
基于spark框架的DBSCAN文本聚类算法
2018-05-28 07:15宁建飞
汕头大学学报(自然科学版) 2018年2期
宁建飞
(罗定职业技术学院电子信息系,广东 罗定 527200)
0 引言
随着互联网以及计算机存储技术的发展,每天产生的数据正在以PB级的速度增长,文本数据是一类非常重要的数据格式,包含了非常多的信息,将文本数据分门别类将有助于人们快速的进行信息检索.在大数据技术日渐成熟的环境下,将机器学习算法应用于分布式环境中已经成为了一种趋势,通过分布式的计算力将算法的效率提高.机器学习中的聚类算法是处理文本的一种经典解决方案,其中,基于密度的DBSCAN算法以其收敛速度快,易于发现噪声的优点而常常被应用于内容过滤、异常数据检测等各种场景.
近年来,针对DBSCAN算法在单机上的计算瓶颈,国内外学者对DBSCAN聚类算法进行并行化的研究.何中胜等[1]提出了在主机集群上运行基于数据分区的并行化PDBSCAN,降低了算法运行的时间,提升了聚类的性能,但是I/O消耗仍然比较严重.宋明等[2]提出了基于数据交叠分区的并行OPDBSCAN,减少了节点之间局部簇合并时的通信量,但是聚类质量下降.但是以上两类并行化算法在高纬度数据时效率不明显.为了应对高维数据,MR-DBSCAN[3]提出了基于MapReduce平台下的DBSCAN并行算法,通过数据划分的方法,解决了海量的低维数据集,在进行数据划分时产生的负载问题,然而,高维数据的问题还是没有能够得到解决.SNN相似矩阵的出现解决了高维度数据相似度定义模糊的问题,JP[4]聚类算法就是利用了SNN相似矩阵进行聚类.本文结合SNN相似度的定义以及MapReduce计算模型将DBSCAN聚类算法在Spark平台上进行改进,并且应用于文本聚类上.
本文主要研究DBSCAN聚类算法在spark数据处理平台的应用,在进行文本处理时,引入了SNN相似度的概念使得DBSCAN聚类在文本数据上有效,并且将SNN相似度结合到DBSCAN中并行化.SNN相似度算法并行化将形成多个K近邻子矩阵,将其合并后能够计算出SNN密度,从而得到文档之间相似度的度量,再进行DBSCAN算法的聚类并行化,通过数据划分,使得每一个工作节点进行DBSCAN局部聚类,在将局部聚类结果合并,从而达到DBSCAN文本聚类的目的.本文算法将DBSCAN聚类算法应用在spark平台上,速度相比于单机的DBSCAN聚类[17]以及基于Hadoop平台的DBSCAN聚类均有不错的提升.
1 相关工作
1.1 SNN相似度图
共享最近邻(SNN)相似度适用于高维数据之间的相似度计算.它的核心思想是:两个数据对象假设互为共享最近邻,则相似度为两个数据对象的K近邻邻居对象中相同数据的数目.如果两个对象共享最近邻点的数目越多,那么这两个对象的相似度就越高,这两个对象归为同一类的可能性越大;如果两个对象不是在对方的最近邻表中,那么这两个对象的相似度为0.相似度的计算公式如式(1).
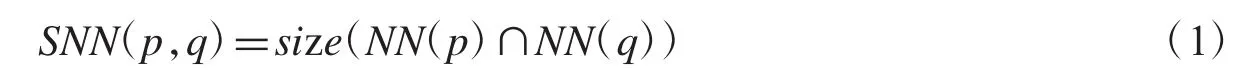
NN(p)和NN(q)分别是对象p和对象q的最近K邻近表.
SNN相似度只依赖于两个数据对象间共享的最近邻对象个数,而不是最近邻对象的距离,由于SNN相似度反映了数据空间中点的局部结构,因此它对密度的变化和空间维度不敏感,所以SNN相似度可以用来作为新的密度,尤其是在高维数据的相似性比较上,SNN非常适用.
