
一种基于多值属性的改进Apriori算法
2017-04-21 05:26杨小兵
中国计量大学学报 2017年1期
赵 龙,杨小兵,吴 强,高 宇
(中国计量大学 信息工程学院,浙江 杭州 310018)
一种基于多值属性的改进Apriori算法
赵 龙,杨小兵,吴 强,高 宇
(中国计量大学 信息工程学院,浙江 杭州 310018)
随着大量需要被挖掘的数据变得越来越复杂,多维关联规则已经成为关联规则挖掘中最实用的内容之一.本文主要介绍了在多维关联规则挖掘过程中,针对同一种属性数据出现重复连接的情况,由此而提出的一种解决方案.通过对多值属性信息进行比较,去除重复连接的属性信息,保留有效信息,减少对数据库的扫描.由此对Apriori算法中连接步进行改进,最后通过布尔型关联规则挖掘数据信息并得到结果.相较于Apriori算法,改进算法能更加快速准确地发现知识,缩短挖掘所用的时间.
多维关联规则;多值属性;Apriori算法;布尔型关联规则
数据在当今时代已经成为一种重要的资源,面对庞大复杂的信息数据,数据挖掘在这种背景下得到了较快的发展.关联规则挖掘是数据挖掘的重要手段之一.在关联规则挖掘中,由于数据的维度不同,可以将关联规则分为单维关联规则和多维关联规则;根据数据的抽象层次分为单层和多层关联规则;根据属性的类型可以分为布尔型和数值型关联规则[1].它们在面对不同的事务类型时采取不同的挖掘方式,交易型数据库和关系型数据库是它们主要处理的事务数据类型.
SRIKANT R和AGRAWAL R[2]在1996年提出了多值属性关联规则,KAREl F[3]等人也提出了关于多值属性的挖掘算法,这种思想的主要内容是将多值属性关联规则转化成布尔型关联规则,然后再通过Apriori算法进行挖掘计算.但是这种方法也存在着不足之处,会使事务数据库的属性值不断增加,数据会变得复杂,给挖掘过程带来了不少难处.近年来,还有很多关于多值属性算法的尝试,国内和国外一些研究者尝试用矩阵的方法来处理多值属性的数据[4-6],这在一定程度上解决了关联规则转化带来的问题;但同时矩阵在进行数据存储和处理也带来了其他问题,当数据量很大时,可能无法处理这些由矩阵存储的数据,这会使计算变得相当复杂.还有很多使用关联规则改进算法进行数据挖掘的尝试[7-9],但是过程中都出现了不可避免的同种属性值连接的情况,一方面数据复杂的属性值影响了算法的效率,另一方面算法的使用中没涉及到处理同种属性值连接的情况,影响了算法的挖掘效率.
针对以上情况,提出的算法改进之处是针对于多值属性关联规则,面对同属性值连接时,为了不让同种属性值产生重复连接,通过提前判断是否有同种属性值已经出现在挖掘的信息数据中,这种做法可以避免由于重复连接而产生的数据信息杂乱问题,而且在扫描数据库时能够节省时间,相对于Apriori算法,有更好的挖掘效率.
1 多维关联规则
在关联规则中,每个不同的谓词称为维,规则中只出现一种谓词的称之为单维关联规则,涉及到两个或者多个谓词的关联规则称为多维关联规则.许多算法只关注单维或者布尔型关联规则挖掘,这种方法只能发现单个属性或属性值的有无信息,例如:
buy(X,"laptop")⟹buy(X,"printer")
只能记录是否购买,这种算法并不适合现在的数据挖掘情况.在实际挖掘数据库时,经常会遇到多谓词表达的信息,例如:
age(X,"20…29")∧occupation(X,"student")⟹buy(X,"laptop")
这种表达方式就能更多的体现信息的丰富程度,更有利于信息的挖掘.
在关联规则挖掘中还有两个非常重要的概念:支持度和置信度.它们是衡量规则兴趣度重要的标准,分别反映了规则的有用性和确定性.如果一条规则A⟹B成立,并且具有支持度s和置信度c,在这个规则中认为有:
support(A⟹B)=P(A∪B),
(1)
confidence(A⟹B)=P(A|B).
