
级联神经网络人脸关键点定位研究
2018-07-12 06:21井长兴章东平
中国计量大学学报 2018年2期
井长兴,章东平,杨 力
(中国计量大学 信息工程学院,浙江 杭州 310018)
人脸关键点定位[1]的目的是将人脸面部关键点如:左右眼角、左右嘴角、鼻子、人脸轮廓等关键面部位置在一张人脸图像上定位出来.人脸关键点定位能够为后续研究工作提供所需要的几何特征等基础信息,在人脸图像编解码[2]、人脸表情识别[3]、人脸追踪[4]、身份验证[5]、人脸三维重建[6]等研究工作带来直接的影响.同时,对于其他关键点定位、回归问题等多种任务具有启发性影响.
非约束条件下的人脸关键点定位仍然存在一些困难和挑战,其主要原因是在非约束条件下某些关键因素影响了人脸关键点定位的准确率.这些影响因素包括:关键点部位遮挡[14]、人脸角度变化[15]、面部结构变化[16]等因素.
针对以上问题,本文提出了一种改进的级联卷积神经网络方法,主要通过对神经网络结构的改进实现了多尺度特征融合,增强网络特征表达能力.如图1,在级联卷积神经网络的第一阶段,构建多尺度融合的网络结构;提出一种结合L1 Loss[17]和L2 Loss[18]的人脸关键点定位损失函数,避免梯度爆炸问题.通过在公开数据集LFPW[19]、HELEN[20]、AFLW[21]、300-W[22]和自建视频监控数据集上的实验结果证明,本文提出的方法相较于ESR、LBF、DCNN等算法平均误差有所下降,进而提高了人脸关键点定位精度.
1 相关研究
人脸关键点定位方法大致可分为以下四类:基于有约束的局部模型方法,分别构建形状模型与外观模型,通过对人脸形状建模来约束估计形状;通过对人脸每一个关键特征点区域描述完成外观模型的构建;主动形状模型ASM[7]使用主成分分析方法对平均人脸形状建模;局部模型CLM[8]分别使用高斯混合模型和特征脸,构建出局部外观和人脸形状模型.
基于主动外观模型方法分别构建全局外观和形状模型.主动外观模型AAM[9]通过构建全局外观模型,将待定位图像配准平均形状得到纹理图像,进行主成分分析[10]建模,融合纹理与形状模型.该方法会出现维度不匹配的现象而难以拟合非约束条件下的人脸关键点位置变化.
基于回归模型方法通过学习人脸形状与关键特征点之间的映射函数,定位人脸关键点位置.通过级联回归模型,迭代多个回归函数逼近人脸关键点的精确位置.ESR[11]使用回归树训练级联回归模型;LBF[12]通过对每一个人脸关键点构建多个回归树的随机森林提取LBF特征,通过全局线性回归得到精确人脸关键点定位.
基于外观信息方法使用深度学习方法,设计卷积神经网络[13],利用神经网络的非线性函数逼近能力回归人脸形状.多任务学习利用卷积神经网络提取特征,主要进行人脸关键点定位任务,同时辅助进行人脸属性等其他任务的进行,通过神经网络特征建立不同任务之间的联系.
2 级联卷积神经网络基本原理
首先,回顾级联深度神经网络模型,2013年Sun[23]等人提出了级联神经网络应用于人脸关键点定位,网络模型是一种三层级联回归网络,采取“由粗到精”的方式逐阶段回归人脸关键点位置.第一层级联对人脸检测框内的人脸关键点位置进行全局粗定位;接下来的两级网络对每一个关键点分别设计神经网络模型,对人脸关键点进行精确定位.损失函数使用L2Loss,即汇总所有人脸关键点目标值yi和相应的预测值xi,其中xi表示某个样本的特征向量.对于n个样本,最小化预测值与标签值之间的平方差,其公式如下:
(1)
其中,h(xi)表示经过激活函数之后的最终预测输出值.在人脸关键点定位的过程中,如果人脸某一个点的偏差变大,会使整个损失函数的误差变得很大,可见异常值对整个回归模型产生很大影响.
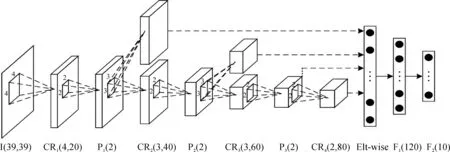
图1 改进的级联神经网络结构Figure 1 Modified architecture of cascade convolutional neural network
3 改进的级联神经网络人脸关键点定位方法
3.1 改进的级联卷积神经网络设计
本文依据级联神经网络在人脸关键点定位中的优势,使用DCNN为基准网络,提出了改进的基于级联深度卷积神经网络的人脸关键点定位网络结构.
