
Energy Optimization Oriented Three-Way Clustering Algorithm for Cloud Tasks
2018-06-15 02:17ChunmaoJiangYibingLiandZhicongLiInformationandCommunicationEngineeringSchoolHarbinEngineeringUniversityHarbin5000ChinaComputerScienceandInformationEngineeringSchoolHarbinNormalUniversityHarbin5005China
Chunmao Jiang, Yibing Li and Zhicong Li(.Information and Communication Engineering School, Harbin Engineering University, Harbin 5000, China; .Computer Science and Information Engineering School, Harbin Normal University, Harbin 5005, China)
Cloud computing has emerged as a new promising paradigm for cloud consumers and provides with minimal management effort. In the cloud computing platform, the resources can be allocated according to the needs. In other words, the user can obtain the required computing and storage services through the network.Cloud applications are deployed to remote data centers where they have high-performance servers and a large number of storage systems.Rapidly growing demands for cloud platforms led to a large number of data centers consuming high amount of electrical energy.
From cloud computing providers’ perspective, they hope to maximize energy efficiency while minimizing energy consumption.The increasing energy cost is a highly potential threat as it increases the total cost of the ownership(TCO), reducing the rate of return on investment of providers. From the users’ point of view, they want to get low-cost and high-quality transparent services based on service level agreements (SLA).
Energy consumption is extremely high hidden behind the provision of services[1]. We have to carefully consider various possible methods and algorithms to reduce energy consumption.
This task can be optimized from three aspects of energy consumption, which are the physical layer, the virtual machine layer, the task layer of the cloud platform.
First, from the physical layer, highly efficient servers, optimize physical networks, cooling, ventilation systems can be chosen.Second, in the virtual machine level, the use of virtualization technology to consolidate the idle virtual machine, reducing virtual machine migration can be considered;Third, in the cloud task level, the owners can perform the optimization of a variety of scheduling strategies, modeling tasks based on characteristics.
In previous studies, the association between task multidimensional attributes and energy consumption was rarely considered.
It is reflected by the fact that, its analysis is not sufficient for the multidimensional properties of cloud tasks.The existing research only considers the basic properties of the task, such as submission time, deadline, tasks size. The cloud task is multidimensional heterogeneous, different types of tasks have different resource needs;Secondly, there is not enough research on the association between multi-dimensional attributes and optimal scheduling of energy consumption. Different task attributes lead to different resource requirements, different resource allocation methods also produce different energy consumption, even a huge difference.
This paper presents a method, specifically, with this method cloud tasks are divided into three categories and clustering according to the characteristics of the use of resources, computing-intensive, storage-intensive, communication-intensive. At the same time, the resources are also divided into three categories and clustering in accordance with the same method, and then the greedy scheduling is performed. The remainder of the paper is organized as follows. In section 1, related work is discussed.Section 2 presents the cloud tasks’ classification and clustering algorithm. And a greedy scheduling strategy is proposed based on the algorithm. In section 3, we do the experiment to examine our strategies proposed above. Finally,the conclusion and future work are presented in section 4.
1 Related Work
Energy-saving task scheduling means using an energy-aware scheduling algorithm to improve the utilization of resources, reduce data center energy consumption for achieving green scheduling.
Ref.[2] proposed a scheduling algorithm based on the tradeoff between time and energy consumption by determining the scheduling order of the tasks and assigning the appropriate compute nodes to the tasks.
Ref.[3] proposed a method to minimize the operating cost of the system. The method is based on the dynamic relationship between CPU utilization and energy consumption to achieve maximizing energy efficiency while satisfying the SLA and ensuring user time requirements.
Ref.[4] proposed a scheduling algorithm for real-time, periodic, and independent cloud tasks. The algorithm ensures the deadline by dynamically adjusting the number of virtual machines or physical hosts. When some hosts are idle, the host is consolidated through virtual machine technology to reduce power consumption.
In order to balance the relationship between reliability, performance and energy consumption, Gao Yue et al.[5-6]introduced a unified resource allocation and fault tolerance scheduling framework for cloud service providers, which has to choose the right error-finding and fault-tolerant policies for each user. This framework improves the fault tolerance of the system and reduces the overall energy consumption of the system under the premise of guaranteeing the user’s deadline.