(2)
如果规则A⟹B的支持度和置信度同时满足最小支持度和最小置信度,认为A⟹B这条规则是一条强规则.在关联规则挖掘中,最后发现的规则通常是由规则以及这条规则的支持度和置信度共同构成,进而为判断挖掘的模式是否具有参考价值提供依据.
针对如何解决多维关联规则中复杂的属性值问题,提出对多值属性数据进行预处理以及对算法进行改进来实现高效率的挖掘.
2 多值属性数据及特点分析
实验时所采用的多值属性数据样例,如表1,数据来源于医院的医疗数据,用于记录病人和用药信息.数据已经进行了清洗与整理,在处理之后基础上,将有用的属性信息保存下来,得到实验数据样例.

表1 处理后的多值属性数据样例
数据中包含的属性有性别、年龄、项目代号、药品编号、剂量和影响,每个属性都有若干个属性值.其中在影响这一属性中,测试内容包含病人在用药前、用药过程中、以及用药后三种状态下体内某指标的指数高低,使用代号a表示指数过低,b代表正常,c代表过高.abb就代表病人在使用药品这个过程中,体内某指标由用药前指数过低,用药过程中指数正常,用药后也正常.
多值属性关联规则的目标是挖掘频繁项集[10].针对多值属性数据,发现每一条规则中含有很多个属性,但是针对于每个属性都只有一个值与其属性相对应;对于一条规则中如果出现两个或者多个属性值同时对应于一个属性的情况,这种挖掘出来的数据信息是不合理的.例如在样例数据中,若使用Apriori算法进行挖掘,会出现这样的候选项集:
age(X,"61…70")∧age(X,"71…80")∧age(X,"80…90")
很显然这种候选集是不正确的,满足这种规则的数据是不会存在的,它对应的支持度在数据库里面的支持度和置信度为0.就是利用这种多值属性数据的性质,在挖掘的结果中,同一种属性的多个属性值只能出现一次,由此对Apriori算法进行改进.
3 算法改进
在主要的算法结构上,使用Apriori算法的结构和层次.通过使用逐层搜索的迭代方法,从低数据项集一直找到高数据项集.这个算法的过程是首先扫描数据库,计算出每个数据项的数量,将满足不小于最小支持度的数据项定为频繁1项集L1,然后通过使用连接步,找到频繁2项集L2,继续下去可以找到L3,…Lk,直到结束为止.
输入:
D:事务数据库
min_sup:最小支持度阈值
输出:
L,D中的频繁项集
1)L1=find_frquent_1-itemsets(D)
2)for(k=2;Lk-1≠Ø;k++){
3)Ck=Apriori_gen(Lk-1)
4)for each transactiont∈D{ //扫描数据库D进行计数
5)Ct=subset(Ck,t) //得到t的子集,它们是频繁项集
6)for each candidatec∈Ct
7)c.count++}
8)Lk={c∈Ck∣c.count≥min_sup}}
9)ReturnL=UkLk
主要内容介绍是如何在连接步的过程中实现更快更简洁的发现知识.通过分析所要挖掘数据的信息和数据的结构,选择合适的挖掘方案和步骤.不难发现所要挖掘的数据量庞大而且繁杂,数据的属性有性别、年龄、项目编号、药品编号、剂量和影响,而且对于每个属性内部,都有各自不同的属性值,这在挖掘时候难免会变得繁杂.为了避免这种情况的发生,通过使用编码的方式对每个属性和属性值都进行编码,使用一系列的编码来表达每条数据所隐藏的信息,这样既方便了属性值复杂的表达,而且在使用过程中能和算法进行结合.通过布尔型关联规则挖掘算法进行实验,这就使复杂的数据挖掘得到了较好的解决.
不同于其他的布尔型关联规则,在探讨挖掘过程中出现的问题时,由于数据中有很多的属性,而且每种属性都有很多的属性值,在挖掘过程中,属性值之间的连接,可能会出现同一种属性的不同属性值进行连接,这是不合适的挖掘结果.如果采取传统的方法,将挖掘出来的信息会与原有的数据库内容进行扫描和验证对比,对于出现同种属性的不同属性值的挖掘信息就会舍弃掉,但是这种方法无疑会耗费巨大的计算资源,让挖掘的效率变得比较低.本文探讨的是在连接步之后,通过比较能提前判断是否有重复属性值的连接,这样能避免重复连接的同时,也不需要再和数据库中的数据进行验证对比,节约了计算资源,有较好的挖掘效率.
