
模糊时间序列模型在论域定义上的研究
2017-03-01 10:55陈海燕彭艳兵
电子设计工程 2017年2期
汪 洋,陈海燕,彭艳兵
(1.武汉邮电科学研究院 通信与信息系统,湖北 武汉430074;2.烽火通信科技股份有限公司 南京研发部,江苏 南京210019)
模糊时间序列模型在论域定义上的研究
汪 洋1,2,陈海燕1,2,彭艳兵1,2
(1.武汉邮电科学研究院 通信与信息系统,湖北 武汉430074;2.烽火通信科技股份有限公司 南京研发部,江苏 南京210019)
文中基于模糊时间序列模型,提出了如何定义论域的方法。预测人员在不断地应用模糊时间序列模型进行预测的同时,也对此模型进行了不同方面的改进,但是大部分主要包括两个方面:一是论域划分,而是模糊关系表示。在论域划分上面,现有的研究都是简单的向上和向下取整的方法,没有意识到论域区间的定义也会影响到预测的结果的原因,所以本文研究了新的定义论域区间的方法,本文新的方法中提出论域区间的定义和当前类别的数据分布有关,这样充分考虑了样本数据的分布情况,提高了论域间隔的准确度和可解释性。最后,本文应用阿拉巴马州大学的预测结果和最新的论域划分方法进行了比较,结果表明了此方法的有效性。
模糊时间序列;论域区间定义;数据分布;论域划分
预测问题已经是这个时代研究的重点,做好市场调研,分析消费者的习惯性行为,预测消费者的消费倾向从而进行针对性的推销使企业获利。模糊时间序列模型应用到各行各业,包括股票预测[1-2]、温度预测[3]、气候预测[4]、环境污水预测[5]等,预测的模型有很多,经典时间序列预测模型可以处理很多的预测问题,但是也有局限性,它依赖大量的历史数据,不能有效的预测历史数据是语言值、不完整或是不确定的问题。1965年美国自动化控制专家Zadeh教授提出了模糊理论和模糊逻辑的概念,并初步建立了处理带有不确定的、模糊的语义问题的模型[6];1994年,Song、Chrisom运用Zadeh教授的理论,建立针对模糊时间序列预测的模型[7-8],为模糊时间序列预测理论奠定了基础。其预测框架由4个步骤组成:1)定义论域和进行论域的模糊划分;2)将历史数据模糊化;3)建立模糊逻辑关系;4)去模糊化后预测。从预测步骤出发,研究人员主要集中在如何划分论域,如何建立模糊关系,如何去模糊化上面,却忽视了论域定义的重要性。在提出聚类算法之前,学者们在定义整个论域的时候基本上采用的简单的向上向下取整的方法。2008-2011年之间,研究此模型的课题组,提出了聚类算法[9-11],即首先将样本数据进行分类,然后再定义每类数据的论域。无论是将将样本数据分类还是没有将样本数据分类,学者的都没有意识到定义论域的重要性,只是将样本数据的最小值向下取整,样本数据的最大值向上取整。文中研究了定义论域的方法,不再是简单的取整,而是利用分类后的数据的集中程度来定义论域。
1 模糊时间序列模型的简介
1.1 模糊时间序列的定义
定义1.1[12](模糊集)设U为给定论域,将论域划分为n个子区间,即U={u1,u2,…,un},则定义在论域U中的模糊集合A表示为:
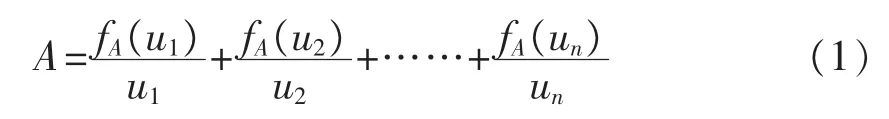
其中,fAi(·)是模糊集合Ai的隶属函数,fAi(·):U→[0,1],uk是模糊集合Ai的一个因素。fAi(uk)是uz对模糊集合Ai的隶属度,fAi(uk)∈[0,1],k=1,2,…,n。
定义1.2[13](模糊时间序列)对任一固定的t=(…,1,2,3,…),设Y(t)⊂R,即为实数域的子集,Y(t)上定义着一组模糊集 fi(t)(i=1,2…),且 F(t)={f1,f2(t),…},则我们称F(t)为定义在Y(t)上的模糊时间序列。
定义1.3[13](模糊关系)假设定义R(t,t-1)为F(t-1)到F(t)的模糊关系,满足F(t)=F(t-1)°R(t,t-1),则可以用模糊逻辑关系F(t-1)→F(t)表示,F(t-1),F(t)都是模糊集,“°”表示合成运算,关系R定义在F(t)上的一阶模糊关系。
定义1.4[13](左件、右件)假设F(t-1)=Ai,F(t)=Aj,则在两个连续的观测值F(t)和F(t-1)可以用一阶模糊逻辑关系表示,记为Ai→Aj,称Ai为模糊关系的左件,Aj为模糊关系的右件。
1.2 模糊时间序列模型建模和预测步骤
1)根据样本数据和隶属度函数定义论域并进行区间的划分;
2)根据样本数据先后的观测值模糊化;
3)建立模糊逻辑关系;
4)将观测值模糊化并预测。
1.3 模型评估参数
使用相对误差、平均误差、均方误差3个指标对方法进行评估。为预测值,yi为真实值,残差为ei=。
1)相对误差:记号为Δ,

