
大数据技术在油田套损井防治中的应用研究
2018-10-19 05:37阮杰
数字通信世界 2018年9期
阮 杰
(中国石油大港油田信息中心,天津 300280)
1 引言
本文基于大港油田公司多年来积累的大量井筒专业数据及生产数据,在正常和套损井构成的大量数据样本中,利用大数据技术了解大港油田套损井分布、套损井发生规律、套损井主控因素,进而预测套损井发生概率,为油田公司套损井的防治工作提供建议和指导,以更好的实现对套损井的防治。
2 大数据技术基本概述
数据挖掘是大数据技术数据分析、处理的核心,是规律发现及预测的主要技术,随着科技的发展,数据挖掘不再仅仅依赖在线分析等传统的分析方法。它结合了多种学科知识,并把这些复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,从而更专注于自己所要解决的问题。通过数据挖掘分析软件,可以高度自动化地分析数据,做出归纳性的推理,从海量数据中挖掘出潜在的、有价值的知识、模型或规则,并对未来情况进行预测,以辅助决策者评估风险、做出正确的决策。
大数据挖掘技术相比于传统的数据挖掘分析,具有数据量大、查询分析复杂等特点,大数据与云计算密不可分。大数据技术的战略意义不在于掌握庞大的数据信息,而在于掌握对这些含有意义的数据进行专业化处理的技术。
大数据的特色在于对海量数据进行分布式数据挖掘,它必须依托互联网的云服务进行分布式处理、分布式数据库和云存储等。如果把大数据比作一种产业,那么这种产业实现盈利的关键是提高对海量数据的“加工能力”。简单地说,大数据技术就是从各种各样类型的数据海洋中,快速获得有价值信息的能力。
3 大数据技术实现套损井防治研究
为探讨大数据技术在油田企业套损井防治中的研究和应用,我们选择了大港油田港西油田套损井开展了具体研究,主要思路和过程如图1所示:

图1 大数据技术实现套损井防治主要思路和过程
通过各个环节的递进,明确多因素情况下,港西油田套损井发生的主要因素,实现对套损井发生情况的预测,明确主控有针对的开展相关防护工作,实现对套损井防治。
根据分析的主题,我们对港西油田各类单井的砂岩段小层数据、射孔数据、套管数据进行了整理实现近千口井、五千余条数据的整理。
3.1 数据挖掘技术进行规律发现
在上述数据的基础上,我们开展了基于岩性、井筒名义寿命、钢级、套损位置深度等单因素的分析及数据样本的分析和拟合。根据相关数据,我们拟合出了套损部位名义寿命在不同岩性中的概率密度曲线,横轴为名义寿命,纵轴为名义寿命对应的概率密度值。
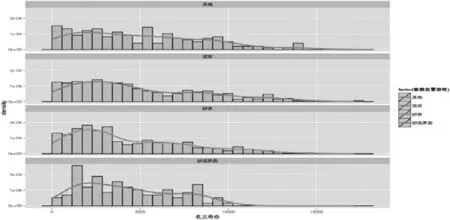
图2 套损井岩性、名义寿命分布拟合曲线
如图2可看出,对于这四种岩性类别,名义寿命的峰值都在2500天左右,概率密度在1到2×1014范围内通过对套损位置深度的概率密度分析,拟合出的套损位置深度在不同岩性中的概率密度曲线,横轴为套损位置深度,纵轴为套损位置深度对应的概率密度值。
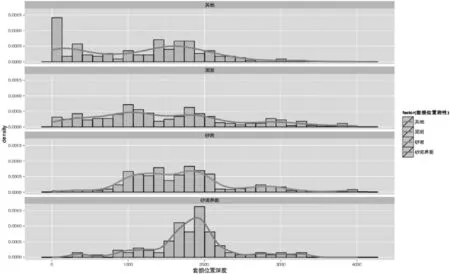
图3 套损位置深度、套损位置岩性分布拟合曲线
在图3这四种岩性类别中,沙泥界面的套损位置深度有明显的峰值,在2000米左右,近似于正态分布,其峰值介于0.0015和0.0010之间,表明沙泥界面岩性中发生套损的深度多为2000米左右。
通过以上因素的共同考虑,对名义寿命、套损位置深度、套损位置岩性因素进行散点图的绘制,并拟合曲线,如图4所示:

图4 名义寿命、套损位置深度、套损位置岩性散点分布图
根据散点图可以看出数据主要分布在深度小于3000米名义寿命小于10000天的范围,根据散点图,使用stat_smooth()平滑函数拟合出曲线图如下:由此可见,对于套损位置岩性为砂岩和其他类型的情况,样本的套损发生位置深度随名义寿命的增加而递减;对于套损位置岩性为泥岩和泥沙界面的情况,在名义寿命随深度增加程总体递减,但在递减过程中,均出现先增后减的情况。

图5 根据散点图拟合出的曲线
3.2 基于机器学习的套损井防治模型研究
在规律分析的基础上,基于R语言我们开展了基于机器学习的数据挖掘模型的构建。首先我们开展了相应的数据清洗,数据清洗的主要目的是去除去缺失的观测(没有进行插补,因为数据量够用),把因变量进行因子化,在清理完成之后,通过分层随机抽样对对样本进行了分类和分组。
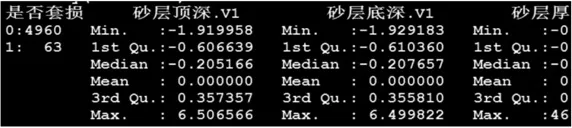
图6
考虑到量纲的影响,进一步对数值型变量进行标准正态scale标准化处理,以确保所有数据在统一的量纲下进行分析和应用。反复比较数据的抽样及分类特征发现,套损井主控因素的研究模型建立宜采用“随机森林”的方法建模分析和特征提取,在基于随机森林算法进行特征提取的过程中,为增强结果的可靠性,引入十折交叉验证方式算法(ten-foldcross validation)。
通过模型的构建,利用分层随机抽样的方式,分别随机选取25%的样本构成测试集,75%的样本构成训练集。通过十次10折交叉验证,其精度都在98%以上,说明模型的预测精度较高。随后,模型针对之前输入的各种特征变量给出了影响港西油田套损井发生的4个重要特征,即为钢级、砂层厚度、水泥返深、渗透率。
基于该算法构建的模型,我们随机抽了了大港油田港西油田21组数据进行相关的验证,通过模型的运算得到结果与实际情况基本吻合,进而验证了模型的基本可用性,也为该模型的正式应用奠定了基础。通过该模型的研究,可以快速的针对特定区块进行套损井主控因素的发现,为专业研究人员提供了基础的套损井发生因素的说明,针对相应的主控因素可以快速的开展有针对的措施应对,以防止或延缓套损井情况的发生,以确保生产的平稳、有序开展。
4 结束语
本文基于油田生产过程中套损井防治的场景,利用大数据技术进行相关机理的研究,对大数据技术的具体应用进行详细的了解和应用,实现了大数据技术在油田套损井防治中的应用,为后续的深入应用奠定了坚实的基础。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
云南化工(2020年11期)2021-01-14
数学学习与研究(2020年15期)2020-11-28
物理与工程(2019年1期)2019-03-22
录井工程(2017年3期)2018-01-22
录井工程(2017年1期)2017-07-31
电力与能源(2017年6期)2017-05-14
当代化工研究(2016年7期)2016-03-20
信息通信技术(2015年6期)2015-12-26
河北建筑工程学院学报(2015年2期)2015-04-29
