
自动混音技术探索(上)
2016-05-14 12:26
信息化视听 2016年6期
自动混音技术并不是一项新技术,从上个世纪70年代开始涌现各种类型的自动混音器,以及其中的各种专利到现在转变为DSP设备内的一个功能。自动混音器的形态也正逐渐从一台独立的设备到虚拟的编程算法。虽然现在各家的软件算法,并不会公布,但我们可以通过了解自动混音器内的核心技术和原理来更好地理解和使用DSP内的自动混音功能。这也是本文写作的目的。
为什么要用自动混音技术?
要探讨这个问题我们将以自动混音技术最常用的场合——会议室来谈。首先我们看下图一个标准的会议室的照片。
图中我们可以清晰的得到以下三点:
1.话筒数量多。一个几十平米的会议室往往需要塞下十几只甚至更多的话筒。音响工程师调试时都会遇到一个现象:一只一只话筒调试到不啸叫,但是开启两只或更多话筒时就莫名其妙的啸叫起来。这也是音响人经常提的一个定律:打开话筒数量增加一倍,系统增益增加3dB,即NOMG(Number of Open Microphone Gain)=10lg(NOM),如右图 :
为了能够同时打开足够多的话筒和确保系统的稳定,越多的话筒我们得调越多的系统余量。同时由于打开话筒越多拾取的环境噪音也越多,导致系统的信噪比下降,无法获得足够的语言清晰度。
2.不注重声学装修。不论是哪种厅堂更注重肯定是视觉,装修一定要好看,大气,庄重等。会议室也不例外,且很多会议室甚至是全玻璃结构的根本不考虑扩声的需求。等到真正使用扩声时,才发现房间反射严重,根本没法获得足够的语音清晰度和传声增益。。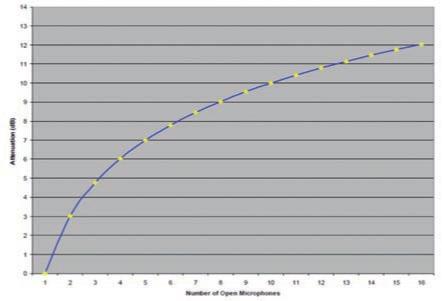
3.话筒正对着音箱。会议室是一个面对面交流的地方,听者和说话者都在一个空间内,那这样也就意味着扩声扬声器覆盖的区域同时又需要话筒进行拾音,所以在会议室内几乎都会遇到话筒正对音箱的情况。这样直接导致我们无法获得足够的传声增益。
通过以上三个问题我们可以看到一个矛盾点:话筒多需要为系统留足够的余量,但建声环境和音箱话筒摆位又无法为系统提供足够的余量。如何化解这个矛盾成为关键。第一个问题,不注重声学装修,反射严重,人们的习惯很难改正,也正是因为这点,现在会议室越来越流行采用可调指向的音柱进行扩声,从一定意义上减少了部分反射,当然这一部分内容并不是本文探讨的范畴,总之第一个问题我们几乎没什么可商量的余地,但这却是最好的解决方法;第二个问题,话筒正对音箱可以通过MIX-MINUS的系统设计,在一定程度上得到提高,但效果有限。摆在我们面前的只有从第三个问题出发了,既然打开话筒越多会增加更多的系统增益,那我们就想办法控制打开的话筒数量和减少因开启话筒增加而增加的增益。那我们来看一下一般的现在有哪几种解决方法:
1.调音师现场调控。调音师是最佳的人选来控制会场的话筒和音量。但是问题是当话筒超过6只,甚至几十只话筒时,而且会议持续几个小时之久时,事情就没有那么简单了。如何来判断某个参会人员要发言也是个问题,有时调音师也无法清楚地看到每一个参会者,很容易犯错。纵使我们能找来一个很厉害的调音师能解决以上问题,但是如果我们有很多的会议室时,给每一个会议室配备一个如此高水准的调音师也是不合理,且其成本是无法承受的。
