
基于大数据处理流程的图书馆用户关系数据管理及应用研究
2016-02-05 07:29辽宁省图书馆
图书馆理论与实践 2016年12期
(辽宁省图书馆)
基于大数据处理流程的图书馆用户关系数据管理及应用研究
姚雪梅(辽宁省图书馆)
文章围绕客户关系管理服务“以用户为中心”的理念,借助大数据的信息采集、存储、分析挖掘技术流程,系统、全面地分析处理图书馆用户关系数据,探讨用户的信息行为和信息需求特点,深入了解用户的需求。在此基础上,将大数据用户关系数据管理的成果融入到创新图书馆用户服务模式中,并提出了具体的服务策略和方法,包括:提出基于大数据用户关系数据管理的阅读推广服务、个性化服务、图书馆用户网络舆情监控、开展用户数据素养教育。
大数据;处理流程;用户关系
随着信息技术和网络技术的不断发展,用户的信息需求向着多样化、个性化转变,促使图书馆的服务理念与服务模式进行革新。阮冈纳赞的“图书馆学五定律”在新时期被更好的诠释,“以用户为中心”[1]的服务理念也被普遍遵循,即以用户需求为中心,通过现代化技术整合图书馆资源与服务,重视用户动态的信息需求和信息行为,挖掘其潜在的需求特征。而大数据对于海量信息的存储和分析能力,必将会给图书馆用户关系管理带来新的机遇。
1 大数据与图书馆用户关系管理
1.1 大数据概述
2011年,麦肯锡全球研究所的报告《大数据:创新、竞争和生产力的下一个前言》指出,“大数据”是指大小超出了传统数据库软件工具的抓取、存储、管理和分析能力的数据群。[2]不断增多的数据量需要不断更新的分析和存储工具,故大数据通常与Hadoop、NoSQL、数据分析与挖掘、数据仓库、商业智能以及开源计算机架构等诸多热点话题联系在一起。简单来说,大数据由三项技术趋势汇聚而成。一是海量的交易数据,由不断增长的关系数据、半结构化和非结构化数据信息构成;二是海量的交互数据,由网络社交平台贡献而来,如Facebook、Twitter等;三是海量的数据处理。大数据的涌现催生出了用于数据密集型处理的架构,如Hadoop,就是一种以可靠、高效、可伸缩的方式进行分布式处理的软件构架。大数据的价值主要体现在两个方面:分析使用和二次开发。但大数据分析也存在其局限性,大数据不等于全数据、真数据,选中的样本和数据影响着研究结果,并且它只能揭示和解释某些事情,并不能预测和解决所有问题。
1.2 图书馆用户关系管理的核心理念
近些年,企业的客户关系管理(CRM)理论逐渐被引入图书馆管理实践,即图书馆用户关系管理。客户关系管理理论代表人物迈克尔·约翰逊指出:“每家公司都必须有能力使客户感到满意,并保持现有的客户。”CRM的核心是:客户是企业发展最重要的资源之一,对企业与客户发生的各种关系进行全面管理,CRM的目标是以快速和周到的优质服务吸引和保持更多的客户,提高客户忠诚度,最终为企业带来利润的增长。[3]图书馆正是借鉴CRM形成了图书馆用户关系管理理念,始终围绕“以用户为中心”,良好的图书馆用户关系可以提高图书馆现有用户的忠诚度,吸引潜在用户,提升图书馆资源的利用率。
1.3 图书馆用户关系数据管理的意义
随着大数据、云计算等技术的发展,图书馆数据,特别是用户关系数据所蕴含的价值越来越容易地被挖掘出来。基于大数据的用户资源管理,可以实现对用户信息的全面整合,发现用户的需求特点和趋势,为用户提供更为快捷与周到的服务;可以创新服务形式,实现多层次、立体化的服务;还可以辅助图书馆领导层优化决策流程;此外,在用户数据管理的基础上,可以发现图书馆自身资源与服务的不足,帮助图书馆协同发展。
2 大数据处理流程
2.1 智能的数据采集
大数据的采集是指利用多种数据库来接收发自客户端(Web、App等)的数据。数据量大是大数据的基本特征之一,除了采集传统的结构化数据,实际上采集到的数据更多的是半结构化和非结构化数据。结构化数据:即用统一长短的字段来记录的数据,如事务性数据和联机分析处理(OLAP)数据;半结构化数据:具有一定结构,可以解析的文本数据文件;非结构化数据:需要用不同长短的字段来表示,如文字、图像、视频等。智能化的数据采集技术大幅度提高了数据收集的效率,为数据处理提供原始资料。
2.2 数据的存储与预处理