As a result, the virtual machine consolidation to reduce data center energy consumption can lead to significant overhead and task delays, and even SLA violations in computing resources and network infrastructure. Ref.[7] proposed a cooperative two-level scheduling method that adjusts the execution speed of a real-time task when a host’s utilization reaches its optimal value, rather than migrating the task to another host.
In order to optimize the data center’s revenue, Wang Wei et al.[8]proposed a strategy to optimize the energy consumption of the data center based on dynamic pricing, and then establish a unified model of service price and energy consumption, to achieve co-optimization service price and energy consumption by studying the relationship between them.
Karthick et al.[9]modeled the energy consumption of heterogeneous cloud data centers, obtained the optimal resource allocation by solving the constraint model, and proposed an energy-optimized resource allocation algorithm based on it.To establish the minimum energy consumption as the goal, the algorithm allocates the appropriate virtual machine to the heterogeneous physical host based on the minimum cost of the resource obtained by the monitoring module in application.
Task clustering is basically a method to combine small tasks into a comparatively large task for minimize the span of the tasks[10-18]. Task clustering are categorized as level and label based clustering, vertical, blocked and horizontal clustering.
In summary, the current research focuses on virtual machines, physical hosts. The former to optimize energy consumption through the merger or migrate the virtual machine, the latter to achieve energy optimization by adjusting the physical hoststate, such as turn off, sleep and so on. They all ignore the impact of energy consumption from the perspective of cloud tasks.
In this paper, by analyzing the actual trajectory of cloud tasks from Google trace[19],we obtain the multi-dimensional attributes of the cloud tasks, and then divides them into three categories and they are clustered.Simultaneously,resources also be divided into three categories and clustered, then agreedy scheduling is utilized from the cloud tasks to cloud resources. We find that the proposed method has a better optimization effect than the simple greedy scheduling algorithm.
2 Task and Resource Clustering Based on a Classification
The overall energy consumption of the cloud platform is directly related to the usage characteristics of tasks in the system resources, according to the task resource table data from Google data analysis. According to their relationship, the tasks for the resource requests are divided into three categories computing resources, storage resources and network resources.
Correspondingly, in this paper, depending on the type of requests on cloud tasks for resources, the cloud tasks are divided into three categories: compute-intensive, data-intensive and communication-intensive as shown in Fig.1.
f(X,R,a)→a↑f↓
(1)

Fig.1 Cloud task clustering scheduler
Eq.(1) represents the relationship between task attributes and system energy consumption, in whichXdenotes the set of task attributes,Rdenotes the set of resource attributes,arepresents the degree of conformity,fdenotes energy consumption. Our goal is to generate a greater probability of descending in the corresponding scheduling energy consumption asagradually increases.
As shown in Eq.(1), it is better that the attributes in the tasks conform more with the resource attributes if we want to reduce the overall system energy consumption.
Based on this formula, we propose an energy-efficient scheduling strategy to improve the level of the task attributes conforming with resource attributes, thereby reducing system energy consumption.
2.1 Model of task and three-way clustering
Suppose the set of tasks submitted by the user are listed as follows
〈Task〉={Task1,Task2,…,Taskm}
(2)
Taskirepresents theith task, each task has multi-attributes. So each task formula is expressed as follows
Taski=
{tID,tlength,tPEs,tstorage,tcomm,tdeadTime,tpriority}
(3)
wheretIDrepresents the unique identifier of the task,tlengthrepresents the task size,tPEsindicates the number of PEs required for the task. The required computational capacity of the task istcompute=tlength/tPEs,tstoragerepresents the storage resources required;tcommrepresents the communication resources required;tdeadTimerepresents the deadline of tasks;tpriorityrepresents the priority of tasks.
The classification of cloud tasks is based on the characteristics of the resources requested by the task.Determining the type of task requires the following two steps:
① Calculate the composite expectation of a task’s resource request according to
(4)
whereα,β,δrepresent empirical parameters of task requirements for computing resources, storage resources, computing resources, respectively.
