
基于深度循环神经网络的时间序列预测模型
2017-03-29 04:59杨祎玥万定生
计算机技术与发展 2017年3期
杨祎玥,伏 潜,万定生
(1.河海大学 计算机与信息学院,江苏 南京 211100;2.江苏省交通规划设计院,江苏 南京 211100)
基于深度循环神经网络的时间序列预测模型
杨祎玥1,伏 潜2,万定生1
(1.河海大学 计算机与信息学院,江苏 南京 211100;2.江苏省交通规划设计院,江苏 南京 211100)
针对水文时间序列的高度非线性和不确定性等问题,利用深度循环神经网络的时间序列预测能力,结合小波变换方法,将原始序列分解重构为多个低频和高频序列,针对各个子序列进行网络模型训练,建立一个基于小波变换的深度循环神经网络的水文时间序列预测模型(WA-DRNN)。网络训练方法采用时间进化反向传播(BPTT)算法,逐步更新网络权值。实验结果表明,WA-DRNN模型较普通的DRNN模型在预测值的均方差和绝对误差上均有较好提升,并且由于该模型的多尺度特性,能够一定程度上减少模型预测引起的滞后作用。实验结果证明,WA-DRNN模型具有预测精度高、滞后误差小的优点,对深度学习算法在水文时间序列预测的应用上有一定帮助。
小波分析;深度循环神经网络;时间序列;预测
0 引 言
由于受气候、气温、人类活动等大量不确定性和复杂性因素的影响,各类水文时间序列具有高度非线性、不确定性等特性,常规的分析、预测方法很难掌握其中的变化规律及变化特性[1]。在水文预报领域,小波分析和神经网络相互结合的方法受到广泛关注,而深度学习的飞速发展又为水文时间序列的预测提供了新的研究思路和方法。
深度学习的概念由Hinton等[2]于2006年提出。深度学习神经网络提供了高维数据空间和低维嵌套结构的双向映射,有效解决了大多数非线性降维方法所不具备的逆向映射问题。Enzo Busseti等[3]将深度学习模型应用在时间序列的预测中,探索了不同深度学习模型的预测精度。因此,可以运用深度学习技术在海量水文数据中挖掘出隐藏模式和规律以及对预测水文过程有用的信息。
文中利用深度循环型神经网络的时间序列预测能力,结合小波分解方法,建立了一个基于小波分解的深度循环型神经网络的水文时间序列预测模型。
1 小波分析
1.1 小波变换
(1)
则称ψ(t)为基小波或母小波(MotherWavelet),将母小波经伸缩和平移得到小波序列,又称为子小波:
(2)
