
基于Transfer和Triangulation融合的中介语统计机器翻译方法
2017-10-11 07:09朱靖波
中文信息学报 2017年4期
王 强,杜 权,肖 桐,朱靖波
(东北大学 自然语言处理实验室,辽宁 沈阳 110819)
基于Transfer和Triangulation融合的中介语统计机器翻译方法
王 强,杜 权,肖 桐,朱靖波
(东北大学 自然语言处理实验室,辽宁 沈阳 110819)
为了解决在构建统计机器翻译系统过程中所面临的双语平行数据缺乏的问题,该文提出了一种新的基于中介语的翻译方法,称为Transfer-Triangulation方法。该方法可以在基于中介语的翻译过程中,结合传统的Transfer方法和Triangulation方法的优点,利用解码中介语短语的方法改进短语表。该文方法是在使用英语作为中介语的德-汉翻译任务中进行评价的。实验结果表明,相比于传统的基于中介语方法的基线系统,该方法显著提高了翻译性能。
统计机器翻译; 基于中介语的统计机器翻译;中介语;质量控制因子
Abstract: This paper presents a transfer-triangulation method for pivot-based translation between two languages with poor bilingual data. It takes the best of both typical transfer method and triangulation method for pivot-based translation, and decodes pivot phrases to improve phrase table. Evaluated on German-Chinese translation task with English as the pivot language, results show that our method achieves significant improvement over baseline pivot-based methods.
Key words: statistical machine translation; pivot-based statistical machine translation; pivot language; quality control factor
收稿日期: 2015-08-26 定稿日期: 2016-03-25