② Determine the task type according to the formula as following
(5)
tTyperepresents the type of cloud tasks.CRkpresents the comprehensive capacity of the resource cluster of thekth class.
By calculating the shortest distance between the composite expectation of resources and the comprehensive performance of various types of resources,we can obtain the type of tasktType.
2.2 Types of resources and clustering
2.2.1Model definition
To illustrate our approach, we define the model and illustrate the related concept.
Suppose 〈R〉={R1,R2…Rn} represent the set of resources, whereRi(i∈[1,n]) represents theith resource,nis number of resources, and
Ri={rID,rcompute,rstorage,rcommi}
(6)
rIDis the unique ID for resources,rcomputerepresents the computing capabilities,rstoragerepresents the storage capabilities,rcommirepresents the communication capabilities.
Synthesizing capacity of resources,REcan be calculated as follows,
(7)
wherea,b,crepresent the weight coefficient for balancing the computing capacity, storage capacity and communication capacity, respectively.
Similarity of resourcesR(i,j)similarrepresents the similarity between resourceiand resourcejin synthesizing the capacity. It can be calculated withthe following formula by using the cosine distance.
(8)
Synthesizing capacity of resources clustersCRdenotes the average level of overall resources capacity in one resources cluster, it can be calculated as follows
(9)
wheremis the number of resources in a resource cluster.
2.2.2Resources three-way clustering
Three-way clustering algorithms were used to cluster the resources. The main idea is to divide the target resource into three resource clusters. The goal is to make the resources have a great similarity in a cluster,large disparities are in different clusters. Using the NFS to measure the effective of three-way clustering algorithm as Eq.(5). Obviously, the smaller value means the better effectiveness.
(10)

Algorithm 1:
1: Construct the set of data by calculating the synthesizing capacity of overall resources.
X={x1,x2,…xn},xi=REi
2: Set the number of clusteringKand the maximal number of iterations.
3: Randomly selectKas the initial clustering center pointvi(I),wherei=1,2,…,K.
4: The remaining data are allocated to the corresponding clusters by calculating the distance of the cos according to Eq.(8).
5: The center point of each cluster is calculated repeatedly until the new center point satisfies the following equation that is, the sum of the distances from the center point to all the data points in the cluster is minimal.
(11)
6:Evaluate the results of the clustering using the NFS value, loop execution if the center point is changed; if the center point does not change, the algorithm terminates.
Finally, we get the clusters of resources,
Cluster(1),Cluster(2),…,Cluster(K)
2.3 Cloud task scheduling strategy
In order to achieve the goal of energy consumption optimization for the cloud platform, it is necessary to improve the consistency of task attributes and resource attributes.
Therefore, this paper presents an energy-efficient scheduling strategy, as shown in Fig.1.
First, the resources in the cloud platform in accordance with its ability to be clustered,
And finally they are divided into three resource clusters: computing resource cluster, storage resource cluster and communication resource cluster. In this way, the searching time and space of the resources can be reduced, the complexity of the algorithm can be reduced, and the resource utilization rate can be improved.
Second, classify the task submitted by the user, according to the task of the preference for resources.
The tasks are divided into three categories: compute-intensive tasks, data-intensive tasks, and communication-intensive tasks.
Then, the computationally intensive tasks are assigned to clusters of high computational power. Data-intensive tasks are assigned to clusters with strong storage capacity. Communication-intensive tasks are assigned to clusters with strong communication capabilities. The purpose is to make the same type of task in the corresponding type of physical host implementation. This can improve the consistency of task attributes and resource attributes, thus reducing the overall energy consumption of the system to achieve the task of energy-saving scheduling.
Finally, the same type of task can use thegreedy algorithm scheduling in the same cluster of resources,
Greedy algorithm will always be assigned to the longest task to the most powerful computing power to perform tasks.
And at the same time to meet the task priority and deadline requirements.
The execution time of a task is equal to the instruction’s length of the task divided by the execution speed of the resource which execute this task. The calculation formula is shown as
Time=tlength/rcompute
Therefore, the following conclusions can be drawn:
① If multiple tasks are running simultaneously on a resource, the total completion time for these tasks is constant.Because the total instruction length of the task and resource execution speed is constant.