其中,a为伸缩因子或尺度因子,将母小波作伸缩变换;b为平移因子,将母小波作平移变换。
对于任意函数f(t)∈L2(R),将其在小波基下展开,这种展开即为f(t)的连续小波变换(ContinuousWaveletTransform,CWT)[5]:
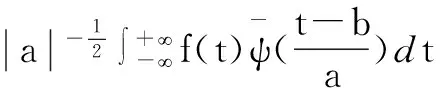
(3)
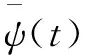
从上式中可以看出,对小波分析变换系数的分析可以显示出ψ(t)的时频特性及其重要的局部变化特性。在实际处理问题时,通常需要将伸缩操作和平移操作限定在一些离散点上进行,对伸缩因子和平移因子作离散化处理,取
(4)
该过程称为离散小波变换(DiscreteWaveletTransform,DWT):
(5)
1.2 多分辨率分析与Mallat算法
小波变换的多分辨率分析(或多尺度分析)是由S.Mallat和Y.Meyer提出的[6]。从空间的概念上说明了小波的多分辨率特性,随着分解尺度从大到小变换,能够在各尺度由粗到细观察序列的不同特征。之后S.Mallat受到塔式算法的启发,提出了马特拉(Mallat)算法。
Mallat算法是在多分辨率分析的基础上提出的一种针对其小波系数而进行逐层分解和重构的快速小波变换算法,大大减少了信号分解时的矩阵运算时间和复杂度。
Mallat算法三层分解[7]过程如图1所示。其中,cAk表示低频信号,cDk表示高频信号,C中保存的是分解的低频信号和高频信号,L记录的是C中分解信号的长度大小。
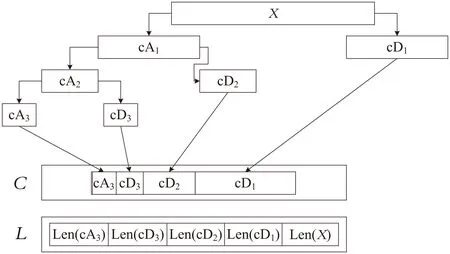
图1 Mallat算法三层分解过程示意图
从图1可以看出,小波分析的每一次分解是对原始信号或上一层的低频信号进行的,分别得到一个低频信号和一个高频信号,而长度是上一层次信号的一半。
2 深度循环神经网络
深度循环神经网络(DeepRecurrentNeuralNetwork,DRNN)本质上是一种通常意义上的深度神经网络(多层感知机)[8],其特点是每层都有时间反馈循环,并且层之间是叠加构成的。每次神经网络的更新,新信息通过层次传递,每层神经网络也获得了时间性上下文信息。