大数据存储是进行分析的前提,所以这个存储平台应该能够支持对海量数据的有效分析,而分布式数据库(DDBS)很好地解决了这个问题。DDBS支持多台计算机通过网络在异地协同工作,但逻辑上仍是一个整体,并由一个分布式管理系统(DDBMS)统一管理。在采集端的数据导入到DDBS过程中,可以做一些简单的预处理工作,如清洗等,因为在大数据背景下,存储了大量冗余、错误的数据,需要利用ETL(Extraction-Transformation-Loading,数据抽取、转换和加载)技术去除其中可识别的错误,提高数据质量,为数据挖掘做准备。
2.3 数据的分析与挖掘
数据分析与挖掘指基于一定的数据挖掘算法,从存放在数据仓库、分布式数据库或其他信息库中的大量数据中分析、发现有用的信息的过程。常见的数据挖掘方法有:聚类分析、回归分析、神经网络、决策树算法等。在大数据环境下,Hadoop作为分布式计算领域的典型代表,是传统关系型数据库(如,Oracle、MySQL等)的有力补充。Hadoop是一个用java语言实现并行处理海量数据的开源软件框架,基于Hadoop的数据库管理系统更适合处理文本、图像这类非结构化数据,其核心部分为HDFS(分布式文件系统)和MapReduce。HDFS将大数据文件分块,并以副本的方式存储在集群的不同节点上,Madoop程序便可以在所有节点上处理这些数据(见图1)。

图1 大数据处理的主要流程
3 基于大数据处理流程的图书馆用户关系数据管理
3.1 图书馆用户数据资源采集阶段
在图书馆中,用户数据可能存在于用户与图书馆直接或间接互动的各个环节中,主要来源于两部分:①存在于图书馆自动化管理系统中,如,用户基本信息数据、流通数据、检索数据、图书馆门禁系统数据、监控数据等;②来源于图书馆互联网平台或图书馆手机APP中,如,网络服务日志、论坛、电子邮件等。此外还有读者面对面的参考咨询数据、读者电话数据等。这些复杂、庞大的结构化、非结构化数据散落在图书馆的各个业务部门,要想将所有数据集中起来,获得全面、高效的用户信息,实属不易,而大数据采集技术为此提供了可能。
对数据抓取实际上是建立在对于问题的理解上,明晰需要采集的数据类型和特点,才能正确地选择数据获取工具。根据数据来源,图书馆用户数据采集工具可分为:①系统日志的采集,如Hadoop的Chukwa、Cloudera的Flume、Facebook的Scribe等,这些工具采用分布式架构,能满足每秒数百兆的日志数据采集和传输需求;②网络数据采集,主要指网络爬虫(Spider)从互联网上抓取的网页内容,并抽取所需的内容属性,以及在用户浏览网页时由网页后台服务器搜集到的记录,从而分析得到的数据信息。
3.2 图书馆用户关系数据的存储
随着网络和计算机的普及,人们习惯于在网上查询、分享和交流信息,图书馆用户每天产生的日志以及分享的资料使得用户数据量高速增长,并且数据具有复杂化、多样化的特点。大数据时代用于存储的数据库系统种类较多,大体可分为关系型数据库、非关系型数据库及数据库缓存系统。关系型数据库遵循“E-R”模型,主流产品有Oracle、SQL Server、DB2、MySQL等;非关系型数据库主要指NoSQL数据库,分为键值数据库(Redis、Voldemort)、列存数据库(Bigtable、Hypertable、Cassandra)、图存数据库(Neo4j、GraphDB、OrientDB)、文档数据库(CouchDB、MongoDB)。目前,传统数据分析软件(如,SAS、SPSS等)因处理能力有限,处理大数据时显得力不从心,因此,Hadoop、MapReduce等大数据分析工具受到越来越多的关注和青睐。HDFS和MapReduce是其处理框架的核心,HDFS为用户提供具有高容错性和高伸缩性的海量数据的分布式存储,并通过MapReduce在集群上实现海量数据的并行处理。图书馆用户大数据信息存储模型的主要类别见下表。
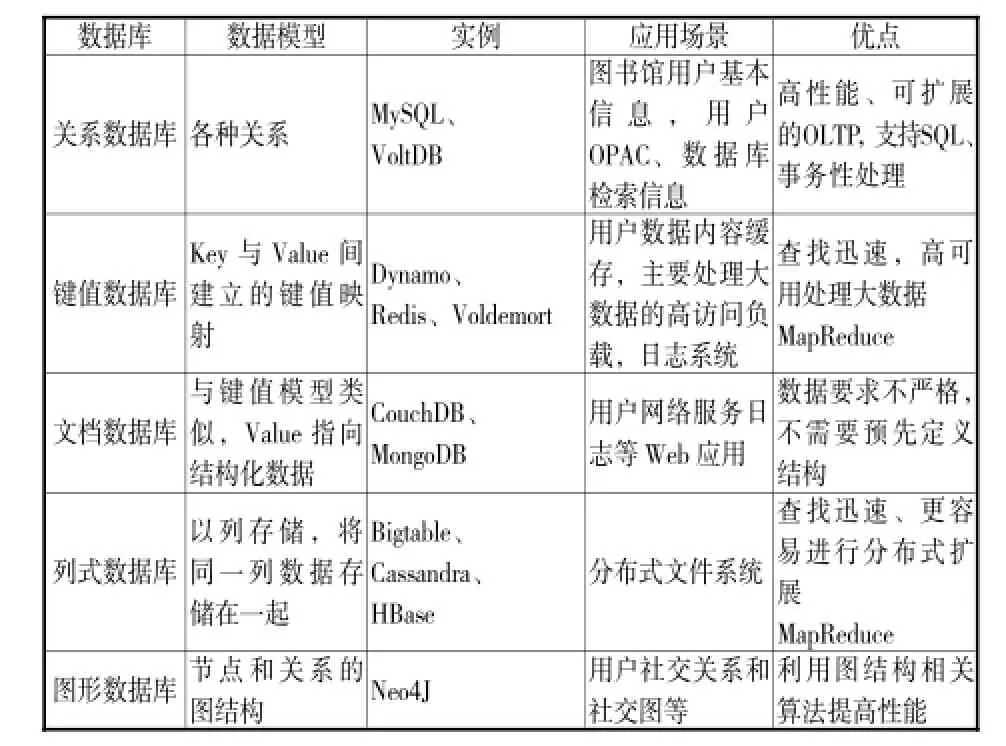
表图书馆用户大数据信息存储模型分类[4]
3.3 图书馆用户关系数据的挖掘与分析
通过对图书馆用户数据的挖掘可以发现用户的行为和需求特点,[5]从而更好地将图书馆资源与服务推送给用户,实现多维度、个性化服务。数据挖掘可以解决许多问题,并提供相应的分析算法,如分类与预测问题(决策树、贝叶斯分类等)、聚类问题(K均值聚类、K中心点聚类等)、关联问题(基于频繁项集挖掘的Apriori算法等)等。大数据时代,分布式平台逐渐成为主流,为使以上这些经典的数据挖掘算法符合分布式环境,开源的分布式架构被推上历史舞台。如,Apache Mahout是Hadoop的开源项目之一,其算法采用MapReduce编程模型开发而实现,有效解决了数据挖掘算法在分布式平台上的并行问题,可以执行深度、高效的大数据挖掘任务(见图2)。
