
基于ELM的网络流量分类及可视化研究
2018-06-07 01:56陈幸如魏书宁
安徽师范大学学报(自然科学版) 2018年2期
陈幸如, 魏书宁
(湖南师范大学 信息科学与工程学院,湖南 长沙 410081)
近代社会,由于科技的迅速发展,互联网的使用越来越普遍,使用范围越来越广,随着互联网的普及,大数据的云分布式处理技术成熟地发展,网络应用多元化已成为趋势。网络流量激增并且呈现多样化给网络管理带来挑战和压力,提高了网络流量管理的难度。网络流量分类在维持网络高效运行、预测网络服务类型和维护网络安全等许多方面发挥着越来越重要的作用。在TCP/IP协议中,端口号是应用程序识别通信的服务器和客户端的手段。源端口和目的端口皆为十六位的非负整数,它的范围是1至65535。一个客户端想要与服务器进行通信,需要一个端口号用来发送服务请求从服务器获得所需服务。根据LANA定制的知名端口号和注册端口号列表,LANA管理局规定的通信机制进行网络流量识别是基于端口网络流量识别技术的本质。传统的基于端口号以及网络载荷[1]的网络流量分析有其自身局限性和许多不可靠的因素,例如流行的P2P等新型网络应用利用随机,动态端口进行通信;还有一些采用隧道协议封装技术的应用。这些措施使得传统的网络流量分类方法失灵。不断更新发展的网络应用使利用端口进行网络流量分类技术的短板逐渐暴露。为了克服这些不足,已经应用在众多领域的机器学习方法引起了众人的关注[2][3][4],机器学习[5][6]不依赖于端口号匹配和协议的解析,利用流特征对网络流量数据进行分类[7]。目前,基于网络流量统计特征的识别方法是一种新兴的网络流量分类方法,利用数据挖掘中机器学习算法,提取不同网络协议的统计特征,通过分类算法来训练网络流量分类模型。这种方法可以随着网络应用的更新重新训练新的分类模型。本文采用新加坡南洋理工大学黄广斌教授等人在2006年研究出的超限学习机(Extreme Learning Machine,ELM)算法,在基于ELM算法上探究网络流量分类,并对网络流量做出可视化数据分析。
1 基于机器学习的网络流量分类
1.1 ELM算法理论
神经网络是一种有监督机器学习,基于已标注类型的样本集进行机器学习并建立分类规则,将未知数据分类成已知的类型。传统的神经网络算法有着各自的缺点,比如:训练速度慢、网络更新迭代计算中容易陷入局部极小点、学习率敏感等。训练网络要想获得较好的性能,需要探索出一种训练快速、能达到全局最优解、具有良好泛化性的训练算法,这些性能目标也是现阶段研究的热点与难点。
超限学习机(ELM)算法是一种单隐层前馈神经网络(SLFNs)。ELM算法与传统BP神经网络不同点在于ELM算法的输入层与隐含层的连接权值w和隐含层神经元的阈值b都是随机产生的,由于后期训练中无需更新w和b,这个网络中无需设定过多的参数,只要确定了隐含层节点数便可获得唯一最优解。ELM的理论如下:
假设SLFNs有L个隐含层节点,对于输入向量x,SLFNs的输出可以由(1)式表示。其中,Gi是第i层隐含层节点激活函数,ai是连接输入层与第i层隐含层节点的输入权值向量,bi是第i层隐含层的偏置,βi是输出权值。
(1)
对于激活函数g的附加节点,Gi定义为(2)式:
Gi(x,ai,bi)=g(bi+ai·x)
(2)
对于具有激活函数g的径向基函数节点,Gi定义为(3)式:
Gi(x,ai,bi)=g(bi‖x-ai‖)
(3)
黄广斌等人[8]已经证明了SLFNs可以逼近任意随机初始化自适应或者径向基函数节点的x∈Rd子集上的连续目标函数,随机生成的网络以最小均方得到的输出能够保持泛化逼近能力,甚至没有隐含层参数的更新。除此之外,ELM解决正则化最小二乘问题比标准支持向量机下解决二次规划问题或者梯度方法更快[8][9]。基于这种理论,ELM以快速学习而建立。从学习的角度来看,不同于传统学习算法,ELM理论旨在不仅达到最小训练错误而且达到最小规范化输出权值。
ELM算法不仅拥有良好的泛化性能,并且还具有通用逼近以及分类能力。相比于传统的神经网络算法,ELM不需要设置学习率,得到的输出权值是全局最优解,不会陷入局部最小值中且计算量小、训练速度快。这些优点是ELM算法被广泛地应用于模式识别、人机交互、疾病诊断、卫星图像实时远程遥感和网络安全等领域的原因。
1.2 H-ELM框架
H-ELM(Hierarchical ELM)是一种建立在多层方式上的算法,在随机特征映射和充分利用ELM的泛化逼近能力的基础上发展。如图1所示,可以看到H-ELM训练框架在结构上可以分为2个独立阶段:无监督分层特征表示和监督特征分类。在前一阶段,是用于提取输入数据多层稀疏特征的基于自编码的ELM。后一阶段原始分类ELM用于最终决策。
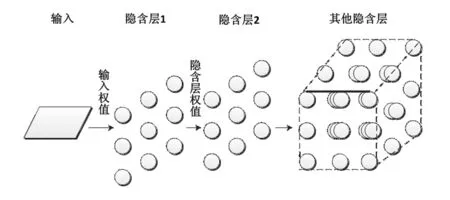
图1 H-ELM结构框架
输入的原始数据被转换至ELM随机特征空间,每一个隐含层输出可以表示为
Hi=g(Hi-1·β)
(4)
其中Hi是i层的输出,Hi-1是第i-1层的输出,g是隐含层激活函数,β是输出权值。H-ELM的每一层都是一个独立的模块,每一层的功能相当于功能提取器,随着层数的增加,特征会更加紧凑。一旦前一隐含层的特征被提取,本层的权值和参数被固定。
1.3 基于流统计特征的ELM流量分类
已知数据中网络流数据集合F={F1,F2,…,Fn},网络流的类型集合T={T1,T2,…,Ti},利用pandas整理的一个n×(i+1)的.csv文件作为输入分类器的样本数据。其中,n为网络流数目,i为流属性数目。根据统计的流特征,利用已知的网路流类型集合去训练ELM分类模型;选取适应ELM分类模型需求的流特征作为输入继而拥有更加精确快速的预测输出是流统计特征这一工作的意义。
分类实验中,流量在通信过程中展现出的网络流按照五元组进行定义:源IP、目的IP、源端口、目的端口和传输文件长度,分类算法执行步骤概括如下:
(1)输入训练样本,样本个数为Q,设置隐含层节点数L,选择激活函数g(x)为sigmoidal函数。
(2)随机生成权值w和阈值b。
(3)计算隐含层输出矩阵H:
(4)获得隐含层与输出层间的连接权值β。
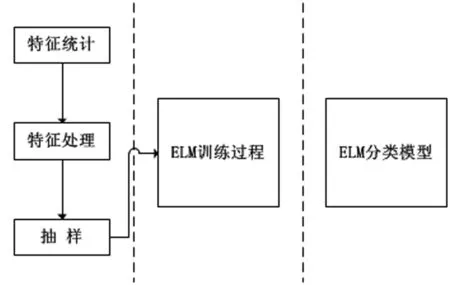
图2 基于ELM流量分类训练过程
流量分类过程可以概括为图2所示。先对数据集提取网络流量统计特征,如果训练集数目过大则需要进行抽样处理以减少训练时间,降低训练复杂度。
2 数据可视化
绘图是数据分析工作中的最重要任务之一,是探索过程中的一部分。数据可视化旨在清楚明了地提供信息,通过图形化手段将复杂的数据模型表达出来,将数据的属性从各个维度观察和分析,直观地表示出数据,使数据中的规律可以被洞悉。数据可视化是一个新术语:它传达出的含义不仅仅是用图表的形式展示数据,更多的是数据背后的信息被揭示,图表的本身应该帮助人们看到数据结构。
目前,开源的编程工具例如:R语言、D3.js、Tableau和python的各种工具类库等使得数据可视化由单一的表示形式演变为数据运算与图表的融合。
3 实验方案及结论
3.1 实验数据及环境
本文采用的是CHINAVIS提供的BigBusiness公司的骨干通信链路上抓取的数据包。该数据集包含了数据链路层、网络层和应用层的相关信息,数据共有2626937条,与只关注网络层活动的传统tcpflow数据不同的是此网络监控日志更加丰富全面,可以更好地、多层次多角度反应数据在网络中的流动过程。
在IP网络,应用层负责将需要传输的数据拆分为一个或多个数据包,应用层的数据项有:ID(记录序号)、IPSMALLTYPE(IP业务类型,主要是TCP和UDP),FILELEN(本次网络连接传输数据的总长度)、FILEAFFIX(本次网络连接传输文件类型)和ISCRACKED(数据是否损坏)共计5个维度。网络层负责建立源地址和目的地址之间的逻辑连接,网络层的数据项有:STARTTIME(开始时间)、SRCIP(源地址)、DSTIP(目的地址)、SCRPORT(源端口)和DSTPORT(目的端口)共计5个维度。数据链路层负责为逻辑链接建立传输通道,数据链路层的数据项包括:VPL1,VPL2和ATMAAL1TYPE。VPL1和VPL2是虚拟管道的标识,ATMAAL1TYPE是这个虚拟线路中传输数据的属性。
由于数据集中存在有少量缺失值数据,实验首先对网络流量进行了数据清洗。数据清洗完成后对数据进行了数据集成,将多个数据源合并存放在一个一致的数据存储中。同时进行的是数据转换和规约。数据转换主要是对原始数据进行规范化处理,将数据转换成适当的形式以适应于数据挖掘和ELM算法的需要。数据规范化即归一化处理数据,不同指标往往具有不同量纲,数值之间差别可能很大,而这些会影响数据分析的结果。
