
基于条件随机场的古汉语分词研究
2017-10-26 11:15杨世超纪月赵立鹏
电脑知识与技术 2017年22期
杨世超 纪月 赵立鹏


摘要:虽然古汉语数字化程度已经较高,但是自动化信息处理仍进展缓慢,针对这一问题,采用条件随机场模型制定特征模板进行古汉语分词研究并构建古汉语训练语料库。实验分析表明,制定具有语言特征的特征模板可以获得较高的分词性能。
关键词:古汉语;分词;条件随机场;特征模板;语料库
中图分类号:TP181 文献标识码:A 文章编号:1009-3044(2017)22-0183-02
1概述
古汉语典籍记载了中华民族的精华,存世古籍总计10万种以上,如果计入碑刻、家谱等约15万种,这些存世古籍负载着厚重的中华文明,凝聚着民族智慧。目前香港中文大学已经做了中文分词的数字化工作,然而针对古汉语的研究仅仅停留在数字化层面,近年来随着计算机技术的快速发展,人们在解决计算机视觉、机器翻译等方面逐渐成熟,但是在古汉语自然语言处理方面仍进展缓慢,要想实现古汉语的篇章理解、文本分析,首先需要将古汉语进行准确率、召回率以及F值都较高的分词,才能保障后续工作的正确性。
2古汉语分词面临的问题
目前公开的分词系统都是针对现代汉语的分词工具,该分词结果显然不能满足古汉语自高性能古汉语分词系统不仅需要好的古汉语分词模型,而且需要有充足的古汉语训练语料。但是仍没有公开的古汉语分词语料库。
3语料库的构建
考虑到人工标记语料工作量大、成本高,且标记规范不一致等问题,首先参照《用于信息处理的现代汉语分词规范》制定统一的分词规范,然后使用人工制定的语料训练模型,之后采用该模型进行分词,将输出的分词结果進行人工校订放人标准语料库。最终获得的语料库如下表2《孟子》语料所示。
4条件随机场
2001年J.Lafferty等人提出的条件随机场是一种无向图模型,给定输入可以根据一定的条件概率对输出进行预测的统计模型。该模型可以用于解决序分词、命名实体识别等序列标注任务。CRF改进了隐马尔科夫模型和最大熵马尔科夫模型,可以更好地解决标注偏置问题以得到更佳的判别值。它的特征模板允许加入更多复杂特征,可以将古汉语复杂特征设计到特征模。
4.1制定特征模板
古汉语有不同于现代汉语的词法、语法特点,为了获得较高效的古汉语分词系统,制定带有古汉语特征的CRF特征模板是非常必要的,例如,“者在”古汉语里经常作为词缀使用,这一用法通常跟在一个形容词后,如“老”者表示“上年纪的老人”。因此,本文设计的特征模板的复杂特征加入了词缀特征。
4.2条件随机场实现古汉语分词
4.2.1语料及标记方案
选取《论语》《孟子》《大学》《中庸》作为实验的数据来源。实验中采用4词位标记进行古汉语的字标注,分别用B表示首字符、E表示尾字符以、M表示中间字符及S表示单字词。
4.2.2数据预处理
本文所采用的条件随机场方法基于开源的CRF++实现,根据上述4词位集表示方法将训练语料表示成输入数据所需格式:天B;时E;不B;如E;地B;利E。
将数据均分为10等份,按照9:1进行划分训练集和测试集。
4.2.3模型训练
采用上述预处理后格式的文件,作为CRF++的输入,进行古汉语分词模型的训练。
4.2.4模型测试
采用训练好的模型对古汉语字符序列进行分词,并和测试集进行比较,得出模型的准确率、召回率以及F值。
5实验结果及结论
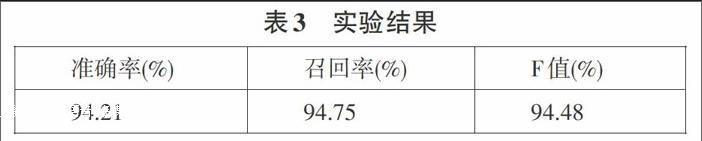
通过10-折交叉验证,每次用平均划分的份语料中的9份作为训练语料,剩余一份作为测试语料,计算十次实验的平局测评数据来对模型进行测评,实验结果如下表3所示:
本文采用条件随机场模型实现了古汉语分词任务,实验发现可以通过人工制定符合古汉语语言特征的特征模板来获得较好的分词效果。
猜你喜欢
潍坊学院学报(2021年4期)2021-11-20
校园英语·月末(2021年13期)2021-03-15
天津外国语大学学报(2020年1期)2020-03-25
汉字汉语研究(2018年1期)2018-05-26
语言与翻译(2015年4期)2015-07-18
语言与翻译(2014年1期)2014-07-10
语文知识(2014年3期)2014-02-28
外语学刊(2011年3期)2011-01-22
当代外语研究(2010年3期)2010-03-20
