
重删环境下双B-树索引性能优化研究
2018-10-08 11:53曹鸿源
中南民族大学学报(自然科学版) 2018年3期
周 斌,曹鸿源
(中南民族大学 计算机科学学院,武汉 430074)
根据国际数据公司IDC[1]预测,2020年全球数据总量将会达到甚至超过40ZB[2].目前提出的重复数据删除技术,虽然能在很大程度上节省系统的存储空间,但是重复数据删除系统的性能和扩展性仍面临着巨大的挑战[3].同时,指纹索引的出现加快了检索的速度和效率,但是随着全球数据量呈现爆炸式增长,指纹数据量也随之飞速增长.例如:存有800 TB大小的数据,假设切分得到的数据块的平均大小为8KB,那么将至少产生2 TB的SHA-1(20Byte)指纹[4],这些指纹数据量仍是非常巨大的.由于内存存储量有限,过多的指纹只能存放在磁盘中,随着访问磁盘次数增多,必然导致重复数据删除系统的检索性能下降.目前的索引机制研究按索引结构分类,可分为:(1)哈希索引机制研究[5-7],主要聚焦于哈希表.哈希表是一种数据结构,具有快速写入和读取的优点.但哈希表仍存在一些不足之处,由于哈希表是基于数组结构,如果哈希表被基本填满,性能会下降得非常厉害;(2)树型索引机制研究[8,9],主要聚焦于B树.B树具有良好的扩展性和插入删除的性能,其中,优化的B树中,B-树可以在非叶子节点结束查询,B+树具有良好的空间利用率,但是B树不适合过大数量的数据索引,树的高度过大会严重影响查询速率;(3)位图索引机制研究,主要聚焦于布隆过滤器.布隆过滤器主要用于识别一个数据块或关键字是否存在于存储容器中.但是布隆过滤器很大的缺点就是不能插入数据块,也不能删除已有数据块.并且随着容器中数据块的增多,误报率也将随之变大.为了提高重复数据删除系统的性能,本文在国内外相关研究的基础上,围绕指纹索引结构,提出一种基于双B-树索引检索性能的优化方案.
1 基于双B-树索引结构
双B-树索引结构是由两棵树结构不同的B-树构成,如图1所示:
(1)对于第一棵B-树B-tree-1,根据B-树的特点,优化树结构.为尽可能的减少B-树的遍历次数,增加了B-树每个节点(磁盘页)中的指纹数量,同时增加了节点分支的数目,从而使B-树的高度更小,由此可以提高指纹的检索效率.
(2)对于第二棵B-树B-tree-2,是在B-树的基础上,结合了LRU(Least Recently Used)算法,设定B-tree-2树的存储数量为B-tree-1的1/m(m具体最优值在实验中得到),利用LRU的最近最少使用的思想,提高B-tree-2检索命中率,从而提升了系统的检索效率.
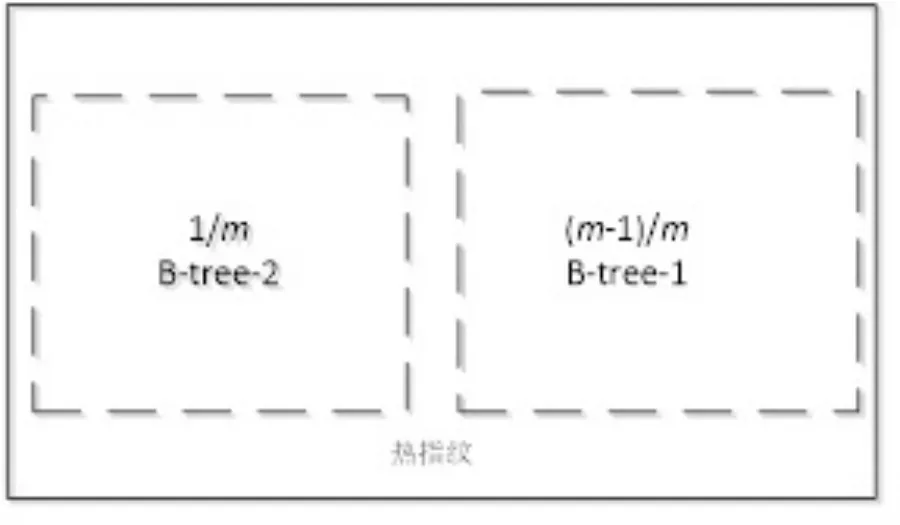
图1 双B-树示意图Fig.1 Double B-tree schematic diagram
1.1 B-tree-1
B-树的高度决定着系统的读取效率,在这里把B-tree-1设计成“矮扁平”形状.如图2所示,因为B-树的时间复杂度与树的高度有关,树越矮,时间复杂度越低.同时增加每个节点的指纹数量,在不影响树的承载量的情况下,减少磁盘访问的次数,从而提升了系统的读取效率.

