域在1990年到2010年间的11609篇论文为实例,对其合作网络、共词网络和共被引网络的自相似性进行了验证。研究表明作者合作网络与共词网络具备比较显著的空间相似性,而共被引网络基本具备自相似性,并且网络特征指标中平均聚类系数收敛的速度远快于其他指标,平均最短路径与平均度的收敛速度基本相近。
[1] E Otte, R Rousseau. Social network analysis: a powerful strategy, also for the information sciences[J]. Journal of information science, 2002, 28 (6): 441-453.
[2] Chen C. Mapping Scientific Frontiers: The Quest for Knowledge Visualization[M]. London: Springer-Verlag, 2002.
[3] K Börner, C Chen, KW Boyack. Visualizing Knowledge Domains. Annual Review of Information Science & Technology[D], B. Cronin, Editor. Information Today, Inc. American Society for Information Science and Technology: Medford, NJ, 2007, 179-255.
[4] 刘则渊,陈悦,侯海燕等. 科学知识图谱方法与应用[M]. 北京:人民出版社,2008.
[5] Chen C. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature[J]. Journal of the American Society for Information Science and Technology. 2006, 57(3): 359-377.
[6] EF Reid, HC Chen. Mapping the contemporary terrorism research domain[J]. International journal of human-cumputer studies, 2007, 65 (1): 42-56.
[7] 周萍,Leydesdorff L,武夷山. 中国科技期刊引文环境的可视化[J]. 中国科技期刊研究,2005,16(6):773-780.
[8] Van Raan. Fractal dimension of co-citations[J]. Nature, 1990, 347 (10): 626.
[9] Van Raan. Fractal geometry of information space as represented by co-citation clustering[J]. Scientometrics, 1991, 20 (3): 439-449.
[10] Van Raan. On growth, ageing, and fractal differentiation of science[J], Scientometrics 2000, 47(2): 347-362.
[11] GG. Brunk. Swarming of innovations, fractal patterns, and the historical time series of US patents[J]. Scietometrics, 2003, 56 (1): 61-80.
[12] R Bailon-Moreno, E Jurado-Alameda, R Ruiz-Banos, et al. The unified scientometrics model, fractality and transfractality[J]. Scietometrics, 2005, 63 (2): 231-257.
[13] 邵立松,窦文华. 自相似网络通信量模型研究综述[J]. 电子与信息学报,2005,27(10):1671-1676.
[14] 黄海生,丁德武,吴璞等. 几种人类生物网络的自相似性实证研究[J]. 计算机工程与应用,2011,47(16):128-130.
[15] Song Chao-ming, S Havlin, HA Makse. Self-similarity of complex networks[J]. Nature, 2005, (433): 392-395.
[16] R Guimera, L Danon, A Dlaz-Guilera, et al.Self-similar community structure in a network of human interactions [J]. Physical Review E, 2003, 68 (6): 065103.
[17] 陶少华,刘玉华,许凯华等. 基于信息维数的复杂网络自相似性研究[J]. 计算机工程与应用, 2007, 43(15):108-110.
[18] 陶少华,刘玉华,许凯华等. 基于容量维数的复杂网络自相似性研究[J]. 计算机工程, 2008, 34(2):175-177.
[19] 汪小帆,李翔,陈关荣. 复杂网络理论及其应用 [M]. 北京:清华大学出版社,2006.
(责任编辑:张 萌)
Empirical Study on the Spatial Self-similarity of Scientific Knowledge Network
LIN Deming,CHEN Lulu
(WISE Lab, Institute of Science Studies and S&T Management, Dalian University of Technology, Dalian 116023)
Self-similarity of scientific knowledge is the theoretical hypothesis of scientometrics. Especially the mapping knowledge is even based on the spatial self-similarity of scientific literatures. Therefore it is essential to investigate the selfsimilarity of scientific knowledge network. We applied scientometics and complex network analysis to study the self-similarity of cooperative network, co-word network and co-citation network qualitatively and quantitatively, where select three characteristic indices which are the average clustering coefficient, average shortest path and the average degree of the network to establish a selfsimilarity model. In the resuilt, prove that the local network topology and global network topology of the scientific literature are selfsimilarity.
:Scientific literature;Scientific knowledge network;Self-similarity;Scientometrics;Mapping knowledge domain
G302;F224
A
10.3969/j.issn1003-8256.2015.01.006
辽宁省教育厅科学研究一般项目“科学引文共被引网络的科学计量研究”(W2012018)、国家自然科学基金资助项目“基于蚁群觅食模型的科学知识的复杂性演化机理研究”(71003011)
林德明(1978-),男,汉族,黑龙江哈尔滨人,大连理工大学公共管理与法学学院科学学与科技管理研究所,副教授,研究方向为科技政策与科技管理;陈璐璐(1989-),女,汉族,辽宁抚顺人,大连理工大学公共管理与法学学院科学学与科技管理研究所硕士研究生,研究方向为科技政策与科技管理。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·小学生快乐作文(2021年12期)2021-08-28
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
冰雪运动(2019年2期)2019-09-02
计算机技术与发展(2019年1期)2019-01-19
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
小猕猴智力画刊(2017年3期)2017-03-24
互联网天地(2016年1期)2016-05-04