2.会议系统。很多会议室会选择会议系统进行话筒的管理和限制。通过限制话筒开启数量确实能一定意义上减少对余量的需求。但某些会议中为了限制的数量可能会影响会议的流畅度。会议系统的音质,是让很多使用者和音响工程师所诟病的。同时会议系统往往混音一路的输出到处理设备,均衡话筒时将对所有话筒进行调整,然而实际每个话筒的均衡点都是不一样的,而且还经常会遇到,调完某个话筒,其他某个某几个话筒啸叫起来等现象。最终导致音质更差,且浪费很多调音师宝贵的时间。
3.自动混音技术。自动根据电平开启或关闭话筒,能够自动平衡因开启话筒数量成倍而增加的系统增益。其实与第一种方式很相似,只不过此时人变成了设备。那此时由于能减少对余量的需求,且话筒采用的是鹅颈话筒的形式,最终出来的声音会比会议系统好很多。但实际上单台的自动混音器其实与会议系统类似,最终也是混音一路到处理设备进行处理。这样的处理形式其实与会议系统一样存在问题。所以我们一般会推荐给客户使用的是带自动混音器功能的DSP设备每只话筒都可以得到相应精准的调试,这样音质最优化,同时某些具备自动混音器直接输出功能,可轻松做到MIX-MINUS,而这一点也是普通自动混音器或会议系统几乎无法实现的。且由于可以结合DSP自身丰富的功能,实现诸多会议系统的功能如主席优先,请求发言,摄像跟踪等等。
综上3种解决方案,会议中多话筒处理既能达到较好的音质,保证系统稳定,又能实现较多会议管理功能的最好方案是采用DSP设备的自动混音功能。了解完为什么需要使用自动混音技术后下面就自动混音技术的分类和技术进行阐述。
自动混音技术分类
从前文我们可以得到自动混音器需具2个基本要素:1. 何时及如何开启和关闭话筒;2. 如何平衡NOM增益。从技术上可以分为两类:Gating和Gainsharing自动混音器。
Gating
Gating自动混音器顾名思义会有一个门限来控制话筒的开关,声音超过门限则打开话筒,声音低于门限则关闭话筒。那如何来获得最佳的门限(Threshold)?
固定阈值:最简单也是最常见的就是采用一个语音触发开关或噪声门,设定一个固定的值,超过这个值则话筒开启,低于则关闭。通常这个值是可以调整的,但无法根据环境噪音自行调整,所以得到的效果往往不尽意。可参见下图:
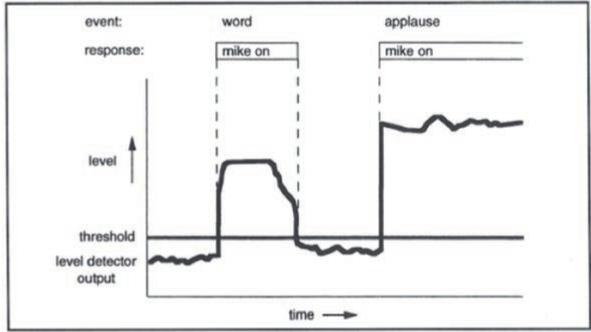
在很多情况下如果设置得太小,则环境噪音、鼓掌和某些音乐等声音很容易就可以开启话筒。设置得太高则又很容易出现吃字或声音卡壳等现象。当使用噪声门等装置还有另外一个问题就是当全体鼓掌的情况出现时,所有话筒都被打开,系统极其容易产生啸叫。由于固定阈值实现简单,成本低,很多自动混音器和软件化的自动混音器仍旧采用类似的方法来做决策,其最终的效果往往很差。
自适应阈值:由于固定阈值很难得到较好的效果,各家厂商相继推出了自己的自适应阈值电路或算法,可根据环境噪音实时得到新的阈值,最终效果的好坏也各有差异。基本示意可参见下图: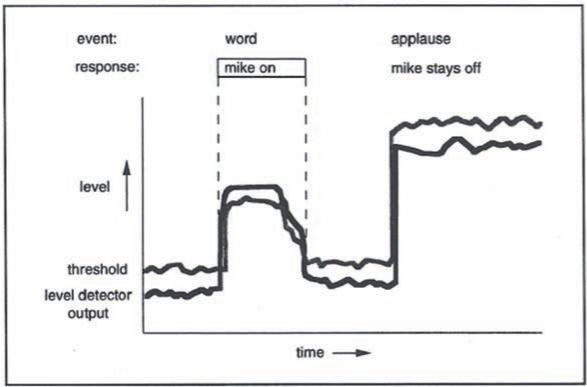
自适应阈值的工作原理各有差异,但归结起来有一下几种类型:
1. 噪声感应。如给每个话筒都加一个噪声感应的话筒,作为其环境噪声的判断水平。有些采用一组话筒或一个混音器一个感应话筒的输入作为参考环境噪音水平。这种方法是最直接的思考方式,但对感应话筒的位置摆放要求较高。早期舒尔曾经出过需要匹配相应麦克风的自动混音器。
