
基于情感特征的用户聚类分析
2016-04-12 09:06任伟刘循
中国新通信 2016年5期
任伟 刘循


【摘要】 随着互联网行业的发展,各式各样的网站不断兴起,用户在网上发帖留言已经成为一种常态,对用户的留言进行情感分析,分析用户的情感倾向和主观情感已经变得越来越流行。首先,本文用基于情感词典的情感分析方法对用户的情感进行分析,为用户的每一条回帖计算其正向情感分值和负向情感分值得以及计算其 正向情感词数目和负向情感词数目,最后以用户为单位,计算均值,得到每个用户的情感特征向量,我们根据用户的情感特征向量,对用户进行聚类分析,探究用户的行为模式有什么不同点和相同点。
关键字:情感分析;KMeans;聚类分析
User cluster analysis based on sentiment feature
REN - wei, LIU- xung (School of Computer, Sichuan University, Chengdu 610065, China)
Abstract: With the development of Internet,all kinds of website becomes popular,users like to leave somemessages on it.That is a good resource for us to analysis sentiment for every user.
This paper uses a dictionary-based method to analysis users sentiment.we calculate thepositive points,negative points,the number of positive word and the number of negative word for every message.then get a mean value of them as a feature vecture for every user.At last,we can use the KMeans algorithe to cluster them and analysis the way when people leave a message.
Keywords:KMeans; cluster; sentiment analysis
一、用户情感分析
本文采用的是基于情感字典的情感分析方法.
1.1 原理
比如这么一句话:“这手机的画面极好,操作也比较流畅。不过拍照真的太烂了!系统也不好。”
① 情感词
要分析一句话是积极的还是消极的,最简单最基础的方法就是找出句子里面的情感词,积极的情感词比如:赞,好,顺手,华丽等,消极情感词比如:差,烂,坏,坑爹等。出现一个积极词就+1,出现一个消极词就-1。
里面就有“好”,“流畅”两个积极情感词,“烂”一个消极情感词。那它的情感分值就是1+1-1+1=2. 很明显这个分值是不合理的,下面一步步修改它。
② 程度词
“好”,“流畅”和‘烂“前面都有一个程度修饰词。”极好“就比”较好“或者”好“的情感更强,”太烂“也比”有点烂“情感强得多。所以需要在找到情感词后往前找一下有没有程度修饰,并给不同的程度一个权值。比如”极“,”无比“,”太“就要把情感分值*4,”较“,”还算“就情感分值*2,”只算“,”仅仅“这些就*0.5了。那么这句话的情感分值就是:4*1+1*2-1*4+1=3
③ 感叹号
可以发现太烂了后面有感叹号,叹号意味着情感强烈。因此发现叹号可以为情感值+2. 那么这句话的情感分值就变成了:4*1+1*2-1*4-2+1 = 1
④ 否定词
明眼人一眼就看出最后面那个”好“并不是表示”好“,因为前面还有一个”不“字。所以在找到情感词的时候,需要往前找否定词。比如”不“,”不能“这些词。而且还要数这些否定词出现的次数,如果是单数,情感分值就*-1,但如果是偶数,那情感就没有反转,还是*1。在这句话里面,可以看出”好“前面只有一个”不“,所以”好“的情感值应该反转,*-1。
因此这句话的准确情感分值是:4*1+1*2-1*4-2+1*-1 =-1
⑤ 积极和消极分开来
再接下来,很明显就可以看出,这句话里面有褒有贬,不能用一个分值来表示它的情感倾向。而且这个权值的设置也会影响最终的情感分值,敏感度太高了。因此对这句话的最终的正确的处理,是得出这句话的一个积极分值,一个消极分值(这样消极分值也是正数,无需使用负数了)。它们同时代表了这句话的情感倾向。所以这句评论应该是”积极分值:6,消极分值:7“
⑥ 以分句的情感为基础
再仔细一步,详细一点,一条评论的情感分值是由不同的分句加起来的,因此要得到一条评论的情感分值,就要先计算出评论中每个句子的情感分值。这条例子评论有四个分句,因此其结构如下([积极分值, 消极分值]):[[4, 0], [2, 0], [0, 6], [0, 1]]
以上就是使用情感词典来进行情感分析的主要流程了,算法的设计也会按照这个思路来实现。
1.2 算法设计
第一步:读取评论数据,对评论进行分句。
第二步:查找对分句的情感词,记录积极还是消极,以及位置。
第三步:往情感词前查找程度词,找到就停止搜寻。为程度词设权值,乘以情感值。
第四步:往情感词前查找否定词,找完全部否定词,若数量为奇数,乘以-1,若为偶数,乘以1。
第五步:判断分句结尾是否有感叹号,有叹号则往前寻找情感词,有则相应的情感值+2。
第六步:计算完一条评论所有分句的情感值,用数组(list)记录起来。
第七步:计算并记录所有评论的积极情感值,消极情感值,积极情感词个数,消极情感词个数。