实验中,网络流量数据的特征统计、绘图等数据分析方面的工作使用的是Python2.7.13,涉及的模块有:numpy,pandas,seaborn,matplotlib等;使用MATLAB R2014b做基于ELM算法的网络流量分类工作。
3.2 实验设计和可视化
根据不同的目的选择不同的特征作为分类依据,为了使实验更具有针对性,选择合适的网络流量特征是极为重要的。如表1所示,从不同角度分析数据,实验中可以统计的特征有很多,基于BigBusiness两个月的网络监控日志数据,对内部网络的通信进行分析,本实验选取了以下4种网络流量特征对服务器进行筛选:
1.主机通信频率
2.主机传输文件长度
3.协议类型
4.传输文件类型
为了找出BigBusiness内部网络的服务器,对选取的网络流量特征使用python中pandas模块的Series和DataFrame进行切片处理,合并、统计整理好作为超限学习机算法的训练集和测试集。作为ELM算法的输入,训练集和测试集共有7个维度:标签、源IP地址主机通信频率、目的IP地址主机通信频率、主机发送数据的长度、主机接收数据的长度、协议类型代号和传输文件类型代号。

表1 网络流量特征统计
3.2.1 基于ELM算法的分类实验 经过ELM网络训练、分类、测试,实验中本文在设置隐含层节点数时,以10作为起始数,共做了10次实验,输出为ELM训练的时间和分类的精度。输出结果如图3所示。
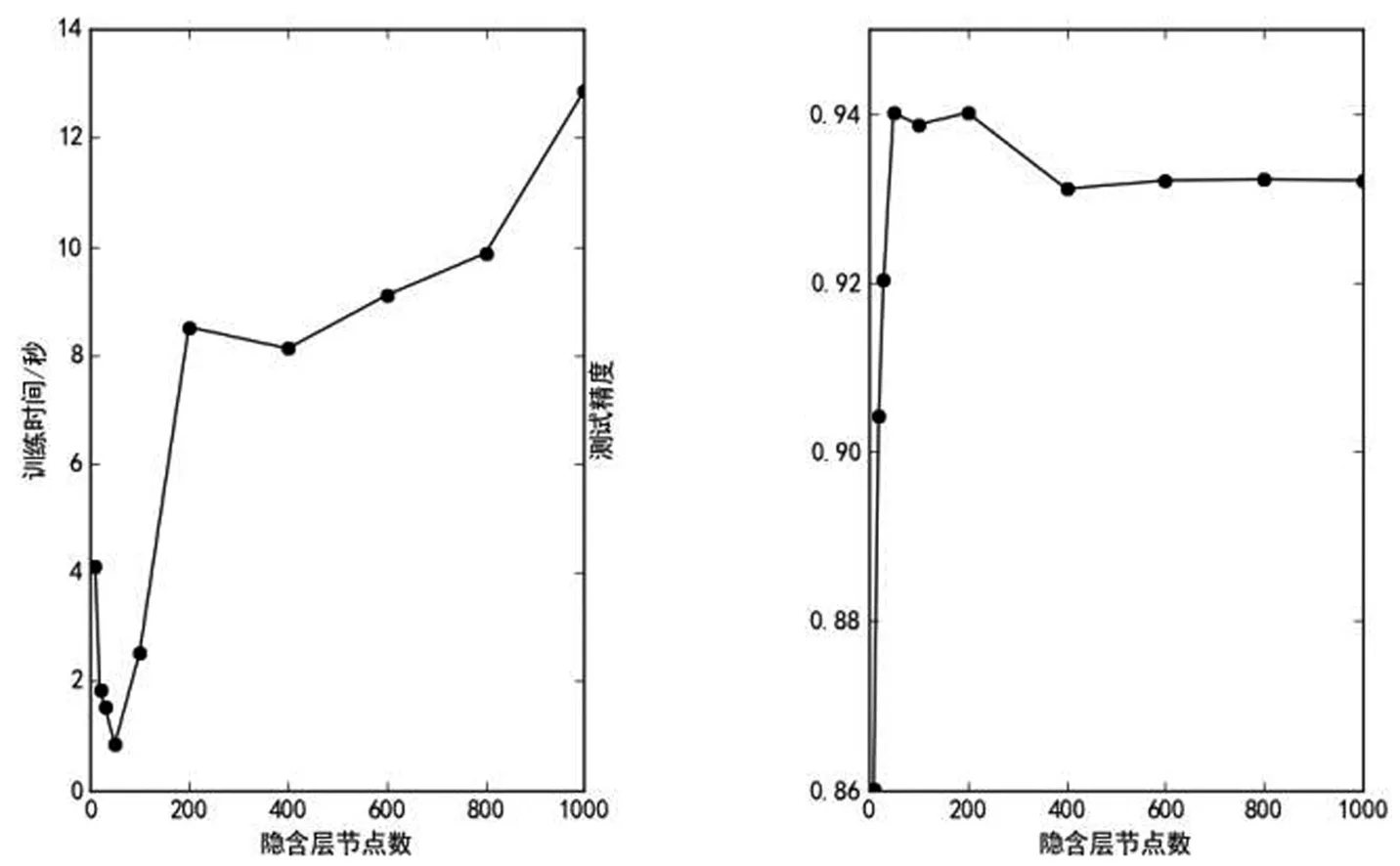
图3 ELM分类器的输出结果图
由实验结果可知,超限学习机这种算法训练时间短,训练速度十分快且它的精度非常高。随着隐含层节点数的增加,训练时间会少许变长,然而并不是隐含层节点数越多时,ELM的精度越高,在针对本次实验的两种网络流量特征的分类上,当节点数为50时,精度达到最高为94.01%且由图3可知,其训练时间也是处于最低点处的。这些优势证明了ELM算法可以很好地应用于网络流量的分类。
3.2.2 基于H-ELM算法的分类实验 在实验中,主要是超参数的选择,参数C是为了正则最小均方计算,参数L是隐含层节点数。对于两个参数的选择,C值的选择需要谨慎,L值应该选取得足够大。一方面,随着L值的增长,一个合适的C值使测试精度曲线更加平缓。如图4所示。另一方面,不同的L值对于测试精度的影响并不大。如图5所示。
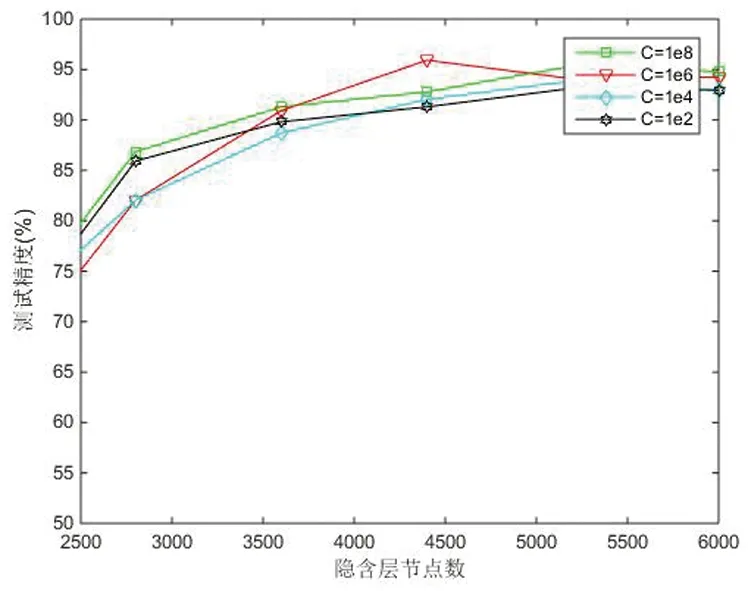
图4 H-ELM参数的选择对测试精度的影响
图5 隐含层节点数对测试精度的影响
3.2.3 基于传统神经网络算法的分类实验 徐鹏等人[10]提出的基于支持向量机的流量分类方法中,利用非线性变换将流量分类问题转换为二次寻优问题。基于支持向量机的流量分类方法不依赖于样本空间分布,稳定性强。但是,此方法用的数据集流特征过多,流特征过多会导致计算复杂度增加,在实际应用中有过多的计算负荷。李平红等人[11]提出一种基于支持向量机的半监督网络流量分类方法,此方法引入增量式学习,使学习精度随着新样本的增加而提高;引入半监督学习[12]降低人工标记样本的错误率和成本。然而,此方法训练时间长。SVM方法在网络流量大规模样本分类实际应用上体现了其建模时间长,训练时间成本高的缺陷。