2)平均误差:记号为ME,
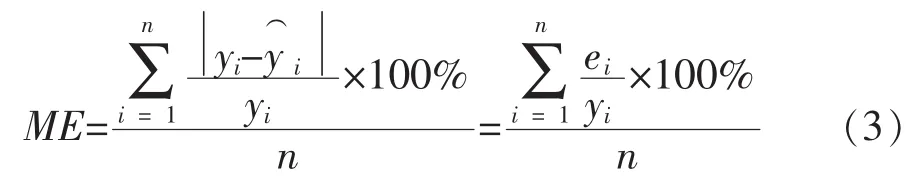
3)均方误差:记号为MSE,

2 提出定义论域的方法及验证
2.1 定于论域方法的阐述
在论域划分上,研究学者的研究重点只是在如何划分论域,而忽视了如何定义论域。1993年,Song和Chissom提出的模糊时间序列模型中,定义论域的方法就是整个样本的最小值的向下取整和最大值的向上取整。2006年,Huarng[15]提出了基于比率的论域划分方法,定义初始值的方法为:initial=a·b′×102,b′=b-1,其中a,b是0到9的任意数字,z可以是任意正整数、负整数或零,论域由初值开始,间隔通过比率进行增长。到后来的模型研究中,基本上都是基于最原始的定义方法,即简单的向下和向上取整的方法,所以本文研究论域定义的方法具有一定的实际意义。下面介绍本文定义论域的方法。
文中采用的预测模型是基于曲和陈的模型,采用的是多尺度论域划分方法,与其他方法不同之处在于本文先计算每个类别的比率,再来定义论域。假设类别1通过多尺度比率算法计算的比率为ratio,则此类别的论域定义为:
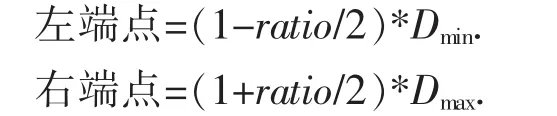
其中,Dmin为类别1中样本数据的最小值,Dmax为类别1中样本数据的最大值。
2.2 新方法的验证-大学注册人数的预测
模糊时间序列模型的研究学者们是基于阿拉巴马州大学1971-1992年的注册人数的进行预测,本文也是采用此作为预测样本,与前人的预测结果进行比较,表1是阿拉巴马州大学的实际注册人数以及每年的变化值。
2.3 预测步骤
模型的预测步骤为:
1)论域区间定义;
2)划分论域;
3)定义模糊集,样本数据模糊化;
4)建立模糊逻辑关系和模糊逻辑关系组;
5)添加启发式知识,建立启发式模糊逻辑关系组;
6)去模糊化并预测。
步骤1:论域区间定义。
步骤1.1:表1中记录了阿拉巴马州大学22年的注册人数,将这些数据从小到大排序,得到的样本数据为:

步骤1.2:利用FCM算法将样本数据分成X1,X2,X33类,分成的结果如下:

步骤1.3计算X1,X2,X33类数据的比率。利用公式(5):

分别计算X1,X2,X33类数据的相邻数据的相对误差,然后在计算平均误差,结果为:
ratio1=0.0307,ratio2=0.0109,ratio3=0.0161.
步骤1.4定义论域区间。
X1,X2,X33类数据的最大值和最小值分别记为:.从分类的结果可以知道D1min=13055,D1max=13867,D2min=14696,D2max=16919,D3min= 18150,D3max=19377。
利用公式(6)和(7)确定3类数据的论域区间,
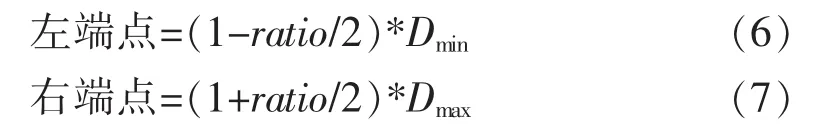
故X1的论域区间是:
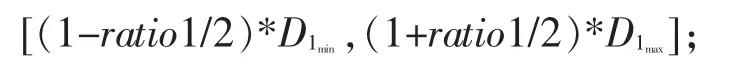
X2的论域区间是

X3的论域区间是

将步骤1.3计算的ratio1,ratio2,ratio3代入上面的公式,得到:
X1的论域区间是[12855,14080];X2的论域区间是[14616,17011];X3的论域区间是[18004,19533]。
步骤2:划分论域。按照曲和陈的多尺度方法进行划分论域。
X1的初始值为12855,记为xinitial=12855。
当j≥1时,xj=(1+ratio)j×xinitial,uj=[xj-1,xj],最后得到23个间隔:
u1=[12855,13250],u2=[13250,13657], …,u23= [19501,19533]
步骤3:定义模糊集,并将样本数据模糊化。
根据步骤2中得到的23个间隔,使用三角隶属函数,定义23个模糊集如下所示:

步骤3.2:根据模糊化的规则,将样本数据模糊化,表2是样本数据模糊化的结果。
步骤4:根据定义1.3,模糊关系的定义,建立模糊逻辑关系和模糊逻辑关系组。
步骤5:引入启发式知识,建立启发式模糊逻辑关系组。
步骤6:去模糊化并预测。按照平均值去模糊化的规则。
2.4 预测结果比较
1)相对误差
图1将本文提出的论域定义方法与曲和陈的方法进行了比较,从相对误差的对比图可以看出,本文提出的方法的相对误差小,在相对误差比较大的地方,曲和陈的方法相对误差更大。采用本文定义论域的方法,除了个别的误差比较大之外,其它的相对误差基本在0.00%~1.00%之间,说明本文提出的定义论域方法的有效性。
2)评估参数-均方误差
利用公式(3)计算本文的预测的均方误差,与曲和陈的方法进行对比,表5为对比的结果。文中方法的均方误差明显低于曲和陈的方法。
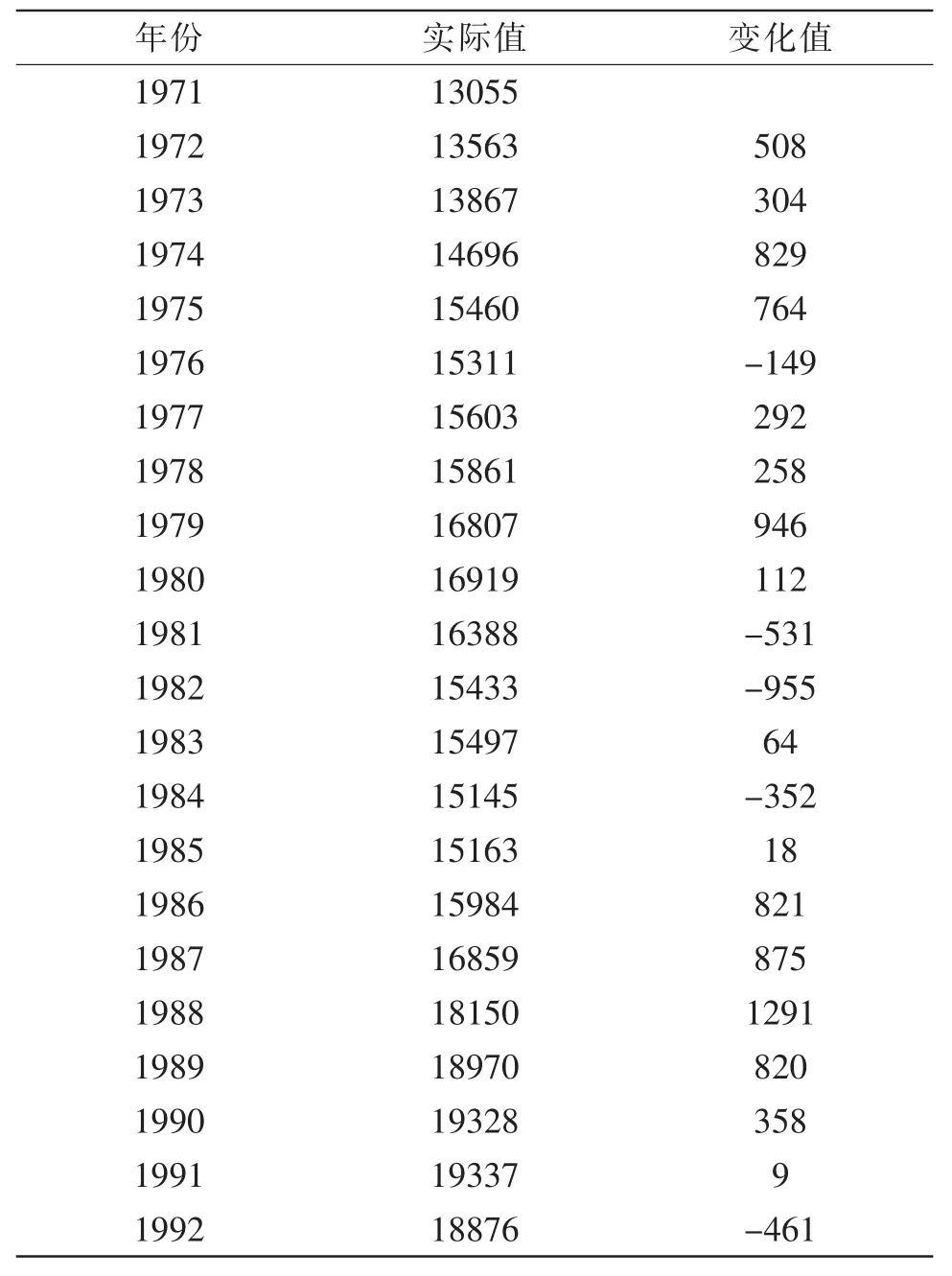
表1 阿拉巴马州大学1971-1992年的注册人数
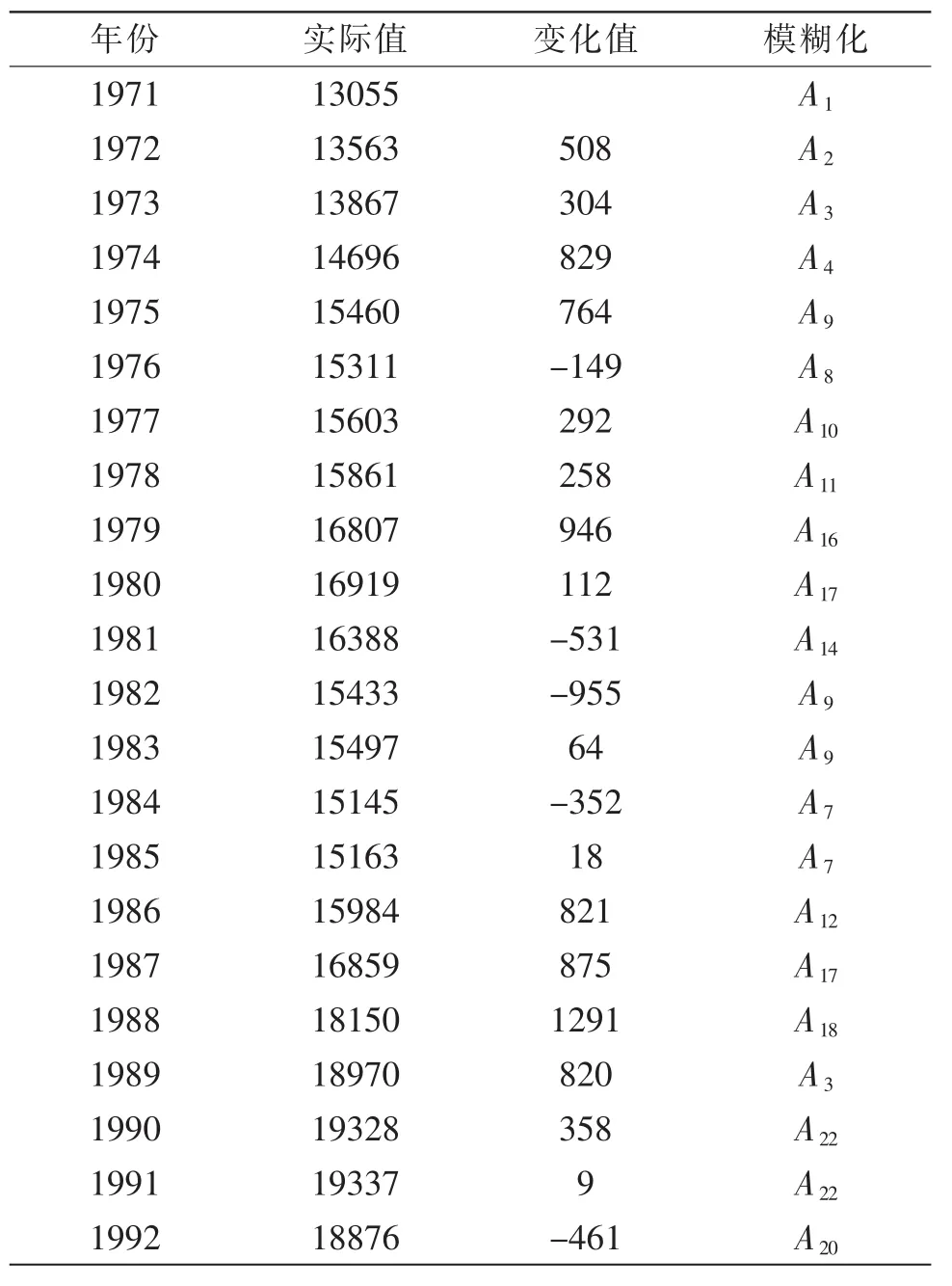
表2 数据模糊化结果

