
面向用户偏好发现的隐变量模型构建与推理
2017-04-20 05:38付晓东刘惟一
计算机应用 2017年2期
高 艳,岳 昆,武 浩,付晓东,刘惟一
(1.云南大学 信息学院,昆明 650504; 2.昆明理工大学 信息工程与自动化学院,昆明 650500)
(*通信作者电子邮箱kyue@ynu.edu.cn)
面向用户偏好发现的隐变量模型构建与推理
高 艳1,岳 昆1*,武 浩1,付晓东2,刘惟一1
(1.云南大学 信息学院,昆明 650504; 2.昆明理工大学 信息工程与自动化学院,昆明 650500)
(*通信作者电子邮箱kyue@ynu.edu.cn)
电子商务应用中产生了大量用户评分数据,而这些数据中富含了用户观点和偏好信息,为了能够从这些数据中准确地推断出用户偏好,提出一种面向评分数据中用户偏好发现的隐变量模型(即含隐变量的贝叶斯网)构建和推理的方法。首先,针对评分数据的稀疏性,使用带偏置的矩阵分解(BMF)模型对其进行填补;其次,用隐变量表示用户偏好,给出了基于互信息(MI)、最大半团和期望最大化(EM)算法的隐变量模型构建方法;最后,给出了基于Gibbs采样的隐变量模型概率推理和用户偏好发现方法。实验结果表明,与协同过滤的方法相比,该方法能有效地描述评分数据中相关属性之间的依赖关系及其不确定性,从而能够更准确地推断出用户偏好。
用户偏好;评分数据;贝叶斯网;隐变量模型;概率推理;带偏置的矩阵分解
0 引言
电子商务和推荐网站等Web 2.0应用产生了大量的用户对商品的评分数据,而这些评分数据中则包含了可直接观测到的用户和商品本身的属性,以及用户对商品的评分等,蕴含了用户对某种商品类型的偏好。近年来,从评分数据中提取用户偏好已经成为数据挖掘、推荐系统和个性化搜索研究的热点。相对商品类型和用户评分等可直接观测到值的变量而言,用户偏好是隐变量(Latent Variable)。从实际应用看,商品本身的属性、评分和用户偏好之间存在相互依赖关系,且具有不确定性。如何描述上述具有不确定性的依赖关系,是解决实际应用中针对观测属性来提取用户偏好的关键,进而为商品个性化推荐、用户划分和虚假评价检测等应用提供依据。对此,研究描述各观测属性(也称显变量)和用户偏好之间依赖关系及其不确定性的知识模型构建,以及基于该模型进行知识推理来发现用户偏好的方法,是本文研究的主要任务和基本思想。
近年来,用户偏好发现已有许多研究成果。例如,文献[1]提出基于用户认知行为的上下文感知的偏好获取方法;文献[2]提出一种偏好-主题模型,引入用户偏好维度来提取用户偏好。然而,上述工作并未考虑用户偏好与用户行为或相关属性间的内在联系,使得发现的用户偏好准确度不高。
通常情况,用户评分数据往往比较稀疏。例如,Amazon网站一般存在95%的数据缺失[3],进而无法计算各商品属性之间的依赖关系。Salakhutdinov等[4]提出了概率矩阵分解 (Probabilistic Matrix Factorization, PMF)模型,该模型以概率的形式描述评分矩阵和隐含特征矩阵。随后Salakhutdinov等[5]将PMF扩展为贝叶斯概率矩阵分解(Bayesian PMF, BPMF)模型,并用马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)方法进行训练,该模型的预测准确率较高,但BPMF模型是一种线性模型,并不能表示隐含特征之间的非线性关系。Koren[6]提出了带偏置的矩阵分解(Biased Matrix Factorization, BMF)模型,该模型对于稀疏性、数据扩展等问题都有良好的性能。评价中有很多因素取决于用户或商品本身的属性,本文将独立于用户或商品的因素视为偏置部分,将用户对商品的喜好视为个性化部分,利用矩阵分解中偏置部分对提高评分预测的准确率远远高于个性化部分这一结论,基于BMF模型来填补缺失的评分值,对评分数据进行预处理。
