
基于模糊匹配的Lucene检索应用
2018-01-18 07:10钱柯
电子设计工程 2018年1期
钱柯
(江苏科技大学计算机科学与工程学院,江苏镇江214400)
随着互联网的发展,数据量呈现爆发式的发展,在海量数据中如何快速及时的查找到所需的信息已经成为一个重要问题。现在很多的站内搜索都是基于Lucene搜索引擎包完成的,包括目前流行企业级站内搜索所用的solr检索服务器,其底层也是基于Lucene。而在一些商用领域,Lucene也是作为其内部全文检索子系统的核心[1]。
目前,普通的全文检索在检索过程中往往只是对用户输入的查询语句进行简单的分词操作,然后将分词结果在索引库中逐一进行匹配,根据匹配出来的结果寻找到对应的文档,这样做的优点就是简单易操作,容易实现。缺点也很明显,对于用户输入的内容,没有进行有效的简单判断而直接进行分词然后去索引库中查找,这样做往往会降低检索的精度,本文提出了一种简单可行的基于模糊查询的Lucene检索,在原有的Lucene检索基础上,对用户的检索内容进行简单的错字纠错,增加了检索的精度。
国内出现的比较早的自动校对系统是啄木鸟系统,自动纠错的方式是通过对文本进行分词,由于文本中绝大多数的错误是出在单字词上,根据单字词的词频和其前后两个汉字的持续强度给单字词打分,然后将得分与一个预先设定好的阈值比较来判断该单字词是否为错字。马金山等人构建了一种多方法融合的中文自动校对模型,该模型以三元模型为基础,利用依存方法等特点分析文本中句子的依存,提供了一种新的思路和方法来处理全局错误。张仰森等人提出了一种基于规则和统计相结合的方法,根据统计分析大量正确文本后单字词出现的规律,提出新规则用来发现错误,并且结合了以单字散串建立的字二元、三元统计模型以及词性二元、三元统计模型,提出了文本自动查错模型与实现算法。
1 Lucene简介与搭建
1.1 Lucene简介
Lucene是Apache下软件基金会jakarta项目组的一个子项目,它是一个开放源代码的全文检索引擎工具包[9],原作者是DungCutting,曾经是V-Tim搜索引擎的开发者之一。由于商业引擎不开源,搜索结果不是单纯的根据网页本身的价值进行排序,比如最大的中文搜索引擎百度,其搜索出来的网页是通过竞价来排名的,因此,为了能够为各种中小型应用程序提供全文检索功能,DuungCutting在自己的主页上发布了Lucene,2001年年底Lucene成为了Apache的一个子项目,目前DungCutting从事INTERNET底层架构的研究。Lucene提供了完整的查询和索引功能,还提供了部分文本分析引擎,目前有很多Java项目都使用了Lucene作为其后台的全文检索引擎,比较著名的有web论坛系统图Jive,邮件列表HTML归档/浏览/查询系统Eyebrows,Java开发工具Eclipse等。
1.2 构建索引
Lucene采用的是反向索引机制。在反向索引中,文档中的每个词或者短语对应着一个文档列表[10]。Lucene索引的构建就是通过不同的解析器,对不同类型的文档进行解析,利用分词器(Analyer)对从解析结果中提取索引相关信息,组成若干的项(term)。项(term)是最小的单位,项(term)组成域(field),若干个域组成文档(document),若干个(document)组成段(segment),Lucene的索引index就是由若干个段组成。
1.3 搜索索引
Lucene的检索是通过IndexSearcher类来完成的,IndexSearcher类必须要Query对象作为其传入参数[3]。lucene提供了好几种不同的检索方式,如布尔查询(BooleanQuery),区间范围查询(RangeQuery),通配符查询(WildCardQuery)等等,用户通过构建所需的query对象,调用QueryParse类来实现Lucene内部查询语句,在索引库中查找到匹配的索引,根据索引值的信息,返回查询内容对应的文档位置。
1.4 分词器的选择