1.2 DBSCAN聚类算法
DBSCAN聚类算法是经典的基于密度的聚类算法,该算法有两个重要的参数,一个是全局密度半径Eps,一个是密度阈值MinPts,它的核心思想是聚类中的每一个核心对象,在某个密度半径内数据对象大于某个密度阈值.给定一个数据集0,1,2,…n},对于任意点 p(i),计算点 p(i)到集合中的剩余点 p(1),p(2),…,p(i-1),p(i+1),…p(n)的距离,将距离按照从小到大的顺序进行排列,则第k个点的距离称为k-dist,对集合中的每个点都需要计算k-dist,最后得到一个所有点的k-dist集合.在得到k-dist集合之后,对k-dist集合进行升序排序,然后拟合一条排序后的k-dist集合中k-dist的变化曲线,画出曲线进行观察,将曲线突变的位置所对应的的k-dist的值作为半径Eps的值.根据经验定义一个密度阈值MinPts来作为计算使用.在迭代结束之后,如果聚类结果不理想可以适当地调整Eps和MinPts的值,再进行迭代计算,在进行多次迭代计算对比之后,选择比较合适的参数.如果Eps取值过大,则会导致同一个聚类簇中包含太多的点,如果Eps取值过小,则会导致聚类簇过多;如果MinPts取值过大,则会发现同一簇中的点被标记为噪声点,如果MinPts取值过小,则会导致核心点的数目增多.因此,合理的选择两个参数是这个算法的关键步骤之一.
DBSCAN算法的具体步骤是:
(1)预处理数据文件;
(2)计算每个点与其他所有点之间的距离;
(3)计算每个点的k-dist值,并且对所有点的k-dist集合进行升序排序,输出排序后的k-dist值;
(4)绘制 k-dist图;
(5)根据k-dist图确定密度半径Eps;
(6)给定MinPts,计算核心点,并且建立核心点与核心点距离小于密度半径Eps的点的映射;
(7)计算连通的核心点,并且将噪声点去除;
(8)将每一组核心点和到该点距离小于半径Eps的点,放在一起形成一个聚类簇.
DBSCAN算法通过将高密度的区域聚成簇,并且可以发现任意形状的簇,有效地处理噪声数据.但是在DBSCAN算法中也有着明显的缺陷,即参数Eps的选择对聚类结果的影响非常大,并且目前还没有完善的解决方案.在绘制k-dist图时,DBSCAN算法将会耗费大量的时间,并且当数据量增大时,内存和I/O消耗将会激增.
1.3 Spark框架
Spark是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的并行计算框架.Spark框架的计算基于内存运行,并且提供了一种分布式的并行的数据结构-弹性数据集RDD(Resilient Distributed Datasets).Spark使用Scala编写,Spark可以和Scala集成,使得Scala可以灵活的操作分布式数据集.Spark支持分布式数据集的迭代算法,可以集成于Hadoop的文件系统之上,因而构建于Spark上的算法处理大规模的数据非常方便和迅速.
在Spark框架被设计出来之前,处理大数据的解决方案是Hadoop,Hadoop以其分布式的MapReduce程序著称,可以计算PB级别的数据,但是Hadoop也存在着明显的瓶颈,当算法的复杂度增加,迭代次数上升,那么基于Hadoop的MapReduce框架就会不停的进行磁盘的IO,因为每一次迭代的计算结果都需要写回磁盘然后再读到内存做下一次的迭代计算,这无疑提高了时间成本,而新一代的计算框架Spark则大大的节省了时间成本,它在迭代计算过程中并不将数据写回磁盘,而是保存在内存中供下一次计算使用,减少了磁盘IO,并且Spark框架并不仅仅在于内存计算,它还可以将整个执行计划解析成一个DAG(Directed Acyclic Graph)图,每个节点是一个stage,然后可以自动的对stage进行优化,使得效率提升.
RDD是Spark一切的基础.RDD是一个分布式的内存抽象,数据在各节点中分区,而RDD则是分区的集合.RDD来源广泛,可以从集合中转换而来,也能从HBase数据库中读取,更可以从Hadoop文件系统中读取.在每一个分区数据上都会有一个程序函数去对这些数据进行计算,并且RDD之间会产生依赖关系,RDD可以生成新的RDD.Spark的设计延续了Hadoop许多优秀的理念,比如数据就近读取等等.Spark处理数据的流程图如图1所示.首先从文件系统中读取数据集,然后Spark程序两个核心步骤:转换和执行.转换是一个延迟执行过程,程序只被记录但是不执行,知道Action真正触发才会执行程序.
随着Spark的发展,Spark框架已经渐渐超过Hadoop成为大数据的首选解决方案,将机器学习算法并行化到Spark上已经有许多的成功的例子,例如Kmeans,SVM,贝叶斯分类等等,这些算法很多都已经成为Spark MLlib的工具类.在国内外学者的推动下,Spark MLlib库也将会越来越丰富.