循环神经网络(RecurrentNeuralNetwork,RNN)是一种特殊的神经网络,很有争议地被划归为深度网络一类。当按照时间折叠,它可以被视为一个有无限多层的深度神经网络[9]。对于RNN来说,每层的基本功能是用来对数据进行记忆,而不是分层次处理。通过每次迭代,新的信息被添加到每一层中,RNN可以通过无限制次数网络更新将信息传递下去,使得RNN可以获得无限的记忆深度。
标准的RNN传播过程为,给定n维输入序列x1,x2,…,xn,m维网络的隐层状态序列h1,h2,…,hm,k维输出序列y1,y2,…,yk,迭代公式如下[10]:
ti=Whxxi+Whhhi-1+bh
(6)
hi=e(ti)
(7)
si=Wyhhi+by
(8)
(9)
其中,Whx、Whh、Wyh为权值矩阵;bh、by为基底;ti为隐层的输入,si为输出单元的输入,同为k维变量;e、g为预定义的非线性向量值函数。

文中所提到的DRNN模型,其中第一层隐层的公式如下:
h(1)(xt)=σ(W(1)xt+b(1)+Uh(1)(xt-1))
(10)
RNN使用当前时刻的输入数据xt和前一时刻对xt-1重构值h(1)(xt-1)计算隐层h(1)(xt)激活值,W(1)和U为连接权值,b(1)是当前层的基底,σ代表sigmoid激活式为:
σ(z)=1/(1+e-z)
(11)
DRNN模型建立在多层RNN上,使得模型更加的非线性化,也使得模型可以承载更多的参数。
图2是一个具有三隐层的DRNN网络。

图2 DRNN结构示意图
使用式(12)来表达这个DRNN网络:
h(i)(xt)=σ(W(i)h(i-1)(xt)+b(i))
(12)
其中,h(i)(xt)表示第i层的激活值,且i大于1,对于每个隐层都有一个对应的权值W(i)和基底b(i),模型在t方向的迭代如式(12)。
3 预测模型构建
利用小波分析方法对原始水文时间序列进行预处理[11],进行多尺度小波分解和单支重构,可获得不同的高频和低频序列,对预处理的数据进行相空间重构后作为DRNN模型的训练数据,建立一个基于小波分解的深度循环神经网络的水文时间序列预测模型(称为WA-DRNN模型)。
WA-DRNN预测模型结构如图3所示。
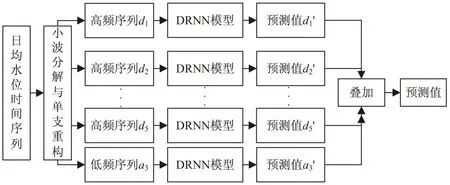
图3 WA-DRNN预测模型结构
首先将时间序列数据进行小波分解和单支重构成多条序列,然后分别输入DRNN模型进行预测,最后将预测值叠加[12]成最终预测值。
WA-DRNN模型建立过程如下:
(1)数据准备。先选取一个站点的历史日均水位数据,对数据进行归一化处理,并且保存其最大值和最小值。
(2)小波分解和单支重构。选择合适的小波函数和分解尺度,对日均水文时间序列进行多尺度小波分解和单支重构,获得该序列的近似系数和各细节系数,然后对这些系数分别进行单支重构,获得一条能够描述原始序列趋势变化的低频序列和多条保留了不同信息的高频序列。
(3)相空间重构[13-14]。设置相空间重构的延迟数值,分别对低频序列和各个高频序列进行相空间重构,以此形成相应的训练数据和测试数据。
(13)
(14)
其中,X为输入矩阵;Y为输出矩阵。
输入序列为nin维时间序列x(t),目标序列为y(t)。
(4)DRNN模型训练。设定DRNN的学习速率、网络层数和每层的节点数目,利用相空间重构的多组训练数据分别对DRNN模型进行训练。
(5)预测水位。用训练好的DRNN模型对子序列的测试样本进行预测,并将各子序列的预测值进行叠加,从而得到最终的预测值,这样就实现了对水文时间序列的建模和预测。
4 实例分析
以星子站1957-2010年间的日均水位数据为例来研究基于小波分解的深度循环神经网络预测模型。其中,训练数据为星子站1957-2009年间共14 553组经过相空间重构的数据,预测模型输入为星子站2010年2月6日至2010年5月18日的日均水位数据。
首先,对数据进行归一化处理,以提高数据在训练过程中的收敛速度。在这里使用Max-Min归一化方法,对于序列中的最大值xmax和最小值xmin,对序列中所有元素xi有:
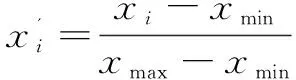
(15)
再挑选合适的小波分解参数,将原始信号合理地分解到恰当的多个频段上。这里使用Daubechies小波6(db6),对其进行小波分解和单支重构,其中高频部分如图4所示。
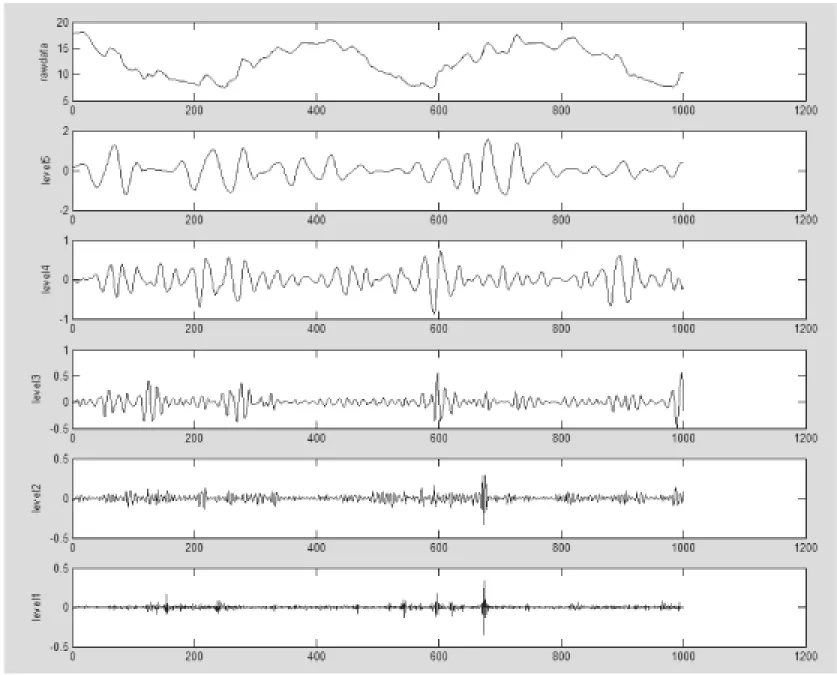
图4 日均水位序列原始序列与db6分解后的高频信号对比图
其中,第一条曲线为原始序列曲线,下面五条为db6小波分解并进行高频重构后的5个尺度的序列。高频序列能够捕捉到原始序列轻微的扰动,将原始序列中突发性、局部性、隐藏性的信息保留在其中。
DRNN模型训练参数如下,学习速率为0.000 01,迭代次数为1 000,输入窗口大小为20,隐层一共为两层,第一隐层节点数为30,第二隐层节点数为5,输出节点为1。DRNN模型的预测结果如图5所示。