作为一种重要的概率图模型,贝叶斯网(Bayesian Network, BN)[7-8]是不确定性知识表示和推理的有效框架,被广泛应用于数据分析和医疗诊断等领域[9- 10],它以有向无环图(Directed Acyclic Graph, DAG)表示随机变量或属性间的依赖关系,每个节点对应一个条件概率表(Conditional Probability Table, CPT),定量地描述变量间的依赖关系。近年来,基于BN的用户偏好发现成为了一类有代表性的方法,例如,文献[11]提出一种非参数BN模型和从日志数据中提取某个用户的搜索意图的方法,文献[12]提出基于BN从Web服务的行为来动态提取用户偏好的方法。但是,上述方法中,BN的构建仅涉及观测到的数据,不能有效发现隐含关系,进而降低了用户偏好发现的准确性。
隐变量是描述不能直接观测其取值的变量,含有隐变量的BN简称隐变量模型(Latent Variable Model)[7]。Elidan等[13]指出,隐变量模型可以简化模型结构,使显变量之间的依赖关系更清晰,能够发现和表示数据中的隐含信息。如前所述,评分数据中蕴含的用户偏好并不能直接观测得到,自然地,本文用隐变量来表示用户偏好,以隐变量模型作为研究用户偏好发现的基础。因此,引入隐变量、并用隐变量直接表示用户偏好,可加强模型对用户行为模式的表达能力。文献[14]提出基于深度学习的隐马尔可夫模型和条件随机场来发现主题偏好的方法,文献[15]基于隐评论主题模型从评级推荐系统中用户反馈的短语信息中提取用户偏好。但以上研究未考虑数据中相关属性之间任意形式依赖关系的表示和相应的模型构建。
根据构建好的隐变量模型,可得到表示用户偏好的隐变量与其他显变量之间的依赖关系,因此考虑利用隐变量模型的概率推理机制,计算给定证据变量情形下隐变量(用户偏好)取值的概率,作为发现用户偏好的依据。由于BN的精确推理是NP困难的[16],即使评分数据中的属性不多,但其可能取值较多而使其计算复杂度仍然较高,不能有效地进行概率推理和用户偏好发现。Gibbs采样[17-18]能够支持高效的条件概率和后验概率的计算,且只要采样次数足够多,总能快速地收敛到一个稳定的正确值,因此本文给出基于Gibbs采样的隐变量模型近似推理算法和相应用户偏好发现方法。
具体而言,本文的研究主要包括以下三方面:
1)基于评分数据中的隐变量模型构建。本文首先对缺失评分值进行填补,然后基于BN给出商品属性贝叶斯网(Commodity BN, CBN),最后将描述用户偏好的隐变量插入CBN中,得到含隐变量的商品属性贝叶斯网(CBN with a Latent variable, CBNL)。
2)面向用户偏好发现的CBNL概率推理。本文基于Gibbs采样给出了CBNL模型的近似概率推理算法,该算法通过对给定的证据值计算隐变量可能取值的不确定性,来高效地计算发现用户偏好。
3)实验测试。基于MovieLens[19]上的数据集,实现并测试了本文提出的方法。实验结果表明,本文基于隐变量模型来发现用户偏好的方法具有一定的可行性。
1 问题陈述
用隐变量L表示用户对商品类型的偏好。假设L的取值为1和0,在每一个评分数据实例中,分别表示用户对相应商品类型有无偏好。例如,表1给出了电影评分数据片段,其中:X1表示电影类型(取值为k1、k2和k3),X2表示发行年代(取值为t1、t2和t3),X3表示评价(T、M和F分别代表好评、中评和差评),X4表示评分(取值为1,2,…,5)。假设对于第一个数据实例,L取值为1,说明用户1对发行年代为t1、评价为好评T、评分较高的电影类型k1有偏好。
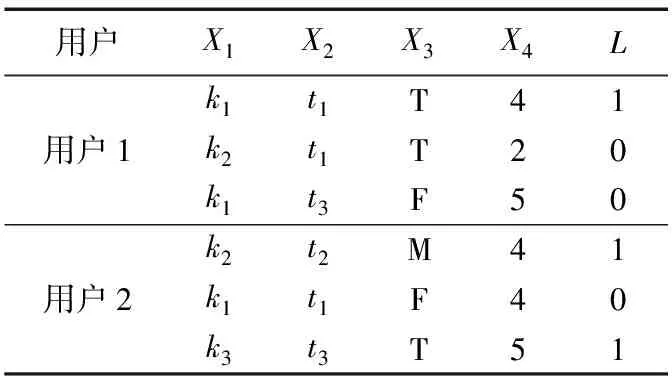
表1 电影评分数据片段
下面首先给出一些相关定义和概念。
BN是一个DAGG=(V,E),随机变量集V构成G中的节点,每个节点对应一个随机变量,节点状态对应随机变量取值,E中的有向边表示节点之间的依赖关系。如果存在从节点X指向节点Y(即X→Y)的有向边,称X是Y的一个父节点,变量X在G中的父节点集用Pa(X)表示。每个节点都有一个CPT,用以量化父节点集对该节点的影响。
