
基于文本挖掘的电子商务市场表现研究
2017-05-09 17:46陈皓琰
科学中国人 2017年12期
陈皓琰
四川城市轨道交通职业学院筹备中心
基于文本挖掘的电子商务市场表现研究
陈皓琰
四川城市轨道交通职业学院筹备中心
大数据转变成可视化数据依靠的是计算机领域中的文本挖掘技术。文本挖掘中最重要且最基本的应用是实现文本的分类和聚类,前者是有监督的挖掘算法,后者是无监督的挖掘算法。本文重点讲述如何利用文本挖掘技术对当前的电子商务市场表现进行研究。
文本挖掘;电子商务;数据分析;爬虫
1 引言
文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘中的一种方法。数据挖掘[1]也称知识发现(KDD),是从数据库中便捷地抽取出未知的、隐含的、有用的信息。
本文的研究背景是基于大数据下进行的,而对电子商务市场表现进行研究,采用的技术是本文挖掘技术。文本挖掘技术是一项非常重要的挖掘和展示数据结论的技术。通过本文的研究,希望能对电子商务的市场表现有一个更加清晰的认识。
2 文本挖掘流程
数据挖掘中的文本挖掘与我们的生活息息相关,比如,搜索引擎上的新闻热点推送,虽然少不了编辑人员的工作,但是在繁杂网络信息中,脱离电脑仅靠人工是几乎不可能完成的。最近一款流行的APP,<<头条>>,它其实也是文本挖掘技术应用的一种展现。本文挖掘的一般流程如图2-1所示:
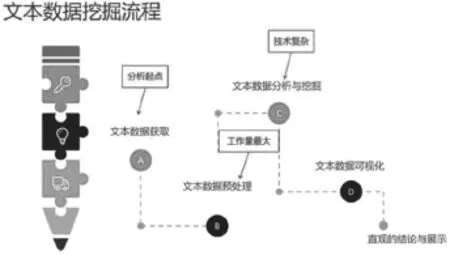
图2 -1文本挖掘一般流程
2.1 文本获取
一般情况下,我们通过网页的形式,获取网络文本,再将得到的文本建成文本数据库(数据集)。在这个过程中,可利用爬虫程序来爬取网络中的信息。爬取的策略有广度和深度爬取,根据用户的需求,爬虫也可分为主题爬虫和通用爬虫。主题爬虫主要是在相关站点进行爬取或者爬取特定主题的文本,而通用爬虫则一般对此不加限制,所以得到的文本量和内容更多。现在网络上已经存在很多开源的爬虫程序,也可根据获取对象的情况自行编写。
2.2 文本预处理
通过执行爬虫程序,我们获取了大量的原始数据和相关资料,但网页中存在很多我们不感兴趣的信息,比如广告、导航栏、html、js代码、注释等等。所以,我们还需要对文本中的信息进行筛选。这个步骤相当于做饭中洗菜的过程,没有清洗过的食材,厨艺再好的人,我想也很难做出佳肴吧。
2.3 分词系统
我们知道,文本中起到关键作用的是往往是一些关键词,这些关键词决定了文本取向。比如说一篇文章介绍的是体育相关的内容,我们只需要对文章中的关键词进行分析就能得到想要的结果了。那么怎样才能找到那些能够影响主题的词语呢?
在找出关键词之前,要先获取文本中所有的词语。这个步骤需要用到一个分词系统或者分词工具。现在针对中文分词,出现了很多算法,有最大匹配法、最优匹配法、机械匹配法、逆向匹配法、双向匹配法等等。这里推荐使用中科院的分词工具ICTCLAS[2],该工具是以北京大学计算机语言学研究所加工的《人民日报》语料库为训练语库,基于层叠隐马尔可夫模型的汉语分词方法,是一个基于统计方法的、集成的一体化汉语词法分析解决方案。
2.4 特征选择
通过分词工具的辅助,我们已经把所有的词进行了分类。但是这些词中,并不都是所需要的,比如语气词、形容词、标点符号。这些词和字符在文中都大量存在,与文本关键词无太大关系,所以可以删除。
经过处理,我们能够得到一个文本集。有的词会在这个文本集中大量出现,有的只出现几次而已。出现频率低的词通常不能决定文章的主题,而且文本集中内容越大,维度会越高,矩阵稀疏度随之成比,严重影响到挖掘结果。国内外许多学者已经在关键词抽取领域中做了大量研究工作,简立峰[3]使用PAT树结构,利用词与词的联系来对中文关键词进行搜索,但是PAT树模型的成本太大,本文引用权重计算方法TF-IDF(term frequency-inverse document frequency),该模型的主要思想是[4]:关键词在文档中权重为关键词在文档中出现的频数反比于包含该特征词的文档书目。TF表示关键词m在文档D中出现的频率,IDF表示所有文档中出现关键词m的文档数目。
3 文本挖掘在电子商务市场表现研究方面的应用
文本挖掘技术可以应用到各个领域当中,电子商务领域尤为广泛。做过电商应用的朋友就会发现,在工作过程中,业务的需求基本来源于数据,这些数据主要靠文本挖掘来获取。比如唯品会,其网站上商品的价格及展现形式都不是随意设定的。唯品会的大数据部门,无时无刻不在运行着爬虫程序,然后进行数据分析,寻找自己想要的商务数据。
3.1 数据爬虫
