
领域文本信息抽取中的短语相似度计算方法
2017-06-20 23:44沈洁彭敦陆
软件导刊 2017年4期
沈洁+彭敦陆


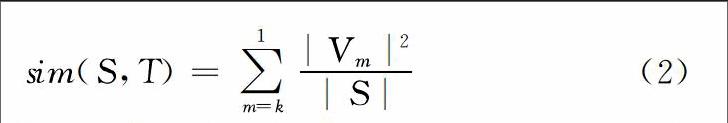
摘要:随着信息化的深入发展,各应用领域积累了大量采用半结构化方式记录的文本数据。为了快速有效地从大规模面向领域的半结构化文本中抽取有用信息,信息抽取技术应运而生。文本信息抽取的核心算法之一是计算词或短语的相似度,针对面向领域的半结构化文本中的中文短语相似度计算,先采用模式匹配算法从原始半结构化文本中抽取中文短语,然后结合领域语义依存关系,对基于公共子串的短语相似度计算方法进行改进,以此提高短语相似度计算的可靠性。实验结果表明,所提算法具有较好的计算效果。关键词:领域半结构化文本;公共子串;依存关系(DOI)DOI:10.11907/rjdk.162708中图分类号:TP301文献标识码:A(文章编号)文章编号:16727800(2017)0040006030 引言 在信息爆炸的今天,各大领域都产生了大规模的半结构化文本。在医疗领域,产生了大量的电子病历文本[1];在司法领域,产生了大量的审判案件法律文书。对领域文本进行高效地信息抽取,是实现文本数据结构化和领域数据分析的基础,而短语相似度计算又是进行正确信息抽取的前提。 通常,由于缺乏背景知识,直接从面向领域的半结构文本中抽取的短语不够准确,难以与领域知识相对应。一种可能的方法是从领域知识库中查找与抽取短语相似的短语来提高信息抽取的准确性。由此,需要高效地计算从文本中抽取出的短语与领域知识库中的短语相似度。迄今为止,短语相似度的计算已应用于诸多方面,例如文本聚类[2]、文本检索[3]和机器翻译[4]等。 在司法领域,为了对大量案件进行有效的数据分析,首先需要对审判案件的法律文书进行信息抽取,形成结构化数据。在针对法律文书(如判决书)抽取的大量数据项中,有一类数据项是由一组连续词语组成的短语,例如,针对“案由”这个数据项,在判决书中可能会抽取到“贩卖毒品罪”,而这一短语在面向司法领域的知识库(取自我国《刑法》)中的对应短语是“走私、贩卖、运输、制造毒品罪”,两者之间不完全相同,但相比其它短语则更加相似。研发出高效计算文本中抽取出的短语与领域知识库中短语的相似度计算方法,有助于提高领域信息抽取的准确度和抽取效率。1 准备工作1.1 面向领域的中文短语抽取〖ST〗〖WT〗 与领域相关的中文短语抽取是面向领域的半结构化文本信息抽取的重要任务之一。抽取出的短语以结构化的形式进行存储,为后期的数据分析服务。在短语抽取中,先使用基于模式匹配的结构化信息抽取方法[5],从面向领域的半结构化文本中抽取中文短语。 下面以实现来说明该算法的执行过程。例如,对短语“指控被告人王某犯贩卖毒品罪一案”,首先进行分词,然后选取案件案由的抽取模式(见图1)对分词序列进行模式匹配得到目标短语。其中,keyword、itemword、objphrase分别表示关键词、普通词和目标短语。通过增加关键词同义词的方式对案件案由的抽取模式进行优化,这样该算法就可以克服传统模式的不足,准确地匹配包括同义词在内的短语表达。< pattern keyword ="指控" pos ="v" >< keyword-synonym >< synonym name ="控告" pos ="v" / >< / keyword-synonym >< Cluster id ="1" >< patternStr >< pattern id ="1" value =" \\s keyword/v 被告人/n itemword/nr 犯/v objphrase/n 一/m 案/ng \\b" >< / patternStr >< / Cluster >< / pattern >1.2 构建领域知识库 法律文书由司法相关工作人员人工进行书写,书写过程中会出现书写不规范的情况。例如使用上节阐述的算法从法律文书中抽取的案件案由为“贩卖毒品罪”,而这一短语在面向司法领域的知识库(取自我国《刑法》)中的对应短语是“走私、贩卖、运输、制造毒品罪”。所以需要构建领域知识库,从知识库中选取与抽取短语相似程度最高的短语作为最后的使用短语,这样可以使抽取结果更加专业化。 本文采用主成分分析算法过滤法律文书中的噪声信息,然后通过深度学习算法抽取领域特征词和领域特征短语,构建领域知识库。司法领域的审判案件法律文书中有很多法律方面的知识,例如,审判案件类型、案件案由、结案方式等,其中案由又分为刑事案件案由、民事案件案由和行政案件案由,刑事案件案由如表1所示。3类案件在知识库中共1 470条具体的案由数据。领域知识库中的专业知识蕴含了该领域宝贵的信息,对于提高信息抽取的准确性和有效性有巨大帮助。2 短语相似度应用实验 2.1 基于公共子串的短语相似度计算 基于编辑距离的短语相似度计算方法,沒有考虑字符与字符之间的连续性。例如“贩卖毒品罪”通过编辑距离计算得到的相似短语是“非法买卖制毒物品罪”,而实际上“贩卖毒品罪”相似的司法领域短语是“走私、贩卖、运输、制造毒品罪”。