
基于情绪基调的音视频双模态情绪识别算法
2018-08-15 08:02卫飞高张树东付晓慧
计算机应用与软件 2018年8期
卫飞高 张树东* 付晓慧
1(首都师范大学信息工程学院 北京 100048)2(成像技术北京市高精尖创新中心 北京 100048)
0 引 言
在情绪识别领域,音频和视频的单模态情绪识别都取得较好的识别结果[1-2]。为了充分利用音频信号和面部表情的情绪信息,音视频双模态情绪识别被广泛研究。音视频双模态情绪识别的融合策略分为特征层融合、分类层融合和决策层融合三种[3-5]。其中决策层融合因为训练简单、不需要音频信号和视频信号时序的绝对同步等特性而被广泛采用。
在音视频双模态决策层融合过程中,音频和视频的单模态识别结果一致的情况占比71.21%,识别结果不一致的情况占比28.79%[6]。而现有决策层融合方法均未对音频和视频的单模态情绪识别结果不一致情况给予考虑,这使得融合后的情绪识别结果不准确。
情绪基调是对一段时间里人们情绪状态的整体刻画,对时间间隔里每帧的情绪状态具有指导意义[7-8]。当音频和视频的单模态情绪识别结果不一致时,可以使用情绪基调确定音视频双模态的整体情绪状态,并对音频和视频不一致的识别结果进行修正。
针对单模态间情绪识别结果不一致导致识别结果不准确的问题,本文将情绪基调考虑在内,提出了一种基于情绪基调的音视频双模态情绪识别算法。首先对音频和视频进行单模态情绪识别;其次对音频和视频的单模态识别结果进行线性加权和零均值归一化处理,得到音视频双模态的情绪基调;然后基于不同的情绪基调对单模态间不一致的识别结果进行修正;最后,基于情绪基调对音视频双模态进行决策层融合,得到最终的情绪识别结果。
1 基于情绪基调的音视频双模态情绪识别算法
基于情绪基调的音视频双模态情绪识别算法的流程如图1所示。
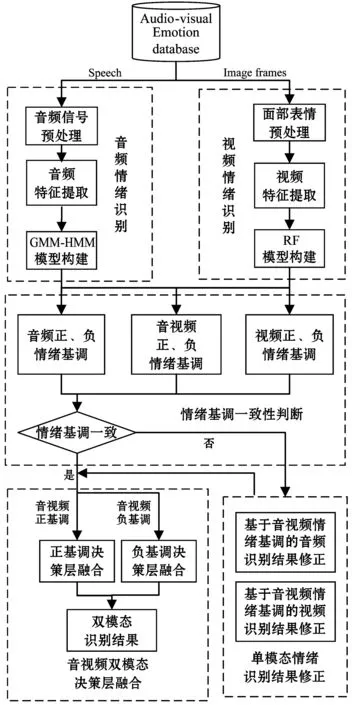
图1 基于情绪基调的音视频双模态情绪识别算法流程图
步骤一使用音视频情绪数据库进行音频和视频的单模态情绪识别。音频情绪识别过程包括音频信号预处理、音频特征提取和GMM-HMM[7]模型构建;视频情绪识别过程包括面部表情预处理、视频特征提取和RF[9]模型构建。
步骤二进行音频单模态情绪基调、视频单模态情绪基调和音视频双模态情绪基调一致性判断,若三者情绪基调不一致,进行步骤三,反之跳到步骤四。
步骤三基于音视频情绪基调对音频和视频的单模态识别结果进行修正。
步骤四在音视频正、负情绪基调下,分别对音视频双模态进行决策层融合,得到最终的情绪识别结果。
1.1 单模态情绪识别
对音频信号进行预处理,即使用3 s的滑动窗口进行片段切分,相邻片段之间有1 s的重叠。对所有音频片段使用OpenSMILE工具[10]提取AVEC2013.config对应的2 268维度的音频特征,并运用基于关联的特征选择和主成分分析方法(CFS-PCA)[7]进行特征降维。应用GMM-HMM模型进行模型训练和音频单模态的情绪识别。其中:GMM模型对特征向量的分布进行建模,HMM模型对音频的时序信息进行建模。
对于面部表情有遮挡的视频帧进行去除操作,采用局部二值模式(LBP)[11]算法提取图像帧的特征。使用RF算法对提取特征进行模型训练,并以RF叶子节点中视频帧的情绪值均值作为视频单模态的情绪识别结果。
1.2 情绪基调一致性判断
在音频单模态情绪识别过程中,每3 s对应一个音频片段,使用基于GMM-HMM模型得到其识别结果。在视频单模态情绪识别过程中,每20 ms对应一帧,使用RF模型得到其识别结果。为了保证音频和视频识别结果的同步,以音频片段时间窗口为基准,对窗口里帧的视频情绪值取均值,该值作为时间窗口中所有视频帧的情绪识别结果。
对音频和视频单模态情绪识别结果进行线性加权得到音视频双模态的情绪值:
Z=ω1X+ω2Y
(1)