② The resources are equal for the task. In other words, if a resource’s performance is high, then it is fast regardless of which task is executed.
③ If a task has the shortest execution time on a resource, the execution time on the other resource is the shortest.
2.4 Scheduling algorithm
Greedy scheduling is to assign multiple tasks to a certain number of resources based on resource clustering and task classification. Tasks are of the same type, and the corresponding resources have the same attributes. However, because the parameters between the tasks and configuration between resources cannot be exactly the same. So we need to consider the resource allocation strategy.
A specific greedy scheduling is listed as:
(1)Input:taskList={Task0,Task1,…,Taskn-1} andCluster(k)={R0,R1,…,Rm-1},where all tasks have the same type;k∈[1,K];
(2)Sort(taskList,des); //The tasks are arranged in a descending order according to the instruction length;
(3)Sort(Cluster(k),asc); //Resources in an ascending order according to the execution speed;
(4)Time[i][j]=Taski.length/Rj.compute; //Initialize the time matrix
(5)Time(Rm-1)=Time[0][m-1];//Assign the 0 row task to the resource with the largest column number
taskNumbers(Rm-1)=1;//The number of tasks running on a resource increases by one
taskList.get(0).setRID(Cluster(k).get(m-1).getID());//Resourcem-1 performs the task
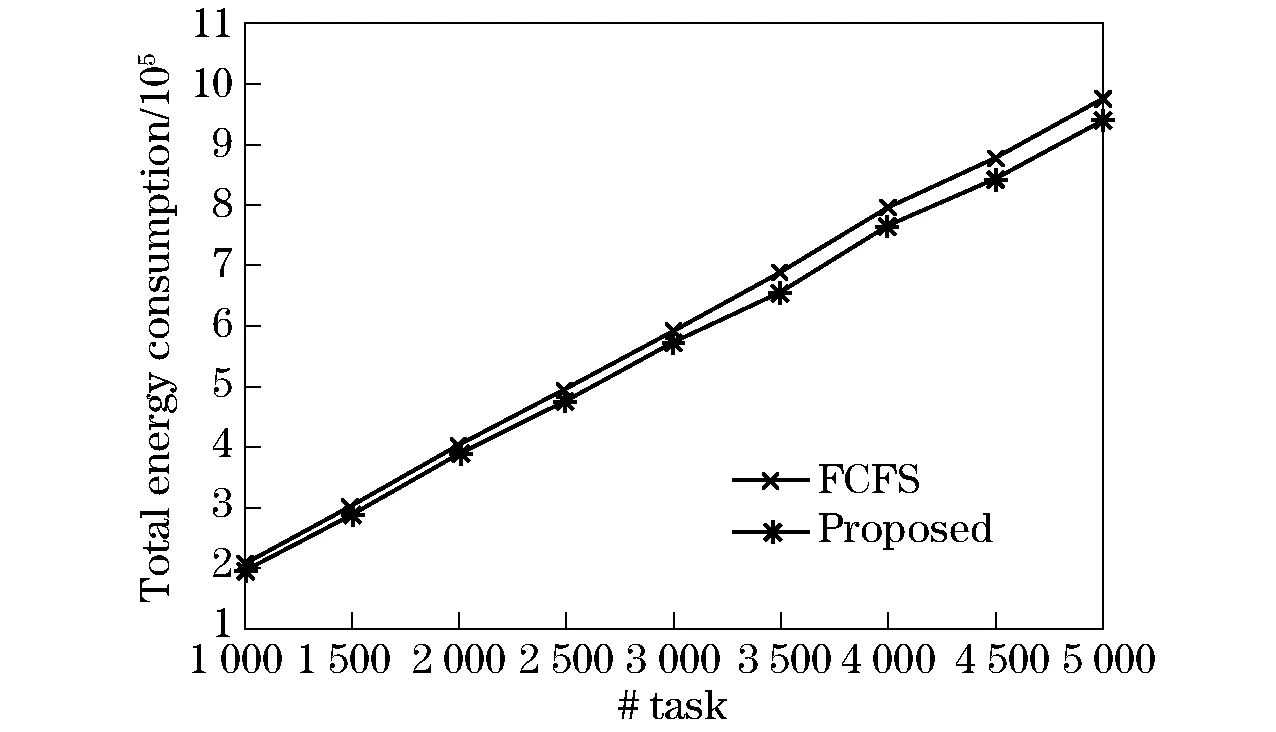
(6)for(i=1;i minTime=Time[m-1]+Time[i][m-1];//Record the optimal value index=m-1;//Temporary Index for(j=m-2;j≥0;j--){ if(Time(Rj)==0){//If the current resource has not yet been assigned a task if(minTime≥Time[i][j]){//Compare whether the allocation is optimal index=j;break;}//If i is the best, update the index, exit the loop if(minTime>Time(Rj)+Time[i][j]){//on the contrary minTime=Time(Rj)+Time[i][j];//Update the optimal time index=j;}//update the index //Achieve simple load balancing esleif(minTime=Time(Rj)+Time[i][j] &&taskNumbers(Rj) index=j; } Time(Rindex)+=Time[i][index];//Update the total execution time of the resource taskNumbers(Rindex)++;//Update the number of tasks running on the resource taskList.get(i).setRID(Cluster(k).get(index.getID());//Assignments }//END CloudSim is a cloud simulation framework, which can simulate the cloud data center infrastructure, virtual resources and related services. It can simulate the hardware infrastructure including: data center, physical host, network situation. And it can simulate the software including: cloud users, cloud tasks, virtual machines, resource capabilities. At the same time, it also provides the time sharing and space sharing allocation strategy. Developers can use CloudSim for large-scale cloud-related simulations. At the same time, it also provides time sharing and space sharing allocation strategy. Developers can repeatedly test the algorithms before deploying the application service online.This not only saves manpower and resources but also facilitates the developers. First, we extend the cloud task classes based on the CloudSim to meet the required attributes of the algorithm. The class diagram we designed for the cloud task is shown as Fig.2. Fig.2 Task class In this experiment, we simulated two data centers, there