为了更好地与ELM分类器进行对比,本文将网络流量数据输入传统BP(Back propagation)神经网络算法中,利用BP神经网络算法对同样的网络流量进行分类实验;在同等条件下将数据输入SVM算法中,对比实验结果如表2所示。
由对比实验结果可知,ELM算法在分类实验中展现了其建模时间短、训练速度快且分类精度高的优势。对于传统的机器学习算法,例如BP神经网络和SVM,虽然SVM算法的分类精度很高,但其建模和训练的时间消耗是巨大的;而对于传统的BP神经网络算法来说,它的缺点是非常明显的,实验结果显示:BP神经网络算法作为分类器的算法表现出建模时间长、训练速度慢且分类精度较低。不适用于大规模网络流量数据的分类和实际应用。
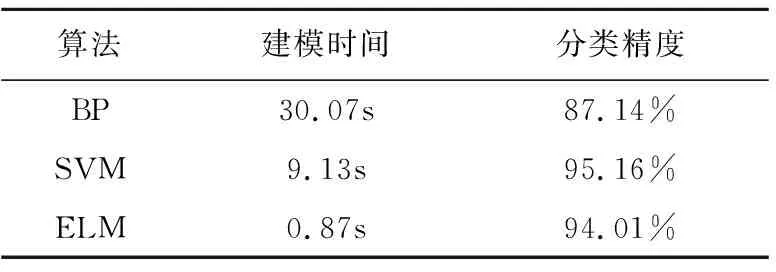
表2 ELM算法与其他传统学习算法的对比试验结果
3.2.4 可视化分析 由基于ELM算法分类后的结果,实验找到了数据集中的服务器。本文利用可视化来展示ELM算法分类后的主机网络流量特征:
(1)从主机的度的角度来看,选取了前50个服务器的出度和入度如图6和图7所示,坐标轴横轴为度,纵轴是服务器IP地址。从图6和图7可以看出有的服务器的出入度相差不大,但有的服务器出入度相差很多。
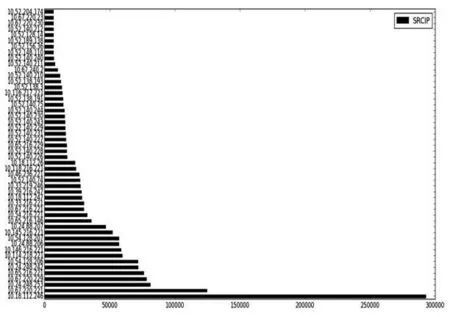
图6 服务器出度
图7 服务器入度
(2)从主机的传输—接收流量大小的角度来看,根据样本中的167个服务器绘出线型图如图8所示,坐标轴横轴为主机序号,纵轴为传输流量大小。实线表示发出的流量,虚线表示接受的流量。由图8可以看出大部分服务器发出的流量和接收的流量大小持平,只有少数提供特定服务的主机发出的流量和接收的流量大小相差较大。
4 结 语
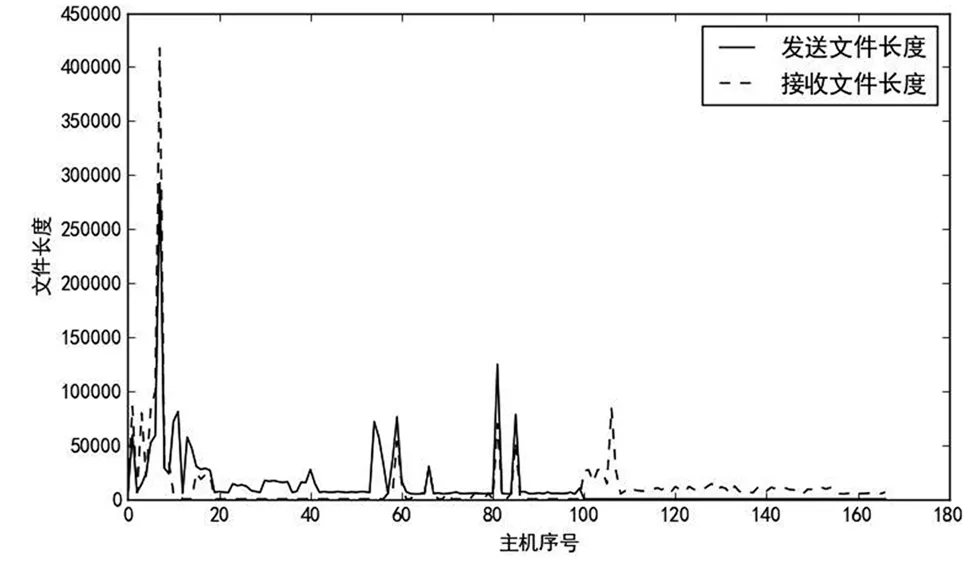
图8 主机传输—接收流量线型图
本文针对内网服务器识别分类问题提出的基于ELM的网络流量分类方法,无论是在训练时间还是分类精度方面都有良好的表现。通过对原始流量数据分析选择ElM分类模型,根据分类后的仿真结果对数据进行了可视化绘图从而进一步地了解ELM算法对网络流量数据分类的效果。最终的实验结果表明ELM算法可以取得较好的分类效果,可以满足网络流量分类识别的应用需求。H-ELM和ELM之间最主要的区别是在ELM特征分类前H—ELM用分层训练获得原始数据的多层稀疏表示,而在ELM中,原始数据是用来直接回归和分类的。总的来说H-ELM改善了学习表现。未来工作中将要注重网络流量的预测以及新样本加入训练时无需对样本重新训练的SLFNs的增量式学习算法OS-ELM解决网络流量分类问题的研究。
参考文献:
[1] 丁杰.基于n-gram多特征的流量载荷类型分类方法[J].计算机应用与软件,2017,34(2):152-158.
