
云存储中大数据优化粒子群聚类算法
2017-03-01 10:56王东强王晓霞
电子设计工程 2017年2期
王东强,王晓霞
(青岛农业大学 理学与信息科学学院,山东 青岛 266109)
云存储中大数据优化粒子群聚类算法
王东强,王晓霞
(青岛农业大学 理学与信息科学学院,山东 青岛 266109)
对云存储系统中的大数据进行优化聚类设计,降低存储开销,提高数据管理和调度能力,传统方法中对云存储大数据聚类方法采用量子进化方法,当量子群个体存在非线性偏移时,数据聚类存在局部收敛,导致聚类准确度降低。提出一种基于优化粒子群算法的云存储中大数据优化聚类算法,进行了云存储大数据聚类的原理分析,在传统的模糊C均值聚类的基础上,采用粒子群聚类算法进行大数据聚类算法改进设计,把数据的分割转化为对空间的分割,得到云存储系统中海量数据的模糊聚类中心矢量,采用粒子群聚类方法对聚类数据的离散样本进行动态分配,得到数据聚类的信息素浓度,结合粒子群优化聚类的约束条件,求得云存储中大数据聚类的中心最优解。仿真结果表明,采用该算法进行云存储中大数据优化粒子群聚类,数据聚类的聚类准确度高,收敛性能较好,能在较短的迭代步数下计算得到最优解,在模式识别等领域展示了较好的应用价值。
云存储;粒子群;大数据;聚类算法
随着云计算的出现,云存储服务的诞生与发展,基于云存储系统的大数据云计算为云用户提供了廉价的存储空间[1]。从分配与数据管制形式来看,云存储能够划分成公共云、私有云及混合云等类别。经过云计算,将云存储系统里的资源数据实行统一调度与信息处置,经过资源融合,使用云网格估算,将一个须要相当大的估算问题划分为很多小的部分,然后将这些局部一个一个分散到很多低性能的计算机来处置,达成以虚拟化为关键的云平台架构,通过云存储实现大数据的调度和管理,大数据调度的重要基础是进行数据聚类,数据聚类是实现模式识别的根本。
传统方法中对云存储系统中的数据聚类方法主要有基于FCM的数据聚类算法、基于支持向量机SVM分解的数据聚类算法和基于BP神经网络控制的数据聚类算法等[2-3],但是传统方法在数据聚类过程中容易陷入局部收敛,导致聚类的准确度降低,对此,有关文献实行了算法改进,当中,文献[4]提出基于混沌差分进化的云存储系统大数据聚类算法,采用层次聚类进行大数据的特征提取,在层次聚类过程中随着类别层次的变化导致聚类中心矢量偏移,性能不好。文献[5]中,对云存储大数据聚类方法采用量子进化方法,当量子群个体存在非线性偏移时,数据聚类存在局部收敛,导致聚类准确度降低[6-7]。文中提出一种基于优化粒子群算法的云存储中大数据优化聚类算法,首先进行了云存储大数据聚类的原理分析,在传统的模糊C均值聚类的基础上,采用粒子群聚类算法实行大数据聚类算法改革设计,最后经过仿真实验实行了性能检验及证明,展现出了文中算法在实际大数据聚类里的优越性能,得出有效性结论,在模式识别等领域展示了较好的应用价值[8]。
1 问题描述和云存储大数据聚类算法原理
1.1 云存储及大数据聚类问题描述
云存储系统是云计算的核心问题之一,构建云存储及大数据聚类算法,将资源多源性简化为单一资源进行重构,提高云计算中多源信息资源的高效分配[9-11]。在云计算大数据管理中,需要对大数据进行数据聚类,通过数据聚类,提高数据的调度和扩展能力,在云存储系统中,需要构建云存储系统,典型的大数据云储存系统模型设计如图1所示。

