
人类睡眠数据的特征提取和分析方法的研究
2017-12-12 09:09张春雷李金宝
黑龙江大学工程学报 2017年3期
胡 悦,李 昂,张春雷,李金宝,*
(1.哈尔滨商业大学 体育学院,哈尔滨 150080;2.哈尔滨市第三中学,哈尔滨 150001;3.黑龙江大学 计算机科学技术学院,哈尔滨 50080)
人类睡眠数据的特征提取和分析方法的研究
胡 悦1,李 昂2,张春雷3,李金宝3,*
(1.哈尔滨商业大学 体育学院,哈尔滨 150080;2.哈尔滨市第三中学,哈尔滨 150001;3.黑龙江大学 计算机科学技术学院,哈尔滨 50080)
使用智能手机来搜集声音和体动数据,对其进行预处理,提出联合特征提取和特征选择的TSFS方法。单纯的使用一种方法来选择特征,都会存在着一定的弊端。该方法是将特征提取和特征选择两种方法的联合,不仅可以筛选出符合实际情况的特征,而且还提高了分类的准确度。针对人类睡眠识别过程中的分类方法问题,提出基于改进二叉树的Multi-SVM睡眠分类器融合方法。单纯的使用一种分类方法,分类准确度难以得到提升。该方法是将多个SVM分类器组合成单枝的二叉树的形状,且树的每个节点都用一个二分类的SVM来分类。不仅降低了分类误差的积累,同时也提高了分类准确度。
可穿戴;睡眠监测;特征提取;特征选择;分类器融合
人类生命的1/3是处在睡眠中,可见睡眠的质量无论在人类的身体、精神,还是情感上都起着至关重要的作用。睡眠充足可提高工作效率、精力充沛、促进人体生长发育,这也是健康的必备条件之一。睡眠不足会导致疲劳、精神涣散、注意力下降、记忆力差,更甚者可能导致糖尿病、肥胖、抑郁、睡眠紊乱、睡眠呼吸暂停综合征等疾病[1]。同样不好的睡眠习惯也会导致心血管疾病和神经问题,如压力、焦虑等。所以,对人类睡眠数据的获取和分析,及对睡眠质量的评估和睡眠疾病的诊断都有极其重要的应用价值和研究价值。
随着科技的发展,人们越来越对可穿戴智能睡眠健康监测设备感兴趣。这些设备可以对病人的睡眠及身体各项指数进行实时监测,将搜集的数据上传到云端,专家和医护人员足不出户就可观察到病人的健康状况并传达给护理人员处理意见,这样有助于增加医疗诊断的效率和准确度。相比传统问诊模式,这种智能模式具有更多优势。当今,最流行的可穿戴智能睡眠健康监测设备如苹果iWatch智能手表[2]、Jawbone Up手环[3]、脉搏血氧饱和仪等。这些设备内部嵌入某些传感器,并实现特殊功能。
现阶段老龄化的加剧及社会对人类医疗投入的增加,推动了可穿戴智能睡眠健康监测设备迅猛发展。先进的科学技术和医疗技术的结合,促使人们越来越看好这个市场前景。所以,也要对人类睡眠有更深入、更细致的了解和认识。并将先进的知识和理念融入到人类睡眠监测过程中,开发出更符合人们需求的睡眠监测系统。
如果在夜深时,经常会出现打鼾、呼吸暂停、呼吸不足、呼吸紊乱、睡眠障碍等症状的人们,为防患于未然,需要在家里对睡眠进行实时监测,对睡眠有一定的分析和质量评估,并找出影响睡眠的因素,改善睡眠,提高身体健康。本文主要对人类睡眠数据获取和分析方法进行研究。
1 相关工作
1.1 特征提取的研究现状
提取特征越多,分类准确度会越高,但有时特征达到一定限度的时候,再增加特征,准确度反而会下降[4]。所以,控制特征的维度是非常重要的,既不能太少,也不能太多。Zoubek L等[5]利用PSG中的EEG、EOG、EMG信道的信号采用序列前向选择(Sequential forward selection,SFS)、序列后向选择(Sequential back selection,SBS)迭代式的特征选择算法,根据标准J的值来增加或减少特征数量,并选择出最优的时域和频域特征,可以识别Sleep、Wake两类。实验结果表明仅仅使用EEG信道的特征,分类准确度达到71%左右。若再加入EOG、EMG信道的特征,分类准确度可达到80%。Khabou M A等[6]评估了基于Actigraphy信号用于分类的63个不同特征的有效性,实现了两个特征选择算法去排列这些特征的有效性,即Add-One特征选择算法和Entropy-Minimization算法,实验结果表明Add-One特征选择算法效果更优。且这两种算法都是从排好序的这些特征中选出最优的特征,一旦特征选择好之后,利用最小距离分类器把这些Actigraphy信号分成不同的类别。这个最小距离分类器使用两种K-Mean和Max-Min聚集算法去生成模型。实验结果表明仅使用1~5个特征,分类的准确度达到95%~100%。GüneS等[7]利用PSG中的ECG、EOG、EMG信道的信号、气流、血氧饱和度、胸廓运动等信息,提出Multi-Class F-Score特征选择方法,采用多对F-Score值来决定增加或减少特征数量,结合多层感知机人工神经网络识别出4种不同程度的阻塞性睡眠呼吸暂停,实验结果表明准确度达到84.14%。但以往的研究都没有分析用于分类器的这些个人特征,也没有说明为什么选择这些特征等问题。
1.2 分类方法的研究现状
Gautam A等[8]使用嵌入手机的加速度传感器来预测睡眠,提出3种方法将加速度数据分成睡眠和觉醒两个状态,如Kushida’s方程式、基于统计的方法、基于训练的HMM方法。实验结果表明3者中最优的基于训练的HMM方法分类的准确度达到84%。Gu W等[9]实现了Sleep Hunter的智能睡眠监测系统,利用手机里的加速度传感器、麦克风、光传感器等来识别与睡眠相关的事件。通过加速度数据可预测出体动的数量,通过麦克风可预测出咳嗽、说梦话、打鼾等事件发生的次数,通过光传感器可预测出照明条件,及睡眠的持续时间和个人因素综合在一起,使用一个非监督的统计模型条件随机场来预测睡眠阶段、睡眠质量,并在浅度睡眠阶段提供叫醒服务。
存在一些特殊模型和特殊监测系统来识别睡眠,Oliver N等[10]实现了HealthGear,一个实时可穿戴智能系统来监测、分析生理信号SpO2和心率,它是由一些非侵入式生理传感器(如脉搏血氧计)构成。这些传感器通过蓝牙将监测数据传送到手机端,在手机端进行存储、转换、分析,及使用时域和频域分析算法来自动预测呼吸暂停事件。Harada T等[11]实现了将多个压力传感器排列在枕头内部来实时地监测在睡眠过程中的呼吸和体动的睡眠监测系统,通过头部压力分布的改变创建一个简单的监测模型,基于这个模型又提出了一个呼吸计数算法,实验结果表明准确度非常高,达到专业医疗设备的水平。与传统的监测呼吸系统相比,Nishida Y等[12]把人们从可穿戴设备中解放出来。利用放在屋顶的麦克风来收集呼吸数据,利用摄像头来记录身体位置、姿势等信息,利用210个压力传感器构成的床垫来监测体动、呼吸曲线,通过呼吸曲线评估出血氧的频率分布。由此就构成了一个非侵入式、非约束性的生活环境感知(SELF)系统自动识别人类的呼吸、阻塞性呼吸暂停。此系统不仅提高了准确度,还提供了一个无干扰、舒适的睡眠环境。但是,由于不同的分类方法会有不同的要求,且适用于不同的情景。所以,要选择出切合实际情况的分类方法。
针对以上现状,本文提出基于特征提取的特征选择TSFS方法和基于改进二叉树的Multi-SVM睡眠分类器融合方法来对睡眠数据进行处理和分析。
2 睡眠数据获取和预处理
2.1 睡眠数据获取
本文采用的是利用智能手机中的加速度传感器、陀螺仪传感器、重力传感器来搜集体动数据,利用麦克风来搜集声音数据。智能手机是一种非入侵式的监测设备,对监测者身体不会产生影响。它既可以通过身体运动情况,也可以通过声音情况来识别睡眠,身体运动同时会带动床上的手机产生运动,手机内传感器的加速度、角速度、运动方向等数据都会发生变化,将变化的数据记录下来就可以准确的识别出体动信息。声音数据转换成频域信息,由于说梦话、打鼾、呼吸、咳嗽等睡眠事件的频率是不同的,所以可以通过声音数据来识别睡眠情况。
手机监测过程中无需整晚的佩戴,对睡眠无影响。手机人人都有,无需额外去购买,节约成本。它不仅存储能力大,而且运算速度快、传感器的灵敏度高。智能手机还可以做到实时监听和上传数据,方便用户及时对自己及家人的睡眠数据进行观察和分析。
2.2 睡眠数据预处理
加速度传感器、陀螺仪传感器、重力传感器在监测过程中,由于噪声或是不规则地使用造成测量值的不准确,产生错误的数据,在结果中引入了误差。所以,对数据进行预处理是非常有必要的。采用卡尔曼滤波器来处理加速度传感器、陀螺仪、重力传感器数据。其工作原理是通过前一时刻的估计值和现在时刻的观测值来估计出现在时刻的估计值,并将现在时刻的估计值返回到滤波器中更新估计算法中的一些重要参数,以此构成一个循环往复的递推过程。信号系统中的状态量为x(n)={x(t0),x(t1),…,x(tn)},观测量为ζ(m)={z(t0),z(t1),…,z(tm)},如算法1所示。