图5 DRNN预测结果对比图
WA-DRNN的DRNN部分的参数与上面相同,其中小波分解的参数为db6小波高频部分的2到5级,以及db6低频信号的第5级,作为输入。WA-DRNN模型的预测结果如图6所示。
由两幅图的对比可以看出,单纯利用DRNN作为预测模型,已经可以较好地预测出模型的趋势走向。而经过WA-DRNN改进后,由于其的多尺度特性,减少了DRNN模型的滞后作用,并且能够较好预测到几个极值点的情况。同时根据表1可以得出,WA-DRNN和DRNN的均方差分别为0.78和1.33,平均绝对误差分别为0.6和1.069,表明WA-DRNN效果更好。
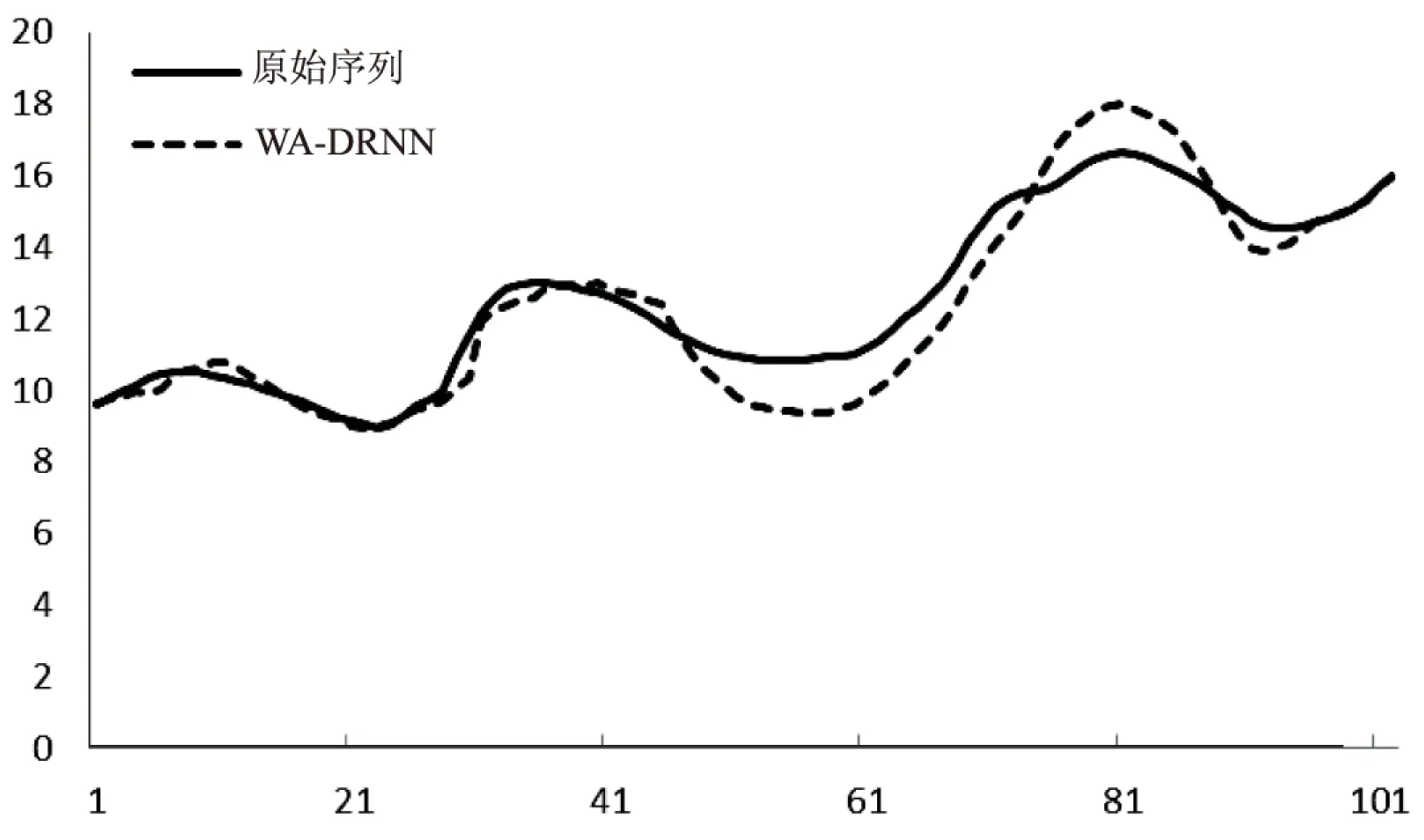
图6 WA-DRNN预测结果对比图
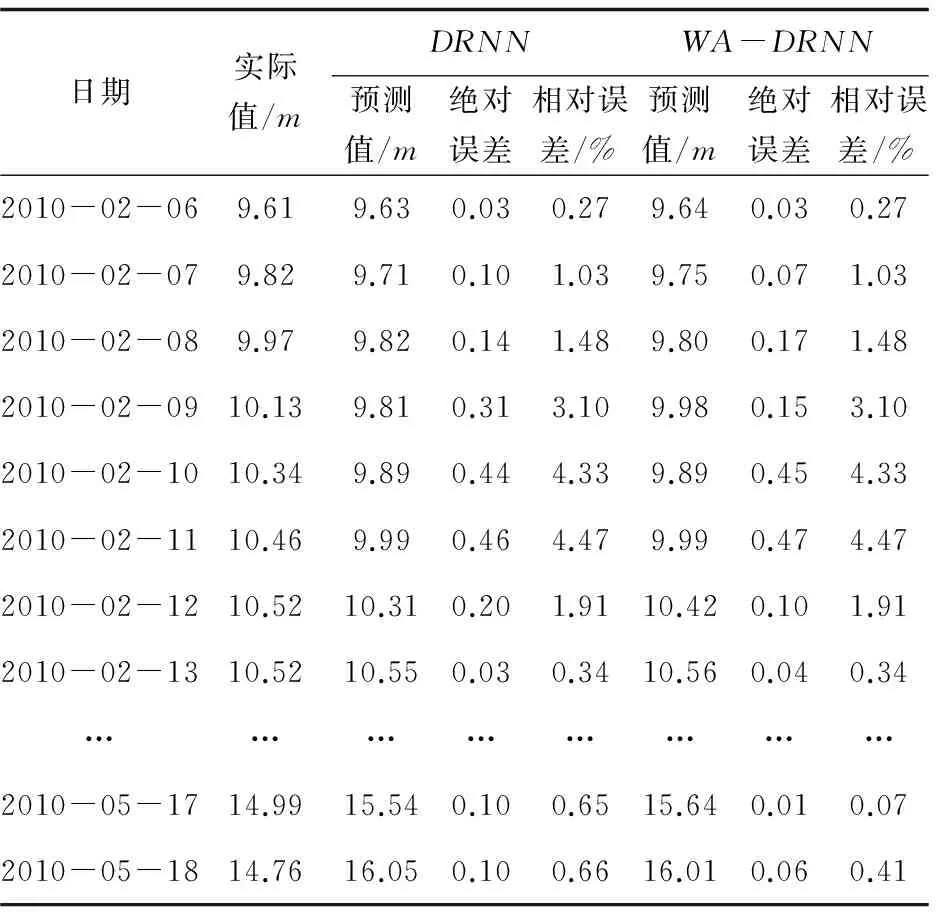
日期实际值/mDRNNWA-DRNN预测值/m绝对误差相对误差/%预测值/m绝对误差相对误差/%2010-02-069.619.630.030.279.640.030.272010-02-079.829.710.101.039.750.071.032010-02-089.979.820.141.489.800.171.482010-02-0910.139.810.313.109.980.153.102010-02-1010.349.890.444.339.890.454.332010-02-1110.469.990.464.479.990.474.472010-02-1210.5210.310.201.9110.420.101.912010-02-1310.5210.550.030.3410.560.040.34……………………2010-05-1714.9915.540.100.6515.640.010.072010-05-1814.7616.050.100.6616.010.060.41
5 结束语
文中提出了基于小波分解的深度循环神经网络对星子站日平均水位进行预测的方法。基于小波分解的深度循环神经网络较单纯的深度循环神经网络有着更强的逼近能力和容错性。实验结果表明,基于小波分解的深度循环神经网络有效降低了预报误差,提高了模型的预测精度,减少了模型的滞后误差,具有较强的预报和泛化能力。
[1] 王 文,马 骏.若干水文预报方法综述[J].水利水电科技进展,2005,25(1):56-60.
