
基于可视分析的伪基站活动特征分析方法
2018-07-03 11:32赵韦鑫蒋宏宇吴亚东
西南科技大学学报 2018年2期
唐 楷 赵韦鑫 蒋宏宇 吴亚东,2 王 松,3
(1. 西南科技大学计算机科学与技术学院 四川绵阳 621010;2. 西南科技大学四川省军民融合研究院 四川绵阳 621010; 3. 中国工程物理研究所电子工程研究所 四川绵阳 621010)
“伪基站”即假基站,能够搜集以其为中心、一定半径范围内的手机卡信息,利用GSM单向验证漏洞伪装成运营商的非法无线电通信设备,通过冒用银行、运营商、国家机关或他人号码的名义,强行向用户发送诈骗、色情、赌博、广告等短信息。不法人员利用伪基站发送短信,不仅干扰公共频率资源,影响人们的正常通讯,而且通过群发短信的方式发送内容不受控的短信息,严重侵害了社会秩序。
Hilas设计了一套私有网络中短信诈骗检测的专家系统[1],Borgaonkar等[2]建立了一套垃圾短信检测的框架。主题模型通常被用来识别垃圾短信和垃圾短信主题,类似的工作如将其运用于垃圾邮件检测上[3]。城市轨迹是垃圾短信监测系统中一个重要的特征,其中对于轨迹去噪,卡尔曼滤波[9-10]能够从一系列的不完全及包含噪声的测量中估计动态系统的状态,Lee等[8]详细介绍了卡尔曼滤波在轨迹数据上的运用。而停留点能从伪基站轨迹数据中提取出伪基站的停留点,文献[11-12]中在用户的GPS轨迹中利用了停留点技术进行旅游推荐。合并相似轨迹也是伪基站城市轨迹数据可视分析系统中重要的一个维度,Gaffney 等[13]提出了采用EM算法的方式聚合轨迹,Li等[14]提出了一种增量式轨迹聚类的方法来减少轨迹聚类的时间空间消耗。郑宇等[4]也对城市数据中轨迹去噪、轨迹重要特征挖掘等问题上进行了很完善的总结。
1 数据简介及分析流程
1.1 数据简介
伪基站数据常常是由用户主动上报垃圾短信前最后连接到合法基站的位置时间和其接收到的垃圾短信内容组成。但伪基站具有十分强的流动性,因此通过根据其近似位置和传统的数据分析方法,仍然很难把握伪基站的活动规律。本文将采用可视法分析方法,从短信内容和其时空活动信息开始挖掘,揭示伪基站的行为模式,旨在提出一套伪基站时空信息分析框架,为有关部门打击伪基站提供有效的解决方案。
1.2 分析流程
针对伪基站发送的垃圾短信的时空特征以及其文本特征,本文将从分析任务、数据处理和挖掘、时空特征可视分析三个方面对分析流程(如图1所示)进行阐述。在数据处理部分,首先对垃圾短信进行数据清洗,根据短信相似度对短信进行聚类;另一方面对垃圾短信进行数据清洗、文本分词、词频统计,对短信进行人工分类,根据分类结果和词频统计选择具有分类意义的词语,使用这些词汇对短信进行分类,最后通过短信伪造的号码和文本中设计的网址对短信的危害性进行评估。其次对于伪基站的时空数据,通过数据清理,轨迹分段,分离不同伪基站等预处理方式来去除数据中的冗余和噪声,经过轨迹进行压缩后,对其进行停留点分析、频繁模式分析等轨迹数据模式挖掘。对处理后的数据,根据其时空特征进行可视化,本文的分析任务是帮助分析人员探索伪基站的行为模式,帮助公安人员对伪基站进行打击。