图1 典型大数据云存储结构模型构建

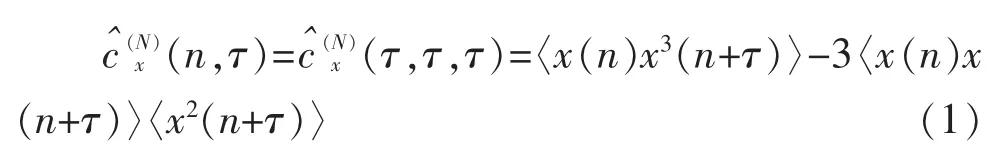
其中,云存储的样本集x={x1,x2,…,xn}数据分析的聚类中心{a1,a2,…,ak},在第k+1次迭代过程中的粒子群的聚类中心矢量为:

其中ws和we表示云存储系统的惯性权值,取值分别为0.95和0.4,在上述模型设计的基础上,进行云存储中大数据聚类算法研究,提高数据的聚类性能。
1.2 云存储系统中的大数据聚类原理分析
在大数据环境下,对信任节点的数据种类进行区分治理,数量非常少的一类被叫作少数类,而另一类就被叫作多数类,具备这样特点的两区分数据集则被叫作是不平衡的[12-15]。文中在传统的模糊C均值聚类的根本上,使用粒子群聚类算法实行大数据聚类算法改进设计,首先给出传统的模糊C均值聚类算法设计模型,算法具体描述如下:
在云计算存储系统中,假设有限特征解的海量数据集:

用基于M-Learning学习网络局部性交叉性信息链模型,得到云存储系统中的海量数据集合中含有n个样本,数据的分割成均匀分布的粒子群,得到聚类样本xi,i=1,2,…n的特征矢量为:

采用解析排队模型进行数据聚类的信道补偿,把有限数据集合X分为c类,其中1<c<n,通过上述处理,把数据的分割转化为对空间的分割,得到云存储系统中海量数据的模糊聚类中心矢量为:

其中vi为存储结构中心的第i个特征向量,(第i个聚类中心矢量)。大数据特征聚类中心VMi的聚类划分矩阵表示为:

通过定义,得到模糊C均值聚类算法,在大数据调度环境下,采用粒子群聚类方法对聚类数据的离散样本进行动态分配,得到数据聚类的信息素浓度为:

式中,m为权重指数,(dik)2为样本xk与Vi的大数据的存储结构中心矢量,用欧式距离表示,为:

数据聚类中心的粒子最优解为:

结合约束条件,采用李雅普诺夫极限定理,求云存储中大数据聚类的中心极值为:

对上述求最优解,得到数据聚类中心,进行数据聚类。
2 基于优化粒子群算法的大数据聚类改进
在上述进行云存储系统结构模型构建和模糊C均值聚类算法描述的基础上,进行粒子群聚类算法改进设计,对云存储系统中的大数据进行优化聚类设计,降低存储开销,提高数据管理和调度能力,传统方法中对云存储大数据聚类方法采用量子进化方法,当量子群个体存在非线性偏移时,数据聚类存在局部收敛,导致聚类准确度降低。为了克服传统方法的弊端,文中提出一种基于优化粒子群算法的云存储中大数据优化聚类算法。
假设在D维大数据云存储聚类特征空间中,有m个粒子组成一个种群,当扰动序列加入种群中,影响了聚类精度,对此,文中把数据聚类问题转化为一个多目标优化问题,云存储中大数据聚类的数学描述如下:

其中,fi(x)(i=1,2,…,n)为目标函数,gi(x)系统有两个不稳定的1周期点x=0和x=1-1/μ,hj(x)为等式约束。这里,引入混沌粒子群扰动概念,得到决策变量x*支配的聚类中心的特征解为:

为了避免粒子陷入局部最优,对于每个大数据信息特征矢量Xi进行存档,为:

其中,fi是Pareto最优解,Pij(k)表示 k时刻第i个决策变量,不等式fi(X*)≤fi(X)成立,其中i=1,2,…,n,设置聚类的阈值Nth,当Neff<Nth时,搜索区域的Oα和Oβ两个区间的聚类正确的概率为:

采用粒子群跳数改进机制进行存储库中的粒子更新,粒子群跳数改进机制原理如图2所示。
图2 粒子群跳数改进机制原理
更新粒子群中每个粒子的空间位置

其中,xk为搜索该区域内的惯性权重,a为聚类中心的非劣解,de为极值点到非劣解的距离,在评估解集分布的均匀程度时,计算按最优聚类中心矢量函数,根据模因组中的更新迭代顺序,得到:
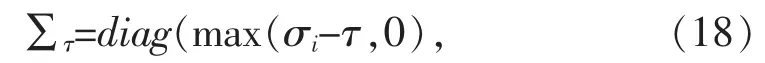
由此得到云存储中大数据聚类的粒子适应度函数为:

其中,{α,β}为分集聚敛目标函数,通过优化PSO聚类方法实现对云存储中大数据聚类,由此实现算法改进。算法改进实现流程如图3所示。
3 仿真测试分析
最后通过仿真实验对本文设计的数据聚类算法进行性能测试和验证,实验的计算机硬件环境为:处理器Intel(R)Core(TM)2 Duo CPU主频2.93 GHz,内存2 GB。操作系统:Windows 7。采用Matlab数学仿真软件进行算法编程实现,云存储系统设计中,通过粒子群重采样策略实现对DOM函数的修改,采用eval()、setTimeout()、setInterval()等直接执行脚本函数进行粒子的多样性滤波,仿真实验中,粒子群的额种群规模为300,进化次数为1024,跳数机制为100,云存储中的干扰向量的扰动率为0.2,分别取粒子数Ns=200,500,700,1000,以n=30K,m={20,50,100}和n=100K,m=100四种情况为例在进行云存储大数据聚类仿真,在云存储环境下,进行数据聚类测试,首先进行原始大数据采样,得到原始数据结果如图4所示。

图3 大数据聚类算法实现流程

图4 云存储中的原始大数据采样结果
上述数据由于相互特征差异不明显,难以有效区分,采用文中算法进行数据聚类,实现模式识别,得到数据聚类结果如图5所示。
从图可见,采用文中算法进行数据聚类,具有较大的特征差异性,各类数据之间得到有效区分,对云存储系统中的数据聚类性能较好,为了对比算法性能,以数据聚类的收敛度为测试指标,获得仿真后果像图6所示,由图可知,使用文中算法,可以在限制的迭代步数下实现最优化聚类,收敛性能较好,展示了较好的应用价值。
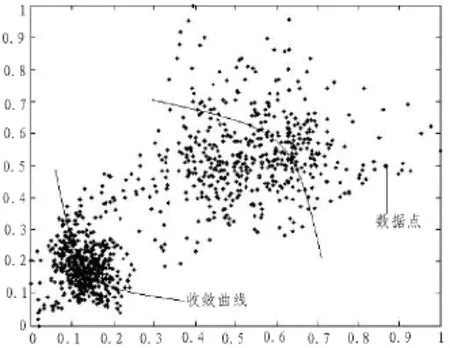
图5 数据聚类结果