基金项目: 国家自然科学基金青年基金(61300097);国家自然科学基金(61272376);国家自然科学基金(61432013)
1 引言
构建性能优异的统计机器翻译系统通常需要数百万乃至更多的双语平行数据进行训练。然而在实际应用时,除少量数据资源丰富的语言对外(如英汉、英阿),大多数语言对往往面临双语平行数据资源缺乏的问题(如德汉)。
为此,研究人员提出了基于中介语的统计机器翻译方法,其核心思想是: 通过与源语和目标语均存在大规模平行语料的第三方语言,间接地满足源语-目标语的平行数据的要求。两个典型的基于中介语的统计机器翻译方法分别为Transfer方法[1]和Triangulation[2-3]方法。Transfer方法是句子级的中介语方法,核心思想是先将源语句子翻译为中介语句子,再将中介语句子翻译为目标语句子。其缺点是翻译过程需要解码两次,不但更耗时,而且存在翻译错误蔓延的问题。而Triangulation方法是短语级的中介语方法,核心思想是分别训练源语-中介语短语翻译表Ts-p、中介语—目标语的短语翻译表Tp-t,再利用相同的中介语短语进行短语表融合,构建出源语-目标语的短语表Ts-t。Triangulation方法能够利用推导出的源语-目标语短语表直接进行翻译,避免了Transfer方法的两次解码的不足,并且其处理对象是短语,相比于句子有更大的灵活性,成为了目前中介语统计机器翻译的研究热点。然而,在Triangulation方法中,只考虑了在Ts-p和Tp-t中共现的中介语短语,忽略了非共现的中介语短语(本文称这种类型的中介语短语为中介语断点)。这将导致产生大量的互译性不高的噪声翻译规则,干扰解码器的译文选择过程,并且还存在源语短语丢失的问题。
针对上述问题,本文提出一种基于Transfer和Triangulation融合的中介语方法,其核心思想是利用短语级而不是句子级的Transfer方法,将原本被忽略的中介语断点翻译成目标语,形成中介语-目标语的翻译规则,从而将中介语断点转化成非断点。本文提出的方法能够利用传统Triangulation方法中忽略的中介语断点信息改善推导出的短语表,从而提高整体翻译性能。在以英文作为中介语的德-汉翻译任务中,本文的方法相比于传统的Transfer方法和Triangulation方法,BLEU-4分别提高4.74和0.84。
2 基于中介语的统计机器翻译