图1 伪基站行为模式分析流程Fig.1 The process of analysing pseudo base station behaviour pattern
2 数据处理
2.1 短信文本内容实体抽取
2.1.1 相似短信聚类
垃圾短信由于其目的单一明确,往往其短信内容相似,很多短信只是标点符号不同、短信中插入的电话号码、QQ、微信号不同或者对相同的事物采用了不同的措辞。
本文设计的方法能够从这些短信中找到基短信,并将内容少量不同的短信视为它的衍生短信。
算法如下:
Step 1: 通过去除掉短信中的标点符号,然后通过Jieba[15]对其进行分词,再去除掉词语集合中的停用词,得到词语集合Si。
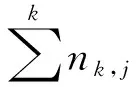
(1)
最后将两个权重相乘可计算其语义权重Ci,j=Fi,j×Ii,j。
Step 3:计算两两短信间的HL指数。其中短信x和y之间的差异度Hx,y:
(2)
式中,如果主导文字序列完全相同,Sx和Sy之间的差异率为0。通过差异度可以计算短信x和短信y之间的相似度HL指数:
(3)
经过该算法对13 000条短信进行相似聚类之后,只剩下3 000条基短信,大大缩减了之后的计算量以及人工工作量。
2.1.2 垃圾短信分类
伪基站团伙往往会同时发出不同类型的垃圾短信,一部分不法分子通过垃圾短信来进行违法活动宣传,还有一部分不法分子通过这些短信来进行诈骗。不同类型的垃圾短信,对人们的危害程度各有不同,根据短信的特点以及危害程度,本文使用统计方法以及语言规则将垃圾短信分为广告、诈骗、色情、谣言、赌博、其他6种类型。首先通过专家人工标注对少量短信进行分类,再通过研究其文本,对其进行分词和词频统计,分析在某类别中出现词频较高且在其他类中出现较少的词语,将其作为候选关键词作为垃圾短信分类的依据,从而使用关键词匹配对短信进行分类(图2)。

图2 伪基站垃圾短信类型分布以及垃圾短信中最常假冒的号码Fig. 2 The distribution of spam messages, and the most commonly counterfeited numbers in these messages
2.1.3 垃圾短信危害性评估
为了帮助相关部门最有效地打击伪基站,本文对垃圾短信的危害性进行了评估,通过识别短信是否出现号码、号码是否和发送号码相同以及短信中是否出现链接等特征,本文制定了垃圾短信危害度评估公式:
Degree=Wsource+Wlink+Wnumber
(4)
其中Wsource为伪造号码的权重,Wlink为短信中链接的权重,Wnumber为短信中出现号码的权重,该号码的权重是基于对所有短信统计出其出现次数后除以短信总数来对此进行加权。通过最后得到的权值来区分出较严重的金融诈骗、虚假宣传和推销以及对用户进行骚扰的程度。如果发送号码伪造已知的银行号码或者运营商号码,并且短信中出现链接的情况,该类短信将认为是危害性最为严重的类型。本文希望借助此评估方法帮助公安部门可以对危害性最大的垃圾短信伪基站进行优先打击。
2.2 时空轨迹预处理
伪基站轨迹数据具有时空有序性(伪基站轨迹数据是具有位置、时间、内容的采样数据,其轨迹点蕴含了伪基站的时空特征)、采样异频性(由于伪基站数据是由不同用户上报,轨迹活动存在随机性和时间差距较大的特征)和数据质量差(由于伪基站的位置无法被直接采样,只能通过收到其发出短信的用户的地址来估测,而对用户有一定的精度影响)的特点。而伪基站轨迹作为追踪基站的主要对象,预处理的效果将直接影响后期对伪基站轨迹数据进行数据挖掘和可视化的效果。同时,针对不同的挖掘目标,制定不同的预处理方案具有重要的作用。
2.2.1 伪基站轨迹去噪
伪基站的位置是将用户主动上报垃圾短信前最后连接的合法基站的位置近似作为伪基站的位置。
经过数据分析,伪基站中存在两种不同的噪声。一种是采样数据中同一时间存在多个位置,造成原因可能如图3所示,多个同一时间接受伪基站短信的用户处于不同位置(伪基站覆盖位置刚好跨越多个基站)。另一种是由软硬件设备异常导致的错误采样,例如移动对象进入室内或其他干扰 GPS 接收信号而导致定位误差。这些噪音点会极大影响轨迹数据挖掘和分析的结果,本文针对两种情况定义了不同的轨迹数据清洗方法。