基于BN的基本概念,下面给出商品属性贝叶斯网(CBN)的定义。
定义1CBN模型为一个DAGG=(V,E,θ),其中:V={X1,X2,…,Xn}为G中的节点集合,每个节点对应评分数据中的一个属性;E为G中节点间有向边的集合;θ为G中节点CPT的集合。有向边Xi→Xj(1≤i,j≤n,i≠j)表示Xj依赖于Xi。若Xi的父节点集合为Pa(Xi),则节点Xi的CPT为P(Xi|Pa(Xi))。给定Xi的父节点集Pa(Xi),Xi与其所有非后代节点条件独立。
将描述用户偏好的隐变量加入CBN中,可得到用户偏好与商品属性间依赖关系的隐变量模型,下面给出含隐变量的商品属性贝叶斯网(CBNL)的定义。
定义2CBNL为一个DAGGL=(V,L,E,θ)。其中:V∪L为GL中的节点集合,L为GL中表示用户偏好的隐变量,E为GL中节点间有向边的集合,θ为GL中CPT的集合。
CBNL的构建包括DAG构建和各节点CPT计算,下面分别介绍这两方面的工作。
2 评分数据中的隐变量模型构建
2.1 缺失评分值填补
BMF模型以概率的形式描述评分矩阵和隐含特征矩阵,并考虑用户和商品的偏置部分。例如,不同用户对商品的评分都有自己的标准,有的用户对商品的整体评分偏高,有的用户对商品的整体评分偏低。评分数据集D中的评分值往往非常稀疏,因此在D中抽取出“用户-商品”评分矩阵M,基于BMF模型来填补矩阵M中的缺失值,通过降维的思想来抽象出商品的T个隐含特征。
利用BMF模型填补矩阵M中的缺失值时,将矩阵M分解为用户隐含特征矩阵U和商品隐含特征矩阵V,则用户ui对商品vj的缺失评分可由式(1)表示:
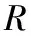
(1)
其中:μ为M中所有评分记录的全局评分平均值,用户偏置bi是独立于商品特征的因素,商品偏置bj是独立于用户兴趣的因素。
采用平方误差作为损失函数,利用式(2)使已知评分与填补评分之间的误差最小,即计算出的评分尽可能与实际评分相吻合。
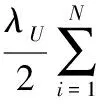
(2)
表2为基于BMF模型进行评分值填补前、后的用户-商品评分矩阵。特别强调,即使用户u4没有对任何商品给出评分,通过BMF仍能得到比较合理的评分。
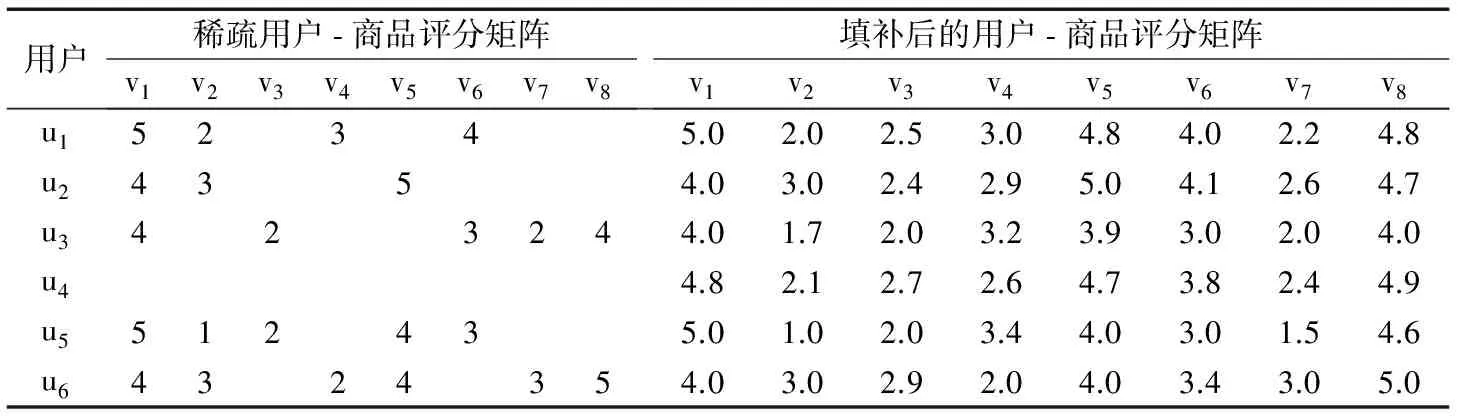
表2 基于BMF模型得到的填补评分矩阵
基于上述方法,可以填补矩阵M中的所有缺失评分值,得到完整的评分矩阵M,根据统计算出每个用户对某种商品类型的平均评分,从而得到完整的商品评分数据集,为CBN构建进行数据预处理。
2.2 CBNL模型结构构建
本文提出的CBN构建方法,通过计算两个商品属性之间的互信息[20](式(3))和条件互信息,来判断两个属性之间的依赖关系。

(3)
根据式(4)所示的条件互信息计算公式[20]可以判断两个商品属性之间的条件独立性。
I(Xi,Xj|C)=
(4)
其中:C表示节点Xi和Xj的最小割集,最小割集指Xi和Xj的所有邻接路径上的邻居节点,邻接路径是两个节点间所有边构成的路径。与Xi相邻的节点存入集合N1中,与Xj相邻的节点存入N2中,若|N1|<|N2|,则N1中元素为最小割集,否则N2中元素为最小割集。
基于上述方法来判断两个属性之间是否有边,见算法1。
算法1CBN结构构建。
输入 商品评分数据集D,商品相关属性X={X1,X2,…,Xn},节点顺序ρ和阈值ω;
输出CBN的DAG结构:G=(X,E)。
1)
确定网络初始结构。G←由节点X1,X2,…,Xn组成的无边图,H←∅,E←∅
/*H为节点对列表,E为有向边集合*/Forρ中任意两个不同变量DoIfI(Xi,Xj)>ωThenH←H∪(Xi,Xj)
EndFor
按I(Xi,Xj)由大到小的顺序重排H中的节点对
ForH中不存在开放路径的节点对(Xi,Xj)Do
/*开放路径是不存在碰撞节点的路径,
碰撞节点指大于1条边指向它的节点*/ 根据ρ连接Xi和Xj,将(Xi,Xj)添加到E中H←H{Xi,Xj}
EndFor