算法1卡尔曼滤波算法(KF)输入:(1)状态方程:x(n)=T(n,n-1)×x(n-1)+Γ(n,n-1)× ω(n-1)其中,x(n)为N×1的状态矩阵,T(n,n-1)为N×N的状态转移矩阵,Γ(n,n-1)为N×S的状态噪声矩阵, ω(n-1)为系统噪声。(2)观测方程:z(n)=c(n)×x(n)+v(n)其中z(n)为M×1的观测向量,c(n)为M×N的观测矩阵,v(n)为观测噪声。(3)系统状态噪声矩阵为E( ω(n)× ω(n)H)=Q1(n),H在实数域表示矩阵的转置,测量噪声相关矩阵为E(v(n)×v(n)H)=Q2(n)。输出:^x(n|ζ(n))为系统状态预测量1 初始状态,^x(0|ζ(0))=E(x(0))P(0)=E{[x(0)-E(x(0))]×[x(0)-E(x(0))]H}2 状态一步预测^x(n|ζ(n-1))=T(n,n-1)×^x(n-1|ζ(n-1))∈CN×13 观测z(n)计算新息ε(n)=z(n)-^z(n|ζ(n-1))=c(n)×x(n)+v(n)-c(n)×^x(n|ζ(n-1))-^v(n|ζ(n-1))=c(n)×x(n)+v(n)-c(n)×^x(n|ζ(n-1))∈CM×1由于噪声与前一时刻的观测量相互独立,即E(v(n)×zH(k))=0,k=0,1,…,n-1,所以^v(n|ζ(n-1))=04 一步预测误差自相关矩阵P(n,n-1)=T(n,n-1)×P(n-1)×TH(n,n-1)+Γ(n,n-1)×Q1(n-1)×ΓH(n,n-1)∈CN×N其中,初始时P(n-1)=E[ψ(n-1)×ψH(n-1)]∈CN×Nψ(n-1)=x(n-1)-^x(n-1|ζ(n-2))5 新息过程自相关矩阵H(n)=c(n)×P(n,n-1)×cH(n)+Q2(n)∈CM×M6 卡尔曼增益G(n)=P(n,n-1)×cH(n)×H-1(n)∈CN×M7 更新状态估计^x(n|ζ(n))=^x(n|ζ(n-1))+G(n)×ε(n)∈CN×18 更新状态估计误差自相关矩阵P(n)=[I-G(n)×c(n)]×P(n,n-1)∈CN×N9 回到步骤2,递推滤波
对于声音数据,本文采用快速傅里叶变换(FFT)来进行预处理,把时域信息变换成频域信息,且在频域上提取特征,能更好的区分睡眠阶段。而FFT正是离散傅里叶变换(DFT)的一种比较快速的算法。基-2 FFT算法是将计算一个N点的DFT,转换成了计算2个N/2点的DFT的过程。同时对2个N/2点的DFT,继续迭代下去,转换成4个N/4 的DFT。可见,FFT算法将时间复杂度从O(n2)变成O(nlogn)。