2.1 Transfer方法 Transfer方法是一种句子级的中介语方法。首先分别利用源语—中介语、中介语—目标语双语平行数据训练出源语—中介语翻译系统Ss-p以及中介语—目标语的翻译系统Sp-t。给定源语句子s,当进行源语—目标语的翻译任务时,利用Ss-p先将s翻译成m(m≥1)个中介语结果,记作p1,p2,…,pm,再通过Sp-t将每一个中介语结果pi(1≤i≤m)翻译为n(n≥1)个目标语译文,记作ti1,ti2,…,tin,共产生m×n个翻译结果,最后从中选择1best作为最终的翻译结果。由于Transfer方法中需要解码两次(s→p和p→t),所以整体的解码时间更长,更关键的是,连续的解码将造成翻译错误的蔓延。
2.2 Triangulation方法
Triangulation方法是短语级的中介语方法。首先分别训练源语—中介语短语翻译表Ts-p、中介语—目标语的短语翻译表Tp-t,再利用相同的中介语短语进行短语表融合,构建出源语—目标语的短语表Ts-t,该过程如图1所示。在德—英短语表中,存在翻译规则“drastisch zurückgegangen→fallen dramatically”,同时在英-汉短语表中,存在翻译规则“fallen dramatically→急剧下降”,通过共现的英文短语“fallen dramatically”,能够推导出德—汉翻译规则“drastisch zurückgegangen→急剧下降”。同理,还可以推导出“drastisch zurückgegangen→戏剧性地衰退”、“drastisch zurückgegangen→已经大幅下滑”。
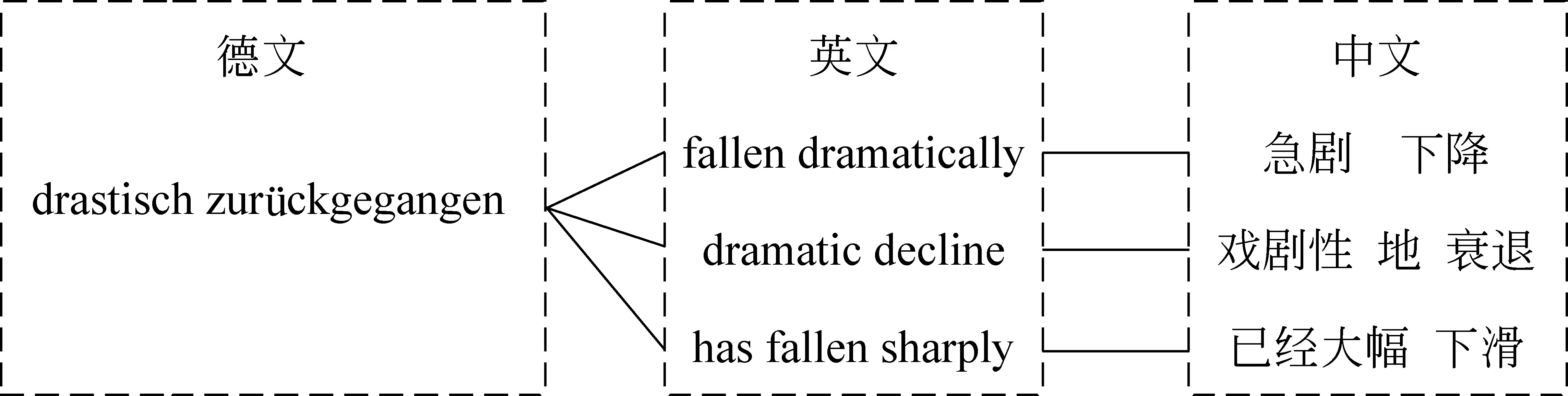
图1 使用Triangulation方法进行源语—目标语翻译规则推导
Triangulation方法中最关键的问题是: 如何给推导出的短语翻译规则进行特征打分,主要包括双向的短语翻译概率、双向的词汇化权重。给定源语短语s,目标语短语t,则在Triangulation方法中[2],使用式(1)对基于中介语的短语翻译概率∅进行建模。

(1)
使用式(2)对基于中介语的源语—目标语的词对齐推导。
(2)
其中,As-p、Ap-t、As-t分别表示源语-中介语、中介语—目标语、源语—目标语之间的词对齐信息。使用式(3)计算词汇化权重[4]。
(3)
其中,

(4)
在基于中介语的统计机器翻译中,可以使用式(5)[2]对源语词汇和目标语词汇共现次数进行建模。
(5)
其中,K表示被推导出的规则总数;当x=y时,δ(x,y)=1,否则δ(x,y)=0。