H1←H
2)
缺边检测。
IfH1=∅Thengoto3)
ElseFor对每个节点对(Xi,Xj)∈H1DoZ←min{cut(Xi, Xj)}IfI(Xi,Xj|Z)>ωThen根据ρ连接Xi与Xj,将(Xi,Xj)添加到E中
EndFor
EndIf
3)
冗余边检测。
For对每条有向边(Xi,Xj)∈EDoIfXi与Xj间还有其他路径Then暂时删除(Xi,Xj),Z←min{cut(Xi,Xj)}IfI(Xi,Xj|Z)>ωThen将(Xi,Xj)添加到E中
Else永久删除(Xi,Xj)
EndIf
EndIf
EndFor
ReturnG
算法1对于包含m个数据实例、n个节点的DAG,式(3)执行O(n2)次,每次计算时间为O(m);而互信息大于ω(ω为给定的互信息阈值,为了尽可能多地表达节点之间的依赖关系,ω一般取值为[0.01,0.05])的节点对才计算条件互信息,式(4)的执行次数远小于O(n2)。因此,算法1可在O(mn2)时间内构建CBN。
在构建好的CBN结构G中,基于最大半团插入表示用户偏好的隐变量,得到CBNL结构。下面首先给出判断半团和最大半团的定义。
定义3[12]假设Q是BN中的节点集合,若对于任一节点Y∈Q,有|Δ(Y;Q)|>2-1|Q|,其中Δ(Y;Q)表示Y在Q中的邻居节点(Y的父节点或孩子节点)组成的集合,|Q|为Q中节点数,则Q是一个半团。
定义4 若在半团T中引入与T相邻的所有节点都不满足半团定义,那么T是一个最大半团。
为了构建CBNL结构,首先搜索G中所有包含3个属性的子团(即3-clique);然后对每个子团进行扩展,找到G中所有的最大半团C={C1,C2,…,Cm};其次向每个最大半团中插入表示用户偏好的隐变量,得到m个候选模型结构;最后对每一个模型结构分析与隐变量相关的依赖关系,据此判断该隐变量是否能够表示用户偏好。任选一个模型结构作为最终的CBNL结构GL,见算法2。
算法2CBNL结构构建。
输入CBN模型结构G;
输出CBNL模型结构GL。
从G中找出所有的3-clique结构{C1,C2,…,Cn}Fori←1tonDoFor对任意与Ci直接相连的节点XjDoIf{Ci∪Xj}满足半团定义ThenCi←Ci∪Xj
EndIf
EndFor
EndFor
去除重复的最大半团,得到{C1,C2,…,Cm}
Fori=1tomDo删除Ci中的所有边,若|Pa(Xj)|≥1,则将L作为Xj的父节点,否则Xj作为L的父节点
EndFor
在m个候选结构δ1,δ2,…,δm中选择一个作为GL
ReturnGL
例如,对于表1中的评分数据集D及相关属性,由算法1可得到如图1(a)所示的CBN结构;再由算法2可以找到2个3-clique,C1={X1,X3,X4},C2={X2,X3,X4},分别对其扩展得到相同的最大半团结构C={X1,X2,X3,X4},在C中插入表示用户偏好的隐变量L,可得到如图1(b)所示的CBNL结构。

图1 CBNL结构构建
2.3 条件概率参数计算
期望最大化(ExpectationMaximization,EM)算法[21]主要用于在含有隐变量的概率模型中计算参数的最大似然估计(MaximumLikelihoodEstimation)或极大后验概率估计。因此,基于2.2节中得到的CBNL结构,使用EM算法来估算该结构中各节点的CPT。EM算法从随机产生的初始值θ0开始迭代,假设已迭代了t-1次,那么第t次迭代由如下步骤完成。
E步:基于θt-1对隐变量取值进行修补,利用式(5)计算期望对数似然函数。

(5)
其中:m是评分数据集D中的实例数,l是隐变量L的取值。
M步:利用式(6)计算使Q(θ|θt)达到最大时θ的取值。
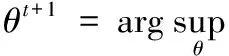
(6)
E步和M步不断交替进行,直到各节点的CPT收敛到稳定值。
例如,针对图1(b)所示的CBNL结构,鉴于描述的方便,假定商品评分数据中的每个属性可能取值数为2,基于EM算法得到各节点的CPT,最终的CBNL如图2所示。