(1)

3 联合特征提取和特征选择的TSFS方法
3.1 预选先验特征
在分类识别过程中,先验特征不仅包括时域特征,同时还存在频域特征。这些特征对人类睡眠的识别都起着非常好的作用。所以,首选先验特征,对于加速度数据和陀螺仪数据、重力加速度数据及它们的振幅中选择最大值、最小值、均值、中值、方差、峰值、倾斜度、均方根等8个特征。且其中一些特征也应用在文献[13]中对身体运动进行区分,分别介绍一下均方根、峰值和倾斜度的公式。

(2)

(3)

(4)
对于声音数据选择Entopy、Centriod、Flux、Bandwidth、Rolloff等5个特征,且其中一些特征也应用在文献[14-15,21]中对声音进行分类,文献[9]中说明它们在不同的声音事件上频谱有不同的分布,易于区分。经过快速傅里叶变换得到的一个窗口的数据为f1,f2,…,fN,分别介绍一下公式。
(5)

(6)
(7)

(8)

(9)
3.2 选择特征的方法
对于特征,有两种主要的处理方法:特征提取和特征选择。特征提取是对特征进行适当的变换,这样的变换分为线性的和非线性的。线性的常用方法有PCA、LDA、独立成分分析[16,20]等。不考虑特征本身所具有的含义和联系,选出的特征可能不符合实际情况,可理解性差,无关特征也有可能被选入到最优特征子集中。
而特征选择是通过遍历特征集,以一定的评价准则来选择出最优的特征子集,难点在于评价准则的制定,而且遍历特征集的搜索过程也是一个NP难的问题。特征选择中的搜索方法一般分为“启发式搜索”“完全搜索”“随机搜索”[17],具体分类见图1。

图1 特征选择方法Fig.1 Methods of feature selection
3.3 联合特征提取和特征选择的TSFS方法
单独使用任一种选择特征方法,都存在它的弊端,达不到最佳的效果,所以,本文提出联合特征提取和特征选择的TSFS方法。在特征提取领域中基于核的主成分分析Kernel PCA方法利用核将PCA方法推广到非线性的样本空间,而在特征选择领域中启发式搜索中的增L减R的特征选择LRFS方法处理速度快、效果好,由此把它们二者相结合。
首先,PCA方法,它是将高维度的线性原始样本空间经过空间映射变换到低维度的新的样本空间,并提取一些最能表现样本的新特征,也叫主要成分,使特征间的冗余度降低。同时它也是基于统计信息的方差最优的一种特征提取方法,如算法2所示。

算法2 PCA方法输入:X={X1,X2,…,XN}为原始样本集合输出:Y={Y1,Y2,…,YM}为新样本集合1 为消除不同评价标准导致数据的差异,影响分析,要先进行标准化。选取样本与均值的差作为原始数据,计算均值矩阵E(X)=μ2 计算样本与均值的差,记为 x=X-μ3 构造Λ协方差矩阵,记为Λ=1N x xT4 计算Λ的特征值λ1,λ2,…,λD,且按降序排列λ1≥λ2≥…≥λD,及它们相应的特征向量T={T1,T2,…,TD}5 计算主成分的贡献值η=∑Mi=1λi/∑Di=1λi,选出η符合范围前M个主要成分,得到a={T1,T2,…,TM}6 计算出新样本值,Y=aT x7 returnY
KPCA方法是将原始非线性样本空间使用非线性变换核的手段映射到高维的特征空间上,在特征空间上使用线性变换PCA方法进行压缩,降低特征空间的维度。这样,问题的重点转换为核方法的选择上。
核技巧[18]是变换成向量的内积,设X是输入空间,H为特征空间,如果存在一个从X到H的映射
φ(x):X→H,使得∀xi,xj∈X,都有公式10成立。
K(xi,xj)为
(xi,xj)→K(xi,xj)=φ(xi)·φ(xj)
(10)
核函数,φ(xi)为映射函数,φ(xi)·φ(xj)为φ(xi)和φ(xj)的内积。一般通过φ(xi)和φ(xj)来计算K(xi,xj)并不十分容易。所以,直接计算K(xi,xj),而无需关注具体的映射φ。因为给定K(xi,xj)时,φ并不唯一。然而,想要成为核函数,只需满足Mercer条件即可。