二、构建用户情感特征向量
通过上一节的工作 我们得到了每个用户每条的回帖的情感特征向量,即[正向情感得分,负向情感得分,正向情感词数目,负向情感词数目],通过每条发言的情感特征,我们可以构建用户的整体情感特征,分别计算用户的正向情感均值、负向情感均值,正向情感方差,负向情感方差,正向情感词平均数,负向情感词平均数,用户的整体情感特征有助于我们对用户的情感进行分析,比如均值代表了正向情感或者负向情感的大致水平,而方差则表示了用户情感水平的波动情况,方差越大,表明用户的情感变化范围较大,而正向情感词平均数和负向情感词平均数则需要配合情感均值来使用,若是 负向情感词平均数 或者 正向情感词平均数 很高 但是 正向情感均值 和 负向情感均值 缺不高 说明在情感词时用了很多否定词,说明在表达情感时比较委婉。反之 若正向情感均值或负向情感均值 比较高 同时 正向情感词平均数 与负向情感词平均数也比较高 则说明在表达情感时显得比较直接。
三、用户情感特征分析
我们对100位用户的情感特征向量进行进行分析,首先进行相关性分析,我们利用皮尔逊相关系数 来计算各个变量之间的相关性。首先对每一列数据进行标准化处理 即每一列的数据减去该列的均值同时除以标准差 公式如下
X*=(x-e(x))/sd(x)
然后采用协方差公式进行相关系数的计算
R(x,y)=cor(x*,y*)=x.y
从相关系数矩阵中我们可以看出,正向情感得分和正向情感词数目,负向情感得分和负向情感次数目 ,正向情感词数目 和负向情感词数据 具有最想的想关性,但是 跟据我们的算法 正向情感得分 就是 根据 正向情感词数据而来的 除非情感词前面加了否定词 此时 说话的语气会变得较为委婉无法揣测真是的情感 如 语句“他成绩不好” 这句话是直接方式的负向情感的表达 如果改为 好 还是 成绩还可以呢,所以 此时 不管是负向情感得分 还是负向情感得分 都为0.但是在情感词数据上 则不为0,这说明用户在说话习惯上产生了不同,有的人说话比较直接,有人说话比较为委婉,所以我们变换特征向量,即让用户情感特征向量的第一列除以第三列,第二列除以第四列,我们将新的特征向量的第一列命名为 正向情感直接系数,第二列命名为负向情感直接系数,情感直接系数反应了用户说话的直接程度,越高 说明用户说话约直接。接下来我们用KMeans聚类算法 对用户进行聚类,以此来验证我们的想法。在使用KMeas 之前 我们首先用散点图 来对数据点的分布进行观察。
从图1中可以看出 数据点的分布近似椭圆形,适合用KMeans算法对数据点进行聚类(因为我们使用欧式距离来对数据点之间的距离进行度量)。同时有非常明显的2个聚类中心,所以在使用KMeans算法时 我们将聚类的数目定义为2[1]。
我们不对数据进行任何预处理的工作,直接对数据进行聚类,聚类效果如下图所示。
我们发现数据点被分成了2个类,Y轴坐标比较大的分为了一类,Y轴坐标比较小的分为了一类,这是因为数据点的Y轴坐标范围比X轴范围大得多,而KMeans算法采用欧式距离来度量数据点之间的差异性,而由于Y轴坐标的范围比X轴大的多,所思数据点之间的差异主要由Y轴坐标决定,所以分类超平面就会垂直于Y轴。这样的聚类效果 显然不是我们想要的。为了使得X轴和Y轴有相同的均值和方差,我们需要对数据继续标准化处理,这样样本点在X轴和Y轴上的均值都将变为0,方差变为1[2]。
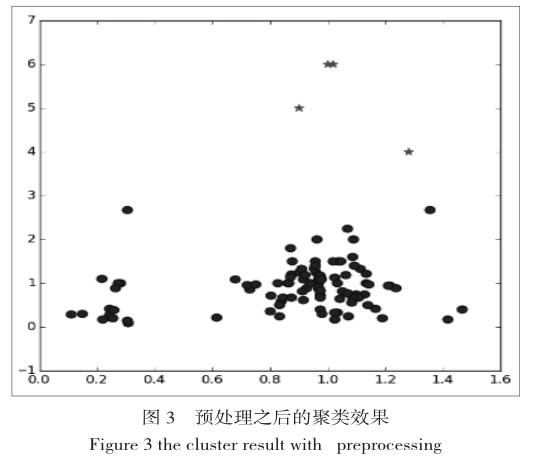
对数据进行标准化处理后 我们用散点图来看下聚类的效果。
可以看到数据被分成了2类,我们对每一类球均值,可以发现 第一类的均值向量为(0.269,0.59) 第二类的均值向量为(1.16,1.01) 第二类的情感直接系数比第一类大了许多,说明第一类人说话较为婉转,第二类的人说话则更为直接。
四、结论以及进一步的工作
我们通过对用户的网络留言数据进行情感分析,得到用户的情感特征向量,
通过用户的情感特征向量,对用户进行聚类分析,通过聚类分析,得到用户的说话的行为习惯。但是本文有些地方做的还是不够细致。
1、在得到用户的情感得分矩阵中,我们使用了基于字典的情感分析方法,对用户的情感进行打分,但是在具体的算法上 显得较为粗糙,没有结合客观情况进行深入分析,如“科比的球技不太好”,这句话利用我们的情感分析算法,得到的情感得分为0,但是这句话其实表达了一种负向情感,因为真是情况是科比的球技很好,所以这句话表达的应该是负向情感。
2、特征较少,没有进行更深入的特征工程构建,只是对用户说话的直接与否进行对用户进行分类,所使用的特征有限,应该更加深入构建用户的情感特征。
参 考 文 献
[1]Christopher Bishop.Pattern Recognition and Machine Learning[M].Americn:spring er,2007-10-1.548-662.
[2]Trent Hauck.Sklearn-coobook[M].England:packer publishing,2014-11-4.66-78.
猜你喜欢
中学生理科应试(2021年11期)2021-12-09
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
数学学习与研究(2018年15期)2018-11-12
小天使·五年级语数英综合(2017年11期)2017-11-30
软件(2017年6期)2017-09-23
电子技术与软件工程(2016年23期)2017-03-06
电脑知识与技术(2016年22期)2016-10-31
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