使用上述的公式对推导出的短语规则进行特征打分后,便得到了完整的源语-目标语的短语翻译表。然后按照标准的基于短语的统计机器翻译方法,直接进行源语到目标语的翻译。
虽然Triangulation方法能够直接把源语翻译为目标语,避免了Transfer方法中多次解码造成的翻译错误蔓延问题。但是,该方法也面临其他的问题:
(1) 产生互异性不高的噪声翻译规则。如图2(a)所示,源语短语s翻译为中介语p1的概率为0.9,表示为∅(p1|s)=0.9,同时∅(p2|s)=0.1。在应用Triangulation方法时,由于高翻译概率的p1无法翻译为任何目标语短语,则s只能通过低翻译概率的p2推导,从而形成互译性不高的翻译规则s→t2,而这些噪声翻译规则将干扰解码器的译文选择过程。
(2) 源语短语丢失。如图2(b)所示,源语短语s对应的全部中介语短语p1和p2都无法翻译成任何目标语短语,导致s无法推导出目标语翻译规则,所以在应用Triangulation方法时,s将在被构建的源语-目标语短语表中丢失。
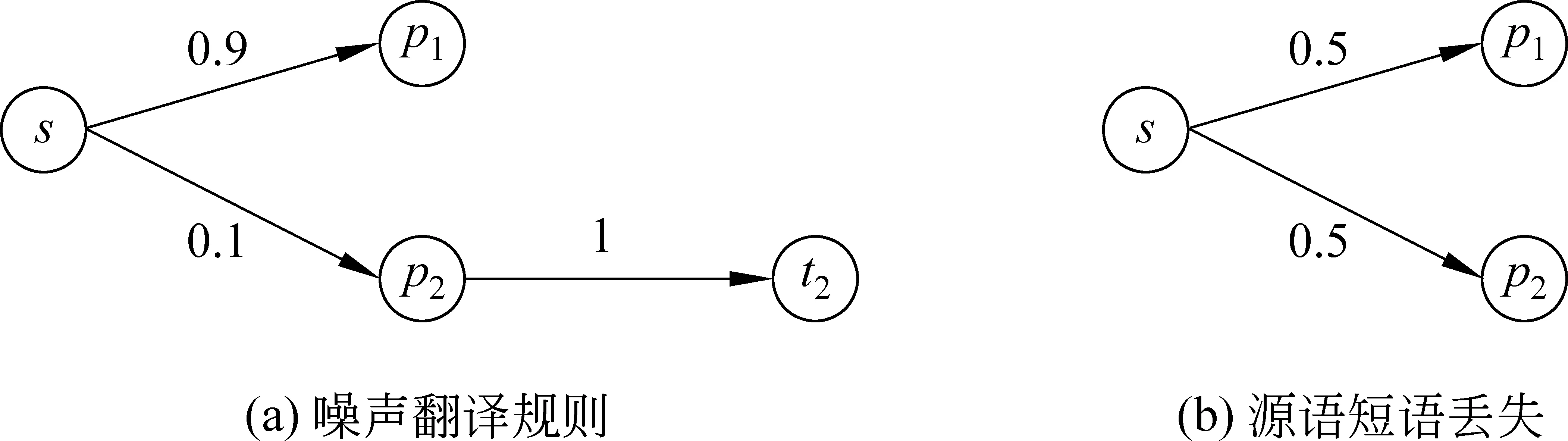
图2 传统Triangulation方法存在的问题(直线上的数值表示短语翻译概率)
本文定义图2(a)中的p1,以及图2(b)中的p1和p2为中介语断点,称这种现象为中介语断路。以上两个问题产生的主要原因都是由于中介语断路,所以本文的出发点就是通过解码中介语断点的方式将其转化成非断点,利用更多的中介语信息改善短语翻译表质量。
3 Transfer-Triangulation方法
3.1 中介语断点 对于任意源语短语s,本文定义满足下列条件的中介语短语为中介语断点条件:


在本文实验数据中,我们发现约75%的中介语短语是断点。这说明大量的中介语短语无法在Triangulation方法中用来推导源语-目标语短语规则,造成可用规则的丢失,同时影响已推导出的翻译规则的概率估计。而出现中介语断路的原因是由于源语到中介语的双语训练语料和中介语到目标语的双语训练语料中,不可避免地存在如领域、语言习惯、表达方式等各种差异,最终反映到训练得到的短语翻译表中。所以,可以说中介语断路现象难以避免,而且会随着语料的相关性差异增大而越来越严重,而中介语断路现象本身也将影响Triangulation方法的性能。
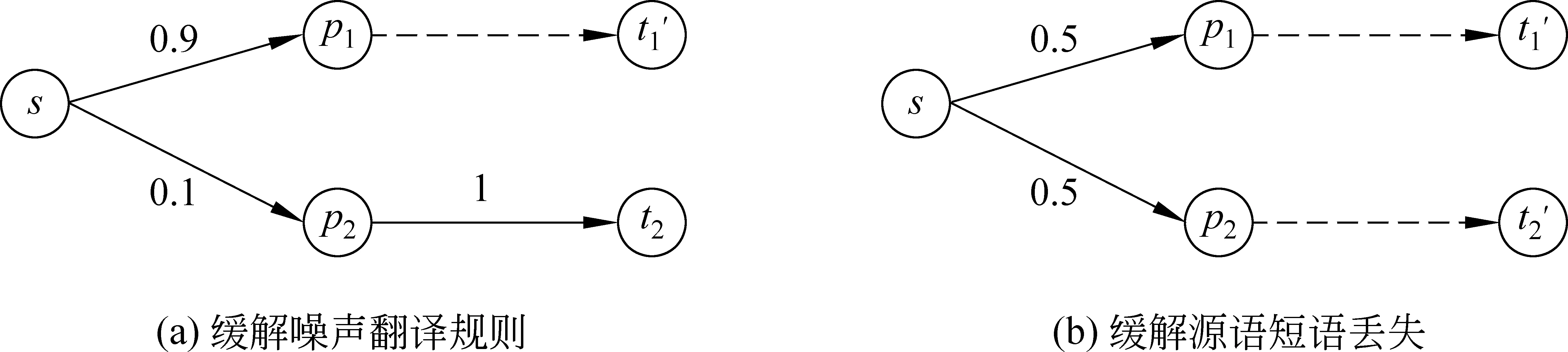
图3 利用解码中介语短语缓解上述问题示意图
3.2 解码中介语断点
(1) 如何计算p→t′的短语翻译概率和词对齐?
(2) 应该解码哪些中介语断点?