式中:X为音频的情绪识别结果;Y为视频的情绪识别结果;ω1和ω2为双模态融合的权重系数;Z为音视频双模态的情绪值。通过大量实验证明,ω1和ω2设置为0.3和0.7时,音视频双模态的情绪值与实际标注结果最相符。

(2)
(3)
(4)
当音频与视频的单模态识别结果不一致时,音频情绪基调、视频情绪基调和音视频双模态的情绪基调三者也不一致。根据情绪基调具有对时间间隔里每帧的情绪状态进行指导的性质,以音视频双模态的情绪基调为基准,对音频和视频单模态的识别结果进行修正,使得音频情绪基调、视频情绪基调和音视频双模态的情绪基调三者达到一致。当三者情绪基调一致时,无需修正。
1.3 单模态识别结果修正
根据音频情绪基调的正、负情况,将音频样本划分为正基调样本和负基调样本两部分。针对不同基调的音频样本,我们采用不同的GMM-HMM进行训练。即正基调样本采用正基调GMM-HMM模型进行训练;负基调样本采用负基调GMM-HMM模型进行训练,得到正负基调的音频识别模型。以音视频双模态的正、负情绪基调为基准,音频样本使用相应基调的GMM-HMM模型进行修正。
视频采用RF模型进行单模态情绪识别,并把RF叶子节点中视频帧情绪值的均值作为情绪识别结果。修正过程中,选取RF叶子节点中视频帧情绪基调与音视频双模态情绪基调一致的叶子节点,对这些叶子节点的情绪值取均值作为帧的识别结果。其中,视频帧情绪基调通过帧情绪值的符号得出,若帧情绪值的符号为正数则为正基调,反之为负基调。
1.4 音视频双模态决策层融合
音频信号和人脸面部表情等信息的互补性,在一定程度上可以提高情绪识别的准确率[12-14]。根据音视频双模态的情绪基调可以将音视频样本分为正基调样本和负基调样本。在正、负基调下,使用相应基调的样本分别进行音视频双模态的决策层融合。将二者进行整合即可得到最终的音视频双模态情绪识别结果。
本文采用基于情绪基调的音视频双模态的线性相关性分析算法进行决策层融合。通过单模态间识别结果的相关性分析得到音视频双模态融合的权重向量,使用权重向量对两个模态的识别结果进行线性加权,得到音视频双模态的情绪识别结果。基于线性相关性分析的音视频双模态融合算法的伪代码见算法1。
算法1基于线性相关性分析的音视频双模态融合算法
Input: 音视频双模态融合的初始化权重向量θ=(1,1),音频和视频的识别矩阵M,音视频标注真值N
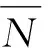
For每个音视频文件ido
Compute
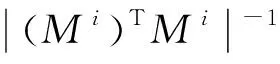
Endfor
Repeat
For每个音视频文件ido
Endfor
Until
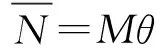
其中:
θ:2×1的音视频双模态融合的权重向量。
Mi:两列矩阵,对应音视频文件的音频和视频的单模态情绪识别结果。
Ni:音视频文件的真值,数据库提供。

ωi:音视频文件的回归向量。
ci:真值与融合结果的相关系数,ci越高,真值与融合结果越接近。
(5)
(6)
(7)
应用AdaBoost权重更新的思想,使用式(5)来迭代更新θ值,直到满足式(6)中的条件,计算得到融合权重的最优解。最终,通过式(7)计算得到音视频双模态的情绪识别结果。
2 实验及结果分析
SEMAINE数据库[15]模拟人机交互的环境,由20个被测者(8男,12女)与四种性格(温和、外向、生气、悲伤)工作人员进行交谈。该库含有95个音视频文件,每个音视频文件时长为3~5分钟,总时长约7小时。其中,音频信号采样频率48 kHz,量化位数24 bit;视频每秒50帧图像,像素值为580×780。SEMAINE是一个维度情绪的数据库,在Valence、Activation、Power、Expectation和Intensity五个维度上分别进行了标注,标注范围[-1,1]。
