
2000年以来我国多语言语料库研究进展
2016-05-14 05:41司莉何依
现代情报 2016年6期
关键词:综述
司莉 何依
〔摘 要〕语料库是指根据一定的方法收集的自然出现语料构成的电子数据库。2000年以来我国对多语言语料库的研究呈现快速上升的趋势。在全面文献调研的基础上,本文对我国多语言语料库的研究现状进行了归纳与梳理。国内学者对多语言语料库的研究多集中于语言学领域,其次是计算机领域。研究主题主要分布在多语言语料库的关键技术研究、多语言语料库的应用研究两大方面。
〔关键词〕多语言语料库;跨语言语料库;平行语料库;可比语料库;综述
〔中图分类号〕G252.8 〔文献标识码〕A 〔文章编号〕1008-0821(2016)06-0165-06
〔Abstract〕Corpus is an electronic database which is composed of the natural corpus collected accordingto a certain method.Since 2000,the research on multilingual corpora in China presented a rapid upward trend.Based on a comprehensive literature research,this paper summarized the current research situation of multilingual corpora in our country.The researches on multilingual corpus were mostly concentrated in the field of linguistics,followed by the computer field.Research topics were mainly distributed in two parts:the key technologies of multilingual corpora and the application multilingual corpora.
〔Key words〕multilingual corpora;cross-language corpora;parallel corpora;comparable corpora;review
语料库是指根据一定的方法收集的自然出现语料构成的电子数据库[1]。按语种划分可分为单语言、双语言和多语言语料库,后两者根据语料的组织形式又可以分为平行语料库和可比语料库。平行语料库,又称对齐语料库,是由原文本和对应的翻译文本构成的语料库,语言之间是完全对等的、互译的,是译文关系,多用于机器学习、双语词典;而可比语料库,又称类比语料库,是表述相同主题的多种语言文本的集合,源语言和目标语言没有严格的翻译关系,多用于语言对比研究,比如针对同一事件不同语言的新闻报道的集合等。