本小节主要解决的是问题(1)。给定D是将中介语断点p翻译为目标语t′的完整推导过程,则使用式(6)计算短语规则p→t′的短语翻译概率φ(t′|p)。
(6)
p→t′的词对齐推导算法描述如图4所示。算法核心思想是根据翻译推导的过程,依次将与推导对应的span[i,j](j>i≥0)、span[j+1,k](k>j+1)拼接,根据目标语拼接方向(正向或反向),更新span[i,k]的词对齐信息。图4中的Step2就是更新两个span词对齐的过程,Step3是进行span拼接,得到更新词对齐后的更大的span,并利用翻译推导信息继续更新词对齐。图5展示了使用本算法更新两个span词对齐结果的示例。

图4 解码结果的词对齐推导算法

图5 解码结果的词对齐推导算法示例
3.3 质量控制因子
本小节描述的是如何解决判断哪些中介语断点应该被解码的问题。直觉上,并不是所有中介语断点都对完善短语表有帮助。我们期望捕获的是在不可靠的短语推导过程中,没有被利用的高质量中介语断点。

本文引入质量控制因子ψ的概念,利用推导产生的包含最大正向短语翻译概率的翻译规则所使用的中介语信息,衡量在给定源语短语s的推导过程的质量,其定义如下:
(7)

利用质量控制因子计算出的推导过程可靠性,本文将所有推导分为如下三类:
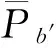
(8)
所以,本文解码中介语断点的定位是: 通过解码Discard型推导中的中介语断点缓解源语短语OOV问题,通过解码Low型推导中低于λ的高质量中介语断点产生更多优质的翻译规则。
4 实验结果与分析
4.1 实验设置 德-英、英-汉系统使用的数据如表1所示。
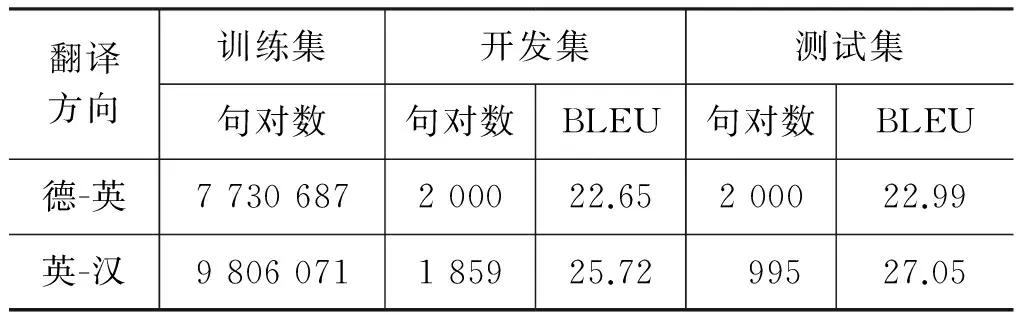
表1 双语训练数据/开发集/测试集 数据说明
我们采用基于短语模型的NiuTrans开源工具[5]完成以英语为中介语的德-汉翻译任务。使用GIZA++[6]工具获得双向词对齐结果,再使用“grow-diag-final-and”方法[4]进行词对齐对称化。抽取德-英短语对的长度设置为3-3,英-汉短语对的长度设置为3-5,则最终被推导出的德-汉短语长度为3-5。对所有抽取的短语翻译表进行取Top-N处理,这里设置N=30,即每一个源语短语对应的翻译候选最多为30个。分别使用66 522 497句和42 946 518句单语句子训练5元英文和中文的语言模型,均使用修正的Kneser-Ney平滑方法[7]。需要注意的是,在解码中介语断点时,使用的仍是上述语言模型,并没有因为解码结果是短语而做针对性优化。所有的特征采用最小错误率训练MERT[8]进行参数调优。使用基于词的BLEU-4[9]评价最终的翻译性能。
4.2 实验结果及分析
实验一 中介语断点比例
应用本文的实验数据及设置,得到德-英、英-汉短语翻译表信息如表2第一行及第二行所示。然后使用Triangulation方法得到被推导出的德-汉短语翻译表,其信息如表2第三行所示。可以看到,德—英短语表中包含1 915万唯一的英文短语;英-汉短语表中包含3 969万唯一的英文短语,但只有495万条英文短语在Triangulation方法中被使用。