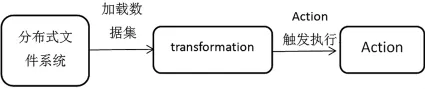
图1 Spark程序执行步骤
2 DBSCAN算法的并行化实现
传统DBSCAN聚类算法计算速度快,但是在处理多维度的数据时,密度定义模糊,因此DBSCAN算法在高维数据上的聚类效果不佳,并且随着数据量提高,运算时间激增,会影响聚类的质量.针对以上的问题,本文引入了文献[4]中的SNN相似度来改进DBSCAN算法,使之能够适应高维的文本数据,并且通过生成SNN密度,每个节点计算数据集的子连通图,也就是进行DBSCAN局部聚类,每个节点计算完了之后进行一次全局的合并,从而达到算法的并行化,使用Spark的RDD可以减少大量的I/O,并且大大的提升了迭代的速度.
2.1 基于SNN相似度的DBSCAN聚类
SNN相似度是基于JP[4]算法实现的,根据文本的数据,JP算法的数据输入文档-权重矩阵,每一行都是一个文本形成的向量,每个向量中的元素等于特征项的权重.基于SNN相似度的DBSCAN算法采用SNN相似度来作为聚类的依据,具体步骤如下:
(1)计算相似度构造邻近度矩阵;
(2)根据K最近邻将邻近度矩阵稀疏化;
(3)构造SNN图;
(4)根据SNN图计算SNN密度;
(5)使用DBSCAN聚类算法根据SNN密度进行聚类算法的核心点在于SNN最近邻表的创建.
2.2 DBSCAN算法的并行化
Spark框架中的RDD底层接口中有非常多的接口是基于迭代器的,在Spark中运行程序能够避免非常多的磁盘I/O操作,计算效率大大的提高.并且Spark提供了缓存和分区供用户对RDD控制,例如将某些数据缓存起来,从而提高执行的性能.
由于文本数据量比较大,本文对一些细节进行了优化,采用了Kryo序列化方式来取代默认的Java序列化方式,提高了效率.
算法是基于MapReduce模型的,master服务器负责分配数据块,map任务之间互不影响,并且以[key,value]的形式传递给reduce,reduce对中间结果进行进一步的计算.
本文针对DBSCAN算法主要并行化的过程分为两步:一是构建SNN相似度,二是DBSCAN算法的并行化.文本数据预先进行分词、去除停用词等等清洗工作.
2.2.1 SNN相似度算法并行化
Map阶段每一个map完成一部分数据的邻近度计算,假设INDEX是起始文档的下标,SIZE是该map中处理的文档个数.Map阶段的伪代码如下:

reduce阶段所做的工作比较简单,只需要将部分的KNN矩阵合并在一起,最终输出一个全局的稀疏化矩阵K,生成的稀疏化矩阵可以计算出SNN密度,可供下一阶段的DBSCAN算法中使用,并且在spark中,可以利用广播变量将SNN密度在每一台节点上做一个只读的缓存,从而在下一步,节点内部可以进行局部的DBSCAN聚类.因为文档与文档之间的相似度已经得到了度量,因而在接下来的聚类中,文档聚类等价于点聚类.
2.2.2 DBSCAN聚类并行化
数据划分:为了提高计算效率,是DBSCAN算法并行化,对数据进行均匀的划分是非常必要的,由于在上一步已经得到了SNN密度,文档空间的特征不明显,因而选择均匀地划分,这样牺牲了一点性能,但是对总的运行速度影响不大.
局部聚类:数据划分好以后,每一个划分好的数据会由master节点分发到一个计算节点worker上,worker节点根据广播变量SNN密度,选取一个局部的Eps值.再通过SNN密度得到文档之间的相似度,然后采用DBSCAN算法对节点中的数据进行局部DBSCAN的聚类.
局部聚类合并:在所有数据分区聚类完成了之后,必然会存在着全局性不足的问题,因此,需要对局部聚类进行合并.有以下三类的数据需要进行合并:
(1)两个类本属于同一个类,但是由于在不同分区,被分成了两个类.这种情况需要满足:两个类的数据处于相邻分区中并且两个类别中任意两个的边界区域点之间的相似度应当不小于两个类的Eps.
(2)某类中的噪声点本应属于另一个类,但是由于处于另一个分区而导致被判别为噪声数据.假设A类中的噪声点p属于另一个类B,则应该满足B类中的任意数据点q与p的相似度不小于B类的Eps,并且A,B类处于相邻的分区.