自20世纪90年代初世界上第一个多语言语料库“加拿大议会会议录英法平行语料库”在加拿大建成以来[2],国内外出现了一些多语言语料库,如厦门大学海外教育学院主持开发的英汉双语平行语料库(厦大E-C Corpus)[3]、北京大学中国语言学研究中心开发的汉英双语语料库[4]、北京外国语大学日本研究中心研制的中日对译语料库[5]、香港理工大学研制的双语旅游语料库、上海交通大学的科技英语可比语料库(JDEST)、绍兴文理学院创建的《红楼梦》汉英平行语料库[6]等。国内学者对多语言语料库的研究以双语平行语料库为主,涉及3种及3种以上语种的语料库较少。据笔者统计,英汉语料库的研究文献(包括学术论文、学位论文、会议论文)占总文献的55.9%。语料库的语种以英汉语为主,其次是维汉语,另外还包括俄语、日语、法语、藏语等与汉语的结合。本文研究的多语言语料库包括两种及两种以上语言的语料库。
1 我国多语言语料库研究数量分布
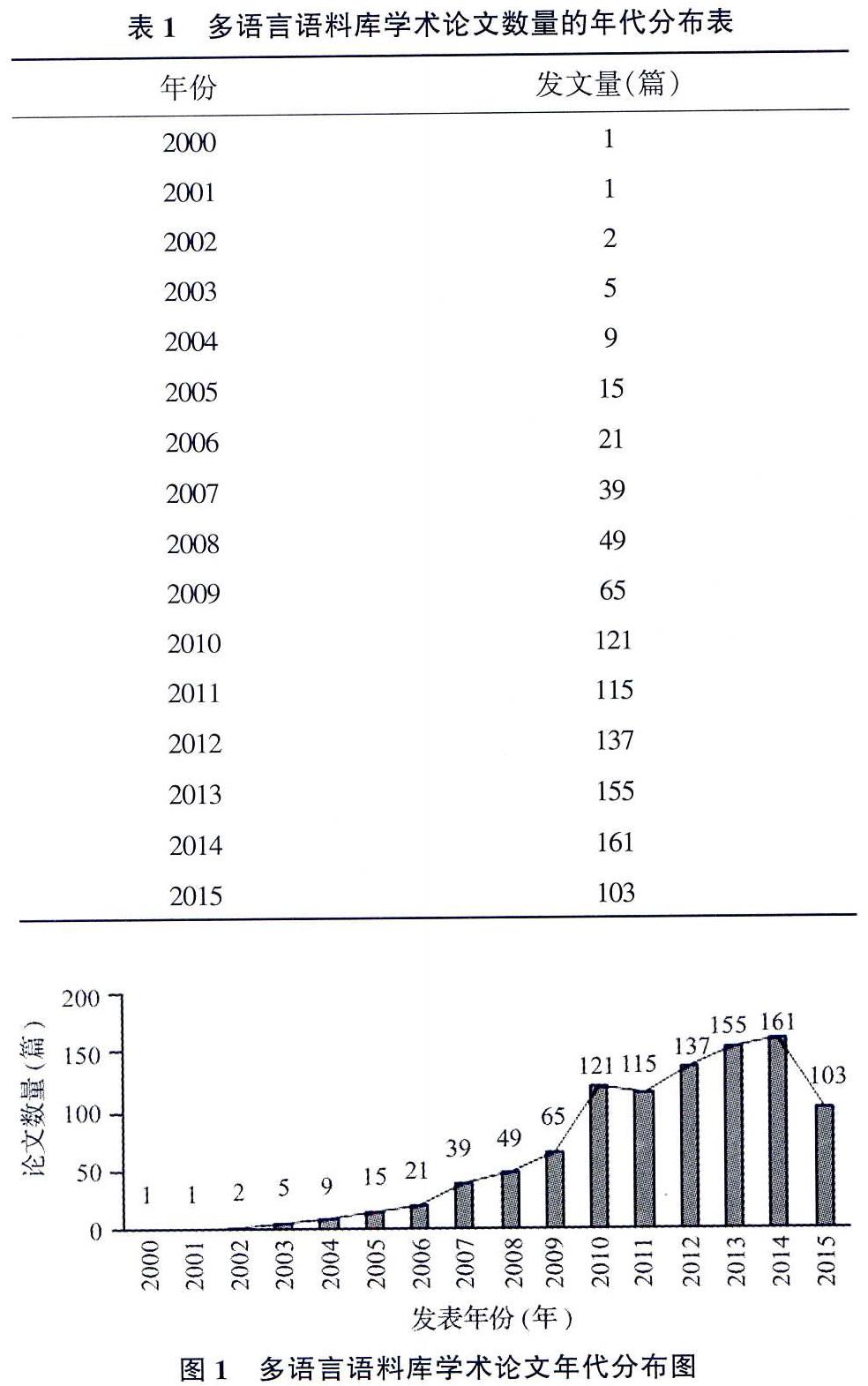
笔者选取CNKI、重庆维普、万方数据库为数据源,以“跨语言语料库”或“双语语料库”或“多语言语料库”或“平行语料库”或“对齐语料库”或“类比语料库”或“可比语料库”为关键词,对期刊论文、会议论文与学位论文进行检索,经筛选得到999篇与“多语言语料库”主题相关的论文,其中学术论文628篇、会议论文51篇、学位论文320篇。具体学术论文数量的年代分布分别如表1和图1所示。
从图1可以看出,2000年以来我国对多语言语料库的研究基本呈快速上升的趋势。笔者将其分为3个阶段,第一阶段为萌芽时期(2000-2004年),这一阶段的发文量较少,年均发文量3.6篇;第二阶段为初步发展时期(2005-2009年),发文数量有所增长,但增幅较慢,年均发文37.8篇;第三阶段为快速发展阶段(2010年至今),发文量大幅提升,共发文792篇,占总文献量的79.2%,年均发文132篇。可见,多语言语料库的研究已引起学界足够的重视,成为领域研究热点。
2 我国多语言语料库研究的主题分布
除了检索各种学术论文外,笔者还以“语料库”为主题词对国家图书馆馆藏书籍进行检索,筛选出32种多语言语料库相关的图书,数据采集时间为2015年11月5日。通过对研究成果的深入研读与归类统计,得出关于我国多语言语料库研究主要集中在多语言语料库关键技术和多语言语料库应用两大方面。
2.1 关于多语言语料库构建的关键技术研究
研究者提出的构建多语言语料库的关键技术主要有3种,分别是语料资源的获取技术、对齐技术、术语抽取技术。此外,还有文本分类技术、去重技术和句子边界识别技术。
2.1.1 语料资源(网页)的获取技术研究
(1)平行网页获取技术研究
平行网页是指存在于两个不同的网页中的、相互翻译的两种语言的网页对,如武汉大学官网的中英文版本网址分别是URL:http:∥www.whu.edu.cn和http:∥en.whu.edu.cn。其网页中包含的高质量双语语料是平行语料库的构建的重要来源,常用URL命名规律或HTML结构信息来发现平行网页。熊文新对“中外对话”环保网站的中英文文本的存放、文件的命名方式及页面的构成规律进行分析,并构建双语平行语料库[7];徐春通过一定的网页分析算法预测候选URL与目标网页的相似度或与主题的相关性,从而抓取平行网页[8];姜子进等根据HTML特征建立HTML树,以HTML树结构来识别网页正文内容的特征,然后根据正文内容信息相似性提取网页[9];莫源源等根据网页内容及候选网页对间余弦相似度等特征和最大熵模型训练的分类器对平行网页进行识别,以获取柬英(柬埔寨语与英语)平行网页[10];刘奇等先利用HTML结构实现平行网页的递归访问,再使用URL模式优化遍历平行网站的拓扑顺序来获得平行网页[11]。