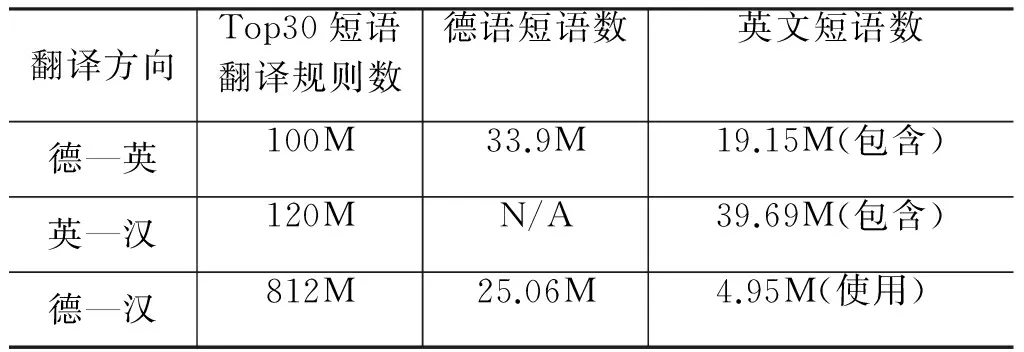
表2 系统训练得到的短语翻译表及Triangulation方法推导出的短语翻译表(M表示百万)
这里,我们以德—英的英文短语条数为参考,则断路的英文短语数为1 915-495=1 420万条,比例达(1 420万/1 915万)×100%=74.15%。也就是说,在德-英短语表中,有74.15%的英文短语存在断路情况,这是一个在基于Triangulation的中介语统计机器翻译中普遍存在的问题。而本文的出发点正是想缓解中介语短语断路的问题。
实验二 质量控制因子阈值λ对翻译结果的影响
由于不同的质量控制因子阈值的设置,对判断需要解码的中介语短语数目有关,从而对改善短语翻译表产生影响,这里我们做了下列实验: 在开发集上,通过改变阈值λ的取值,观察其对翻译结果的影响。实验结果如图6所示。

图6 质量控制因子阈值λ在开发集上对翻译结果的影响
之所以呈现先增后减的趋势,本文分析结果是: 如果质量控制因子阈值设置得过小,只有较少的高质量断路中介语短语被重新解码利用起来,对整体的翻译性能帮助并不明显。但如果设置质量控制因子的阈值过大,将会引入一些低质量的中介语短语,从而对翻译性能造成损害。这里我们看到λ=0.4时翻译性能达到最高,所以后续的实验默认设置λ=0.4。
实验三 不同推导类型对翻译性能的影响
我们对比了传统的Transfer方法、Triangulation方法和本文提出的Transfer-Triangulation方法中处理不同推导类型的翻译性能结果,如表3所示。
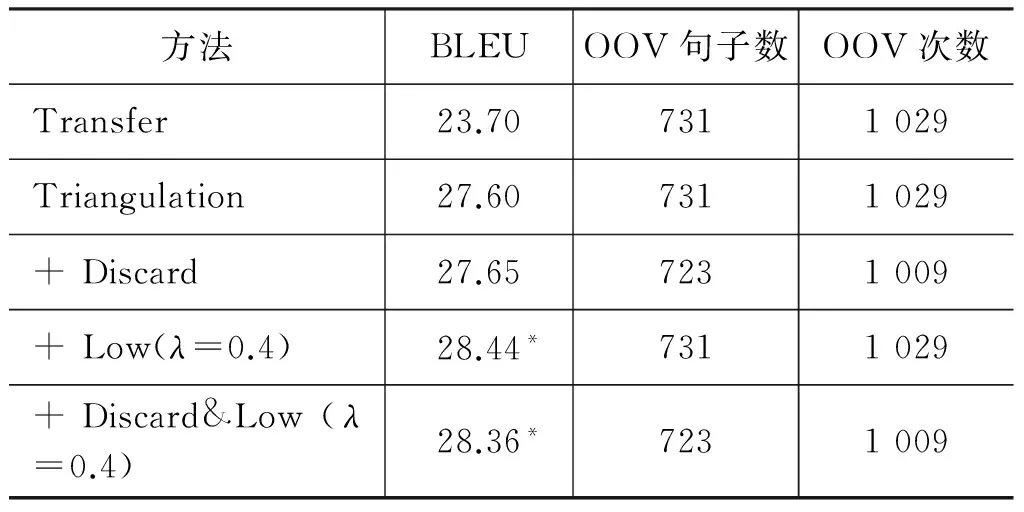
表3 Baseline及处理不同推导类型在测试集上的翻译性能(*表示显著高于Baseline)
由第一行和第二行可以看到,Triangulation方法比Transfer方法翻译性能更好,BLEU值上升了3.9个点。对于+Discard方法,在2 000句的测试集上仅仅减少了八个未登录词,并没有如设想地缓解了未登录词问题。分析其中原因发现,对于大多数的包含源语未登录词的源语-中介语短语,相应的中介语短语也包含未登录词,从而导致解码的结果中也包含未登录词,造成解码失败。对于+Low方法,由于传统的Triangulation方法丢失了一些高质量的中介语短语,而本文方法能够有效利用这部分高质量的中介语短语进行短语翻译表改善,最终实验结果也证实了该想法的有效性。对于+Discard&Low方法同只+Low的方法在BLEU上没有太多差异,且对OOV现象缓解的作用很小。
5 相关工作
基于中介语的统计机器翻译的典型方法有两种: Transfer方法和Triangulation方法。
对于Transfer方法,由2.1节分析可知,给定一个源语句子,最终会产生m×n个目标语的翻译结果。González-Rubio 和Duh等人[10-11]提出使用基于最小贝叶斯风险的系统融合方法去选择最优的翻译结果。
