
基于LSTM-Attention的中文新闻文本分类
2018-10-08 11:53蓝雯飞汪敦志潘鹏程
中南民族大学学报(自然科学版) 2018年3期
蓝雯飞,徐 蔚,汪敦志,潘鹏程
(中南民族大学 计算机科学学院,武汉 430074)
进入21世纪以来,互联网行业蓬勃发展,伴随而来的是信息快速传递的大数据时代.在海量的数据信息中,信息的表达方式呈现多样化,例如文本、图像和语音等.其中,文本作为信息的一种重要承载方式,相对于图像和语音等载体而言,具有容量占有率少,更方便地存储和管理的特点.但是,文本的表达并没有图像和语音那么的直观,需要人为地去阅读整个文本,然后理解其表达的含义,这种传统的人工方式显然不能适应当今信息呈现爆炸式增长的大数据时代.因此,在海量的文本信息中,如何快速准确地获取人们所需的,成为了一项值得研究的课题.
文本分类早期的研究主要是基于知识工程[1],其分类的规则需要人工地去定义然后提炼出来,再按照分类规则去构建分类器,该方法不仅耗费大量的时间和精力,而且还要求领域内的专家具有一定的经验.为了克服这种手工分类方式带来的困难,随着机器学习的兴起,机器学习文本分类技术开始取代早期的分类方法[2].深度学习作为机器学习的一个分支,近年来随着高性能计算的发展以及大数据时代的来临,已经在学术界以及工业界引起了广泛的影响,并渗入了各行各业.深度学习与传统机器学习最大的不同之处在于深度学习有自动获取特征的能力,这样就免去了传统方法在繁杂的特征工程中耗费的成本,本文的主要工作是利用深度学习模型解决中文新闻文本分类的问题.
1 相关研究工作
在文本表示方面,Collobert等人[3]提出了使用神经网络的方法自动学习词汇的向量化表示,其基本原则是:一个词包含的意义应该由该词周围的词决定.首先将词汇表中的每一个词随机初始化为一个向量,然后用大规模的语料作为训练数据来优化此向量,使相似的词具有相近的向量表示.这样的训练方法能够将适合出现在窗口中间位置的词聚合在一起,而将不适合出现在这个位置的词分离开来,从而将语义(语法或者词性)相似的词映射到向量空间中相近的位置.与替换中间词的方法不同,Mikolov等人[4,5]提出了一种使用周围词预测中间词的连续词袋模型(CBOW).CBOW模型将相邻的词向量直接相加得到隐层,并用隐层预测中间词的概率.同词袋模型一样采用的是直接相加,所以周围词的位置并不影响预测的结果.Mikolov等人还提出了一种连续Skip-gram模型,同CBOW模型的预测方式相反,连续Skip-gram模型通过中间词来预测周围词的概率.
在构建语言模型方面,Socher[6]采用了RNN进行句法解析,Irsoy等人[7]将RNN建立起深层结构,成为了一个典型的三层结构的深度学习模型.但是RNN在求解过程中存在梯度爆炸和消失问题[8],并且不适用于长文本,所以后来的研究者又在此基础上提出了长短时记忆神经网络LSTM(Long Short-Term Memory)[9],它是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件.如今,LSTM已经被应用在了许多领域,如机器翻译[10]、图像分析[11]、语音识别[12]等.总之,基于LSTM模型解决自然语言处理问题已经成为了当下的主流研究方向.
2 LSTM文本分类模型
RNN适合处理随时间变化的序列性问题,自然语言正好符合这一特点,因为人类处理语言的方式是按照从前往后随时间的顺序进行的,如果我们想要知道一句话的下一个词是什么,必须要知道前面几个词,所以利用RNN处理自然语言问题是最为直观的一种方式.由于普通的RNN神经网络结构不能解决长时依赖问题,所以更多地使用的是改进后的LSTM模型,图1和图2所示的是利用LSTM解决分类问题的两种典型的模型结构图.
图中的输入层x0,x1,x2,……,xt对应的是词向量,在输入层之上是一层正向的LSTM层,由一系列的LSTM单元组成,而如何将词向量融合为高一级别的句向量,图1和图2有各自不同的方式:图1把LSTM最后时刻的输出作为高一级的表示,图2把所有时刻的LSTM输出加和求平均后的结果作为高一级的表示.最后,在softmax层,进行全连接操作,得到最终预测的类别y.
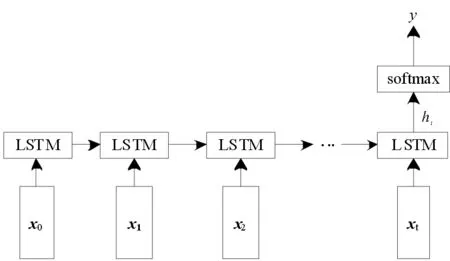
图1 NLP中的第一种LSTM分类模型Fig.1 First LSTM classification model in NLP

图2 NLP中的第二种LSTM分类模型Fig.2 Second LSTM classification model in NLP
3 LSTM-Attention模型
注意力机制最早是在图像领域提出来的[13],研究的动机是受人类注意力机制的启发.而在NLP领域,最早是在机器翻译上应用注意力机制[14,15].机器翻译使用的是一种典型的序列到序列(sequence to sequence)的模型[16],也是一种编码到解码(encoder to decoder)的模型[17].传统的机器翻译模型仅根据最后一个词学到的表达和当前要预测翻译的词联系起来,而加入注意力机制后,将源语言端的每个词学到的表达和当前要预测翻译的词进行联系.相比传统的机器翻译,加入注意力机制后的模型,效果有明显的提高.
上面提到的NLP中的两种LSTM分类模型,一种是利用LSTM最后时刻的输出作为高一级的表示,而另一种是将所有时刻的LSTM输出求平均作为高一级的表示.这两种表示都存在一定的缺陷,第一种缺失了前面的输出信息,另一种求平均没有体现每个时刻输出信息的不同重要程度.为了解决此问题,引入Attention机制,本文对LSTM模型进行改进,设计了LSTM-Attention模型,如图3所示.