图2 B-tree-1树示意图Fig.2 B-tree-1 schematic diagram
1.2 B-tree-2
在数据管理系统中,研究人员对数据库索引技术的研究一直未曾停止过.就目前数据库系统应用需求来看,数据库索引结构优化和提升的空间仍旧很大.在现有系统应用中,Hash索引、二叉树索引、B-树索引和TRIE树索引等是使用较为普遍的索引结构.由于B-树的检索速度快,且可以在非叶子节点处结束遍历,并且B-树也很适合改进,因此,B-树索引得到了广泛的应用.目前,存在的B+树等,就是在B-树的基础上改进而来的.
在实际应用中,数据访问一般是随机的,且当前访问时间最近的数据,有可能在近段时间再次访问.如果让B-树缓存中始终保留这些数据,那么可以大大减少外部存储访问的次数,进而提高重复数据删除的检索性能.为此,本文设计中,在B-树的基础上加入了LRU算法.
LRU(Least Recently Used,最近最少使用)[10,11]算法是根据数据的历史访问记录来清除数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”.在由LRU算法优化而来的算法中,LRU-2,MQ(2),2Q三种算法,虽然都能提高数据查询的命中率,但是其复杂度和付出的代价也相应提高,4种算法对比如表1所示:

表1 LRU系列算法的对比
根据表1中的数据可以明显看出,随着命中率的提升,算法的复杂度和代价也相应地提高,在此基础上考虑,为了能够提高B-tree-1的命中率且尽量减少复杂度,本文选择了经典的LRU算法.
在LRU算法设定中,计数器为命中的缓存计数,当缓存空间不足,并且不需要清理数据的时候,通过遍历所有的计数器,将最少使用的数据替换.LRU算法的弊端在于假如缓存空间和缓存的数据都较大,需要清除数据的时候,则需要遍历所有计数器,就会造成比较严重的性能与资源消耗,导致检索效率降低.
为达到高效的检索性能,仅仅只有LRU算法的计数功能已经不能满足本文的需求,本文针对传统的LRU算法进行了改进:
LRU自带的计数功能虽然可以很好记录最新访问的数据,并使其插入或者调动到链表的头部,但是随着B-tree-2中指纹数量的增加,遍历所有计数器的时间也会增加,这给内存开销增大了压力.鉴于此,假设在LRU中的链表中加入时间参数T,即,在时间T内未被访问,便被淘汰掉.这样不仅保存了LRU算法原本的优点,还可以和B-tree-2高度融合,适配了B-tree-2的需求.
B-tree-2的主要原理是,避免大量的检测和计数器的遍历所带来的系统开销,在这里设定一个时间参数T,每间隔一定时间T,检测该节点的数据指纹有无被访问,没有则清除该节点释放缓存,如图3所示.为此,再为节点加入一个时间点t,用来标记最近一次访问的时间点,数据指纹一但在T时间内被访问,t就会自动刷新到被访问的时刻.因为树状索引父节点的存在,如果父节点未被访问的时间大于设定的时间参数T,且此父节点下的子节点也在时间参数T内未被访问,那么父节点及其子节点才会从索引中全部淘汰.

图3 B-tree-2树示意图Fig.3 B-tree-2 schematic diagram
算法中,引用了指纹访问频次以及最近一次操作时间,从而得出此指纹热度值,如果一个指纹被引用的次数越高,并且被引用的时间越新,则这个指纹就会被长时间留在B-tree-2索引中,反之则会被释放掉.
2 实验结果与分析
为了测试本文提出的基于双B-树的索引结构算法的有效性和优越性,本文通过实验得到DBIS算法与B-树的写入、读取和删除速度,并将实验结果进行了比较和分析.
在模拟系统中使用可变长切分算法对文件进行分块处理,选用基于文件内容进行数据切分的CDC算法,每个数据块设置为平均4kB.采用哈希算法是SHA-l算法,并且对于长度小于264位的消息,SHA-l会产生一个20个字节的信息,作为数据块的指纹,识别数据块.索引结构选用传统的B-树索引结构和双B-树索引结构.实验中m的取值为1/15,时间参数T的取值为0.15s.
2.1 写入性能测试
实验开始先分别初始化B-树和DBIS树,接着将已经通过重复数据删除系统处理函数产生的数据指纹进行写入,同时,通过使用编译器本身带有的计时器作为系统时间计时器,并统计得出DBIS树索引和B-树索引在不同索引量的情况下,写入操作分别所需要的时间.具体测试结果如图4所示.