(3)一些小类中的数据由于被分散而且数量少,导致都被视作成了噪声数据,那么这些数据应该被归为新的一类.归类的条件应当满足:假设A,B是两个相邻分区的类,EA,EB分别为他们的边界区域点集,S为EA,EB的噪声点集.如果存在S中的某个点p,p与S中点相似度不小于A,B的Eps的数量大于MinPts,那么可以认为p是新的核心对象,其他数据与p归为一类新类.
在并行化过程中,相邻分区之间需要互相发送边界区域点集以完成最后的局部聚类合并.在完成最终的聚类之后,需要根据结果调整Eps参数,得出最佳的聚类结果.
3 实验结果与分析
3.1 实验环境与数据集
本实验采用的云计算数据平台是apache开源的spark1.6.2版本以及Hadoop2.6.2版本,Hadoop提供HDFS存储以及yarn资源调度,spark提供计算框架.硬件环境为5个节点,1个 Namemode(spark的 Master节点),4个Datanode(spark的 Worker节点).Namenode节点的机器配置为:Intel Core I7-4720HQ,8G内存,500G硬盘,Datanode节点的机器配置为:Intel Core I5-4430,4G内存,500G硬盘.软件环境配置为:CentOS 6.5版本,JDK1.8.0_60,Scala2.11.8,InteliJ IDEA 14.1.5版本.Hadoop的安装配置方式为HDFS+HA的方式.
本实验的语料数据来源于网络新闻数据,通过爬虫抓取国际,体育,社会,娱乐等18个频道的新闻数据,共8 236篇文档.为了能够进行聚类分析,必须对语料数据进行预处理,通过分词、停用词过滤、特征降维和文本表示模型,转化成聚类算法能够处理的向量形式.文本预处理中采用的分词工具为中科院的自然语言处理工具HanLP,停用词表使用的是HanLP项目中的数据,文本表示采用向量空间模型对每个文本进行表示.
3.2 实验结果与分析
在Spark计算框架中对已经预处理的预料数据进行DBSCAN文本聚类处理,并且在聚类过程中对比不同的Eps值和MinPts值来选取最佳的聚类效果,最后通过单节点和多节点的运行时间、以及与Hadoop平台上相同节点数算法的加速比来检验算法的性能.加速比定义为算法在一个节点上的运行时间与算法在N个节点上的运行时间的比值.
从聚类结果分析,如表1,有部分文档并没有成功归类,被DBSCAN列为了噪点,并且有一部分文档归类不准确.通过表格可以看出,数据量过大,会导致聚类簇的增多.娱乐类的准确率较低,可能的原因有文档的特征代表性不够,使得区分度不够,使得娱乐类的文档归到了社会类之中;体育类的准确度较高,可能的原因是体育类的特征词代表性比较强,例如裁判,比赛,球员等等.但从总体来看,DBSCAN算法在spark平台上进行文本聚类还是可行并且有效的,能够将相似的文本归为一类.
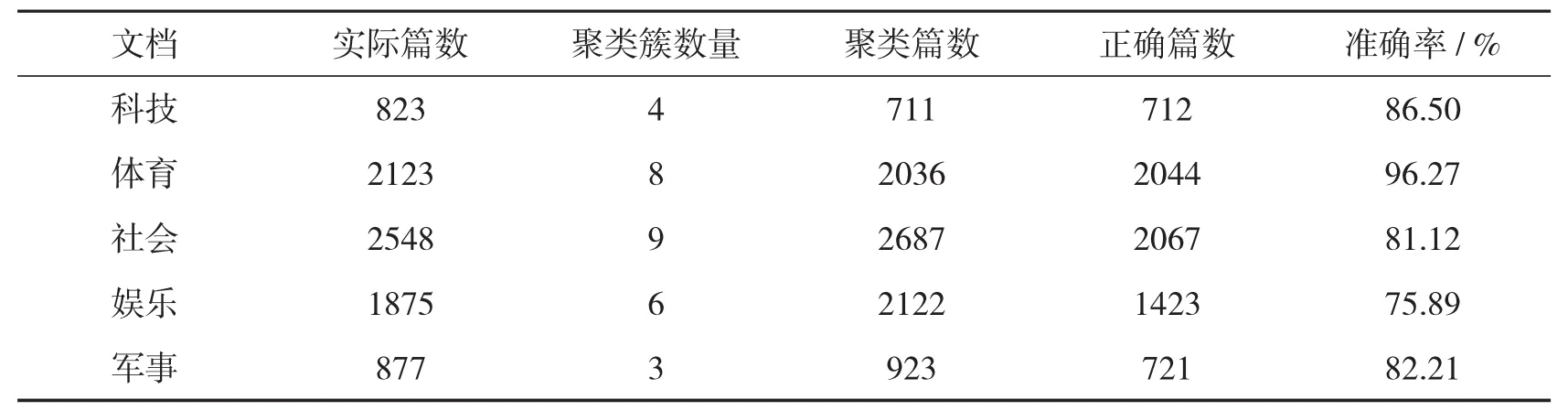
表1 聚类结果
通过图2的曲线可以看出,随着数据量的增大,spark环境下的运行时间消耗明显少于单机的时间消耗,并且多节点的运行时间随着数据量的增加并没有呈现出快速增长的趋势而单节点在随着数据量的增大出现了运行时间激增的情况,表明算法的并行化处理效率更高,性能更好.