[2]HintonGE,SalakhutdinovRR.Reducingthedimensionalityofdatawithneuralnetworks[J].Science,2006,313(5786):504-507.
[3]BussetiE,OsbandI,WongS.Deeplearningfortimeseriesmodeling[R].USA:StanfordUniversity,2012.
[4] 孙延奎.小波分析及其应用[M].北京:机械工业出版社,2005.
[5] 衡 彤.小波分析及其应用研究[D].成都:四川大学,2003.
[6] Mallat S G. Multiresolution representation and wavelets[D].Philadelphia,PA:University of Pennsylvania,1988.
[7] Mallat S G. Multiresolution approximations and wavelet orthonormal bases of L2(R)[J].Transactions of the American Mathematical Society,1989,315(1):69-87.
[8] Graves A,Mohamed A R,Hinton G.Speech recognition with deep recurrent neural networks[C]//International conference on acoustics,speech and signal processing.[s.l.]:IEEE,2013:6645-6649.
[9] Hermans M,Schrauwen B.Training and analysing deep recurrent neural networks[C]//Advances in neural information processing systems.[s.l.]:[s.n.],2013:190-198.
[10] Pascanu R,Gulcehre C,Cho K,et al.How to construct deep recurrent neural networks[C]//Proceedings of the 2014 international conference on learning representations.[s.l.]:[s.n.],2014.
[11] 桑燕芳,王 栋,吴吉春,等.水文时间序列小波互相关分析方法[J].水利学报,2010(11):1272-1279.
[12] 左其亭,高 峰.水文时间序列周期叠加预测模型及3种改进模型[J].郑州大学学报:工学版,2004,25(4):67-73.
[13] 朱跃龙,李士进,范青松,等.基于小波神经网络的水文时间序列预测[J].山东大学学报:工学版,2011,41(4):119-124.
[14] 余宇峰,万定生.Benford法则在水文数据质量挖掘中的应用研究[J].微电子学与计算机,2011,28(8):180-183.
A Prediction Model for Time Series Based on Deep Recurrent Neural Network
YANG Yi-yue1,FU Qian2,WAN Ding-sheng1
(1.College of Computer and Information,Hohai University,Nanjing 211100,China;2.Jiangsu Province Communications Planning and Design Institute,Nanjing 211100,China)
Aimed at the problems of high-nonlinearity and nondeterminacy for hydrology time series,a prediction model for hydrology time series based on Wavelet Analysis and Deep Recurrent Neural Network (WA-DRNN) is put forward by using the predictive capability of deep recurrent neural network,combined with the wavelet analysis for the reconstruction of the original time series and training of high and low frequency series.The network training adopts Back Propagation Through Time (BPTT) algorithm to update the network weight.The experiment shows that the WA-RNN model is better than the normal DRNN model in the mean square error and absolute error,and for the reason of multiscale the model can decrease the lag of prediction.It turns out the WA-DRNN model has advantages of higher predictive accuracy and less lag,which is helpful for application of hydrology time series prediction of deep learning algorithm.
wavelet analysis;DRNN;time series;prediction
2016-04-22
2016-08-17
时间:2017-02-17
国家科技支撑计划课题(2015BAB07B01);水利部公益性行业科研专项(201501022)
杨祎玥(1992-),男,硕士研究生,研究方向为数据挖掘;万定生,教授,CCF会员,研究方向为信息处理与信息系统。
http://www.cnki.net/kcms/detail/61.1450.TP.20170217.1630.046.html
TP391
A
1673-629X(2017)03-0035-04
10.3969/j.issn.1673-629X.2017.03.007
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
现代经济信息(2021年3期)2021-11-23
科技风(2021年19期)2021-09-07
陕西档案(2021年2期)2021-05-21
计算机应用与软件(2020年9期)2020-09-09
北京化工大学学报(自然科学版)(2020年1期)2020-06-22
电子制作(2019年13期)2020-01-14
人民珠江(2019年4期)2019-04-20
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