1.线性
K(x,y)=x·y
2.N阶多项式
K(x,y)=[(x·y)+1]N
3.高斯径向基

本文选用高斯径向基函数(RBF)作为核函数。具体描述KPCA方法,如算法3所示。

算法3KernelPCA方法输入:样本空间X={X1,X2,…,Xn}T,Xi=[Xi1,Xi2,…,Xim],i=1,2,…,n,参数σ2输出:Y={Y1,Y2,…,YM}为新样本集1 样本空间映射到特征空间,X→M={φ(H1),φ(H2),…,φ(Hm)}2 特征空间中心化,μ=∑mi=1φ(Hi),M∗={φ(H1)-μ,φ(H2)-μ,…,φ(Hm)-μ}3 特征空间上数据的协方差矩阵为:C=1m∑mi=1[φ(Hi)-μ]·[φ(Hi)-μ]T4 接下来,求协方差矩阵C的特征值和特征向量,即满足CV=λV,λ为矩阵C的特征值,V为矩阵C的特征向量。5 CV=λV左右两边同乘φ(Hi)得,φ(Hi)CV=φ(Hi)λV6 又因特征向量可以由数据集M∗线性表示,即 V=∑mj=1αj·φ(Hj)7 φ(Hi)CV=φ(Hi)λV,可表示为1m[∑mj=1αjφ(Hj)]×[∑mk=1[φ(Hk)-μ][φ(Hk)-μ]T]·φ(Hi)=λ∑mi=1αj(φ(Hj)·φ(Hi))8 本文选择高斯径向基函数,K(Hi,Hj)=φ(Hi)·φ(Hj)。令K~ij=Kij-1m[∑mw=1Kiw+∑mw=1Kwj]+1m2∑mw,t=1Kwt。所以,化简为,mλK~α=K~2α,即mλα=K~α9 对mλα=K~α求解K~的特征值λ1,λ2, ,λD,且按降序排列λ1≥λ2≥…≥λD,及它们相应的特征向量T={T1,T2,…,TD}10 计算主成分的贡献值η=∑Mi=1λi/∑Di=1λi,选出η符合范围前M个主要成分,得到a={T1,T2,…,TM}11 计算出新样本值,Y=aTK~12.returnY
其次,假如原始特征集合个数为D,最优特征子集个数为d。序列前向特征选择SFS初始特征个数从0开始,每次迭代都从候选集中选出评价标准中最佳的一个特征增加到最优特征子集中,并保证特征间冗余度小,直到最优特征子集个数达到d为止。缺点是无法将已经加入到最优子集中的特征再剔除出去。相反,序列后向特征选择SBS初始特征个数从D开始, 每次迭代都从最优特征子集中选择评价标准中最差的一个特征剔除出去,并保证所选的特征与最优子集中的特征差异很大,直到最优特征子集个数达到d为止。缺点无法将已经从最优特征子集中剔除的特征再加回来。而增L减R的特征选择LRFS方法是根据L和R的大小关系,分两种情况处理:
1.LR。每次迭代先使用SFS方法增加评价标准中最优的L个特征到最优特征子集中去,再使用SBS方法从最优特征子集中剔除评价标准中最差的R个特征。
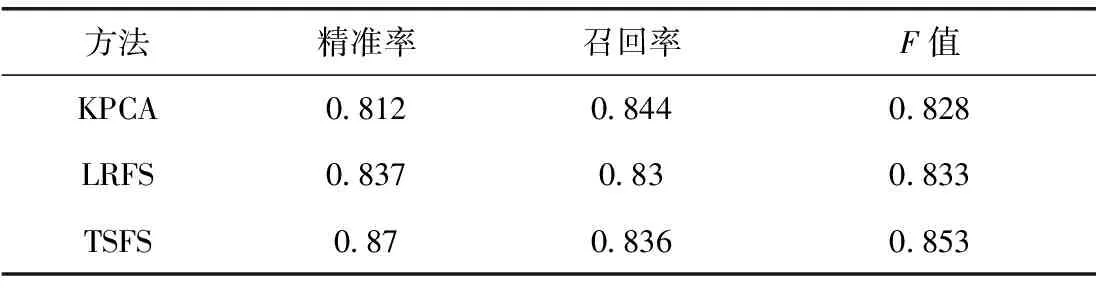
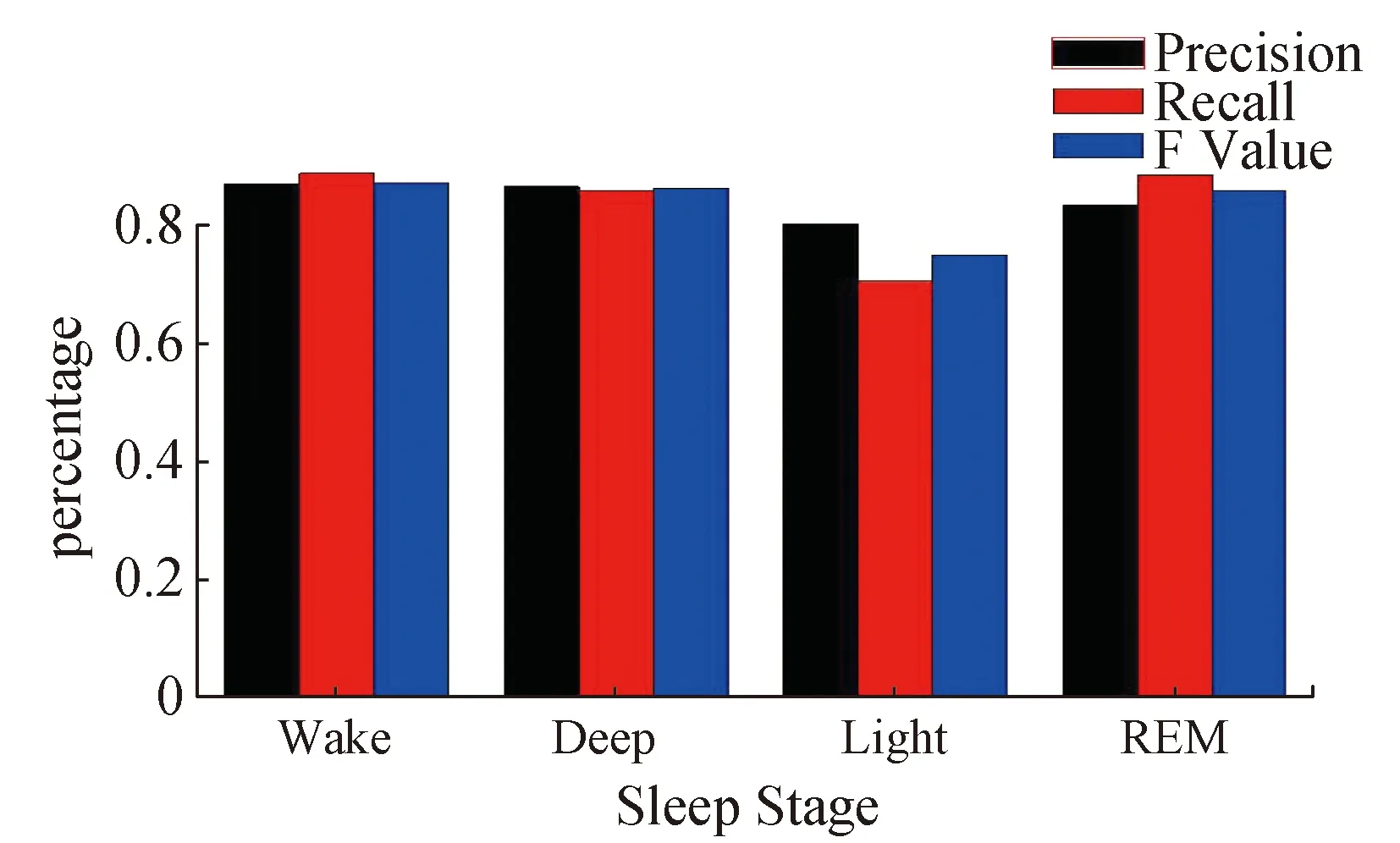
2.L LRFS折中了SFS和SBS的优缺点的一种回溯方法,该算法比SBS处理速度快,比SFS实验效果好。特征既能被选入,同时可能被剔除,如算法4所示。 算法4增L减R的特征选择LRFS(L>R)输入:包含i个特征的特征子集F(i),i≤D,κ1(•)、κ2(•)为评价标准,t为临时变量输出:包含d个特征的最优特征子集F(d)1 采用SFS方法在候选集F(D)-F(i)中按照评价标准κ1(•)选出最优的L个加入到特征子集F(i)中,并生成新的特征子集F,元素个数为i+L2 更新循环变量t=i+LF(t)=Fi=t3 采用SBS方法在最优的特征子集F(i)中按照评价标准κ2(•)剔除最差的R个特征,并生成新的最优特征子集F`,元素个数为i-R4 更新循环变量t=i-RF(t)=F′5 if(t=d)6 returnF(t)7 else8 更新循环变量i=tF(i)=F(t)9 回到步骤1,继续计算 最后,TSFS方法分两层来完成,第一层使用KPCA方法,将原始特征集进行非线性变换,再使用PCA方法将高维空间压缩到低维空间,以实现降维。但仍会存留一些冗余的特征没被过滤掉。第二层使用LRFS方法过滤掉与类别不相关的特征,评价标准为与类别的相似度,并选择最优的L个特征加入到最优特征子集中,并用评价标准为特征间的余弦距离,并剔除最差的R个特征,以这样的过程迭代下去选出最优的特征。这样保证选取的最优特征符合类内距离紧密、类间距离很大等特点。具体过程如算法5所示。 算法5联合特征提取和特征选择的TSFS方法输入:F={F1,F2,…,FD}为本文预选的所有先验特征的集合,参数σ2,临时变量Y={Y1,Y2,…,YM},κ1(•)、κ2(•)为评价标准输出:最优特征子集Fopt={Fopt1,Fopt2,…,Foptd}1 Y=KPCA(F,σ2),执行KPCA方法2 设定评价标准增L的评价标准:κ1(x,y)=ρ(x,y)=cov(x,y)D(x)×D(y) 减R的评价标准:κ2=cos(x,y)=x·y(x·y)3 Fopt=LRFS(Y,κ1,κ2),执行LRFS方法4 returnFopt 4.1 分类器融合技术 不同的分类方法对于不同的分类属性会得到不同的分类准确度,特点和要求也各不相同,所以针对实际情况,选择适合且效果最佳的分类方法是非常有挑战的。单一的分类方法在性能上的提升以达到一定限度,那如何降低分类的错误率,研究将多个分类方法有机组合成一个效果最佳的分类方法,即产生了分类方法的融合技术。 定义1:设训练数据集为I={(x1,c1),(x2,c2),…,(xn,cn)},xi表示第i个训练样本数据,ci表示第i个类别。基础分类器的集合为T={T1,T2,…,Tm},m 4.2 基于Bagging多分类器选择融合 基于Bagging(Bootstrap Aggregating)多分类器选择融合是指定一个基础分类器集合T和原始训练数据集I,在原始训练数据集的基础上进行多次有放回等概率抽样得到新的数据集Ii,且二者大小完全相同。多次迭代这样的过程,将产生许多新的训练数据集,在此基础上,使用基础分类器T预测,得到分类结果为ci。目标函数S设定为投票法,即选择基础分类器输出的分类结果中出现次数最多的那一类为最终的分类结果c*,具体过程见图2。 图2 Bagging实现过程Fig.2 Process of Baaging implementation 4.3 基于AdaBoost多分类器组合融合 基于AdaBoost多分类器组合融合是一种提升方法,将一系列弱分类器组合成强分类器的过程。通过修改原始训练数据集的权重而得到新的训练数据集,使当前的弱分类器受前一轮弱分类器分类结果的影响。其目的是提高在前一轮弱分类器中被错误分类的数据的权重,降低被正确分类的数据的权重,由于权重的改变激励下一轮弱分类器加大力度处理由上一轮弱分类器中被错误分类的数据,以此构成循环迭代的过程,算法已在文献[18]中详细介绍。这些弱分类器采用分治的方法解决了一些难于处理的分类问题,即每一轮都加大难于处理的那部分数据的权重,减小容易处理的那部分数据的权重,将难于处理的那部分数据留给下一轮优先处理。 4.4 基于改进二叉树的Multi-SVM睡眠分类器融合 图3 二叉树的Multi-SVM分类器融合Fig.3 Binary tree of Multi - SVM classifier fusion 支持向量机(Support Vector Machines,SVM)[18]作为基础分类器,它是在特征空间上的间隔最大的线性分类器,拥有完善的统计学理论基础,适用于二分类且分类准确度优于其他基础分类器。