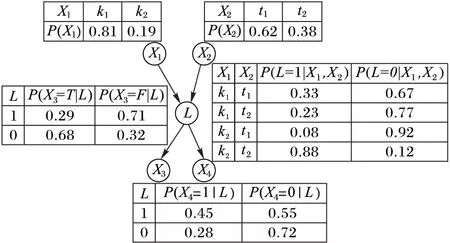
图2 最终的CBNL
3 面向偏好发现的CBNL概率推理
为了进行基于CBNL的用户偏好发现,对CBNL进行概率推理时,把隐变量作为目标变量,把CBNL中与隐变量有直接依赖关系的属性作为证据变量(即已知变量)。经过Gibbs采样算法多次迭代计算得到隐变量的最大后验概率值,将计算出的概率值与给定的偏好阈值进行比较,从而发现用户对商品类型是否有偏好。
Gibbs采样算法从满足条件分布中迭代地进行抽样,当迭代次数足够大时,就可以得到来自联合后验分布的样本。为了简化计算而又不失一般性,对于隐变量的计算仅考虑其马尔可夫覆盖(X的马尔可夫覆盖包括X的直接孩子节点、X的直接父节点、以及X的直接孩子的其他父节点的集合,记为MB(X))中的节点对它的影响。见算法3。
算法3 基于Gibbs采样的CBNL概率推理。
输入GL=(V,L,E,θ),证据变量集合Φ,Φ的取值e,非证据变量L,L的取值l,遍历次数s;
输出P(L=1|e)。
1)
初始化。 随机地为L赋值,v0←e∪l,N[l]←0
/*N[l]为L取1的个数*/
2)
产生样本序列。Fork←1tosDoFor每一个样本v(k)中的LDoB←P(L=0|vMB(L))+P(L=1|vMB(L))

v(k)←(v(k-1)(-l),l)
/*v(k-1)(-l)表示在第(k-1)个样本中去除L值后的样本*/
EndFor
EndFor
3)
计算P(L=1|e)。
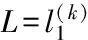
/*l(k)1为第k次采样中L=1*/N[l]←N[l]+1
EndIf
EndFor
P(L=1|e)←N[l]/s
利用算法3,基于给定的阈值λ,若P(L=1|e)≥λ,则认为用户对这样的商品类型有偏好。文献[16, 22]指出,只要采样次数足够多,Gibbs采样算法总能收敛到一个稳定的正确值,后面将通过实验进一步测试算法3的收敛性和正确性。
针对图2中的CBNL,计算P(L=1|X1=k1,X2=t1,X3=T,X4=1)。随机地为L赋值得到D0=[X1=k1,X2=t1,L=0,X3=T,X4=1]。第一次对L采样,有P(L=1|X1,X2,X3,X4)=0.25,则P(L=0|X1,X2,X3,X4)=0.75,若r1=0.4,得到D1=[X1=k1,X2=t1,L=0,X3=T,X4=1]。若采样300次,其中L=1有250次,则P(L=1|X1=k1,X2=t1,X3=T,X4=1)=0.833,表明用户对发行年代为t1、好评、高分的电影类型t1有偏好。
4 实验结果与分析
本文使用MovieLens[19]上用户评分数据作为测试数据集,包含6 040个用户对3 900部电影的1 000 209条评分数据,将电影类型、发行年代、评价(从标签中抽取出来)和评分4个属性作为CBNL的节点。实验环境:IntelPentiumDual-Core2.0GHz处理器,2GB内存,Windows7(32位)操作系统,使用MatlabR2012b作为开发平台。
首先,测试基于BMF模型进行评分值填补结果的准确性,并在不同的数据量情形下与PMF[4]、BPMF[5]模型进行比较。用平均绝对误差(MeanAbsoluteError,MAE)和均方根误差(RootMeanSquaredError,RMSE)作为衡量填补结果准确性的依据,MAE和RMSE值越小,说明填补的数据与真实数据之间的误差越小。如图3、图4所示,在不同数据量情形下,BMF模型填补数据时的MAE和RMSE值均最小,这说明BMF模型在数据填补时更为准确。
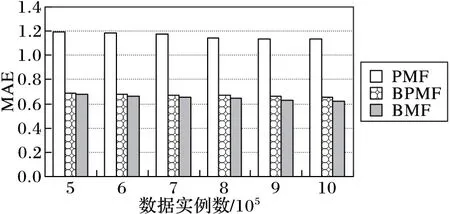
图3 MAE值
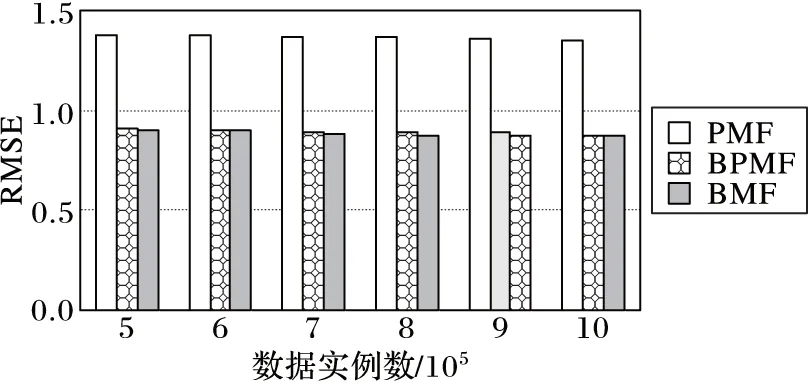
图4 RMSE值