表3 模糊逻辑关系表

表4 模糊逻辑关系组
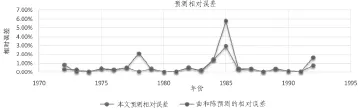
图1 相对误差比较图

表5 均方误差比较
3 结 论
文中针对模糊时间序列模型的预测步骤,基于前人的研究提出了定义论域的方法,此方法解决了前人对论域的重要性的忽视的问题,不再是简单的向上向下取整,而是和数据分类后的分布情况有关,本文中对此方法进行了验证,并且和多尺度比率进行了比较,无论在平均误差还是在均方误差上,本文提出定义论域的方法在预测的准确度上明显高于多尺度比率算法。
参考文献:
[1]蔺玉佩,杨一文.基于模糊时间序列模型的股票市场预测[J].统计与决策,2010(8):34-37.
[2]邱望仁.模糊时间序列模型及其股指趋势分析中的应用研究[D].辽宁:大连理工大学,2012.
[3]余文利,方建文,廖建平.一种新的基于模糊C均值算法的模糊时间序列确定性预测模型[J].计算机工程与科学,2010,32(7):112-116.
[4]王永弟.模糊时间序列模型在短期气候预测中的应用[J].南京信息工程大学学报,2012,4(4):316-320.
[5]倪明,肖辞源.模糊时间序列预测模型研究及其在污水处理上的应用[D].南充:西南石油大学,2012.
[6]Zadeh L A.Fuzzy sets[J].Information and Control,1965(8):338-353.
[7]Q.Song,B.SChrisom.Forecasting enrollments with fuzzy time series.Part I[J].Fuzzy Sets and System,1993,54(1):1-10.
[8]Q.Song,B.SChrisom.Forecasting enrollments with fuzzy time series.Part II[J].Fuzzy Sets and System, 1994,62(1):1-8.
[9]Cheng C H,Cheng G W,Wang J W.Multi-attribute fuzzy time series method based on fuzzy clustering [J].Expert Systems with Applications,2008,34(2):1235-1242.
[10]Li S T,Cheng Y C,Lin S Y.A FCM-based deterministic forecasting model for fuzzy time series[J]. Computers and Mathematics with Applications,2008,56:3052-3063.
[11]Li S T,Cheng Y C.An enhanced deterministic fuzzy time series forecasting model[J].Cybernetics and Systems,2009,40(3):211-235.
[12]杨纶标,高英仪,凌卫新.模糊数学原理及应用[M].广州:华南理工大学出版社,2013.
[13]邱望仁,刘晓东.模糊时间序列模型研究综述[J].模糊系统与数学,2014,28(3):173-181.
[14]陈刚,曲宏巍.模糊时间序列模型相关理论的研究[D].辽宁:大连海事大学,2012.
[15]Huarng K H.Ratio-based Lengths of Intervals to Improve Fuzzy Time Series forecasting[J].IEEE Transactions on Systems,Man,and Cybernetics-Part B:Cybernetics,2006,36(2):328-340.
A research on the definition of discourse of fuzzy time series models
WANG Yang1,2,CHEN Hai-yan1,2,PENG Yan-bing1,2
(1.Wuhan Research Institute of Posts and Telecommunications,Communication and Information System,Wuhan 430074,China;2.FiberHome Communication Technology Co.Ltd.,Nanjing Researchand Development Department,Nanjing 210019,China)
This paper puts forward how to define the discourse on fuzzy time series models.Although forecasters have applied the model and improved it at the same time,the most research included two aspects:one is the division of discourse,the other one is fuzzy logic relationship.On the definition of discourse,due to the existing research on the definition of discourse is only simply rounded up and down,unaware of the importance of the definition of discourse can also affect the result of prediction,so this thesis puts forward a new method about the definition of discourse.In this new method,the definition of discourse is related to the data distribution of current category.Because the distribution of the sample data is considered,so the accuracy of intervals is improved.Finally,in order to prove the effectiveness of the proposed method,this paper predicts the enrollment Alabama,and the result of experiments show that this method has good prediction effect.
fuzzy time series model;definition of discourse;data distribution;partition of discourse
TN911.1
:A
:1674-6236(2017)02-0009-05
2016-01-09稿件编号:201601051
江苏省科技支撑计划项目(2015BAK20B05)
汪洋(1978—),男,江苏南京人,硕士,工程师。研究方向:计算机网络。
猜你喜欢
厦门大学学报(自然科学版)(2022年4期)2022-07-15
成都信息工程大学学报(2021年6期)2021-02-12
现代装饰(2020年7期)2020-07-27
运筹与管理(2019年10期)2019-12-17
测控技术(2018年10期)2018-11-25
广东石油化工学院学报(2016年3期)2016-05-17
山东青年(2016年1期)2016-02-28
电源技术(2016年2期)2016-02-27
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