这里的间隔最大化实际上就是求解凸二次规划的最优化问题,并且可以找到全局最优解。在多分类的情况下,可以组织多个SVM。例如基于二叉树的Multi-SVM分类器融合,根为所有类别构成的一个总的类别,由根出发进行二分,将一个类别分裂为两个子类别,再对子类别继续分裂,直到叶节点为单独的类别为止,这样就将一个多类别问题转换成诸多二分类问题,其中每个内部节点的二分类问题都使用一个SVM分类器来训练。这样的结构建立非常简单,c个类别的分类问题只需使用c-1个SVM分类器,识别速度较快。结构见图3、图4。图4的结构更容易产生误差的积累,也就是说当某个内部节点将一些样本分类错误,那么这个错误会延续到此内部节点的后代节点上。如果这样的内部节点离根特别近的地方,误差积累越多,分类效果就越差,严重影响识别过程。而图3的结构在误差积累方面更优一些,假如事先根据识别的难易程度将类别设定一些优先级,能准确识别的类别优先处理,比较复杂的类别留到后面处理,这样误差积累就会降低。对类别设定优先级成为了关键。 图4 平衡二叉树的Multi-SVM分类器融合Fig.4 Balance Binary tree of Multi - SVM classifier fusion 用距离、相关性、信息增益来衡量样本间的相似程度。使用距离来计算相似性是把所有样本的特征参数都当做同等条件计算,忽略不同属性之间的差异。而使用信息增益来计算相似性是利用熵来表示样本分布的密集程度,只能看出特征对分类系统的影响,而无法具体到某个类别上。所以,针对以上两种方法的优缺点,将二者结合为类别优先级的判定标准为最佳,产生了定义2。 定义2:假设样本X=[x1,x2,…,xN]属于类cα,且xi=(Fi1,Fi2,…,FiN),i∈[1,M],样本Y=[y1,y2,…,yN]属于类cβ,且yj=(Fj1′,Fj2′,…,FjN′),j∈[1,M],则改进的类间距离d(cα,cβ): (11) 在式(11)中,|Fij|表示Fij在X中出现的次数,|Fij(cα)|表示属于cα的Fij样本个数,φ(Fij)和φ(Fij′)分别表示Fij和Fij′对于样本归属类别cα和cβ的熵。其中,当有P个类别时,此式d(ci,cj)具有自反性和对称性,d(ci,ci)=0,d(ci,cj)=d(cj,ci),i,j∈[1,P],且i≠j。可见,熵越大,特征的不确定性越大。所以距离越大,类别间更容易区分。首先找出一个类别ci距离剩下的P-1个类别最远,此时ci的优先级是较高的。若出现两个类别距离其他类别同样远,则选择类下标较小的优先级高。以此类推,直到剩下最后两个类别进行比较时,类标号较小的优先级高。改进二叉树的Multi-SVM睡眠分类器融合算法,如算法6所示。 算法6改进二叉树的Multi⁃SVM睡眠分类器融合算法输入:原始训练数据集I={(x1,y1),(x2,y2),…,(xn,yn)},xi∈Rn,yi∈{c1,c2,…,cp},i=1,2,…,n输出:基于二叉树的多类别SVM分类模型T1 根据式(11)计算类与类之间的距离d(ci,cj),i,j∈[1,P],且i≠j2 每一个类别ci,都存在P-1个距离值,将其构成A是P×(P-1)的矩阵3 计算每一个类别ci的P-1个距离值之和si,产生S是1×P的矩阵4 对矩阵S按照从大到小的顺序排序,相应的类别存入矩阵(dij)∈D1×P中5 将S中第一个元素所对应的类别d11的优先级定为最高,并存入c′为1×P的矩阵中。若S中同时存在多个元素为最大时,取类别dij值中较小的优先级定为最高6 此时,将已找到的最高优先级的类别与其他类别划分开,将重新计算剩下P-1个类别互相之间的距离,重复步骤2~6的过程。直到只剩下两个类进行划分时,类下标小的类别优先级高,并将二者共同加入到c′,转到步骤77 根据排好序的类别c′∈{c1′,c2′,…,cp′},生成改进的二叉树T8.returnT 5.1 数据集 图5 实验环境Fig.5 Experimental environment 本文挑选了15名年龄在20~30岁的实验对象,其中7名女性和8名男性,分别测试15 d内睡眠情况。睡眠数据既包括体动数据,即加速度计数据、陀螺仪数据、重力传感器数据及每个数据的振幅值和时间戳,维度大小为4×3+1=13。也包括声音数据和时间戳。从睡眠数据中选取特征样本的维度为12×8+1+5=102。其中,时域特征的维度为12×8=96,对12维原始数据的每一维提取8个时域特征。频域特征的维度为5,还有一维是时间戳。数据的窗口大小为2 s,覆盖率为50%。数据的采样频率分别为100 Hz、16 000 Hz。在搜集到的睡眠数据中随机抽取80%作为训练数据,剩下的20%作为测试数据。在模型的训练阶段,本文选择Zeo头戴对睡眠阶段的划分做为真实数据。因为Zeo监测的准确度可达到75%左右[19],相比于PSG(80%)差一些,但已接近监测睡眠的真实情况。而且Zeo相比于PSG成本更低,也更利于携带。PSG需要在特定的环境下监测,此时由于监测设备的各种限制,用户不一定反映出自己的真实睡眠情况。实验环境见图5。 5.2 预处理结果 原始加速度数据中含有一定的随机噪声,原始数据的波动情况见图6(a)。使用卡尔曼滤波之后波动更加明显,它的滤波效果图见图6(b)。 图6 加速度数据Fig.6 Acceleration data 原始声音数据见图7(a),FFT变换后的数据见图7(b)。因为噪声较多是高频信号,所以使用FFT之后要继续消除高频信号,效果见图7(c)。 图7 声音数据Fig.7 Sound data 5.3 最优特征子集 数据集中,特征维度为102。TSFS方法第一层采用的是KPCA方法,对102维的数据集进行降维,并降到F维,将不同维度的数据集送入到SVM中进行预测,并观察F的变化对分类准确影响程度(图8(a)),当降到30维的时候,分类的准确度最高。接下来,将通过KPCA方法得到的30维的特征送入第二层LRFS方法中去,挑选出与类别最相关,且与特征内部最无关的特征,维度为M维。将不同维度的数据集送入到SVM中进行预测,并观察M的变化对分类准确影响程度(图8(b)),可见,当降到15维的时候,分类的准确度最高。 图8 TSFS的识别准确度Fig.8 Accuracy of TSFS 不同的参数σ2对实验效果的准确度也有着不同的影响(表1)。由表1可见,随着σ2增加,分类准确度增加。所以,本文选取σ2=100。 联合特征提取和特征选择的TSFS方法和基于增L减R的特征选择LRFS方法、KPCA方法3个方法的准确度比较,见图9。TSFS方法优于LRFS方法和KPCA方法,且在特征个数为15时,准确度达到最高。KPCA在特征为30时准确度最高。LRFS在特征为15时准确度最高。特征选择少量时,误分类较多,准确度不高,但再增加特征时准确度会有显著的提升。达到上限时,再增加特征准确度就会下降。 表1 参数σ2对准确度的影响 图9 TSFS、LRFS和KPCA 3种方法的准确度比较Fig.9 The accuracy of TSFS,LRFS and KPCA 在精准率、召回率、F值等方面的比较,见表2所示。可见,TSFS方法的精准率和F值最高,而KPCA的召回率最高。