短语“贩卖毒品罪”与短语“非法买卖制毒物品罪”相同的字符为“卖”、“毒”、“品罪”,而短语“贩卖毒品罪”与短语“走私、贩卖、运输、制造毒品罪”相同的字符为“贩卖”、“毒品罪”,由此可以看出短语与短语的相同字符越连续,越具有语义含义。为了解决相同字符不连续导致相似短语选取错误的情况,本文提出基于公共子串的短语相似度计算方法(Common Substring,CS)。 定义1 子串:字符串S中任意个数的连续字符所组成的子序列称为该字符串的子串。 定义2 公共子串:如果字符串C既是字符串S的子串又是字符串T的子串,则字符串C是字符串S和字符串T的一个公共子串。 定义3 最长公共子串:指字符串S和T的公共子串中长度最长的一个公共子串D。 动态规划算法是解决最长公共子串[6]问题的经典算法,通过式(1)可以计算出原始短语和目标短语的最长公共子串,进而可以得到不包含重复字符的公共子串(包含空字符串)。原始短语S和目标短语T的公共子串(不包含重复字符)个数为k,公共子串集合按长度从大到小排序,可以通过式(2)计算基于公共子串的短语相似度。其中,|Vm|表示公共子串的字符个数,|S|表示原始短语的字符个数。 通过基于公共子串的短语相似度计算方法给连续的字符赋予更高的权重,可以解决通过编辑距离计算短语相似度时,字符不连续情况导致的相似短语选取错误的情况,从而提高算法的准确度。2.2 结合领域语义依存关系的短语相似度计算 在上节提出的短语相似度计算方法考虑了连续字符的重要性,通过赋予连续字符更高的权重增加了连续字符的重要程度,但是没有考虑短语中词语与词语之间的依存关系(Dependency Relationship,DR)。例如短语“制造、贩卖毒品罪”中包含动宾关系,强调的是宾语“毒品”,而上节中提出的算法给连续字符“制造贩卖”赋予了更高的权重,而忽略了宾语“毒品”的重要性。通过分析司法领域知识库中的短语,可以发现知识库中的短语都是名词性短语,主要包括3种关系:主谓关系、动宾关系和定中关系。在司法领域,对于主谓关系,主语依存于谓语动词,多数在语义上强调的是主语;对于动宾关系,宾语依存于动词,强调的是宾语;对于定中关系,定语依存于中心词(名词),强调的是定语。通过分析领域短语中词语与词语之间的语义依存关系,可以发现短语的主语、宾语和定语是短语的语义重心,应该给语义重心赋予更高的权重,更好地体现领域的特征。 在计算短语相似度时,考虑短语语义重心可以使选取相似短语的结果更加准确,在此提出结合领域语义依存关系的公共子串短语相似度计算方法(DR-CS)。为了找到短语的语义重心,需要对短语进行依存句法分析。本文通过语言技术平台(LTP)[7]得到短语中的主谓关系、动宾关系和定中关系,进而得到句子的主语、宾语和定语。如图1所示,SBV表示主谓关系,VOB表示动宾关系,ATT表示定中关系。对目标短语中的主语、宾语和定语分别赋予权重,并结合上节中提出的算法计算短语相似度,可以体现短语的语义重心,提高短语相似度计算的准确度。主语、宾语和定语的权重如式(3)所示,其中WG分别表示主语、宾语和定语的权重之和,λ1、λ2、λ3表示权重的系数,需要通过实验进行调整,|Gsub|、|Gobj|、|Gatt|分别表示主语、宾语和定语的字符个数。将主语、宾语和定语的权重与基于公共子串的短语相似度计算方法相结合得到式(4)。 结合领域语义依存关系的公共子串短语相似度计算方法不仅考虑了字符与字符之间的连续性,还考虑了领域依存关系,增加了领域词语的重要程度,体现了短语的语义重心,提高了相似短语查找的准确性和有效性。2.3 实验方法实验数据来自江苏省全省人民法院在2014年1月-2014年12月公开审判案件的裁判文书 ,包括4 000篇刑事案件裁判文书、4 000篇民事案件裁判文书和4 000篇行政案件裁判文书,总共12 000篇文档。 实验采用对比的方法,验证本文提出算法的准确性和有效性。结合司法领域知识库中的刑事、民事和行政案件案由,计算抽取短语与案件案由列表中短语的相似度。将结合领域语义依存关系的公共子串短语相似度计算结果与基于编辑距离的短语相似度计算方法和基于公共子串的短语相似度计算方法的计算结果进行对比,验证结合领域语义依存关系的短语相似度计算方法的有效性。〖JP+2〗表2展示了3种方法的短语相似度计算结果。原始短语就是抽取短语,目标短语是知识库中的短语。第3、4、5列分别表示基于编辑距离的短语相似度计算方法、基于公共子串的短语相似度计算方法和结合领域语义依存关系的公共子串短语相似度计算方法的计算结果。对于基于编辑距离的短语相似度计算方法,选取编辑距离最小的目标短语作为原始短语的相似短语,而对于基于公共子串的短语相似度计算方法和结合领域语义依存关系的短语相似度计算方法,应该选取相似度值最大的目标短语作为原始短语的相似短语。从表2可以看出,结合领域语义依存关系的短语相似度计算方法具有更好的区分度。