对于Triangulation方法,Kholy等人[12]提出从词对齐信息中抽取两个与语言独立的特征,该特征指示了被推导出的源语-目标语翻译规则的可靠性。Tofigh等人[13]提出利用基于中介语的上下文向量,从而计算被推导出的源语-目标语翻译规则间的短语相似度,并依据该相似度进行短语表过滤,从而起到过滤噪声规则的目的。朱晓宁等人[14]提出使用随机漫步方法获取潜在的源语-目标语短语路径,从而缓解源语未登录词问题。而后,朱晓宁等人[15]又提出在融合短语表前直接对源语-目标语的短语对共现次数进行估计的方法,避免了在短语推导时由于中介语断点导致破坏短语翻译概率空间的问题。Miura等人[16]提出在进行短语规则推导时记录所使用的中介语信息,在进行源语-目标语的翻译过程中额外考虑中介语的语言模型特征。
另外,Michael等人[17]探索了不同中介语的选择对系统的影响,英文更适合作为印欧语系及部分亚洲语言(如泰语、越语)之间的中介语。
不同于上述方法,本文提出的Transfer-Triangulation方法是将Transfer方法应用于短语级,利用解码中介语短语的方法改善被推导出的短语表。
6 总结
本文提出Transfer和Triangulation融合的中介语统计机器翻译方法,通过应用短语级的Transfer方法,将高质量的中介语断点解码成相应的目标语短语,从而将中介语断点转换为非断点,使得Triangulation方法能够利用更多中介语信息,达到改善短语表、提高翻译性能的目的。其中,本文解决了计算解码结果短语翻译概率和词对齐问题,并提出了质量控制因子的概念,将使用Triangulation方法推导过程分为三类: 丢弃型、低可信、高可信,利用质量控制因子阈值挑选Triangulation方法中无法使用的高质量中介语短语信息。实验结果表明,中介语短语断路现象是在应用Triangulation方法时普遍存在的问题,本实验中断路的中介语短语比例达74.15%;随着质量控制因子阈值λ增大,翻译性能呈先上升后下降的趋势,原因在于: 如果λ过小,只有较少的高质量断路中介语短语被解码,而如果λ过大,将会引入低质量的断路中介语短语,损害翻译性能;对低可信推导中的高质量中介语断点重新解码产生的推导规则,能够有效改善传统Triangulation方法推导出的短语表,减少了噪声翻译规则,并且扩大了短语表的覆盖度,BLEU值提高了0.86个点。但是对丢弃型推导的重解码处理并没有如预期有效缓解OOV问题,其原因在于源语如果包含OOV,其相应的中介语短语也往往包含OOV,从而造成解码失败。未来我们将探索如何将中介语的解码结果作为翻译特征,帮助解码器选择正确的翻译选项。
[1] Masao Utiyama, Hitoshi Isahara. A comparison of pivot methods for phrase-based statistical machine translation[C]//Proceedings of Human Language Technology: the Conference of the North American Chapter of the Association for Computational Linguistics, 2007: 484-491.