Lucene自带的分词器是ChineseAnalyer,这个分词器使用的是单字切分,单词切分会提高系统的召回率,降低准确率,比如“参加过世界杯”,如果用单词切分的话,搜索“过世”也可以命中该文档,显然这样不符合用户的需求。Lucene支持第三方分词器,通过对比,我们选择IKAnalyer,IKAnalyer是一个开源的,基于Java语言开发的轻量级中文分词工具包。它有很好的词典存储,更小的内存占用,采用了特有的“正向迭代最细粒度切分算法”,能够很好的支持中文语句的切分,而且IK分词器支持词典的扩充,使用者可以手动添加专有名词和停用词,IK分词器可以对使用者添加的专有名词不进行切词操作,过滤掉使用者添加的停用词。
2 Lucene检索系统的实现
2.1 精确匹配算法
普通的Lucene检索是基于精确匹配算法来实现的。精确匹配算法思想如下:
1)调用分词器对查询语句进行分词处理。
2)将分词后结果加入到查询条件query中去。
3)调用Lucene的查询语句在索引库中对搜索索引。
4)根据索引到的结果查询数据库,返回结果。
普通精确算法的不足之处就在于将查询语句分词后没做任何处理就加入到查询条件query中去,这样搜索的坏处在于搜索结果完全取决于分词结果,对分词器的选择依赖过大,因此我们可以对分完词的结果进行处理来优化匹配算法。
IK分词器会将所有可能的分词结果返回,这样会导致有些在索引时候匹配到某些不需要的索引。例如,对于语句“我去世界杯看球赛”可能会分成“我去世界杯看球赛”和“我去世界杯看球赛”,如果不对分词结果进行处理而是全部加入到查询条件中去,则会将含有“去世”的结果返回。对此可采取的策略有两种:第一种是通过在IK analyzer的ext.dic文件中手动加入专有名词,分词器就会选择将“世界杯”做为一个整体来切分。第二种则是修改IK analyzer的分词算法,正向最大匹配中文分词算法可以做到最大匹配而不是第一次匹配就进行切分。正向最大匹配算法的核心思想通过扫描分词文本,同时与词表中的词进行,当扫描到的分词文本既是词表中的词并且也不是其他词的前缀,则匹配出来的就是最大文本。具体算法流程本文不做详细介绍。
以上两种方法优化了精确匹配算法,能够提高匹配的精确度。然而,对于用户输入的查询语句,如果其中存在错字,可能就会影响到分词情况,进而影响到检索结果,因此为了进一步提高检索的正确率,我们引入模糊匹配算法。
2.2 模糊匹配
模糊匹配是为了解决用户输入的查询语句可能存在的错字现象而引入的匹配算法。Lucene检索中5个性能指标:查全率、查准率、响应时间、死链比率、索引库更新频率。其中查准率定义为搜索引擎检索结果中相关信息与检索结果的比[10]。为了提高查准率,首要的就是提高检索中相关信息量,而用户输入的内容是否有错字对检索的查准率有着重要影响。
设wi和wj是两个汉字,因为两个汉字之间可能存在音似和行似,因此本文定义两个汉字之间的相似度函数:

其中,psim和ssim分别表示分别表示两个汉字的音相似度和形相似度,α和β分别是参数,α+β=1。
文中对可能的错字根据上述公式计算出相匹配的汉字,通过预先设定好的阈值筛选出合适所有可能合适的值。先计算出常用汉字的sim(wi,wj)值,得到音似表和形似表。这样在获取每个汉字的相似字的时候,就能够直接从给定的音似表和形似表,通过比较阈值得到符合条件的所有汉字。现在假定一个字符串s=w1w2w3…wi-1wiwi+1…wn,其中wi是分词后的词语,prop(wi)表示wi的状态,prop(wi)=1表示wi是单字词,prop(wi)≠1表示wi是非单字词。result(wi,wj)表示wi与wj两汉字所有相似字的的笛卡尔积。
Step1.初始步:若i=1且prop(w1)=1,则直接获取result(w1,w2),返回结果。否则至Step2.
Step2.判断wi的prop(wi)的值直至prop(wi)=1,其中i+1≤n,获取result(wi-1,wi),匹配词典中的所有词,返回所有匹配成功结果,否则获取result(wi,wi+1),再次匹配词典,返回匹配成功结果,否则至Step3.