图3 伪基站存在多种位置的示例图Fig. 3 An example diagram where a pseudo base station exists in a variety of locations
对于同一时间存在多个位置这样的情况,通过观察数据中点的分布可以发现两种情况在轨迹中都存在。针对该种噪音,本文通过根据轨迹分布排除超出轨迹1.5×IQR(四分位距)的数据点,然后求出剩余数据点组成凸包的质心作为伪基站在当前时间点的位置(图4)。

图4 伪基站在同一时刻存在多个位置的分布情况和去除噪声效果对比效果Fig. 4 The distribution of PBS at the same time and the contrast effect of trajectory denoising result
另一种情况是针对由软硬件设备异常导致的错误采样,在这个领域有很多相关工作,通过中值或均值滤波进行去噪[4],对于测量点Ai,对其的真值估计在其前(n-1)/2和后n/2个轨迹点的均值或中值中,其中n为滑窗大小。中值滤波和均值滤波的处理过程相似,但通过实验发现,滑动窗口的大小较大时,均值能更好地估计真值的大小,而在处理极端错误值时,中值滤波要比均值滤波具有更强的鲁棒性。在去除密集轨迹的噪声时,中值滤波和均值滤波都能很好地处理异常值,但在稀疏轨迹或者多个连续噪声点时,这两种滤波方式都不能取得比较好的效果。所以本文采用对两者进行平均的方式,减少了异常值对于整体轨迹的影响(图5)。

图5 轨迹去除噪声效果的对比Fig. 5 The comparison of trajectory denoising result
2.2.2 不同基站伪基站轨迹分离
一条短信可能由多个伪基站发出,这大大提高了数据分析难度,为了从伪基站大量的时空轨迹中抽取出基站实体,需要根据时间切片对轨迹进行分组,然后根据每个时间片的距离以及时间判断其是否属于一个基站,该算法流程如下:
Start:输入经过时间切片后的轨迹序列S,设P为序列S中的点
构建伪基站轨迹树T
FORSiinS:
FORPjinSi:
IFjequal 1:
AddNode(T,Pj)
Reduce(T→LNs)
ELSE:
FORPkinT→LNs:
IF Dis(Pk,Pj)>D:
AddNode(Pk,Pj)
END IF
ELSE:
AddNode(T,Pj)
END FOR
END IF
END FOR
END FOR
End:输出轨迹树T
删除掉长度小于最长序列长度一半的序列后,树中每一个序列即一个基站的行为轨迹,之后的可视分析工作将建立在该分离过的伪基站行为轨迹。
2.2.3 时空轨迹数据结构
由于伪基站轨迹点定位精度有限,所以将地图按一定约定划分成网格,将伪基站的轨迹点视为伪基站在此范围中活动。考虑分区的大小和分区的形状对于系统的性能和下一步挖掘有意义停留点。本文通过地理编码算法Geohash[5]得到一个分层的空间数据结构,将城市地图划分为76 m×76 m的网格单元。该数据结构(图6)提供了任意精度,并且可以通过逐渐从编码字节串末尾逐渐删除字节,以减小其大小(并逐渐失去精度)。由于逐渐的精度退化,相近的地方经常出现相似的前缀。共享前缀越长,两个地方越接近。

图6 Geohash编码方式Fig. 6 The way of geohash encoding
3 伪基站行为模式分析
伪基站的行为模式将从基站的活跃时间区间、基站活跃地理位置、伪基站发送短信类型进行反映,发送不同类型垃圾短信的伪基站往往拥有不同的行为模式。
3.1 伪基站时间特征分析
通过提取不同种类短信的时间特征,从图7中可以发现色情短信经常从晚上开始发送并且一直到午夜,而赌博和广告这类短信主要在午间时段较为活跃。
3.2 伪基站空间特征分析
通过提取不同种类短信的空间特征,发现诈骗类的短信更倾向与环绕整个北京城进行垃圾短信的散播,而色情类的短信更容易在宾馆、火车站和地铁站附近散播。