用户的数据挖掘大致有两种路径。第一种是比较传统的“假设检验”方法,即在正式进行大数据挖掘前,先进行一个理论假设,我们需要做的是利用现有的数据来证明这个假设的真实性——“假设—数据—验证”。第二种是数据库知识发现(KDD)方法,通过人工设计一定的算法来“观察”数据本身而进行挖掘。图书馆可以对用户的浏览、评论、检索、收藏等情况进行分析,来发现和预测用户现实及潜在的阅读行为、需求特点和规律,并推出相应服务,使服务更人性化、个性化。

图2 基于Hadoop的图书馆用户关系数据挖掘与分析模块框架
4 基于大数据的图书馆用户关系数据管理实践应用
4.1 开展阅读推广服务
近年来,全国许多图书馆纷纷通过各种载体、形式、渠道向公众传播阅读理念,开展讲座、展览、征文演讲比赛、创客大赛等活动进行阅读推广。有的在区域内结成了图书馆联盟(如安徽省公共图书馆阅读推广联盟[6]);有的进行了有针对性的阅读推广人培训;有的实践了以读者为主导的资源建设模式(如内蒙古图书馆推出的“彩云服务计划”[7]),共同为延伸图书馆服务,扩大阅读队伍而努力。阅读推广活动是相对群体性的活动,应根据区域特点、用户自然情况等因素综合考虑。大数据时代,“移动+互联网”的发展为图书馆阅读推广活动地有效展开插上了翅膀。例如,图书馆可以通过大数据对用户注册、OPAC检索和借阅、用户流量等信息进行采集,利用数据挖掘技术对用户进行细分。每个细分群的用户都有相似的属性,分析用户群的组成情况,采取更有针对性的阅读推广策略,既能开发用户资源,又能提高阅读推广质量。
4.2 个性化推送服务
判断一个人将来的信息需求行为最好的指标是他过去的需求行为,这是利用大数据进行用户分析的真正意义所在。[8]个性化的信息服务是建立在对读者现实和潜在需求的理解之上,通过大数据技术(Hadoop平台、SQL Server等)对每位用户的信息行为进行分析,包括根据其使用图书馆自动化系统、移动终端设备(图书馆手机APP等)或互联网进行的检索、借阅、浏览、评论等情况,预测用户的阅读趋势,作为图书馆开展个性化服务的依据。以信息推送服务为例,信息推送集合了自然语言处理、数据挖掘、互联网等多门技术,图书馆可以将大数据与信息推送相结合,利用关系型数据库和非关系型数据库对用户本地数据(系统浏览日志、OPAC检索日志等)及互联网数据进行采集、存储和分析,并通过数据挖掘技术进行文本挖掘和Web挖掘,从而更加精准地了解用户的兴趣点,进行有针对性的服务和信息推送。事实证明,适时适度的推送服务能够有效提升用户活跃度,增强用户体验,提高图书馆资源利用率。此外,还应对用户个性化信息进行动态战略管理,及时了解其信息行为的变化因素,分析出用户的忠诚度和阅读趋势,积极采取措施并做出相应的调整,留住老用户,吸引新用户。
4.3 图书馆用户网络舆情监控
基于大数据的网络舆情分析可以帮助图书馆及相关部门及时发现、跟踪、监测网络上用户关注的热点问题和事件的发展趋势,辅助科学决策。图书馆可以建立网络舆情监测平台,根据预设的关键词和监测范围,通过互联网,自动采集网站、论坛、博客、微博等多媒体平台的信息,自动筛选有用的数据,进行统计和识别,及时掌握舆情动态,为科学决策做准备。这一过程融合了多学科的研究方法与技术手段,借助内容分析法、语义分析法、文本挖掘、自动聚类、自动标引技术等,实现对海量信息的采集、存储、统计和分析。其目的是从大量杂乱无章的数据中,挖掘出有价值的数据项之间的关系,发现用户舆情热点,对用户的观点、态度、喜好进行分析,及时调整图书馆相关的服务内容;还可以反映用户对图书馆服务的整体评价,并及时做出正确的舆论引导,提高图书馆在社会大众心目中的地位。
4.4 开展用户数据素养教育