图3 LSTM-Attention模型Fig.3 LSTM-Attention model
图中输入序列为一段文本分词后的各个词的向量表示x0,x1,x2,…,xt,将每个输入传入LSTM单元,得到对应隐藏层的输出h0,h1,h2,…,ht.这里,在隐藏层引入Attention,计算各个输入分配的注意力概率分布值α0,α1,α2,…,αt,其思想是计算该时刻的隐藏层输出与整个文本表示向量的匹配得分占总体得分的比重,αi,j∈[0,t]的计算公式如下:
(1)

(2)
其中w,W,U为权值矩阵,b为偏置量,tanh为非线性激活函数.
得到各个时刻的注意力概率分布值以后,计算包含文本信息的特征向量v,计算公式如下:
(3)
最后,利用softmax函数得到预测类别为y,计算公式如下:
y=softmax(Wvv+bv).
(4)
本文采用梯度下降法训练模型,通过计算损失函数的梯度逐步更新模型的参数,最终到达收敛.为了使目标函数收敛得更加平稳,同时也为了提高算法的效率,每次只取小批量样本进行训练.模型使用交叉熵损失函数,计算公式如下:
(5)

4 实验
4.1 实验准备
本文的实验是在Window10系统下进行的,使用的CPU是Inter Core i5-2450M 2.5GHz,内存大小为6GB.实验编程语言为Python3.0,开发工具为Pycharm,使用到的深度学习框架为Tensorflow1.0.1.本文的实验数据集来源于搜狗实验室中的搜狐新闻数据,从中提取出用于训练中文词向量的中文语料,大小约为4GB左右.然后选取了5个类别的新闻数据,分别为财经、汽车、娱乐、军事和体育.每个类别新闻为2000条,共10000条新闻,利用这10000条数据来评估模型的分类效果.
4.2 实验设计
本文采用LSTM模型,对中文新闻文本进行分类.为了评价分类模型的效果,通过精确率(Precision)和召回率(Recall)以及F1值对分类结果进行衡量. 为了说明注意力机制对分类结果的影响,将本文使用的LSTM-Attention模型的分类结果,与经典的LSTM两个分类模型的分类结果进行对比.另外,为了说明基于LSTM模型分类的优势,在同样的数据集上利用传统的机器学习分类模型对文本进行分类,然后将分类结果进行对比,使用的机器学习方法包括支持向量机(SVM)[18]、最近邻(KNN)[19]、朴素贝叶斯(NB)[20].为了排除由于特征构建方式不同而导致实验结果没有可比性,利用传统机器学习的特征构建方式同样是基于词向量,每条新闻文本的特征取为所有词向量均值.
4.3 实验结果及分析
TensorFlow中的 TensorBoard 可视化工具,可以通过读取 TensorFlow训练后保存的事件文件,展示各个参数的变化图.图4、图5分别所示的是TensorBoard中,LSTM、LSTM-Attention在模型训练完成后,模型训练损失值随迭代次数的变化图.
从图中可以看出所有模型在利用梯度下降法进行训练时,函数损失值是逐渐下降的,并最终趋于稳定收敛状态.引入Attention机制后的LSTM模型,相比于原来的模型而言,由于模型复杂度的增加,造成起始的损失值变大,但收敛速度是有所增加的.由此可见,Attention机制对模型的分类识别能力是有一定的影响力的.

图4 LSTM模型训练损失变化图Fig.4 LSTM training loss change diagram

图5 LSTM-Attention模型训练损失变化图Fig.5 LSTM-Attention training loss change diagram
表1所示的是不同分类模型的整体平均Precision值、Recall值和F1值比较结果.

表1 不同分类模型的平均分类结果比较
从表1所示的结果可以看出,在相同的数据集上,以word2vec训练的词向量作为文本特征,除了NB分类模型分类效果较差,其他分类模型均取得了较好的分类效果,可以证明word2vec训练的词向量能够很好的描述文本特征.另外,LSTM分类模型以及LSTM-Attention分类模型的分类效果要比传统的机器学习分类模型好,原因在于Attention计算了文本中每个词分配的注意力概率分布值,这样可以有效地提取出文本中的关键词,而关键词对文本的语义表达起到了重要的作用,说明Attention对文本分类性能的提升起到了一定的作用.
5 总结
本文利用word2vec训练大规模中文新闻语料,从大量的文本信息中得到中文词的词向量,作为文本的特征表达.相比于传统的机器学习提取特征的方法,word2vec可以自动将语义信息浓缩进数学向量中.基于词向量的文本表示方法,本文对LSTM分类模型进行了改进,引入了Attention机制.Attention的计算是可微的,可以通过反向传播训练,适用于深度学习中的网络结构,由此设计了LSTM-Attention模型.从实验结果也可以看出,引入Attention机制后的LSTM模型对文本的分类效果有了一定程度的提升.但是,Attention机制的应用也有一定的限制,它需要耗费一定的计算成本,因为需要为每个输入输出组合分别计算注意力分配的概率值,一旦输入输出序列增加,Attention计算量随之呈指数级增长.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