(2)混合网页获取技术研究
混合网页是指互为翻译的文本存在同一个网页内,即网页中既有源语言,又有目标语言。要获取混合网页,就要先检测网页是否含有所需要语种的正文文本。王琳琳分别使用基于Unicode字符编码分布和N-Gram的语种识别两种方法进行句子的语种识别,并进行对比实验,以发现混合网页[12]。
2.1.2 对齐技术与方法研究
对齐是指从互译的语言文本中找到其互译片段的过程,根据对齐粒度的大小可以分为篇章、段落、句子、短语、词等多个层次。国内学者对对齐技术与方法的研究主要集中在词对齐和句子对齐两方面。
(1)词对齐方法研究
张亚军等基于统计方法依次使用IBM模型1、IBM模型2构建出一个词对齐系统[13]。刘鹏远等基于HowNet以及WordNet进行相似度计算,然后设定相似度阈值来进行词义过滤,以改进词对齐技术中的错误累计问题[14]。陈亮提出基于语言模型的多词对齐算法,解决词对齐过程中存在的一对多和多对多的对齐问题[15]。
(2)句子对齐方法研究
张艳与柏冈秀纪提出了以基于长度的统计对齐方法为主,以基于标点的方法作为对齐的后处理部分的汉英句子对齐的扩展方法[16];于新等针对藏文语言的特殊性提出了基于词典的汉藏句子对齐算法[17];塞麦提·麦麦提敏等将词汇信息和长度信息相结合,识别出锚点句对,并将其作为分割标志对全文进行分段,进而实现各片段内的句子对齐[18];才藏太提出了一种藏文句子的边界识别方法,即利用特殊规则和词表对藏文句子进行识别,然后利用最大熵模型对有歧义的句子进一步识别[19];刘智颖建立了句子级语义标注语料库,探讨句子级语义标注语料库的标注内容、标注方法和标注难点[20]。
此外,李康熙从语言学角度出发,重点结合象征单位和翻译单位等概念探讨了双语对齐中存在的问题[21];赵莲提出了基于跨语言信息检索与特征过滤相融合的方法来建立源语言文档与目标语言文档间的对应关系,以确保可比较语料库的对齐质量[22]。
2.1.3 对应单位抽取技术研究
对应单位是指源语言和目标语言文本中任何可以识别的相互对应的语块或者片段,在部分文献中又称为翻译对、互译对,可用于双语词典编纂和统计机器翻译。梁铭对双语语料中的名词和短语进行统计并生成候选术语集,使用翻译概率计算公式计算每个英文候选术语与相关的中文间的翻译概率,并通过设定随词频变化的阈值以及贪心算法来选取中文翻译[23];任高举等提出了一种改进的短语抽取算法,先考虑词对齐矩阵中一个汉语与多个维吾尔语词的对齐情况,然后利用Och的短语抽取算法抽取短语对,最后考虑维吾尔语SOV语序(即主语+宾语+谓语语序)结构特点,抽取双语短语[24];唐亮等提出基于多策略过滤方法,即先从一种语言中抽取多词短语,然后通过一系列过滤措施得到质量较高的单语言多词短语,最后通过相似度计算抽取并整合翻译对[25];刘颖等用正则期望从汉语专利语料库中抽取并过滤汉语短语,利用词对齐工具Giza++和Moses从汉英平行语料库中抽取汉英短语,根据二者的交集得到翻译对[26];严灿勋等基于C#正则表达式的英汉翻译对抽取方法,从机读电子词典、含英汉翻译对的网页等资料中提取有固定模式的翻译对[27];徐会芳从可比较语料库中分别抽取中、英文多词术语,再使用最小化样本风险算法来调节特征权重,得到术语匹配对,并使用阈值限定法过滤正确的术语对[28]。