将数据集按照1∶1∶1的比例划分为训练集、验证集和测试集,其中训练集含有31个音视频文件,验证集和测试集各32个,并选取Valence和Arousal两个维度进行实验。使用基于情绪基调的音视频双模态情绪识别算法对SEMAINE库的Valence和Arousal维度情绪进行识别,并使用两个维度情绪识别RMSE和PCC的均值对识别结果进行衡量。在测试集上进行验证,音频和视频单模态的初始识别结果与基于情绪基调修正后的结果如表1所示。
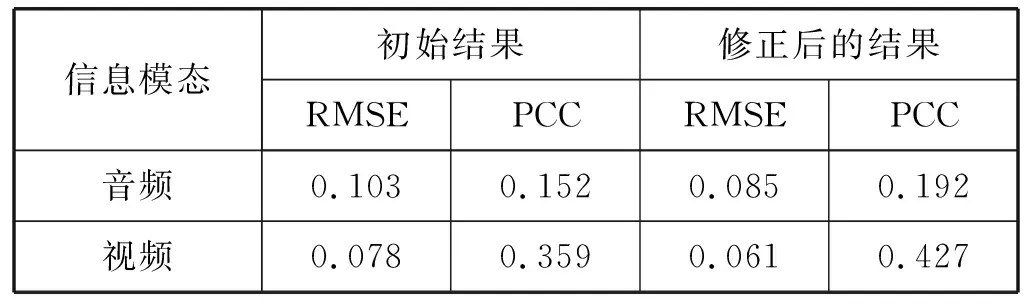
表1 单模态初始结果与修正后的结果
由表1可以得出,基于音视频双模态的情绪基调对单模态间不一致情况下的识别结果修正后,音频和视频单模态的RMSE得到降低,PCC有了一定程度的提升。对音频识别结果进行修正,RMSE由0.103下降到0.085,PCC由0.152提升到0.192。对视频识别结果进行修正,RMSE由0.078下降到0.061,PCC由0.359提升到0.427。
为了验证基于情绪基调音视频双模态情绪识别算法的准确性,分别使用不同的音视频双模态的决策层融合算法与本文算法进行实验,结果如表2所示。

表2 决策层融合结果
基于相同的音频和视频特征,使用不同的音视频决策层融合算法与本文算法进行实验对比。从表2可以看出,音频和视频都使用SVR作为单模态识别模型,采用线性加权算法(音频权重系数0.3,视频0.7)进行决策层融合,RMSE为0.079,PCC为0.328;音频使用SVR作为识别模型,视频使用RF作为识别模型,采用线性加权算法进行决策层融合,RMSE为0.083,PCC为0.344;音频使用GMM-HMM作为识别模型,视频使用RF作为识别模型,采用线性加权算法进行决策层融合,RMSE为0.057,PCC为0.378;音频使用GMM-HMM作为识别模型,视频使用RF作为识别模型,采用线性相关性分析算法进行决策层融合,RMSE为0.048,PCC为0.403;本文使用GMM-HMM模型进行音频情绪识别,使用RF模型进行视频情绪识别,引入情绪基调对单模态间识别结果不一致情况下的音频和视频情绪识别结果进行修正。在不同音视频双模态情绪基调下,分别使用线性相关性分析算法进行决策层融合,RMSE为0.035,PCC为0.461。相对于其他四种音视频双模态的决策层融合算法,本文算法取得的RMSE最低,PCC最高。证明了该算法的有效性和准确性。
3 结 语
在音视频双模态决策层融合过程中,当单模态间情绪识别结果不一致时,融合后的识别结果不准确。本文将单模态间识别结果不一致情况予以考虑,提出一种基于情绪基调的音视频双模态的情绪识别算法。当音频和视频的单模态情绪识别结果不一致时,本文创新性地使用情绪基调对两个模态的识别结果进行修正,解决了单模态间识别结果不一致导致融合后识别结果准确率不高的问题。决策层融合阶段,在不同音视频情绪基调下,使用线性相关性分析算法进行音视频双模态决策层融合,识别结果的准确率也有了一定提升。使用SEMAINE数据库对该算法进行验证,结果表明,音视频双模态情绪识别的RMSE得到下降,PCC得到提升。
猜你喜欢
汽车零部件(2021年4期)2021-04-29
VOGUE服饰与美容(2020年4期)2020-04-21
财讯(2019年24期)2019-09-03
家庭影院技术(2019年7期)2019-08-27
电子制作(2018年12期)2018-08-01
家庭影院技术(2018年2期)2018-04-18
思维与智慧·上半月(2018年2期)2018-02-08
电影文学(2016年19期)2016-12-07
商(2016年23期)2016-07-23
领导决策信息(2012年46期)2012-09-22