在算法上,通过下面的算法步骤实现避免出现同种属性不同属性值的重复连接.
Procedure Apriori_gen (Lk-1: frequent(k-1) itemset)
1)for each项集l1∈Lk-1
2)for each项集l2∈Lk-1
3)if(l1[1]=l2[1])&&…&&
(l1[k-2]=l2[k-2])&&(l1[k-1]=l2[k-1])
then{
4)c=l1连接l2
//连接步:产生候选
5)ifl1与l2中有相同的属性且属性值不同then
6)deletec
//删除重复连接的候选
7)else if has_infrequent_subset(c,Lk-1) then
8)deletec
//删除非频繁的候选
9)else addctoCk}
10)returnCk
在算法的过程中加入了相同属性值连接的检测.通过比较新连接属性对应的编码和已经存在于频繁项集中属性对应的编码是否有重合,如果重合,说明新连接的属性已经存在,将删除该新连接;若编码不重合,说明该连接可以形成新的候选项集,直到不能发现新的频繁项集为止.通过扫描数据之前进行提前判断候选项集是否满足多值属性数据的性质,即同一种属性的多个属性值只能出现一次,这样能够有效避免出现相同属性的不同属性值出现连接,进而提高挖掘效率.
4 实验及分析
实验是在Core i5-3470 CPU 3.2 GHz,4 G内存的硬件环境下,操作系统为Windows环境,使用eclipse编程实现.数据采用医院的医疗数据,数据已经经过预处理和清洗,作为实验的原始数据,开始实验并得到实验结果.针对不同的条件,给出以下两种情况,一是在相同的支持度情况下,比较挖掘采用数据量和挖掘所耗费的时间之间的关系;二是在相同数据量的情况下,比较支持度和挖掘耗费时间之间的关系.改进后算法对于数据量的要求和数据内容的要求相对严格,针对不同量级的数据量,挖掘效率的体现也不一样.
当将支持度设置为0.2%时,Apriori算法和改进Apriori算法的挖掘效果比较,如表2和图1.
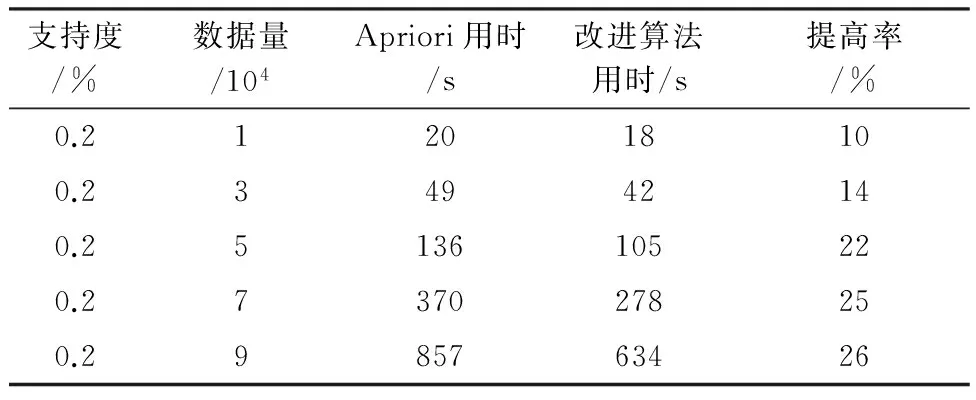
表2 实验数据记录表
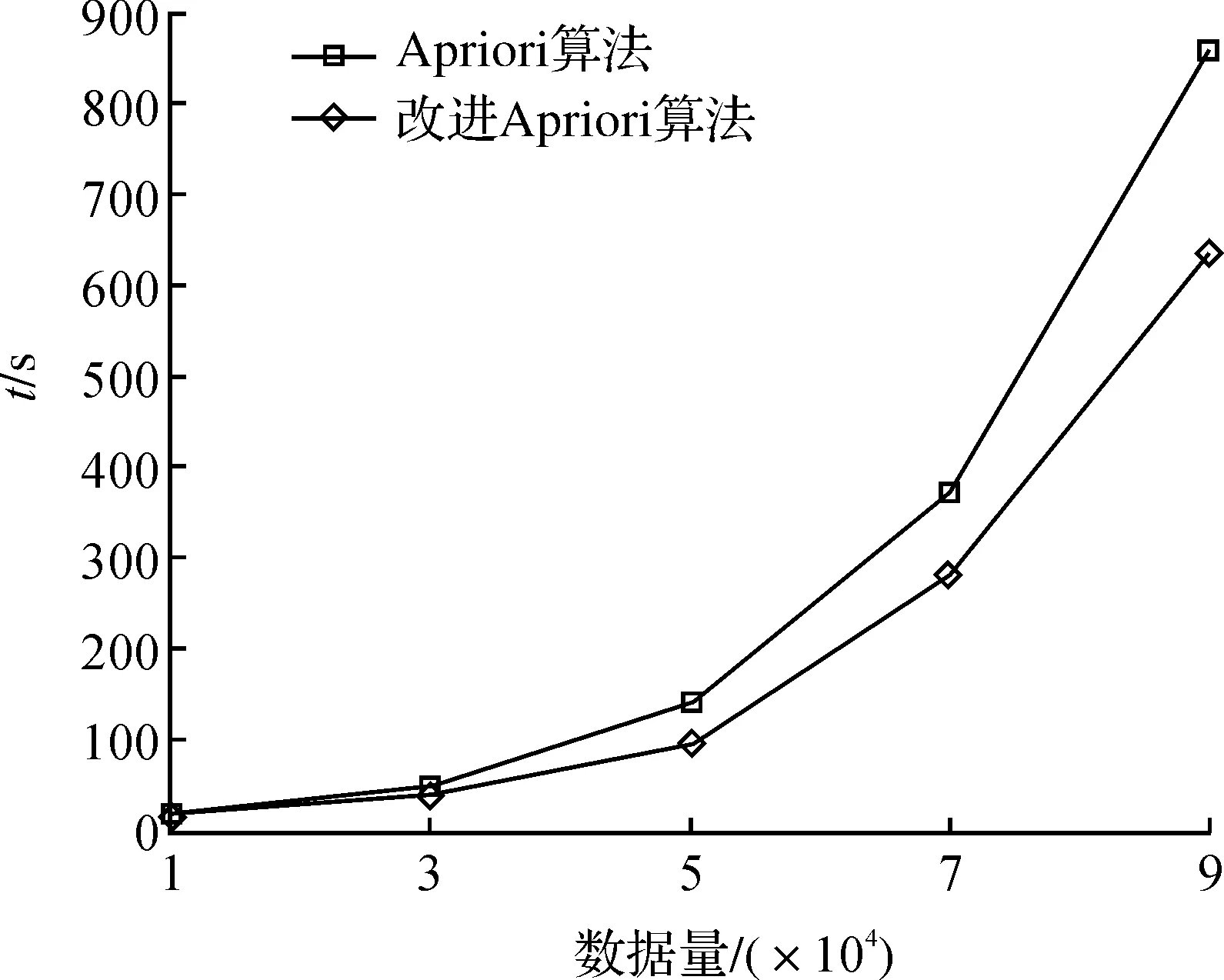
图1 耗费时间t和数据量之间的关系曲线Figure 1 Curve between time-consuming and the amount of data
针对不同的数据量,改进算法效率优于原算法.当随着数据量的增加,改进Apriori算法和Apriori算法的效率差距越来越大,一方面随着数据的增大,耗用时间差也增大;另一方面,数据量的增大,使得数据中的的属性值数量增多,出现同属性值连接的情况就更多,改进算法的优越性更加明显.
当将数据量的值设置为50 000时,Apriori算法和改进Apriori算法的挖掘效果进行比较,如表3和如图2.