由图3可得数据集在Spark框架下的加速比明显优于数据集在Hadoop框架下的加速比,并且随着节点数的增加,数据集在Spark框架下的加速比上升趋势也随着变换,这是由于节点间的通信量增加以及I/O次数增加导致的.由此可见,相比于Hadoop,DBSCAN算法在Spark框架下的表现更能适应大数据的环境,并且算法还有值得优化的地方,因而DBSCAN算法在Spark框架下的性能是可观的.
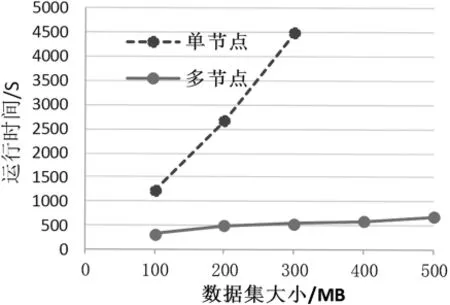
图2 单节点和多节点环境下的算法执行效率对比

图3 两种架构加速比比较
4 结语
本文针对基于密度的DBSCAN聚类算法内存和I/O消耗严重的问题以及当前的大数据背景,提出了基于Spark框架的并行化DBSCAN算法,并且对DBSCAN算法进行了改进,采用SNN相似度使其能够适应高维数据的聚类,有效的减少了内存消耗的问题以及提高了算法运行的性能.实验结果表明本文提出的算法相较于传统的DBSCAN聚类算法能够处理高维度的数据集,并且与Hadoop平台下的DBSCAN算法相比在文本聚类的时间有了明显的下降.但是由实验步骤可知,算法并未完全的并行化,数据的预处理步骤以及数据的存储在HBase上等步骤都需要额外执行,本文单从DBSCAN算法的运行时间分析,有明显的速度提升,下一阶段的工作希望能够将DBSCAN算法完全并行化,并且减少算法对参数的敏感度,增加自适应性.
[1]何中胜,刘宗田,庄燕滨.给予数据分区的并行DBSCAN算法[J].小型微型计算机系统,2006,27(1):114-116.
[2]宋明,刘宗田.基于数据交叠分区的并行DBSCAN算法[J].计算机应用研究,2007,21(7):17-20.
[3]HE Y B,TAN H Y,LUO W M,et al.MR-DBSCAN:An efficient parallel density-based clustering algorithm using MapReduce[C]//2011 IEEE 17th International Conference on Parallel and Distributed Systems,2011:473-480.
[4]JARVIS R A,PATRICK E A.Clustering using a similarity measure based on shared nearest neighbors[J].IEEE Transaction on Computer,1973,22(11):1025-1034.
[5]周水庚,周傲英,曹晶.给予数据分区的DBSCAN算法[J].计算机研究与发展,2000,37(10):1153-1159.
[6]郗洋.基于云计算的并行聚类算法研究[D].南京:南京邮电大学,2012.
[7]BECKMANN N,KRIEGEL H,SCHNEIDER R,et al.The R*-tree:an efficient and robust accross method for points and rectangles[J].International Conference on Management of Data,1990,19(2):322-331.
[8]于苹苹,倪建成,姚彬修,等.基于Spark框架的高效KNN中文文本分类算法[J].计算机应用,2016,36(12):3292-3297.
[9]邹艳春.基于DBSCAN算法的文本聚类研究[J].软件导刊,2016,15(8):36-38.
猜你喜欢
客联(2022年3期)2022-05-31
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
中国新闻周刊(2021年26期)2021-07-27
世界科学技术-中医药现代化(2021年10期)2021-03-02
电脑爱好者(2017年7期)2017-05-06
人间(2015年11期)2016-01-09
燕山大学学报(2015年4期)2015-12-25