2.1.4 其他技术研究
其他技术研究涉及文本分类与去重技术。熊超等通过考虑双语平行语料文档与文档、文档与词和词与词之间的语义对应关系,提取原始文档的潜在语义对,构建潜在语义对偶空间,把双语文档映射到此概念空间后,实现跨语言文本分类[29]。申文明等利用整体相似因子和局部相似因子计算句子的相似度,并借鉴KMP算法的匹配思想,提出中文字符串匹配的类KMP算法,以实现平行语料库中形似句子的去重[30]。
2.2 关于多语言语料库应用的研究
多语言语料库常被用于翻译、词典构建、机器翻译、多语信息平台构建和跨语言信息检索中。
2.2.1 在翻译中的应用研究
(1)应用于翻译共性研究
翻译共性是指译文中呈现的有别于原文的一些典型的、跨语言的、有一定普遍性的特征[31]。研究集中在翻译的显化、隐化、简化和范化等方面。董敏与冯德正基于自建的平行语料库,检索与汉语对应的英文逻辑连接词,进而分析英汉翻译逻辑关系显化策略的动因[32];黄立波基于双语平行语料,对汉英和英汉翻译中连接成分和人称代词主语的转换进行考察,以发现语言形式手段差异与翻译中显化和隐化的关系[33];武光军以汉英类比语料库作为实证研究平台,以搭配作为研究对象,分别分析了翻译汉语、英语文本的整体搭配特征,以加深对翻译共性的认识[34]。
(2)应用于词汇及古籍翻译
借助领域多语言语料库对具体词的用法进行分析和研究,能够对译名进行统一与规范,获得作品、短语的最佳翻译方式。易焱与王克非基于英汉、汉英双向平行语料库对现代汉语人称代词“大家”和它在英语中的对应项进行分析,以加强对人称代词在翻译语言中使用规律的认识[35];王子颖利用中国大陆和香港法律法规汉英平行语料库,研究了shall和may两个情态动词在肯定和否定形式下的不同用法[36];胥逸萌选取5年的《政府工作报告》建立了一个小型双语平行语料库,研究报告的翻译团队对“推进”一词的用法[37];刘克强基于自建的《儒林外史》汉英句对齐平行语料库,对该书中服饰、习俗、戏曲等方面的翻译进行分析[38]。
(3)应用于译者风格研究
通过语料对比分析,可以考察译者在传承原作风格之外的自我显现。刘泽权利用语料库检索软件将《红楼梦》的4个英译本在词汇和句子层面的基本特征进行数据统计和初步的量化分析,比较其在翻译风格上的异同[39];宋伟华通过自建的《六祖坛经》汉英平行语料库对该部典籍最早的两个英译本进行分析,探讨导致两个译本方式不同的因素[40];卢晓娟根据鲁迅小说的3位不同译者的英译本建立语料库,从译者所运用的翻译策略、翻译风格等角度,探讨影响译者风格形成的因素[41]。
(4)应用于翻译教学