表3 实验数据记录表
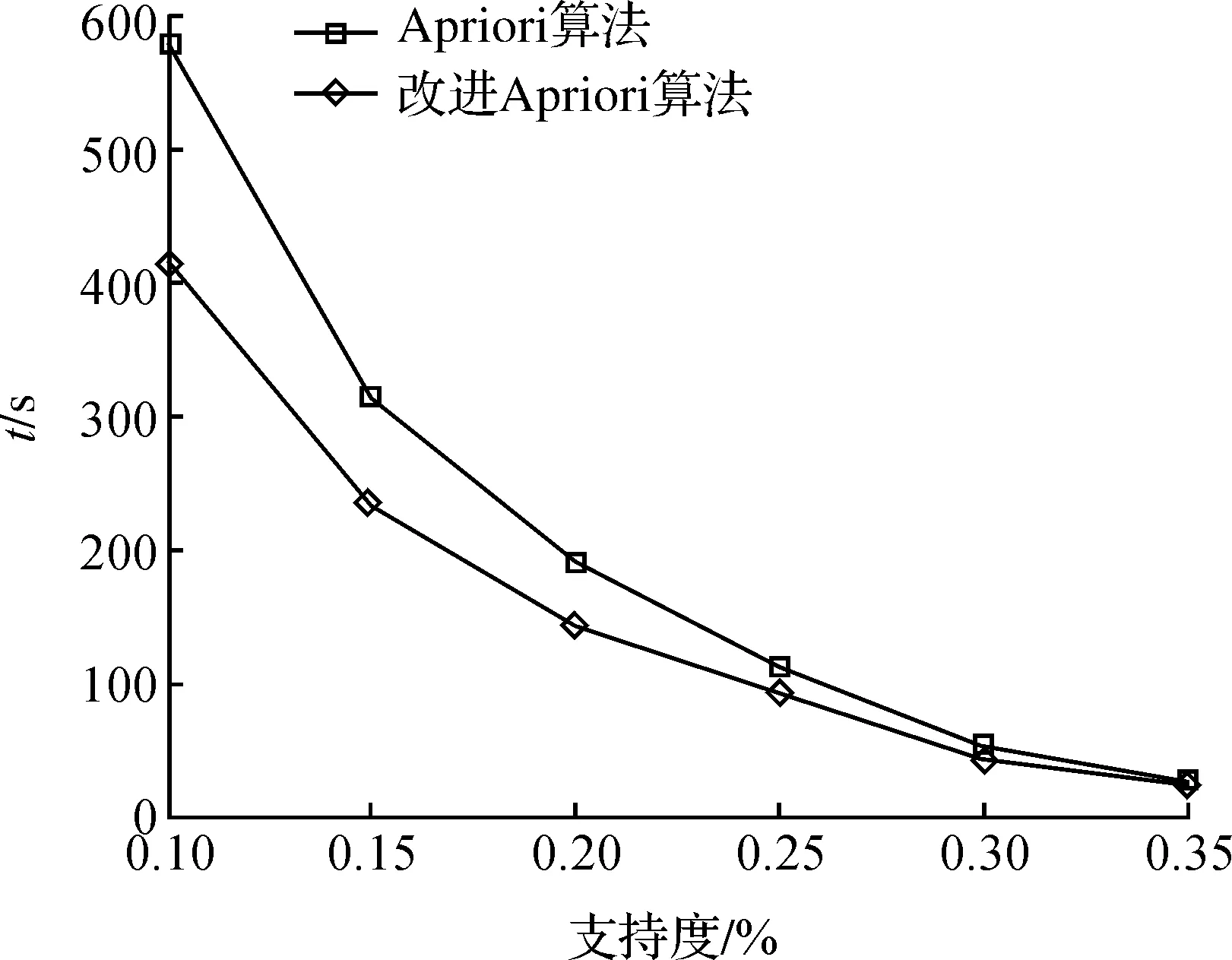
图2 耗费时间和支持度之间的关系曲线Figure 2 Curve between time-consuming and the support
针对于不同的支持度,改进算法的表现优于Apriori算法.随着支持度的减小,两种算法的差距也逐渐扩大,因为随着支持度减小,产生的候选项集就越多,出现同属性值连接的情况就会越多,改进算法效果就更明显.