[2] 孙靖超.一种基于机器学习的网页分类技术[J].信息网络安全,2017(9):45-48.
[3] 戚铭钰,刘铭,傅彦铭.基于PCA的SVM网络入侵检测研究[J].信息网络安全,2015(2):15-18.
[4] 王涛,余顺争.基于机器学习的网络流量分类研究进展[J].小型微型计算机系统,2012,33(5):1034-1040.
[5] 刘琼,刘珍,黄敏.基于机器学习的IP流量分类研究[J].计算机科学,2010,37(12):35-40.
[6] 李晓明.基于机器学习的网络流量分类算法分析研究[J].中国传媒大学学报(自然科学版),2017,24(2):9-14.
[7] 林平,余循宜,刘芳,等.基于流统计特性的网络流量分类算法[J].北京邮电大学学报,2008,31(2):15-19.
[8] HUANG G,B CHEN L, SIEW C K. Universal approximation using incremental constructive feedforward networks with random hidden nodes [J].IEEE Trans Neural Networks,2006,17(4):879-892.
[9] HUANG G,B ZHOU H. DING X. Extreme learning machine for regression and multiclass classification [J].IEEE Trans Systems Man Cybernetics-Part B:Cybernetics,2012,42(2):513-529.
[10] 徐鹏,刘琼,林森.基于支持向量机Internet流量分类研究[J].计算机研究与发展,2009,46(3):407-414.
[11] 李平红,王勇,陶晓玲.支持向量机的半监督网络流量分类方法[J].计算机应用,2013,33(6):1515-1518.
[12] 周文刚,陈雷霆,LubomirBic,等.基于半监督的网络流量分类识别算法[J].电子测量与仪器学报,2014,28(4):381-386.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
玩具世界(2022年2期)2022-06-15
计算机应用与软件(2022年2期)2022-02-19
房地产导刊(2021年8期)2021-10-13
网络安全和信息化(2020年9期)2020-12-31
出版人(2020年4期)2020-11-14
网络安全和信息化(2020年7期)2020-08-07
网络安全和信息化(2019年8期)2019-08-28
微型电脑应用(2019年8期)2019-08-22
Medical Data Mining(2019年4期)2019-04-05