充分说明,TSFS方法优于KPCA方法和LRFS方法。 通过TSFS方法选择出15个特征,其中12个时域特征和3个频域特征。分别为加速度模和重力加速度模的均值、方差、中值、rms、kurt、skew等12个时域特征,Entopy、Centriod、Bandwidth等3个频域特征,用于睡眠阶段的划分。 表2 评价标准比较Table 2 Comparation of evaluation standard 5.4 睡眠阶段划分结果 图10 基于改进二叉树的Multi-SVM睡眠分类融合布局Fig.10 Layout on the improved binary tree structure of Multi-SVM sleep classification fusion 基于Bagging多分类器选择融合、基于AdaBoost多分类器组合融合两种方法的基础分类器为SVM进行分类。并将它们与基于改进二叉树的Multi-SVM睡眠分类器融合方法在准确度上对比(图11)。由图11可见,本文提出的方法优于AdaBoost、Bagging。 本文将睡眠阶段划分为觉醒Wake、快速眼动睡眠REM、浅度睡眠Light、深度睡眠Deep等4个阶段。在这里针对使用基于改进二叉树的Multi-SVM睡眠分类器融合方法对觉醒Wake、快速眼动睡眠REM、浅度睡眠Light、深度睡眠Deep 4个睡眠阶段的精准率、召回率、F值进行对比,见图12。 图11 3种方法的准确度Fig.11 Accuracy of three methods 图12 睡眠阶段的比较Fig.12 Comparison of sleep stages 由图12可见,Wake阶段精确率、召回率和F值都是最高,Deep阶段的精确率和F值都是比较高的,而REM阶段的召回率比较高,Light阶段的精确率和召回率、F值都是最低的。所以,Wake阶段识别的准确程度最高,Deep阶段识别的准确程度要优于REM、Light阶段。实验证明了算法6的有效性,4个睡眠阶段的优先级由高到低分别Wake、Deep、REM、Light。 由于人类睡眠占据了人类生命活动的大部分,所以对它的研究尤为重要。伴随着可穿戴智能监测设备的发展,人们慢慢地对自己的睡眠有一定了解,但能否准确识别出睡眠的阶段及睡眠质量的评估成为一个非常严重的问题。基于以上描述,本文研究了数据获取、特征选择方法和分类模型。提出了联合特征提取和特征选择的TSFS方法。该方法解决了特征维数灾难问题,选择出与类别相关,且不冗余的特征。提出了基于改进二叉树的Multi-SVM睡眠分类器融合方法。该方法可减少在分类过程中的误差积累,提高了模型分类的准确度。 在联合特征提取和特征选择的TSFS方法中,本文采用的都是一些比较常见的时域或频域特征,数量有限。后续会增加更有利于实际情境且更利于模型分类的特征。且环境过于嘈杂时,信号过滤效果不佳,后续会提高过滤效果。在基于改进二叉树的Multi-SVM睡眠分类器融合方法中,模型仅能实现离线的,后续会增加在线的识别。 [1] Parish J M.Sleep-related problems in common medical conditions[J].Chest Journal, 2009, 135(2): 563-572. [2] http://www.apple.com/cn/. [3] https://jawbone.com/up. [4] Molina L C, Belanche L, Nebot à.Feature selection algorithms: A survey and experimental evaluation[C]//Data Mining, 2002.ICDM 2003.Proceedings.2002 IEEE International Conference on.IEEE, 2002: 306-313. [5] Zoubek L, Charbonnier S, Lesecq S, et al.Feature selection for sleep/wake stages classification using data driven methods[J].Biomedical Signal Processing and Control, 2007, 2(3): 171-179. [6] Khabou M, Parlato M V.Classification and feature analysis of actigraphy signals[C]//Southeastcon, 2013 Proceedings of IEEE.IEEE, 2013: 1-5. [7] Günes S, Polat K, Yosunkaya S.Multi-class f-score feature selection approach to classification of obstructive sleep apnea syndrome[J].Expert Systems with Applications, 2010, 37(2): 998-1004. [8] Gautam A, Naik V, Gupta A, et al.An smartphone-based algorithm to measure and model quantity of sleep[C]//Communication Systems and Networks(COMSNETS),2015 7th International Conference on IEEE,2015:1-6. [9] Gu W, Yang Z, Shangguan L, et al.Intelligent sleep stage mining service with smartphones[C]//Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing.ACM, 2014: 649-660. [10] Oliver N, Flores-Mangas F.HealthGear: a real-time wearable system for monitoring and analyzing physiological signals[C]//Wearable and Implantable Body Sensor Networks, 2006.BSN 2006.International Workshop on.IEEE, 2006: 4-64. [11] Harada T, Sakata A, Mori T, et al.Sensor pillow system: monitoring respiratory system by sensorized environment[C]//Sensors, 2002.Proceedings of IEEE.IEEE, 2002, 1: 705-710. [12] Nishida Y, Hori T.Non-invasive and unrestrained monitoring of human respiratiry system by sensorized environment[C]//Sensors,2002.Proceedings of