多语言语料库可以为教学翻译提供句子及篇章级的英汉对译,提高课堂教学效果。香港城市大学开发了“英汉汉英翻译远程教学系统”,以篇章语言学、系统功能语言学、文体学和话语研究等为理论支撑,对语料进行手工标注[42]。贺文照使用平行语料库和词典等常规参考资源作为实验组和对照组进行实证研究,发现平行语料库能提高翻译的工作效率和质量[43];蒋丽平以某IT学院大三的软件开发专业学生为实验对象,来验证IT英汉平行语料库在辅助翻译的质量和效率[44]。熊兵研究了英汉双语平行语料库的翻译教学模式,并重点分析翻译教学模式的教学内容编排、实施原则及操作方式等问题[45]。
2.2.2 在双语词典构建中的应用研究
多语言语料库的建立方便了词典编撰,如《新时代英汉大词典》是我国国内借用现代语料库研编大中型英汉词典的开山之作[46]。曾文等在实现汉英句子级对齐后,对双语语料分别进行分词和词性标注处理,通过抽取汉英词语单元并计算其关联概率来实现汉英的词语对齐,生成双语词典[47]。吴玥在可比语料库双语词表构建的基础上,提出了基于依存上下文来构建中-英词表的方法[48]。安纪霞等以对数相似性模型为基础,采用迭代策略实现了翻译词典获取,并在自建的小型英汉平行语料库《测试语料》上进行了相应的试验[49]。李德俊探讨了基于语料库的词典编纂系统的方法[50]。刘克强以《水浒传》4个英语全译本为对象,在建立平行语料库基础上编写了《水浒传翻译大辞典》[51]。
2.2.3 在机器翻译中的应用研究
平行语料是机器翻译模型不可缺少的训练数据,机器翻译系统能从语料库中自动提取与待翻译语句相同或相近的例句,并模仿例句自动生成译文。黄瑾在已有的双语平行语料库中选出与待翻译文本相似的数据构造自适应的训练语料,再通过加权调整已有资源的数据分布,在不增加大数据规模的基础上生成更为优化的模型参数,以提高机器翻译的质量[52]。刘粤钳与姚红玉用《人民日报》中、法文网络版的部分文章建立一个小型的汉法平行语料库,然后利用改进的Yamada算法构建了一个汉法机器翻译系统[53]。李梅等针对机器翻译时出现的典型性错误,进行二次加工,即做译后编辑的自动化处理以过滤这些典型性错误,从而加快机译速度并提高机译质量[54]。
2.2.4 在信息服务平台构建中的应用研究
王传英利用双语平行语料库二次开发图书馆公共信息服务平台,以解决读者利用文献时语言障碍问题,并辅助读者阅读、写作[55]。赵衍以中英文平行语料库为基础,设计了一种跨语种的Web产品评论挖掘系统,并将其应用于高尔夫轿车的产品性能挖掘[56]。纳吉米设计与实现了汉维哈平行语料库系统的文档导入及对齐功能,以构建面向电力行业信息系统的汉维哈自动翻译引擎[57]。
2.2.5 在跨语言信息检索中的应用研究
多语言语料库是跨语言信息处理的重要资源。房璐等从多语言语料库中抽取翻译知识,并应用于跨语言信息检索系统的查询翻译中,以改善跨语言信息检索的性能[58]。罗远胜等基于双语平行语料库中两种语言的潜在语义空间,提出双语偏最小二乘双语主题相关模型,以克服跨语言潜在语义索引模型中存在的不足[59]。邹小芳等基于自建的中英平行语料库和蒙特利尔大学的英法平行语料库,对平行文档进行分析建模,提取语言之间的潜在语义对应关系,在潜在中间语义空间中进行检索[60]。胡小鹏等利用n-元词串、关键词簇等自动抽取技术挖掘三元组可比语料库中本族语言模型的双语资源,改进和发展跨语言处理应用[61]。