图7 不同种类伪基站时间特征Fig. 7 Temporal characteristics of different pseudo base stations
通过对时间特征和空间的分析,能够针对不同类型的伪基站制定不同的打击方案,从而提高打击效率。
3.3 伪基站时空混合活动分析
伪基站在静止和匀速运行状态下都会产生大量的冗余点,其中伪基站在某一时间段驻留时间较长, 称之为停留点(stay point)[6]。轨迹中这些点反映了伪基站一段时间的行为,例如停留休息、针对特定地点的投放,而这种地点能为警方抓捕相关罪犯有不少提示。
本文中的伪基站轨迹是由伪基站活动的点序列组成,每个点pi包括了pi.lng(经度)、pi.lng(纬度)、pi.v(伪基站移动速度)、pi.t(测量时间)、pi.w(区域权重),因此:
traj=p1→p2→L→pk,其中pi.t≤pi+1.t。

Start: 停留轨迹StayTraj,区域权重W
StrayP→0
FORSiin StayTraj:
StayP←StayP+Si·WSi
END FOR
End: 停留点
从整体(图8)来看,伪基站停留点在北京二环到三环的分布较多,其中朝阳区车站附近最为严重。而针对绕城式的伪基站活动和固定范围活动的伪基站进行分析,发现绕城式的停留点较为分散,而且在非环路上的重复停留较少。对于固定范围式的,可以发现其停留点仅在一个固定的范围,且重复经过同一停留点次数较多。

图8 停留点分析Fig. 8 Stay-point analysis
4 可视分析设计
基于伪基站行为分析方法,本文设计了PBSU伪基站行为模式可视分析系统(如图9所示),该系统粗略分为5个模块,分别是宏观时间筛选器(A)、地理信息展示模块(B)、热度筛选+详细列表(D)、细节时间筛选器(E)以及伪基站行径散点图(F),能够对基站的行为模式进行多粒度分析,在地图的右边,是对短信的危害性进行评估后的结果,用户能够对其进行点击以查看该短信的具体信息。
宏观时间筛选器能够对基站进行筛选,将在地图上显示在该段时间活跃过的基站,地图上用颜色对基站的类别进行了标注,当用户点击某条垃圾短信的时候,将会显示其同属一个基短信的所有短的活跃日期,使用灰色显示同属基短信的活跃时间,选择某一个活跃日期,右边的基站行径散点图和热力线将会得到更新,用户能够对散点图进行点击和框选操作,当用户点击某一个轨迹点时,将在地图上显示该轨迹点隶属的整个轨迹信息,在用户框选轨迹点之后,将会显示所有框选中的散点的详细信息。
5 案例分析
本文选取的实验数据来自2017年第四届中国可视化与可视分析大会数据可视分析挑战赛ChinaVIS Data Challenge 2017[7]中关于伪基站时空可视分析的竞赛数据集。这个数据集提供了北京市被标

A为宏观时间筛选器 B为地理信息展示模块C为垃圾短信影响度排行 D为热度筛选+详细列表E为细节时间筛选器 F为伪基站行径散点图
记是伪基站发送的垃圾短信的样本数据,其时间跨度为2个月,共有300多行记录。与只关注时空轨迹的传统城市轨迹不同的是,该数据中同一内容的垃圾短信轨迹可能属于多个伪基站,也存在不同内容的垃圾短信属于同一个伪基站发出。同时与只由特定固定设备来检测伪基站提供的数据相比,这份数据利用了庞大的用户数据,使伪基站短信的移动轨迹采样更加丰富,能更加容易刻画伪基站的时空特性。
通过对北京两个月的垃圾短信数据进行分析,可以发现伪基站在空间特征上存在有不同的移动模式。有绕城型基站、小范围移动基站和固定位置型的伪基站这3种主要的空间模式(图10),其中绕城式基站常在北京的第二、三环城快速路上运行,存在时间和短信传播量都较大;小范围移动基站主要选择如朝阳区一样流动人口较多的地区运行,尤其在该地区地铁站附近等地特别活跃;而固定位置型基站主要存在于旅游景区、宾馆密集地区,该类基站传播信息的人群更加固定,所以活动性较小。