IEEE, 2002, 1:705-710. [13] Hao T, Xing G, Zhou G.iSleep: unobtrusive sleep quality monitoring using smartphones[C]//Proceedings of the 11th ACM Conference on Embedded Networked Sensor Systems.ACM, 2013: 4. [14] Saunders J.Real-time discrimination of broadcast speech/music[C]//Acoastics,Speech, and Signal Processing,1996.ICASSP-96.Conference Proceeding,1996 IEEE International Conference on IEEE, 1996,2: 993-996. [15] Lu H, Pan W, Lane N D, et al.SoundSense: scalable sound sensing for people-centric applications on mobile phones[C]//Proceedings of the 7th international conference on Mobile systems, applications, and services.ACM, 2009: 165-178. [16] Ben-Hur A,Brutlag D.Feature extraction, foundations and applications[J].Studies in Fuzziness and Soft ComputingSpringer-Verlag, 2006: 315-324. [17] http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html. [18] 李航.统计学习方法[M].北京:清华大学出版社, 2012. [19] Shambroom J R, Fabregas S E, Johnstone J.Validation of an automated wireless system to monitor sleep in healthy adults[J].Journal of Sleep Research, 2012, 21(2): 221-230. [20] Waltisberg D,Amft O,Brunner D P,et al.Detecting disordered breathing and limb movement using in-bed force sensors[J].IEEE Journal of Bitmedical and Health Informatics,2017,21(4):930-938. [21] Gu W,Shangguan L,Yang Z,et al.Sleep hunter:lowards fine grained sleep stage tracking with smartphones[J].IEEE Transactions on Mobile Computing,2016,15(6):1514-1527. Research on the feature extraction and analysis method of human sleep data HU Yue1, LI Ang2,ZHANG Chun-Lei3, LI Jin-Bao3,* (1.SchoolofPhysicalEducation,HarbinUniversityofCommerce,Harbin150080,China; 2.HarbinNo.3HighSchool,Harbin150001,China;3.SchoolofComputerScienceandTechnology,HeilongjiangUniversity,Harbin150080,China) Using smart phones collect sound and body moving data, and these data are preprocessed, and the combination of feature extraction and feature selection is proposed, which is called TSFS method. Only using a method to select features, there will be some drawbacks. The method is a combination of two methods of feature extraction and feature selection, and not only can be screened out the characteristics of the actual situation, but also improve the accuracy of classification. For the classification of human sleep recognition process, a classifier fusion method of Multi-SVM sleep based on improved binary tree is proposed. Only using one classification method, the classification accuracy is difficult to be improved. The method is combining multiple SVM classifiers into a single branch of the shape of binary tree, and each node of the tree is classified by a two SVM. Not only the accumulation of classification error is reduced, but also the classification accuracy is improved. wearable; sleep monitoring; feature extraction; feature selection; classifier fusion 10.13524/j.2095-008x.2017.03.042 TP391 A 2095-008X(2017)03-0056-015 2017-07-18 国家自然科学基金资助项目(61370222);哈尔滨市优秀学科带头人资助项目(2015RAXXJ0042015RAXXJ004) 胡 悦(1972-),女,辽宁沈阳人,讲师,研究方向:体育心理学、体育管理学、网络群体消费,E-mail:15804510068@139.com;* 李金宝(1969-),男,黑龙江庆安人,教授,博士,研究方向:无线传感器网络、数据库原理、移动计算和并行计算,E-mail:jbli@hlju.edu.cn。