are five physical hosts, the first data center has one host; the second data center has two hosts. Set up ten hosts in 1st data center,and set up six hosts in 2rd data center. There are two user groups, belonging to different regions respectively. And then configure the network bandwidth of each region and the delay matrix, as shown in Tab.1 and bandwidth matrix in Tab.2. Tab.1 Delay matrix Tab.2 Configuration of bandwidth Finally, we configure user information, each user group has 1 000 users submitting requests at the same time. An application server in the data center can handle 10 requests at the same time,the length of each request is 100 bytes. We conducted an experimental simulation by randomly generating tasks, and the simulation time lasts 6 h.The experiment was repeated 20 times under the same experimental conditions,we calculated their average through the 20 experiments, respectively. We take the average task execution time and the total energy consumption and other indicators to measure the effect of the algorithm. By comparing the common greedy scheduling algorithm with the scheduling algorithm proposed in this paper, the effectiveness of the proposed algorithm is verified. By simulation experiments, as shown in Fig.3, the data obtained was compared and analyzed. It shows the average execution time of the proposed algorithm is reduced, compared with the first-come-first-service scheduling algorithm with the increase in the number of tasks. As shown in Fig.4, the FCFS algorithm and the algorithm proposed in this paper, the energy consumption is gradually increasing with the increase of the cloud tasks,but the energy consumption of the proposed algorithm is lower than FCFS algorithm as shown in Fig.5. Fig.3 Time required for performing tasks Fig.4 Total energy consumption Fig.5 Energy saving rate And the difference between the two algorithms gradually increases, indicating that with the increase of the number of tasks, the task clustering and resource clustering for reducing energy consumption play an increasingly important role. The saving rate of energy consumption tends to decrease slightly as the number of tasks increases, this shows that there are extra energy consumption with the increase in cloud tasks, it may be due to the need for energy consumption in the classification of the cloud resources and clustering. Based on the multi-dimensional attributes of the task, this paper proposes a energy consumption optimization strategy for a cloud platform, which clusters the resources, classifies the tasks, and allocates each type of tasks to the corresponding virtual machine resources. Simulation results show that the proposed algorithm can significantly improve resource utilization and reduce system energy consumption compared with FCFS. In the future, we will further optimize the algorithm to reduce the violation of SLA situation, while further analyze the relationship between the task of multi-dimensional properties and energy consumption. [1] Awada U, Li K, Shen Y. Energy consumption in cloud computing data centers[J]. International Journal of Cloud Computing and Services Science, 2014, 3(3): 145. [2] Babukarthik R G, Raju R, Dhavachelvan