Step3.重复计算result(…(result(result(wi,wi+1),wi+2))…wn)直至能够在词典中匹配出正确的词,返回结果,否则退出匹配,返回空值。
模糊出来的所有结果再与索引库进行匹配,这样就能返回所有匹配到索引值。根据索引值,检索出所有可能的记录。
3 模糊匹配在Lucene检索中的应用
3.1 实验语料
海工案例装备知识库管理系统中的检索分为简单搜索和高级搜索都是通过Lucene来搭建的,其数据量达到百万条数据,用户根据实际情况选择检索条件,下面就用户输入的查询条件,对比精确匹配和模糊匹配之间的搜索效率,以及模糊匹配的准确率。
3.2 实验结果
本实验的评价以召回率、准确率和F-Score作为评价标准。评价指标定义如下:

用本文所提出的方法对测试集进行实验,各指数如表1所示。
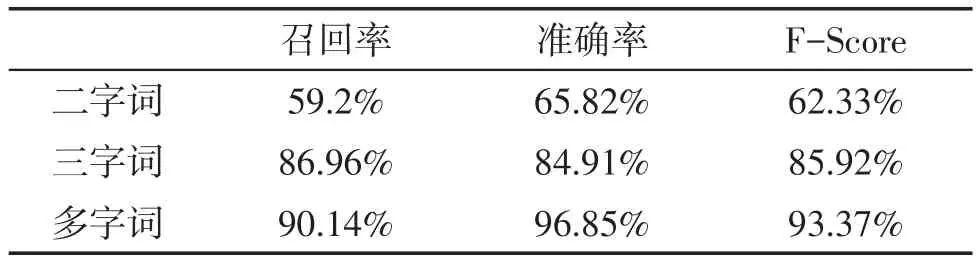
表1 本实验评价指标
本实验的部分实验结果如表2和表3所示,表2表示wi+1是单字词的情况,而表3表示wi+1是多字词的情况。其中×表示该条结果误纠,√表示正确。可以看到,目前在检索中,需要模糊的分两种情况,wi-1为多字词,wi和wi+1都是单字词。wi-1和wi+1为多字词,wi是单字词。只要当我们在索引库中匹配出索引的时候,就停止模糊,返回匹配出来的索引值。之所以这么做,是因为模糊的过程是一个对所有模糊结果求笛卡尔积的过程,如果一直模糊到最后的wn,那么最后可能是导致模糊出来的结果集过大,逐一去匹配可能会严重影响到检索速度,这会影响到用户体验。

表2 wi+1是单字词

表3 wi+1是多字词
现在将上述的模糊算法加入到Lucene检索中,对于用户的查询,调用第三方分词器IKAnalyer,将用户给出的查询语句进行分词。由于Lucene检索对于索引库中不存在的索引直接返回null,而加入的模糊匹配之后,由于遍历音似词典,因此匹配索引的时候有了更多选择,检索结果有明显的效果。
4 结论
通过研究Lucene在海工案例装备系统中检索准确率问题,在原有的基础上加入了模糊匹配算法,这样能够对用户输入的查询语句施行纠错功能,提高了检索的正确率,改善了用户体验。但目前的匹配算法存在匹配数据过大、检索速度变慢、准确率仍然不够高等问题,针对这些问题,将进一步进行研究,改进模糊算法的时间复杂度,加快检索速度,改善用户体验。
[1]马晖男,吴江宁,潘东华.一种基于同义词词典的模糊查询扩展方法[J].大连理工大学学报,2007(3):439-443.
[2]周登朋,谢康林.Lucene搜索引擎[J].计算机工程,2007(18):95-96,118.
[3]胡鹏飞.Lucene与中文分词技术的研究及应用[D].北京:北京交通大学,2010.
[4]姜华.基于Lucene面向主题搜索引擎的研究与设计[D].上海:华东师范大学,2007.
[5]柴洁.基于IKAnalyzer和Lucene的地理编码中文搜索引擎的研究与实现[J].城市勘测,2014(6):45-50.
[6]刘平冰.基于Lucene的Web站内信息搜索系统[D].成都:电子科技大学,2005.
[7]王庆文,裴彦纯,周建慧,等.一种本体与Lucene融合的工艺知识检索方法[J].制造业自动化,2015(23):151-156.
[8]姜元爽,谭培,刘馨元,等.基于Lucene的垂直搜索引擎的设计与实现[J].福建电脑,2015(12):21-22.
[9]罗宁,徐俊刚,郭洪韬.基于Lucene的中文分词模块的设计和实现[J].电子技术,2012(9):54-56.
[10]胡长春.基于Lucene的中文自然语言搜索引擎[D].上海:上海交通大学,2009.
[11]朱蓉.基于模糊理论的查询技术研究[J].计算机应用研究,2003(5):8-10,29.
[12]李建华,王晓龙,王平,等.多特征的中文文本校对算法的研究[J].计算机工程与科学,2001(3):93.
[13]张仰森.基于二元接续关系检查的字词级自动查错方法[J].中文信息学报,2001,15(3):36-43.
[14]李永春,丁华福.Lucene的全文检索的研究与应用[J].计算机技术与发展,2010(2):12-15.
[15]白晓玲.Lucene全文检索系统的实现及其索引性能的提高[J].情报探索,2010(1):116-118.
[16]冯宇.基于模糊层次分析法的Lucene网页排序算法研究[J].计算机与现代化,2011(1):124-126.
[17]周凤丽,林晓丽.基于Lucene的Web搜索引擎的研究和实现[J].计算机技术与发展,2012(1):140-142,160.
[18]秦杰,宋金玉,张广星.基于Lucene的本地搜索引擎研究与实现[J].计算机科学,2014(S2):368-370,407.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
邯郸学院学报(2020年2期)2020-08-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中华诗词(2016年11期)2016-07-21
现代语文(2016年21期)2016-05-25
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
技术经济与管理研究(2014年11期)2014-03-11
西南学林(2013年1期)2013-11-22