然后,测试CBNL构建算法的执行效率。在数据实例为2×104情形下,测试节点数分别为5、7、9、11、13时构建CBNL的时间开销,结果如图5所示,表明构建CBNL的时间开销主要取决于参数计算;还测试了数据实例数分别为1×104、10×104、20×104,…,60×104时构建CBNL的时间开销,结果如图6所示,也表明CBNL构建的时间主要取决于参数计算,且随着数据实例数的增加基本呈线性趋势增加。

图5 不同节点数的CBNL构建效率
进一步,测试了参数计算的准确性。从测试数据集中选取包括5×104、10×104、15×104个数据实例的片段,把其中一个已知属性值当作未知的,用EM算法迭代计算MLE值,然后用得到的MLE值与原MLE值进行对比,将其比值作为误差来衡量参数计算的准确性,结果如图7所示。可以看出,随着迭代次数的增加,EM算法收敛到一个稳定的值,且数据量越大,计算出的MLE值与真实值越接近。
其次,测试了基于CBNL推理发现用户偏好的效率,图8和图9分别给出了在不同数据量的情形下,随着采样次数增加,算法3返回结果的收敛性和执行的时间开销。从图8可以看出,随着采样次数的增加,不同数据量情形下的推理结果均能快速地收敛到一个稳定的值;从图9可以看出,在不同数据量的情形下,算法3的执行时间均能随着采样次数呈线性增长。
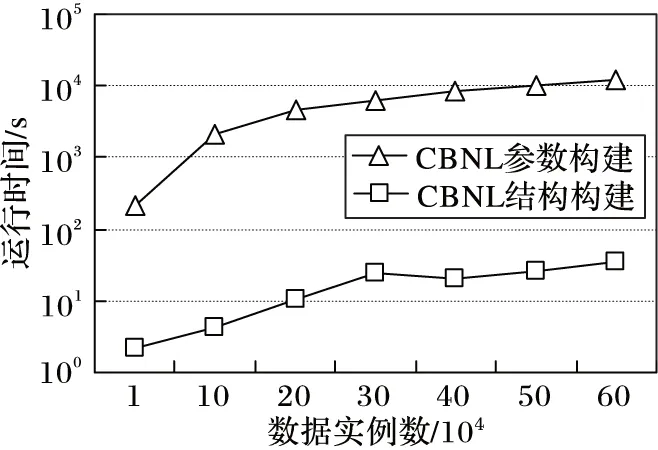
图6 不同实例数的CBNL构建效率
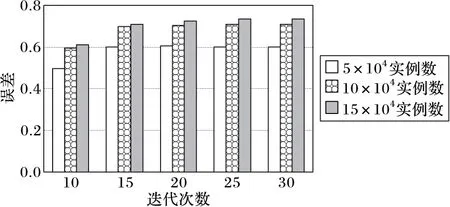
图7 CBNL参数计算的准确性

图8 CBNL近似推理结果收敛性
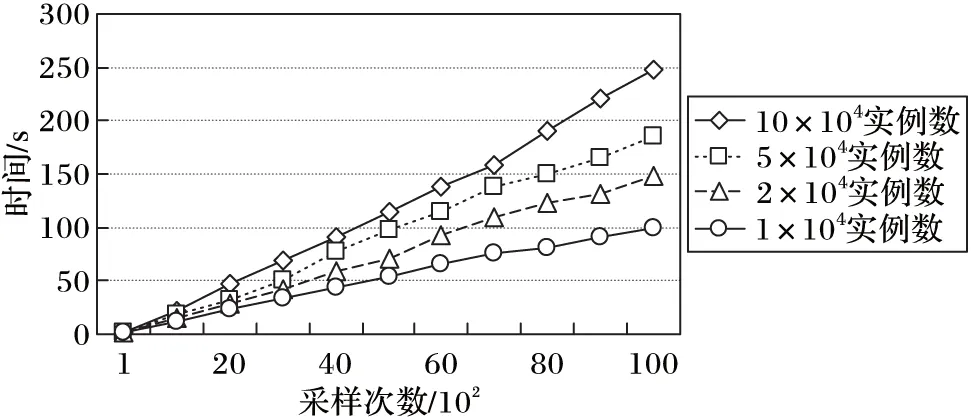
图9 CBNL推理算法效率
最后,测试了基于CBNL推理发现用户偏好的准确性。假设评分数据中的评分反映了真实的用户偏好,针对4或5分的评价,通过多次实验确定偏好阈值为0.67。随机选取3名用户(记为u1、u2和u3),同时选取20部他们都评价过的电影作为测试数据,其中10部电影的评价作为训练数据,剩下10部电影的评价作为对比数据。表3给出了3名用户对10部电影的评分。
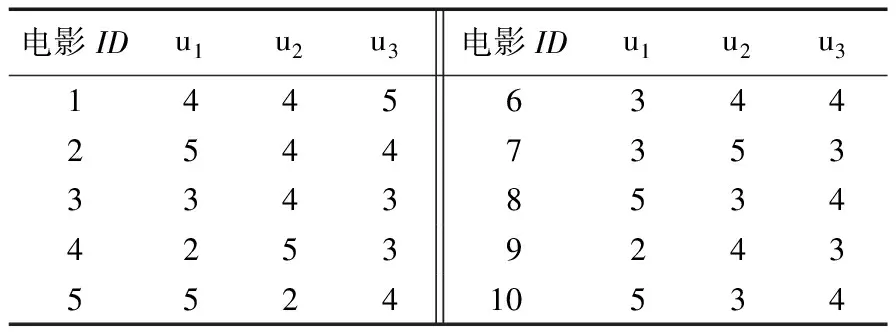
表3 用户对电影的评分信息
将基于协同过滤(CollaborativeFiltering,CF)的方法[23]和本文方法进行对比,该CF方法预测评分时定义了一个推荐值来适当地提高未知商品的评分。本文方法选定u1为目标用户,基于余弦相似度得到u1和u3最相似,将后10部电影按u1的喜好推荐给u3。其中表4给出他们对后10部电影的评分信息,u1的评分是真实的用户评分,通过CF预测得到u3的评分与u3真实的评分相比,正确率为60%,通过本文方法发现用户偏好的正确率为70%。可以看出,基于本文方法发现用户偏好的结果比CF预测得到的评分正确率高,这从一定程度上说明了本文方法的正确性和有效性。

表4 用户对电影的预测评分信息
5 结语
本文基于隐变量模型和概率推理,提出了从商品评分数据中发现用户偏好的方法,解决了现有方法不能描述评分数据中相关属性间任意形式的依赖关系问题,可支持实际中商品推荐和用户定向等应用。
作为基于概率图模型进行偏好发现的初步试探性研究,本文构建隐变量模型时只引入一个二值隐变量,且未考虑评分数据大规模和动态性。引入多个隐变量、考虑与实际更吻和的情形,从海量用户评分数据中来发现用户偏好,满足海量数据处理需求和针对实际情形下用户偏好发现的可行性,是将来要开展的工作。
)
[1] 高全力,高岭,杨建峰,等.上下文感知推荐系统中基于用户认知行为的偏好获取方法[J].计算机学报, 2015,38(9):1767-1776.(GAOQL,GAOL,YANGJF,etal.Apreferenceelicitationmethodbasedonuser’scognitivebehaviorforcontext-awarerecommendersystem[J].ChineseJournalofComputers, 2015, 38(9): 1767-1776.)