3 总 结
2000年我国研究者开始关注多语言语料库,15年来其研究热度持续上升。本文在大量的文献调研基础上,对我国多语言语料库的研究进展进行了分析。在学科领域上,语言学领域对多语言语料库的研究最多,其次是计算机领域。具体来说,语言学领域主要是利用多语言语料库来研究语言翻译问题,即探讨基于语料库的特定领域、不同语种之间的翻译以及翻译教学研究,部分语言学学者会自行构建小型多语言语料库来辅助研究。计算机科学与图书情报领域则更多的聚集多语言语料库的关键技术方面,包括针对语料库中某个技术的实现提出具体的解决方案、新的算法以及多语言语料库的应用问题等。
通过对文献的主题分析发现,我国对多语言语料库的研究大致可以分为两大块,一是多语言语料库关键技术的研究;二是多语言语料库应用研究。在构建多语言语料库的过程中,研究得最多的技术是网页获取技术、对齐技术和术语抽取技术。网页获取技术是多语言语料库的语料来源,是构建多语言语料库的基础;对齐技术、术语抽取技术可广泛应用于多语词典、不同语种的同义词词表和机器翻译中,但是术语抽取技术对多语言语料库的数量、质量、精确度要求较高。多语言语料库的应用以翻译、词典构建、机器翻译为研究热点。在未来,要加强多语言语料库的评价研究,提出定量和定性的评价指标,以提高语料库的构建质量。此外,丰富的网络信息资源已为可比语料库的发展提供了契机,通过爬虫工具可以从互联网上获得大量的可比较文本,未来还应加强对可比语料库关键技术、构建方法的研究。
参考文献
[1]胡开宝.语料库翻译学概论[M].上海:上海交通大学出版社,2011.
[2]王克非,黄立波.国外双语库研制与应用评析[J].外语电化教学,2012,(6):3-10.
[3]英汉双语平行语料库.检索页面[EB/OL].http:∥www.luweixmu.com/ec-corpus/query.asp,2015-11-15.
[4]北京大学中国语言学研究中心.CCL汉英双语语料库[EB/OL].http:∥ccl.pku.edu.cn:8080/cclcorpus/,2015-11-15.
[5]北外语料库语言学.语料库语言学年表[EB/OL].http:∥www.bfsu-corpus.org/content/chronology-corpus-linguistics-yu-liao-ku-yu-yan-xue-nian-biao,2015-11-15.
[6]《红楼梦》汉英平行语料库[EB/OL].http:∥corpus.usx.edu.cn/hongloumeng/,2015-11-15.
[7]熊文新.Web、语料库与双语平行语料库的建设[J].图书情报工作,2013,(10):128-135.
[8]徐春.汉、英平行语料库的研究与构建[J].科技信息,2011,(17):104-105.
[9]姜子进,吐尔根·依布拉音,赛依旦·阿不力米提,等.Web环境下自动获取汉、维语料库[J].计算机应用与软件,2011,28(12):19-21,70.
[10]莫源源,潘丽同,严馨,等.基于最大熵模型的柬英平行网页获取[J].计算机工程,2015:1-8.