图4 DBIS树与B-树插入性能对比图Fig.4 DBIS and B-tree insertion performance comparison diagram
由图4可见,DBIS树在写入性能上比基本的B-树差,DBIS树的复杂度要比B-树相对较高.DBIS树插入时同时要考虑两棵树的计算时间,B-tree-2在给B-tree-1传递消息的同时,B-tree-1要给B-tree-2一定消息回复,这导致了更多的时间消耗.
2.2 读取性能测试
读取性能测试是在已经写入100000条随机选取的数据情况下进行,同时通过编译器自带的计时器进行计时操作,统计出DBIS树索引和B-树索引在不同指纹数量的情况下,读取操作分别所需要的时间.测试分别采用随机生成5000、10000、15000、20000条查询条件,并测试DBIS树索引和B-树索引所需时间并比较,具体测试结果如图5所示.
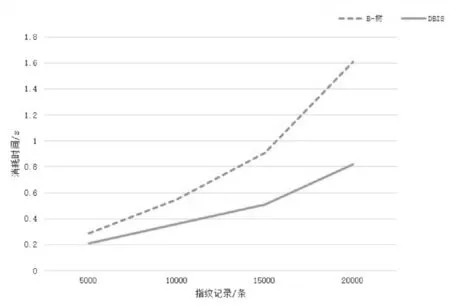
图5 DBIS树与B-树读取性能对比图Fig.5 DBIS and B-tree reading performance comparison diagram
由图5可见,DBIS树具有较为良好的读取性能,由于B-tree-2检测命中率的提高,很大程度上节约了时间,而且B-tree-1的“矮扁平”的特点,减少了访问次数,进而也减少了检索的时间,所以读取性能相对于传统B-树应用于内存数据库中的情况有较好的优化和改善,并随着读取数据量的增加会有更明显的提升.
2.3 删除性能测试
删除性能测试是在已经写入100000条随机选取的数据情况下进行,同时通过编译器自带的计时器进行计时操作,统计得出DBIS树索引和B-树索引在不同指纹数量的情况下,删除操作需要花费的时间.测试分别采用随机生成5000、10000、15000、20000条查询条件,并测试DBIS树索引和B-树索引所需时间并比较,具体测试结果如图6所示.
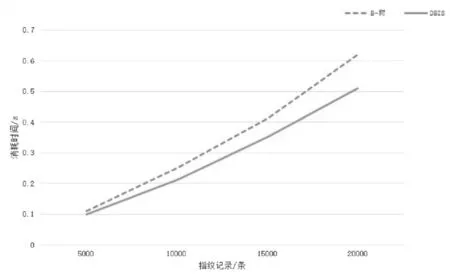
图6 DBIS树与B-树删除性能对比图Fig.6 DBIS and B-tree deleting performance comparison diagram
由图6可以得出,DBIS树索引删除操作要比B-树索引操作更节约时间,能够快速地定位到要删除的对象,便能更快地删除要删除的对象.
通过以上的几个模拟对比试验,可以得出:基于双B-树的索引结构在内存中保存热指纹的特性,优化了重复数据删除系统的读取和删除性能.
3 结束语
当前,重复数据删除技术是一个研究热点,企业界和学界对此技术的研究和改进仍在继续,而在重复数据删除系统中,指纹索引的优化对系统性能的提升起着尤为重要的作用.优化的指纹索引可以减少因多次访问磁盘给CPU带来的额外开销和消耗的大量时间,但是目前的指纹索引读写效率低下,特别是读的性能相对较弱等.为了改进以上不足,针对系统索引结构的读性能优化方面,本文提出了基于双B-树的索引结构检索性能优化方案.具体内容如下:
(1)索引的优化是对重复数据删除系统性能提升的一个重要方向,通过对索引结构等相关技术的深入研究,本文总结了当前索引结构的优缺点,指出了索引结构中读性能处于瓶颈的状态;
(2)本文提出的基于双B-树索引结构,并将此索引结构应用到内存中,旨在减少磁盘访问次数,提高重复数据删除系统的性能.详细介绍了B-tree-1和B-tree-2实现思想和步骤,并在理论上说明了此索引结构对提高系统读取性能的有效性;
(3)改进了LRU算法,在LRU算法中加入时间参数,提高了热指纹的命中率,使其更适配于B-tree-2;
(4)最后与传统的B-树索引结构进行了比较,实验结果表明本文所设计的索引优化方案,有效地提升了系统的读取性能.
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
机械工业标准化与质量(2022年6期)2022-08-12
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
儿童时代·快乐苗苗(2016年2期)2016-10-22