5 结 论
本文提出了一种改进的Apriori算法,在关联规则连接步骤中,通过提前判断已经连接好的频繁项集中属性值的属性,并将即将要连接的属性值所在属性与之比较.如果即将连接的属性值已经存在于已经连接好的频繁项集中,则停止当前连接,就不再需要将新连接的候选项集与数据库中的原始数据进行比较,在属性值比较繁多的时候,能有效避免同种属性值发生重复连接,可以有效降低扫描数据库的次数,进而提高挖掘效率.通过实验,改进的Apriori与传统的Apriori算法比较后有一定的优势,效率提高了很多.但是同时,改进算法依然是基于Apriori算法,扫描数据库时依然有很大开销,对于这方面的改进工作,以后会继续进行.
[1] AGRAWAL R, IMIELINSKI T, SWAMI A. Mining association rules between sets of items in large databases[J].
ACM Sigmod Record,1993,22(2):207-216.
[2] SRIKAN R, AGRAWAL R. Mining quantitative association rules in large relational table[C]//Proceedings of the ACM Sigmod Conference on Management of Data. San Diego, California: ACM Press,1996:1-12.
[3] KAREL F. Quantitative and ordinal association rules mining (QAR Mining)[C]//10th International Conference on Knowledge-Based Intelligent Information and Engineering Systems, KES 2006. Berlin: Springer Verlag,2006:195-202.
[4] 李国雁,沈炯夏.一种基于矩阵的多值关联规则的挖掘算法[J].计算机工程与科学,2008,30(5):72-77. LI G Y, SHEN J X. A quantitative association rules mining algorithm based on matrix[J].Computer Engineering & Science,2008,30(5):72-77.
[5] NADERI DEHKORDI M, SHENASSA MH, BADIE K. Multi level exceptions mining in OLAP data cubes[C]//Computer and Communication Engineering 2008. Piscataway: Computer Society,2008:747-751.
[6] KUMAR ASWANI C. Mining association rules using non-negative matrix factorization and formal concept analysis[C]//5th International Conference on Information Processing, ICIP 2011. Berlin: Springer Verlag,2011:31-39.
[7] DIANA M, ALEJANDRO R, JESS A. A new multiobjective evolutionary algorithm for mining a reduced set of interesting positive and negative quantitative association rules[J].IEEE Transactions on Evolutionary Computation,2014,18(1):54-69.
[8] EIRINI S, DEBIE T, MARIO B. Interesting pattern mining in multi-relational data[C]//Data Mining and Knowledge Discovery. Netherlands: Springer Netherlands,2014:808-849.
[9] VAHID B, MOHAMAD M, AZURALIZA A. multi-objective PSO algorithm for mining numerical association rules without a priori discretization[J].Expert Systems with Applications,2014,41(9):4259-4273.
[10] STANISIC P, TOMOVIC S. Apriori multiple algorithm for mining association rules[J].Information Technology and Control,2008,37(4):311-320.
An improved Apriori algorithm based on multi-valued attributes
ZHAO Long, YANG Xiaobing, WU Qiang, GAO Yu
(College of Information Engineering,China Jiliang University, Hangzhou 310018, China)
As data mining becomes more and more complex, multi-dimensional association rules become one of the most useful in association rules mining. In this paper, a solution was proposed on the case of repeated connection of the same attribute data in the mining of multi-dimensional association rules. By comparing multi-valued attribute information, the algorithm removed the attribute information of duplicate connection, retained the effective information, and reduced scanning of the database. The algorithm improved the connection steps of the Apriori algorithm and obtained the data information and results by using the Boolean association rules. Compared to the Apriori algorithm, the improved algorithm is more quick and accurate to discover knowledge and shorten the time of mining.
multi-dimensional association rule; multi-valued attribute; Apriori algorithm; Boolean association rule
2096-2835(2017)01-0108-05
10.3969/j.issn.2096-2835.2017.01.019
2016-12-01 《中国计量大学学报》网址:zgjl.cbpt.cnki.net
赵 龙(1991- ),男,安徽省淮北人,硕士研究生,主要研究方向为数据挖掘.E-mail:745198363@qq.com 通信联系人:杨小兵,男,副教授.E-mail:xyang@cjlu.edu.cn
TP391
A
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
现代信息科技(2019年20期)2019-10-21
科技资讯(2019年18期)2019-09-17
中国科技纵横(2019年15期)2019-08-27
教育界·下旬(2019年1期)2019-04-26
计算机与数字工程(2018年10期)2018-10-23
计算机与数字工程(2017年2期)2017-03-02