4 基于改进二叉树的Multi-SVM睡眠分类器融合方法


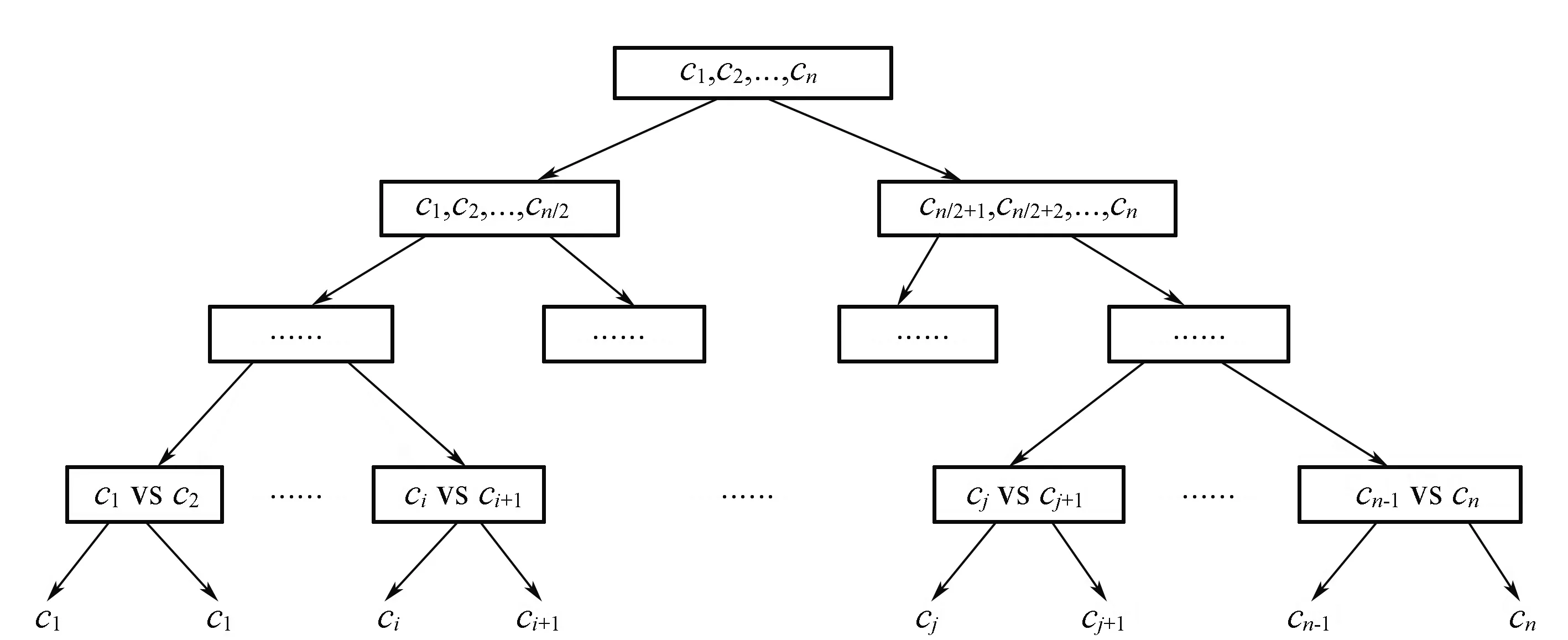
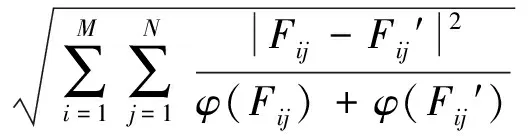

5 实验结果和分析

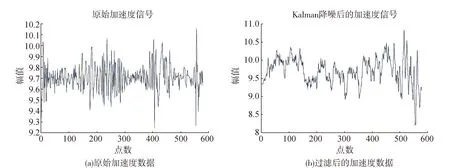

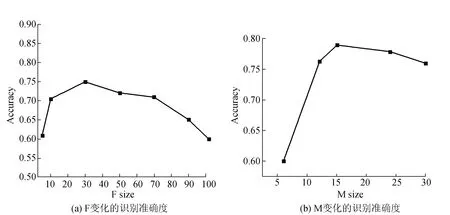





6 结 论
猜你喜欢
电子制作(2019年15期)2019-08-27电子制作(2018年19期)2018-11-14建筑科技(2018年6期)2018-08-30自动化学报(2017年11期)2017-04-04电子制作(2017年23期)2017-02-02中国交通信息化(2016年5期)2016-06-06西北工业大学学报(2015年4期)2016-01-19智能系统学报(2015年4期)2015-12-27噪声与振动控制(2015年4期)2015-01-01