P. Energy-aware scheduling using hybrid algorithm for cloud computing[C]∥Computing Communication & Networking Technologies (ICCCNT), 2012 Third International Conference on,IEEE, 2012. [3] Dabbagh M. Toward energy-efficient cloud computing: prediction, consolidation, and overcommitment[J]. IEEE Network, 2015, 29(2): 56-61. [4] Zhu X. Real-time tasks oriented energy-aware scheduling in virtualized clouds[J]. IEEE Transactions on Cloud Computing, 2014, 2(2): 168-180. [5] Gao Yue. An energy-aware fault tolerant scheduling framework for soft error resilient cloud computing systems[C]∥2014 Design, Automation & Test in Europe Conference & Exhibition (DATE),IEEE, 2014. [6] Liu J Z, Sun B, Zhu C G. Application of fuzzy C-means algorithm in task scheduling problem[C]∥China Institute of Communications, Tenth China Society of Communications Academic Annual Proceedings, 2014. [7] Hosseinimotlagh S, Khunjush F, Hosseinimotlagh S. A cooperative two-tier energy-aware scheduling for real-time tasks in computing clouds[C]∥2014 22nd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing,IEEE, 2014. [8] Wang Wei, Luo Junzhou, Song Aibo. Dynamic pricing based energy cost optimization in data center environments[J]. Chinese Journal of Computers, 2013, 36(3): 599-612. [9] Karthick A V, Ramaraj E, Ganapathy Subramanian R. An efficient multi queue job scheduling for cloud computing[C]∥Computing and Communication Technologies (WCCCT), 2014 World Congress on,IEEE, 2014. [10] Chen W. Balanced task clustering in scientific workflows[C]∥eScience (eScience), 2013 IEEE 9th International Conference on,IEEE, 2013. [11] Katyal M, Mishra A. A comparative study of load balancing algorithms in cloud computing environment[Z]. arXiv preprint arXiv:1403.6918, 2014. [12] Lordan F, Tejedor E, Ejarque j, et al. Servicess: an interoperable programming framework for the cloud[J]. J Grid Comput, 2014,12: 67-91. [13] Chen W, da Silva R F, Deelman E, et al. Using imbalance metrics to optimize task clustering in scientific workflow executions[J]. Future Gener Comput Syst, 2015,46: 69-84. [14] Zhang F, Cao J, Li K, et al. Multi-objective scheduling of many tasks in cloud platforms[J]. Future Gener Comput Syst, 2014,37: 309-320. [15] Ayguadé E, Badia R M, Bellens P, et al. Extending openmp to survive the heterogeneous multi-core era[J]. Int J Parallel Program, 2010,38: 440-459. [16] Lezzi D, Lordan F, Rafanell R, et al. Execution of scientific workflows on federated multi-cloud infrastructures[C]// Euro-Par 2013: Parallel Processing Workshops, Springer, 2013: 136-145. [17] Pinedo M L. Scheduling: theory, algorithms, and systems[M]. Berlin: Springer Science & Business Media, 2012. [18] Kim I Y, De Weck O. Adaptive weighted-sum method for bi-objective optimization: Pareto front generation[J]. Struct Multidiscip Optim, 2005,29: 149-158. [19] Reiss C. Heterogeneity and dynamicity of clouds at scale: Google trace analysis[C]∥Proceedings of the Third ACM Symposium on Cloud Computing, 2012.3 Experiment and Result Analysis
3.1 CloudSim
3.2 Environment setup


3.3 Experimental results and analysis


4 Conclusion
 Journal of Beijing Institute of Technology2018年2期
Journal of Beijing Institute of Technology2018年2期