本文中使用了Python开发的PyRailgun,它是一个简洁、轻量、高效的网页抓取框架。本人在其开源代码的基础上,加入了研究所需要的成分,然后设定好需要爬虫的关键词:电子商务、网购、商务公司、网购评价、商品评价、商品质量、公司融资、融资金额。这八个关键词是程序重点爬虫的对象,爬虫程序执行以后会将与其相关的数据保存下来。本次爬虫程序不做深度爬虫处理,以三级爬虫为最多爬虫层数,数据量以10万条为准,多于10万条以上的数据,不再存储,避免数据量过大,处理周期冗长。
3.2 数据预处理
在数据预处理阶段,本人设定了一些文本规则,将不相关的文本数据清除,只保留和预期目标相关的数据。数据预处理的规则如下:
(1)去除含广告类的数据,这部分数据与研究目标无直接联系且数量巨大。
(2)数据分类:将与本文目标一致的数据划分为一类。使用聚类分析算法,将其划分为三类数据:电子商务公司名称数据、网购评价数据、公司融资数据。
(3)数据精简去重,一个主题相关词只保留一条。
3.3 数据细分
经过数据预处理后,三种目标数据的纯净度大幅度提升。因为本文主要研究的是数据反应出的趋势,所以要对数据再进行细分,规则如下:
(1)电子商务公司名称数据
以公司名称为重点关键词,通过聚类分析算法进行数据分类。
(2)网购评价数据
数据相对零碎,比较难处理。本次实验数据以天为单位,分好评与差评。
(3)公司融资数据
数据也是以公司名称为重点关键词:通过聚类分析算法,将各公司的融资数据情况划分为一类,便于下一步的数据分析中挖掘重点融资情况。
3.4 数据分析
把分类好的数据进行汇总,即可得到所需的数据报表。
(1)电子商务公司名称数据
汇总与电子商务有关的公司个数。
(2)网购评价数据
汇总好评和差评的频次。
(3)公司融资数据
把各公司的每一轮融资结果,汇总成报表。
3.5 研究结论
(1)我国的电子商务公司一直处于增长的趋势,由于文本程序每个季度执行一次,数据量偏少,因此得到的结论是:从2015年10月份到2017年2月份期间,2016年4月份的新增公司数量最多。
(2)客户对网购评价好坏的趋势。客户对网购评价情况,在2015年10月份,网购给予差评的比例较大,基本占到了43%左右,但是随着时间的推移,网购差评的比例越来越少,到了2017年1月份,已减少到了18%左右。说明客户网购体验的发展趋势越来越好。
(3)电子商务创业型公司融资情况趋势。在实验范围内,2016年4月的融资情况和融资数量最佳。
4 结束语
通过使用文本挖掘技术对电子商务市场表现展开应用,主要对一定时间内新增公司的数量趋势、客户对网购评价好坏的趋势、电子商务创业型公司融资情况三个方面进行分析。
因为本次实验的样本有限,tf-idf方法也有不足之处[5],所以结论仅提供参考,期望有更好的云服务技术,对更多的数据进行专业级文本挖掘,进行更深层次的分析。
[1]JiaweiHan,Micheline Kamber.范明,孟小峰,等译.数据挖掘概念与技术[M].北京:机械工业出版社,2001.
[2]刘群.汉英机器翻译若干关键技术探究[M].北京:清华大学出版社,2008.
[3]Chien Lee Feng,PAT-tree-based Keyword extraction for Chinese information retrieval[C].Proceedings of the ACM SIGR InternationalConference on Information Retrieval,1997:50-59.
[4]Aizawa A.An Information-theoretic Perspective of tf-idfMeasures[J].Information Processingand Management,2003,39(1):45-65.
[5]徐建民,王金花,马尾瑜.利用本体关联度改进的TF-IDF特征词提取方法[J].情报科学,2011,29(2):279-283.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
保健医苑(2022年5期)2022-06-10
现代信息科技(2021年21期)2021-05-07
校园英语·月末(2021年13期)2021-03-15
作文大王·低年级(2020年2期)2020-03-13
数学大王·低年级(2020年2期)2020-03-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
商周刊(2018年23期)2018-11-26
智能计算机与应用(2018年5期)2018-10-20