[2] Hua Wu, Haifeng Wang. Pivot language approach for phrase-based statistical machine translation[C]//Proceedings of 45th Annual Meeting of the Association for Computational Linguistics, 2007: 856-863.
[3] Trevor Cohn, MirellaLapata. Machine translation by triangulation: make effective use of multi-parallel corpora[C]//Proceedings of 45th Annual Meeting of the Association for Computational Linguistics, 2007: 828-735.
[4] Philipp Koehn, Franz Och, Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics(HLT: NAACL), 2003: 48-54, Edmonton, Canada, June.
[5] Tong Xiao, Jingbo Zhu, Hao Zhang, et al. NiuTrans: An open source toolkit for phrase-based and Syntax-based machine translation[C]//Proceedings of ACL: System Demonstrations, 2012: 19-24, Jeju Island, Korea, July.
[6] Franz Josef Och, Hermann Ney. A comparison of alignment models for statistical machine translation[C]//Proceedings of the 18th International Conference on Computational Linguistics, 2000: 1086-1090.
[7] Stanley F. Chen, Joshua Goodman. An empirical study of smoothing techniques for language modeling[J]. Computer Speech & Language, 1999(13): 359-393.
[8] Franz Och. Minimum error rate training in statistical machine translation[C]//Proceedings of ACL, 2003: 160-167, Sapporo, Japan, July.
[9] Kishore Papineni, Salim Roukos, Todd Ward, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computation Linguistics, 2002: 311-319.
[10] Jesús González-Rubio, Alfons Juan, Francisc Casacuberta. Minimum bayes-risk system[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, 2011: 1268-1277.
[11] Kevin Duh, Katsuhito Sudoh, Xianchao Wu, et al. Generalized minimum bayes risk system combination[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing, 2011: 1356-1360.
[12] Kholy A E, Habash N, Leusch G, et al. Language independent connectivity strength features for phrase pivot statistical machine translation[J]. Proc of Acl, 2013.
[13] Samira Tofighi Zahabi, Somayeh Bakhshaei, Shahram Khadivi. Using context vectors in improving a machine translation system with bridge language[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, 2013: 318-322.
[14] Xiaoning Zhu, Zhongjun He, Hua Wu, H et al.2013. Improving pivot-based statistical machine translation using random walk[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013: 524-534.
[15] Xiaoning Zhu, Zhongjun He, Hua Wu, et al.2014. Improving pivot-based statistical machine translation by pivoting the co-occurrence count of phrase pairs[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2014: 1665-1675.
[16] Akiva Miura, Graham Neubig, Sakriani Sakti, et al.2015. Improving pivot translation by remembering the pivot[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 2015: 573-577.
[17] Michael Paul, Hirofumi Yamamoto, Eiichiro Sumita† et al. On the importance of pivot language selection for statistical machine translation[C]//Proceedings of NAACL HLT 2009: Short Papers, 2009: 221-224.

王强(1990—),博士研究生,主要研究领域为机器翻译。
E-mail: wangqiang@gmail.com

杜权(1989—),博士研究生,主要研究领域为机器翻译。
E-mail: duquanneu@126.com

肖桐(1982—),博士,副教授,主要研究领域为机器翻译。
E-mail: xiaotong@mail.neu.edu.cn
Transfer-Triangulation Method for Pivot-Based Statistical Machine Translation
WANG Qiang, DU Quan, XIAO Tong, ZHU Jingbo
(NLP Lab,Northeastern University, Shenyang, Liaoning 110819, China)
1003-0077(2017)04-0036-08
TP391
A
猜你喜欢
电力系统保护与控制(2022年14期)2022-08-05
建材发展导向(2021年16期)2021-10-12
电脑报(2019年20期)2019-09-10
电子技术与软件工程(2019年12期)2019-08-22
初中生世界·九年级(2019年6期)2019-08-15
中学课程辅导·教学研究(2018年3期)2018-06-15
文艺生活·中旬刊(2017年10期)2017-11-19
文艺生活·下旬刊(2017年6期)2017-08-03
中国核电(2017年1期)2017-05-17
校园英语·上旬(2017年3期)2017-04-13