2.4 实验结果与分析 本文对12 000篇审判案件裁判文书的案件案由进行了人工标注,通过对比3种算法的结果和人工标注的结果来验证算法的准确性和有效性。 实验过程中,对权重系数进行调整,当λ1=0.8,λ2=0.6,λ3=0.3时,结合领域语义依存关系的短语相似度计算方法得到较好结果。实验使用准确率来评估算法在不同规模下的准确性和有效性。通过对比结合领域语义依存关系的短语相似度计算方法与基于编辑距离的短语相似度计算方法和基于公共子串的短语相似度计算方法的计算结果,可以验证结合领域语义依存关系的短语相似度计算方法具有更好的效果。从实验结果(见图1)可知,横坐标表示实验所用数据集的大小,纵坐标表示ED、CS和DR-CS算法在相应数据集上准确率的大小。另外,从图中还可以看到,在不同规模的数据集下,结合领域语义依存关系的公共子串短语相似度计算方法的准确性比其它两种算法的准确性要高,准确率维持在90%左右。3 结语随着互联网的发展,电子化办公方式越来越普及,各领域都产生了大量文本数据,如何从大规模面向领域的半结构化文本中挖掘有价值的信息是研究者所关注的。有效地信息抽取对后期的数据挖掘和分析效果会生产较大影响。本文从面向领域的半结构化文本出发,先采用模式匹配算法抽取的中文短语,运用结合领域语义依存关系的公共子串短语相似度计算方法计算抽取短语与领域知识库中短语的相似度,查找出领域知识库中与抽取短语最相似的短语作为结果保存到结果数据中,保证了抽取的信息更加符合领域实际情况。实验结果展示了所提算法具有较好的计算效果。如何在分布式环境下对大规模面向领域的文本信息抽取技术及文本数据挖掘算法进行探索,则是下一步研究的重点。endprint
参考文献:[1]KREUZTHALER M,SCHULZ S,BERGHOLD A.Secondary use of electronic health records for building cohort studies through topdown information extraction[J].Journal of biomedical informatics,2015(53):188195.
[2][CHO Y H,PARK S H,LEE S K.Phraserank for document clustering:reweighting the weight of phrase[C].Proceedings of the 2nd International Conference on Interaction Sciences:Information Technology,Culture and Human,2009:168174.
[3][PASCA M. Asking what no one has asked before:using phrase similarities to generate synthetic web search queries\[C].Proceedings of the 20th ACM International Conference on Information and Knowledge Management,2011: 13471352.
[4][ZENS R,OCH F J,NEY H.Phrasebased statistical machine translation[C].Annual Conference on Artificial Intelligence.Springer Berlin Heidelberg,2002:1832.
[5][邵堃,楊春磊,钱立宾,等.基于模式匹配的结构化信息抽取[J].模式识别与人工智能,2014,27(8):758768.
[6][DEOROWICZ S,GRABOWSKI S.Efficient algorithms for the longest common subsequence in klength substrings\[J]. Information Processing Letters,2014,114(11):634638.[7][W CHE,Z LI,T LIU.Ltp:a Chinese language technology platform[C].Beijing:in Coling 2010:Demonstrations,2010:1316.(责任编辑:孙娟)
猜你喜欢
内蒙古社会科学(汉文版)(2021年3期)2021-06-07
红河学院学报(2020年3期)2020-01-19
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
制造技术与机床(2019年6期)2019-06-25
少儿美术(快乐历史地理)(2018年7期)2018-11-16
商情(2018年9期)2018-03-29
中国交通信息化(2016年9期)2016-06-06
人间(2015年33期)2015-12-08
图书馆研究(2015年5期)2015-12-07