[2]LIUL,ZHUF,ZHANGL,etal.Aprobabilisticgraphicalmodelfortopicandpreferencediscoveryonsocialmedia[J].Neurocomputing, 2012, 95: 78-88.
[3] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012:196-212.(XIANGL.PracticeofRecommendationSystem[M].Beijing:Posts&TelecomPress, 2012: 196-212.)
[4]SALAKHUTDINOVR,MNIHA.Probabilisticmatrixfactorization[C]//NIPS2008:Proceedingsofthe2008ConferenceonNeuralInformationProcessingSystems,Cambridge,MA:MITPress, 2008: 1257-1264.
[5]SALAKHUTDINOVR,MNIHA.BayesianprobabilisticmatrixfactorizationusingMarkovchainMonteCarlo[C]//ICML’08:Proceedingsofthe25thInternationalConferenceonMachineLearning.NewYork:ACM, 2008: 880-887.
[6]KORENY.Factorizationmeetstheneighborhood:amultifacetedcollaborativefilteringmodel[C]//KDD’08:Proceedingsofthe14thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2008: 426-434.
[7] 张连文,郭海鹏.贝叶斯网引论[M].北京:科学出版社,2006:31-36,194.(ZHANGLW,GUOHP.IntroductiontoBayesianNetworks[M].Beijing:SciencePress, 2006: 31-36, 194.)
[8]HECKERMAND.AtutorialonlearningwithBayesiannetworks[M]//InnovationsinBayesianNetworks:TheoryandApplications,Volume156oftheSeriesStudiesinComputationalIntelligence.Berlin:Springer-Verlag, 2008: 33-82.
[9]DAYEJ,YEUYK,AHNJ,etal.Inferenceofdisease-specificgeneinteractionnetworkusingaBayesiannetworklearnedbygeneticalgorithm[C]//SAC’15:Proceedingsofthe30thAnnualACMSymposiumonAppliedComputing.NewYork:ACM, 2015: 47-53.
[10]ZHANGJ,CORMODEG,CECILIAM,etal.PrivBayes:privatedatareleaseviaBayesiannetworks[C]//SIGMOD’14:Proceedingsofthe2014ACMSIGMODInternationalConferenceonManagementofData.NewYork:ACM, 2014: 1423-1434.
[11]WANGH,ZHAICX,LIANGF,etal.UsermodelinginsearchlogsviaanonparametricBayesianapproach[C]//WSDM’14:Proceedingsofthe7thACMInternationalConferenceonWebSearchandDataMining.NewYork:ACM, 2014: 203-212.
[12]BIANJ,LONGB,LIL,etal.ExploitinguserpreferenceforonlinelearninginWebcontentoptimizationsystems[J].ACMTransactionsonIntelligentSystemsandTechnology—SpecialIssueonLinkingSocialGranularityandFunctions, 2014, 5(2):ArticleNo.33.
[13]ELIDANG,LOTNERN,FRIEDMANN,etal.Discoveringhiddenvariables:astructure-basedapproach[C]//NIPS2000:Proceedingsofthe2000ConferenceonNeuralInformationProcessingSystems.Cambridge,MA:MITPress, 2000: 479-485.
[14] 吴蕾,张文生,王珏.基于深度学习框架的隐藏主题变量图模型[J].计算机研究与发展,2015,52(1):191-199.(WUL,ZHANGWH,WANGJ.Hiddentopicvariablegraphicalmodelbasedonlearningframework[J].JournalofComputerResearchandDevelopment, 2015, 52(1): 191-199.)
[15]GUANL,ALAMMH,RYUW-J,etal.Aphrase-basedmodeltodiscoverhiddenfactorsandhiddentopicsinrecommendersystems[C]//BigComp2016:ProceedingsoftheInternationalConferenceonBigDataandSmartComputing.Washington,DC:IEEEComputerSociety, 2016: 337-340.