[11]刘奇,刘洋,孙茂松.URL模式与HTML结构相结合的平行网页获取方法[J].中文信息学报,2013,27(3):91-99.
[12]王琳琳.面向Web的多语平行句对挖掘技术研究[D].黑龙江:哈尔滨工业大学,2014.
[13]张亚军,贺琛琛.汉语-维吾尔语的一对一词对齐研究[J].昌吉学院学报,2012,(6):80-83.
[14]刘鹏远,赵铁军,李生,等.利用语义相似度解决双语词汇知识获取的错误累计问题[J].哈尔滨工程大学学报,2006,27(z1):575-579.
[15]陈亮.基于英汉平行语料库的机器翻译知识获取研究[D].北京:北京交通大学,2012.
[16]张艳,柏冈秀纪.基于长度的扩展方法的汉英句子对齐[J].中文信息学报,2005,(5):31-36.
[17]于新,吴健,洪锦玲.基于词典的汉藏句子对齐研究与实现[J].中文信息学报,2011,25(4):57-62.
[18]塞麦提·麦麦提敏,侯敏,吐尔根·伊布拉音.基于锚点句对的汉维句子对齐方法[J].计算机工程,2015,(4):166-170.
[19]才藏太.基于最大熵分类器的藏文句子边界自动识别方法研究[J].计算机工程与科学,2012,34(6):187-190.
[20]刘智颖.基于HNC的现代汉语句子级语义标注语料库的研究和建立[M].北京:中国社会科学出版社,2015.
[21]李康熙,杨勇.平行语料库对齐技术的语言学思考[J].合肥工业大学学报:社会科学版,2009,23(3):83-86.
[22]赵莲.大规模中英可比较语料库构建[D].辽宁:大连理工大学,2010.
[23]梁铭.基于英汉平行语料库术语词典的自动抽取[J].电脑知识与技术:学术交流,2009,5(7):5081-5083.
[24]任高举,吐尔根·伊布拉音,艾山·吾买尔.统计机器翻译中汉维短语对抽取的研究[J].新疆大学学报:自然科学版,2010,27(3):349-352.
[25]唐亮,李倩,许洪波,等.基于多策略过滤的汉日多词短语抽取和对齐[J].山东大学学报:理学版,2015,(9):21-28.
[26]刘颖,铁铮,余畅.汉英短语翻译对的自动抽取[J].计算机应用与软件.2012,29(7):69-72.
[27]严灿勋,刘慧敏,宋兰.基于C#正则表达式的英汉翻译对抽取[J].科技信息,2011,(26):1-2.
[28]徐会芳.可比语料中双语多词术语互译对抽取方法研究[D].辽宁:大连理工大学,2013.
[29]熊超,王明文,吴福英,等.基于潜在语义对偶空间的跨语言文本分类研究[J].广西师范大学学报:自然科学版,2010,28(1):157-160.
[30]申文明,黄家裕,刘连芳.平行语料库的相似语句去重算法[J].广西科学院学报,2009,25(4):248-250,256.
[31]柯飞.翻译中的隐和显[J].外语教学与研究:外国语文双月刊,2005,37(4):303-307.
[32]董敏,冯德正.英汉科技翻译逻辑关系显化策略的语料库研究[J].外语教学,2015,36(2):93-96.
[33]黄立波.基于汉英/英汉平行语料库的翻译共性研究[M].上海:复旦大学出版社,2007.
[34]武光军.基于汉英类比语料库的翻译文本中的搭配特征研究[M].北京:中国社会科学出版社,2014.
[35]易焱,王克非.基于平行语料库的“大家”的对应研究[J].外语与外语教学,2013,(3):49-54.
[36]王子颖.法律语篇中shall和may的翻译对比研究[J].上海翻译,2013,(4):52-57.
[37]胥逸萌.《政府工作报告》中“推进”的概念隐喻用法实证研究[J].读与写:教育教学刊,2012,(8):34-35.