改进的基于级联深度卷积神经网络人脸关键点定位方法用于实现人脸左、右眼睛,鼻尖,左、右嘴角5个关键点定位.网络结构设计采用“由粗到精”的方式,通过三层级联网络对人脸关键点位置实现精确定位.在第一级全局回归网络结构中,针对关键点回归问题,多层网络叠加会使特征在非线性变换过程中丢失空间像素信息,不利于解决关键点在像素层面上回归问题.因此,本文通过构建一个简单的快捷连接(ShortcutConnection[24])卷积层来补偿神经网络特征学习过程中空间信息不足的问题.
在第一级神经网络中,本文设计利用快捷连接卷积层从网络低层到高层,融合多层卷积神经网络输出特征,连接到F1全连接层,使其拥有空间上下文特征信息,弥补空间信息的丢失问题.
其中,每一个快捷连接结构都连接一个卷积层,通过卷积层对传递过来的低层信息做卷积运算,在网络深度固定的情况下增加网络宽度.应对输入的复杂条件下人脸框图特征提取,以提高网络的特征挖掘能力.具体全局回归神经网络结构如图1所示.其中,输入人脸框图大小为39×39,CRi(S,n)为卷积层,s为卷积核大小,n表示特征图数目,i为第i个卷积层;每个卷积层后接PReLU激活函数;Pi(S)为池化层,该网络中采用最大池化原则;Elt-wise层表示特征融合层,融合从低层到高层分别经过卷积后的特征,包括每一个池化层输出和最后一个卷积层输出;Fi(n)为全连层,n代表全连层的结点数.网络输出10维特征向量,为5个人脸关键点坐标值.
3.2 级联人脸关键点定位损失函数
对于损失函数,当预测值与真实值之间差距不大的情况时,L2损失函数有效惩罚了人脸关键点定位中的偏差;当预测值和真实值之间差距较大的情况时,L2损失函数的平方差损失会使损失函数的惩罚力度过大.L2损失函数可以有效剔除掉极性影响,但是对关键点回归时偏差较大的情况惩罚力度过大,本文将对深度模型中存在的该问题进行改进.
本文提出了针对不同偏差值,分情况回归的Moderate Loss损失函数.其在人脸关键点回归问题上具有学习速度快及抑制梯度爆炸的特点.Moderate Loss损失函数是结合L2与L1损失函数的优点,对于n个样本,损失函数最小化输出预测值与目标值之间的绝对差值,可以有效减小平均测试误差(Mean Error):
S=min∑|yi-h(xi)|.
令预测值与目标值绝对差值为δ,对δ分别讨论:
(3)
其中,i为人脸关键点的数量.对于卷积层正向传播迭代预测值与目标之间的绝对差值δ:若小于1,则对整个Moderate Loss损失函数取min(2δ2);其他情况下,则Moderate Loss损失函数取minα|δ|,其中α为可学习参数,取值范围为[0,1].在人脸关键点定位网络中,每一个人脸关键点预测值偏移距离较远时,通过一个可学习参数来控制绝对差值.
Moderate Loss损失函数对人脸关键点偏移量的不同大小分成两种情况来分析,对较小的偏移量有类似L2损失函数的效果;对较大的偏移量学习一个控制参数来加大分程度惩罚.同时在反向传播中具有良好的梯度,控制了L2损失函数容易引起的梯度爆炸现象发生.
4 实验结果及分析
本文实验环境包括:配备Inter(R)酷睿6核I7-6850k 3.7G Hz,显卡Nvidia Titan X 2016 4路交火,Ubuntu 14.04系统,Caffe[25]深度学习框架,算法基于C++和Python 3.4语言开发实现.
本实验的数据集包括公开数据集AFW、LFW、LFPW、HELEN、300-W和实验室自建视频监控数据库(Surveillance Video Face,简称SVF).实验室自建视频监控数据库采集室外不同环境下的人脸视频监控图像,人工标注人脸框以及人脸关键点位置,其中包括训练集1 500张,测试集500张.
在深度模型学习过程中,通过对实验数据观察,发现人脸关键点定位模型在某些特定数据集中不具备鲁棒性.通过对测试集的分析测试发现,测试效果有重大影响的部分测试集包括复杂光照、人脸姿态多样性等情况.在对人脸关键点公开数据集包括分析后发现公开数据集对以上复杂条件下的人脸样本缺乏.因此,本文针对人脸关键点数据集做了扰动,其内容包括:对人脸关键点公开数据集进行光线明暗、曝光度的数据增强;对输入人脸边框左右移动(-1.1,1.1),进行不同人脸边框的精确度的数据增强.同时使用常规数据增强方法,包括翻转、镜像操作来增加训练样本.
结合公开数据集、自建视频监控人脸关键点数据集以及数据增强数据后,共计173420张带人脸关键点坐标的人脸图片.随机从整个数据集中选择8 000张子集作为验证集,22 000张子集作为测试集.数据增强后示意图如图2所示.