图6 大数据聚类收敛性能对比
4 结束语
对云存储系统中的大数据进行优化聚类设计,降低存储开销,提高数据管理和调度能力,传统方法中对云存储大数据聚类方法采用量子进化方法,当量子群个体存在非线性偏移时,数据聚类存在局部收敛,导致聚类准确度降低。提出一种基于优化粒子群算法的云存储中大数据优化聚类算法、首先进行了云存储大数据聚类的原理分析,在传统的模糊C均值聚类的基础上,采用粒子群聚类算法实行大数据聚类算法改革设计,最后经过仿真实验实行了性能检测及证明,展现出了文中算法在实际大数据聚类里的优越性能,实验后果证明,使用文中算法实行数据聚类的聚敛性能较好,能在较短的迭代步数下计算得到最优解,在模式识别等领域展示了较好的应用价值。
[1]谭鹏许,陈越,兰巨龙,等.用于云存储的安全容错编码[J].通信学报,2014,35(3):109-114.
[2]魏理豪,王甜,陈飞,等.基于层次分析法的信息系统实用化评价研究 [J].科技通报,2014,30(2): 142-148.
[3]吴涛陈黎飞郭躬德.优化子空间的高维聚类算法[J].计算机应用,2014,34(8):2279-2284.
[4]辛宇,杨静,汤楚蘅,等.基于局部语义聚类的语义重叠社区发现算法 [J].计算机研究与发展,2015,52(7):1510-1521.
[5]徐向平,鲁海燕,徐迅.基于环形邻域的混沌粒子群聚类算法[J].计算机工程与应用,2016,52(2): 54-60.
[6]LIAO Lü-chao,JIANG Xin-hua,ZOU Fu-min,HE Wen-wu,QIU Huai.A Spectral Clustering Method for Big Trajectory Data Mining with Latent Semantic Correlation [J].Chinese JournalofElectronics,2015,43(5):956-964.
[7]余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究 [J].通信学报,2015(5): 2015099.
[8]熊众望,罗可.基于改进的简化粒子群聚类算法[J].计算机应用研究,2014,31(12):115-123.
[9]苟杰,马自堂.基于MapReduce的并行SFLA-FCM聚类算法[J].计算机工程与应用,2016,52(1):66-70.
[10]WANG Yong-gui,LIN Lin,LIU Xian-guo.结合双粒子群和K-means的混合文本聚类算法[J].计算机应用研究,2014,31(2):364-368.
[11]马艳英.基于遗传算法的Web文档聚类算法[J].现代电子技术,2016,39(1):148-152.
[12]沈艳,余冬华,王昊雷.粒子群K-means聚类算法的改进[J].计算机工程与应用,2014,50(21):125-128.
[13]王杨.基于改进的粒子群优化的模糊C-均值聚类算法[J].计算机与数字工程,2014,42(9):1610-1612.
[14]钱潮恺,黄德才.基于维度频率相异度和强连通融合的混合数据聚类算法[J].模式识别与人工智能,2016,29(1):82-89.
[15]许成鹏,朱志祥.一种基于云计算平台的数据库加密保护系统[J].电子设计工程,2015(19):97-100.
Large data optimization particle swarm clustering algorithm based on cloud storage
WANG Dong-qiang,WANG Xiao-xia
(Science and Information College,Qingdao Agricultural University,Qingdao 266109,China)
The large data of cloud storage system is optimized for clustering design,reducing storage overhead,improving data management and scheduling ability.The traditional method uses quantum evolutionary algorithm to cluster large data clustering method.When the quantum group has a nonlinear shift,data clustering has local convergence,which leads to the decrease of clustering accuracy.A large data clustering algorithm based on particle swarm optimization is proposed,which is based on the traditional fuzzy C means clustering.The clustering algorithm is used to improve the design.The data is transformed into the spatial segmentation.The clustering algorithm is used to obtain the data concentration.The optimal solution is obtained.The simulation results show that this algorithm is used to optimize the particle swarm optimization in cloud storage.The clustering accuracy is high,and the convergence performance is better,and the optimal solution can be obtained in the short iterative step.
cloud storage;particle swarm;large data;clustering algorithm
TP391
:A
:1674-6236(2017)02-0026-05
2016-05-17稿件编号:201605165
山东省自然科学基金(20015CAZ185);校级课题(SYJK13-26)
王东强(1974—),男,山东招远人,硕士研究生,实验师。研究方向:计算机工程,网络安全。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
发明与创新·大科技(2019年12期)2019-03-17
测控技术(2018年10期)2018-11-25
浙江工业大学学报(2017年5期)2018-01-22
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国教育信息化(2015年12期)2015-08-24
电测与仪表(2015年10期)2015-04-09
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