[38]刘克强.儒林外史语词典型翻译——基于平行语料库的研究[M].北京:光明日报出版社,2015.
[39]刘泽权,刘超朋,朱虹.《红楼梦》四个英译本的译者风格初探——基于语料库的统计与分析[J].中国翻译,2011,32(1):60-64.
[40]宋伟华.《坛经》黄茂林英译本与Dwight Goddard英译本比较[J].中国科技翻译,2013,(1):19-22.
[41]卢晓娟.语料库驱动下的鲁迅小说译者风格研究[M].北京:中央编译出版社,2015.
[42]王惠.“精加工”平行语料库在翻译教学中的应用[J].中国翻译,2015,(1):50-54.
[43]贺文照.平行语料库辅助翻译实践实证研究[J].嘉兴学院学报,2013,25(2):64-69.
[44]蒋丽平.IT文本英汉平行语料库辅助翻译实践的实证研究[J].中南林业科技大学学报:社会科学版, 2014,8(4):110-113.
[45]熊兵.基于英汉双语平行语料库的翻译教学模式研究[J].外语界,2015,(4):2-10.
[46]吴晓昱,王安民.平行语料库与汉英词典编纂的对接[J].译林:学术版,2012(2):169-176.
[47]曾文,王惠临,徐红姣.汉英双语词典的自动构建技术研究[J].情报学报,2011,30(4):402-409.
[48]吴.基于依存上下文的中-英词表构建方法[J].信息通信,2013,(7):95-96.
[49]安纪霞,李锡祚,宋冰,等.服务于词典编纂的特定领域专业术语自动抽取[J].计算机与数字工程,2007,(11):53-56.
[50]李德俊.语料库词典学[M].江苏:译林,2015.
[51]刘克强.水浒传翻译大辞典[M].北京:中央编译出版社,2014.
[52]黄瑾,吕雅娟,刘群.基于信息检索方法的统计翻译系统训练数据选择与优化[J].中文信息学报,2008,22(2):40-46.
[53]刘粤钳,姚红玉.一类基于平行语料统计的汉法机译解决方案[J].计算机技术与发展,2008,18(4):114-117.
[54]李梅,朱锡明.译后编辑自动化的英汉机器翻译新探索[J].中国翻译,2013,(4):83-87.
[55]王传英.基于双语平行语料库的信息服务平台建设[J].图书馆工作与研究,2010,(12):79-82.
[56]赵衍.基于中英文平行语料库的Web产品评论挖掘[J].上海管理科学,2012,(5):42-46.
[57]尼加提·纳吉米.面向电力行业的汉维哈文档对齐工具的设计与实现[J].电脑知识与技术,2014,(36):8657-8658,8663.
[58]房璐,葛运东,洪宇,等.可比较语料库构建及在跨语言信息检索中的应用[J].广西师范大学学报:自然科学版,2010,28(3):126-130.
[59]罗远胜,王明文,勒中坚,等.跨语言信息检索中的双语主题相关模型[J].小型微型计算机系统,2013,34(12):2758-2763.
[60]邹小芳,王明文,左家莉,等.新的基于中间语义的多语言信息检索模型[J].小型微型计算机系统,2010,(4):696-701.
[61]胡小鹏,袁琦,耿鑫辉,等.构建和剖析中英三元组可比语料库[J].计算机工程与应用,2014,(13):153-157,186.
猜你喜欢
文化创新比较研究(2020年8期)2021-01-22
装备制造技术(2020年2期)2020-12-14
文化创新比较研究(2020年8期)2020-01-02
电子制作(2019年10期)2019-06-17
电子制作(2019年24期)2019-02-23
石油沥青(2018年6期)2018-12-29
NBA特刊(2018年21期)2018-11-24
自动化学报(2017年11期)2017-04-04
功能高分子学报(2016年1期)2016-04-26
法医学杂志(2015年2期)2015-04-17