图2 数据增强示意图Figure 2 Diagram of data augmentation
验证过程采用的性能指标为:平均测试误差(Mean Error),其公式为
(4)
其中,(x,y)为人脸关键点预测值,(x′,y′)是输出人脸关键点真实值,l是输入人脸检测边框的宽.
本节通过实验来验证改进的级联神经网络(命名为,Shortcut DCNN)以及提出的损失函数.本节从各个方面对上述内容进行实验验证并分析结果,再同其他算法进行效果比对.
4.1 数据增强在人脸关键点定位表现结果
证明数据增强提升网络模型对不同光照、人脸多姿态的鲁棒性.本文对数据集增强前后,分别训练神经网络模型,其中网络结构、损失函数和训练超参数设置相同,比对数据增强前后相同网络训练模型的测试结果.
实验结果如图3所示,分别针对公开数据集和自建SVF数据集数据增强前后进行模型训练与测试,人脸关键点定位效果比未进行数据增强训练的网络模型要好,尤其是应用在监控视频人脸数据测试集中效果明显.自建SVF数据集获取自然环境下视频监控数据集,对数据集进行光照、姿态、人脸边框扰动之后,训练的人脸关键点定位模型对于非约束条件下人脸关键点定位具有更好的鲁棒性.

图3 数据增强前后平均误差对比图Figure 3 Contrast diagram around data augmentation
4.2 不同网络结构在人脸关键点定位表现
对本文提出的网络改进方法和原有网络结构实验对比,具体网络结构参数如表1所示,使用相同训练集,分别训练DCNN和Shortcut DCNN,输入图片裁减为39×39大小,归一化训练图片.改进的网络结构相当于将网络增加两次卷积运算,共同输入到Elt-Wise层,增加输入特征尺度,将低层特征信息经过一个卷积运算后直接传到高层特征语义中,增加整个网络的特征挖掘能力.
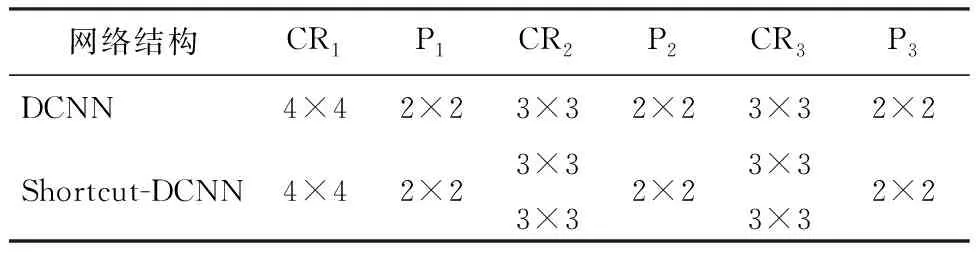
表1 DCNN与Shortcut DCNN卷积核大小对比表Table 1 Size of convolution kernel in DCNN and Shortcut DCNN
根据以上两种不同网络结构,实验结果如表2.在LFPW测试集上做测试并分析结果,第一级全局回归网络输出人脸关键点定位初始值阶段:观察每一个人脸关键点位置与真实值之间的输出误差,包括五个人脸关键点位置中每一个位置的平均测试误差(Mean Error).其中,左眼(LE)、右眼(RE)、鼻子(N)、左嘴角(LM)和右嘴角(RM).Shortcut DCNN比DCNN网络结构在每个人脸关键点的输出误差都要低.融合低层特征到高层语义的Shortcut DCNN在全局回归过程中,增强了网络特征提取能力.级联神经网络精确输出人脸关键点定位阶段:再次观察每个人脸关键点的输出误差,通过第三级的人脸关键点精确回归,每一个人脸关键点的输出误差都有所降低,而且Shortcut DCNN最终定位效果比原有结构要优越.通过两种实验结果证明了Shortcut DCNN网络结构在人脸关键点定位问题的有效性.

表2 不同网络结构在级联结构中输出误差对比Table 2 Mean error comparison of different cascade convolutional neural networks
4.3 Shortcut DCNN网络下,不同损失函数在人脸关键点定位表现
在确定了Shortcut DCNN网络结构的有效性之后,本实验分析损失函数对网络结构以及人脸关键点定位的影响.分别使用L2损失函数和Moderate Loss损失函数训练Shortcut DCNN神经网络.第一级全局回归网络输出人脸关键点定位初始值阶段:测试每一个人脸关键点的输出误差,对于同一个Shortcut DCNN网络结构,Moderate Loss损失函数在人脸关键点定位初始网络训练过程中能够有效训练深度网络,初始定位阶段有较低的误差率.级联深度神经网络精确输出人脸关键点定位阶段:验证了Moderate Loss损失函数针对不同的难易样本具有更好的收敛特性.