[16] 张宏毅,王立威,陈瑜希.概率图模型研究进展综述 [J].软件学报,2013,24(11):2476-2497.(ZHANGHY,WANGLW,CHENYX.Researchprogressofprobabilisticgraphicalmodels:asurvey[J].JournalofSoftware, 2013, 24(11): 2476-2497.)
[17]HRYCEJT.GibbssamplinginBayesiannetworks[J].ArtificialIntelligence, 1990, 46(3): 351-363.
[18] 岳昆,王朝禄,朱运磊,等.基于概率图模型的互联网广告点击率发现[J].华东师范大学学报(自然科学版),2013(3):15-25.(YUEK,WANGCL,ZHUYL,etal.Click-throughratepredictionofonlineadvertisementsbasedonprobabilisticgraphicalmodel[J].JournalofEastChinaNormalUniversity(NaturalScience), 2013(3): 15-25.)
[19]MovieLens[EB/OL].[2016- 03- 18].http://grouplens.org/datasets/movielens/latest/.
[20]CHENGJ,BELLDA,LIUW.LearningBayesiannetworksfromdata:anefficientapproachbasedoninformationtheory[J].ArtificialIntelligence, 2002, 137(1/2): 43-90
[21]DEMPSTERAP,LAIRDNM,RUBINDB.MaximumlikelihoodfromincompletedataviatheEMalgorithm[J].JournaloftheRoyalStatisticalSociety,SeriesB(Methodological), 2007, 39(1): 1-38.
[22]PEARLJ.Evidentialreasoningusingstochasticsimulationofcausalmodels[J].ArtificialIntelligence, 1987, 32(2): 245-257.
[23]SHIHT-Y,HOUT-C,JIANGJ-D,etal.Dynamicallyintegratingitemexposurewithratingpredictionincollaborativefiltering[C]//SIGIR’16:Proceedingsofthe39thInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.NewYork:ACM, 2016: 813-816.
ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61472345, 61562090, 61462056),theAppliedBasicResearchProjectofYunnanProvince(2014FA023, 2014FA028),theProgramofYunnanProvincialFoundationforLeadersofDisciplinesinScienceandTechnology(2012HB004),theProgramforExcellentYoungTalentsinYunnanUniversity(XT412003),theProgramforInnovativeResearchTeaminYunnanUniversity(XT412011).
GAO Yan, born in 1991, M.S.candidate.Her research interests include knowledge discovery, social media data analysis.
YUE Kun, born in 1979, Ph.D., professor.His research interests include massive data analysis and services.
WU Hao, born in 1979, Ph.D., associate professor.His research interests include information retrieval, recommendation system, service computing.
FU Xiaodong, born in 1975, Ph.D., professor.His research interests include service computing, intelligent decision.
LIU Weiyi, born in 1950, professor.His research interests include artificial intelligence, data and knowledge engineering.
Construction and inference of latent variable model oriented to user preference discovery
GAO Yan1, YUE Kun1*, WU Hao1, FU Xiaodong2, LIU Weiyi1
(1.SchoolofInformationScienceandEngineering,YunnanUniversity,KunmingYunnan650504,China;2.FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,KunmingYunnan650500,China)
Large amount of user rating data, involving plentiful users’ opinion and preference, is produced in e-commerce applications.An construction and inference method for latent variable model (i.e., Bayesian Network with a latent variable) oriented to user preference discovery from rating data was proposed to accurately infer user preference.First, the unobserved values in the rating data were filled by Biased Matrix Factorization (BMF) model to address the sparseness problem of rating data.Second, latent variable was used to represent user preference, and the construction of latent variable model based on Mutual Information (MI), maximal semi-clique and Expectation Maximization (EM) was given.Finally, an Gibbs sampling based algorithm for probabilistic inference of the latent variable model and the user preference discovery was given.The experimental results demonstrate that, compared with collaborative filtering, the latent variable model is more efficient for describing the dependence relationships and the corresponding uncertainties of related attributes among rating data, which can more accurately infer the user preference.
user preference; rating data; Bayesian network; latent variable model; probabilistic inference; biased matrix factorization
2016- 08- 12;
2016- 09- 06。 基金项目:国家自然科学基金资助项目(61472345, 61562090, 61462056);云南省应用基础研究计划项目(2014FA023, 2014FA028);云南省中青年学术和技术带头人才后备人才培育计划项目(2012HB004);云南大学青年英才培育计划项目(XT412003);云南大学创新团队培育计划项目(XT412011)。
高艳(1991—),女,云南曲靖人,硕士研究生,CCF会员,主要研究方向:知识发现、社会媒体数据分析; 岳昆(1979—),男,云南曲靖人,教授,博士生导师,博士,CCF会员,主要研究方向:海量数据分析与服务; 武浩(1979—),男,河南平顶山人,副教授,博士,主要研究方向:信息检索、推荐系统、服务计算; 付晓东(1975—),男,云南镇雄人,教授,博士,CCF会员,主要研究方向:服务计算、智能决策;刘惟一(1950—),男,云南昆明人,教授,博士生导师,CCF会员,主要研究方向:人工智能、数据与知识工程。
1001- 9081(2017)02- 0360- 07
10.11772/j.issn.1001- 9081.2017.02.0360
TP311.13; TP181
A
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
World Journal of Diabetes(2019年3期)2019-04-16
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
新高考·高二数学(2014年7期)2014-09-18