数据素养是对信息素养的延伸与扩展,是用户根据自身要解决的问题,通过各种途径,有意识地对数据进行收集、分析和处理的能力。数据素养能力对各学科人员的具体要求不尽相同,图书馆用户基本的数据素养能力应包括:电子资源的检索和利用方法(如,各类数据库的使用)、OPAC检索等。数据素养还与用户的个人因素息息相关,如,受教育程度等。通过大数据分析图书馆用户的资源利用情况,并据此进行有针对性的数据获取和处理的教育与培训。图书馆可以开展常用数据库检索技巧和方法的培训,教会用户如何有效地获得所需信息,并有处理和分析数据的能力,让用户善于用大数据的思维方式来解决工作和学习中遇到的问题。
[1]王翠,郑春厚.以用户为中心的数字图书馆用户界面设计研究[J].图书馆学研究,2008(6):11-14.
[2]郭晓科.大数据[M].北京:清华大学出版社,2013:123.
[3]王广宇.客户关系管理[M].北京:清华大学出版社,2010:374.
[4]李婧,等.地质大数据存储技术[J].地质通报,2015(8):1589-1594.
[5]赵红,王俊英.基于数据挖掘的读者关系管理[J].图书馆工作与研究,2012(1):45-47,62.
[6]安徽省公共图书馆阅读推广联盟[EB/OL].[2016-06-25].http://lm.ahlib.com/ahlibs/index.
[7]内蒙古图书馆推彩云服务:你看书,我买单.[EB/OL].[2016-06-25].http://gongyi.qq.com/.
[8]Charles F.Hofacker,et al.Big data and consumer behavior:Imminentopportunities[J].JournalofConsumerMarketing,2016,33(2):89-97.
Research on Data Management and Application of Library User Relationship Based on Big Data Processing
Yao Xue-mei
This article focuses on the concept of customer relationship management services“user-centric”,application of large data information collection,storage and analysis of data mining process to make a systematic and comprehensive analysis on the library user relationship data,and to explore information behavior,in-depth understanding of user needs and establishes a good relationship with the user.On the basis of the user data management achievements,it puts forward the specific strategies and methods of service that includes data management of reading promotion service based on big data of the user relationship,personalized service,library user network public opinion monitoring to carry out user data literacy.
Big data;Process Flow;User relationship
G252.0
A
1005-8214(2016)12-0084-04
姚雪梅(1984-),女,北京师范大学图书馆学硕士,辽宁省图书馆馆员,研究方向:阅读推广。
2016-07-14[责任编辑]刘丹
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
小太阳画报(2018年1期)2018-05-14
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
小天使·一年级语数英综合(2014年8期)2014-06-26
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