在训练过程中不会出现类似于L2损失函数出现的loss过大被迫训练中止,从而导致无法完成模型训练.L2损失函数训练过程中,预测值和真实值之间差距过大导致损失随着每层迭代越来越大,最后超过了浮点型表示范围,导致训练过程Nan报错而被迫中止训练.Moderate Loss损失函数能够通过判断预测值和真实值之间的差值,来区分难易样本,从而控制训练过程中损失值loss不会轻易变大,避免梯度爆炸问题.Moderate Loss损失函数相较于L2损失函数,更适合应用于人脸关键点回归定位问题.
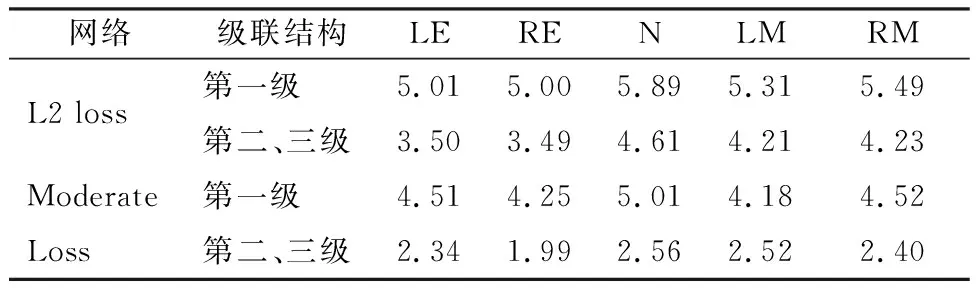
表3 不同损失函数在级联结构中输出误差对比
4.4 对比不同人脸关键点模型定位结果
对比不同模型在相同训练集训练,分别在LFPW和SVF自建视频监控人脸测试集的测试结果,验证人脸关键点在公开数据集和非约束条件视频监控人脸关键点鲁棒性.

图4 不同模型在LFPW测试集上平均误差Figure 4 Mean error comparison of different models on LFPW dataset
实验结果如图4,针对输出的每一个关键点平均误差,ESR和LBF基于机器学习形状回归方法在两个测试集误报较高.Shortcut DCNN和DCNN的平均误差比对结果,本文提出的级联人脸关键点网络训练出来的模型在五个人脸关键点误差较低且相似,得益于损失函数的使用.
实验结果如图5,在VSF自建监控视频测试集中,本文提出的级联人脸关键点定位平均误差相较于其他更低,效果优势明显.在非约束条件下,复杂环境下对人脸检测率和人脸关键点误差率影响较大,本文介绍的网络结构能够更好的提取特征,和DCNN相同网络深度下,通过快捷连接更好的融合了网络低层到高层的特征融合;同时,Shortcut DCNN的损失函数使用,提高了对难易样本的使用效率,很好的控制了平均误差.图6为不同模型在公开数据集LFPW以及自建数据集SVF上人脸关键点定位比较图.
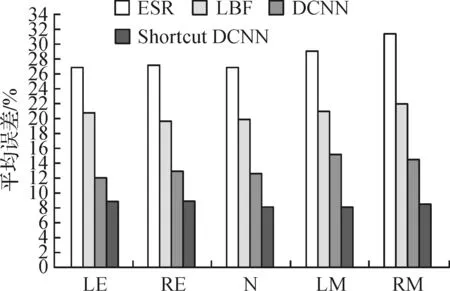
图5 不同模型在VSF测试集上平均误差Figure 5 Mean error comparison of different models on VSF dataset

图6 不同模型在公开数据集以及自建数据集上人脸关键点定位比较图Figure 6 Comparison diagram of different models on LFPWdataset and VSF dataset
5 结 语
人脸关键点定位是计算视觉领域的重要研究方向.本文提出了一种有效的跨层特征融合的级联卷积神经网络,级联人脸关键点回归网络在第一级网络结构中融合了跨层特征,输出全局人脸关键点初始位置;其中在损失函数的使用中,提出了一种有效控制异常Loss的回归问题损失函数,在非约束复杂条件下,该损失函数有效控制了训练过程中的梯度爆炸问题.在具体实验过程中,通过对实验现象的分析,学习到有针对性数据增强步骤的重要性,通过数据增强进一步提高了人脸关键点定位模型在非约束环境下的鲁棒性.
猜你喜欢
核安全(2022年3期)2022-06-29
今日农业(2021年8期)2021-11-28
建材发展导向(2021年11期)2021-07-28
计算机系统应用(2019年9期)2019-09-24
—— “T”级联
同位素(2019年1期)2019-03-14
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
新高考·高一物理(2015年5期)2015-08-18
中国交通信息化(2015年7期)2015-06-06
中国卫生(2014年2期)2014-11-12