图10 伪基站不同的移动模式Fig. 10 The different movement pattern of Pseudo base station
在数据中伪基站发出的垃圾短信也存在一定的时间特征。从图11可看出,垃圾短信只有很短的生存周期,它可能活动只存在一到两天或者间隔很久才再次出现,也可能频繁变换短信格式但内容不变。第一种伪基站可能是团队级的伪基站团伙,不仅为特定违法团队服务,其可能为多个违法团队提供服务,而第二种是由特定违法团队组织,这样的伪基站存在多日的活动,其行为更容易被检测,便于警方抓捕。

图11 同一条基短信下不同短信的活跃时间Fig. 11 The active time about multiple variants of one basic message
6 结语
本文对伪基站发送的垃圾短信进行自然语言处理后进行聚类和分类,对垃圾短信移动轨迹进行了去噪、提取停留点、压缩轨迹存储等,并设计了可视分析系统,该系统能够对基站的行为模式进行探索,从而达到辅助打击伪基站的效果。
[1] HILAS, CONSTANTINOS S. Designing an expert system for fraud detection in private telecommunications net-works[J]. Expert Systems with Applications 2009, 36(9):11559-11569.
[2] BORGAONKAR R, MARTIN A, PARK S, et al. White-stingray: evaluating IMSI catechers detection applications[C]// 11th USENIX Workshop on Of fensive Technologies, 2017.
[3] BERGHOLZ, ANDRÉ. Improved phishing detection using model-based features[C]// CEAS 2008——The Fifth Conference on Email and Anti-Spam August 20-22, 2008, Mountain View, California, USA DBLP, 2008.
[4] ZHENG Y. Trajectory data mining: An overview[J]. ACM Transaction on Intelligent Systems and Technology, 2015, (6): 1-41.
[5] Niemeyer, Gustavo. Geohash[Z]. 2008.
[6] LI Q, ZHENG Y. Mining user similarity based on location history quannan[C]// Proceedings of the 16th ACM SIGSPATIAL international conference on Ad vances in geographic information systems. Heidelberg: 2008: 34.
[7] China Vis2017. http://chinavis.org/2017/index_en.html/ 2017. 7.
[8] LEE W C, KRUMM J. Trajectory preprocessing[A]// Y ZHENG, X ZHOU Computing with Spatial Trajectories[M]. Springer: 2011,1-31.
[9] KALMAN R E. A new approach to linear filtering and prediction problems[J]. Transactions of the ASME-Journal of Basic Engineering, 1960, 82: 35-45.
[10] KALMAN R E, BUCY R S. New results in linear filter-ing and prediction theory[J]. Transactions of the ASME-Journal of Basic Engineering, 1961, 83: 95-107.
[11] ZHENG Y, XIE X. Learning travel recommenda-tions from user-generated GPS traces[J]. ACM Transactions on Intelligent Systems and Technology, 2011,2(1): 2-19.
[12] ZHENG Y, ZHANG L, MA Z, et al. Recommending friends and locations based on individual location history[J]. ACM Transaction on the Web, 2011, 5(1): 5-44.
[13] CADEZ, IGOR V, GAFFNEY S, et al. A general probabilistic framework for clustering individuals and objects[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining ACM. 2000:140-149.
[14] LI Z. Incremental clustering for trajectories[C]// International Conference on Database Systems for Advanced Applications Springer-Verlag. 2010:32-46.
[15] SUN J. Jieba中文分词[EB/OL].https://github.com/fxsjy/jieba,2012[2016-04-20].
猜你喜欢
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
当代工人(2019年4期)2019-04-22
作文大王·低年级(2018年10期)2018-12-06
当代工人(2018年21期)2018-03-06
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
中国交通信息化(2016年8期)2016-06-06
小猕猴智力画刊(2016年5期)2016-05-14
通信电源技术(2016年4期)2016-04-04