2. 扫描阈值。由于噪声感应的额外投入,涌现出了各种通过扫描当前每只话筒的电平然后确定一个阈值的电路或算法。而这正是体现厂家自动混音技术优劣的技术关键点。简单的直接求平均作为阈值,也有不断向下扫描,当遇到最大的电平的通道则在该通道保持一个很短的时间,以此往复。做得不好的阈值电路和算法可能就会出现常见的“吃字”现象。当使用这种方式时的好处是显而易见的,调试人员将不需要去设置阈值,将节省大量的调试时间。
门控技术:在解决完阈值的设定问题后,实际在早期设计自动混音技术还遇到一个问题就是开关所带来的电子脉冲声音。这也是早期限制自动混音器推广的原因之一。目前而言主流的厂商都是采用offattenuation的方式来实现话筒的开关。off-attenuation实际就是将开关变成了通道的衰减。我们知道0dBu的信号输出当我们衰减-40dBu以后将几乎听不到任何的声音。所以通过这种方式就很好的解决了话筒开关而带来的噪音。
NOMA(Number of Open Microphone Attenuation):前面我们讨论的主要是阈值如何确定,以及确定了阈值后话筒如何开关的技术手段。我们还有最后一个问题,多个话筒开启后增加的增益如何解决?一般而言Gating自动混音器都会采用如下的电路来实现总体增益的平衡。采用一个计数器来记录当前开启话筒的数量,然后根据数量进行相应的总增益衰减。如开启两只衰减3dB,开启四只衰减6dB。
那前面我们谈的NOMG=10lg(NOM),这是一个标称上的增益增加。但是我们没有将信号的相干性考虑进去。在一个标准的会议室,不同的讲话者使用不同的话筒,信号进入各自的麦克风通道,这两者我们普遍意义上理解为“不相干信号”。当一个讲话者同时对着距离相等的两个话筒,则在话筒端将接收到两个完全一样的信号,我们称此为“相干信号”。相干信号在电平上不一定要相等,但大小相差一定是很小的。另一个相干的例子就是当会议室的门被用力的开关,书本掉在地上,或大家的鼓掌声等很有可能在两个或多个话筒出产生类似大小的信号。关于两个信号叠加加入相位的考虑实际我们开启话筒数量的系统增益是: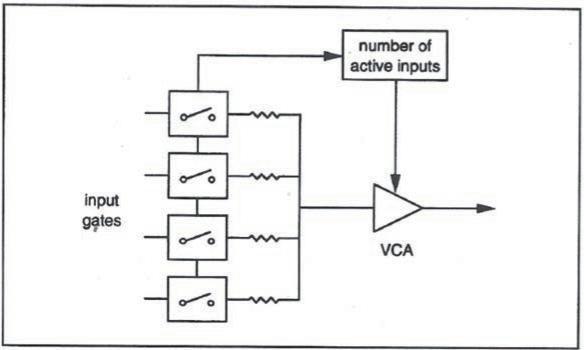
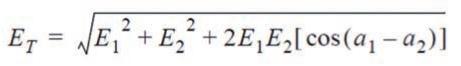
Et:总声压、电流、或电压
E1:第一个信号
E2:第一个信号
α:信号的相位角
由上我们可以得出实际两个信号的叠加是0~6dB的增益增加。基于此部分厂商在做NOMA电路时将此值开放作为可调,但是当作为可调时就增加了工程师调试时的调试参数和对技术的理解,且由于3~6dB的增加往往是较少情况出现,如果为了部分极少出现的情况而大大降低我们的系统增益是得不偿失的。所以很多厂商会采用中间默认为3dB的衰减。这种方式带来的另外一个问题是开启多只话筒可能多的增益,可能的啸叫。则为了避免此问题我们在调试Gating自动混音器时还需要注意在FSM(反馈稳定余量)6dB的基础上再增加至少3dB的系统余量来保证系统的稳定运行。(未完待续)
猜你喜欢
食品工业(2020年8期)2020-08-25
小学生优秀作文(低年级)(2020年6期)2020-07-06
电子制作(2019年7期)2019-04-25
艺术评论(2018年8期)2018-12-28
电子世界(2017年15期)2017-08-30
意林(2016年14期)2016-08-18
通信技术(2011年3期)2011-03-06
民间故事选刊·上(2001年3期)2001-06-14
