
基于采样的超球体聚类离群点检测算法*
2018-10-25 01:00高荣芳董振涛夏海洋
中北大学学报(自然科学版) 2018年5期
高荣芳,董振涛,夏海洋
(西安石油大学 计算机学院,陕西 西安 710065)
0 引 言
离群点检测是数据检测中的热点研究方向之一,其目的主要是为了消除噪声或发现潜在的且有价值的信息,是当今数据检测领域一个重要的研究问题. 离群点检测广泛应用于金融交易、网络安全、欺诈检测和故障检测等领域[1].
传统的离群点检测算法主要有基于分类的算法,如Liu B等人提出的基于SVDD的离群点检测算法[2],Yang J等人提出的自适应权重的One-class-svm的离群点检测算法[3],以及An W等人提出的改进SVDD的离群点检测算法[4]等. 然而基于分类的离群点检测算法只适合于低比例的离群点检测任务,在处理高比例离群数据时算法精度较低. 由于聚类算法可以对相似点进行聚类的特点,使得聚类算法很容易被用到离群点检测中,因此在近几年,基于聚类的离群点检测方法成为研究的热点,如左进等人提出的基于K均值聚类的离群点检测算法[5],梅孝辉等人提出的基于DBSCAN聚类算法改进而来的LDBSCAN-CM离群点检测算法[6],Duan等人提出的基于OPTICS聚类的离群点检测算法[7],以及吕宗磊等人提出的快速超球体聚类离群点检测算法[8]等. 基于聚类的离群点检测算法对数据集的适用能力较强[9],可以处理多分布数据集的离群点检测问题[10],使得其应用场景更加灵活. 然而,由于现有的基于聚类的离群点检测算法不能给出数据点的离群程度,使其无法满足特定领域的功能需求,例如故障检测中对故障等级的确定,金融交易中一笔异常交易的可疑程度等,都需要对检测对象做离群程度的等级划分. 为了使快速超球体聚类算法能够对离群点进行定量描述,提高离群点检测的精度和召回率,本文提出了一种基于采样的超球体聚类离群点检测算法(Sampling-based Hyper-sphere Clustering Anomaly Detection Algorithm,简称SHCAD).
1 快速超球体聚类离群点检测算法
快速超球体聚类离群点检测算法(Fast Hyper-sphere Clustering Anomaly Detection Algorithm,简称FHCAD). FHCAD算法根据用户自定义超球体密度阈值和连接度阈值来进行离群点检测,其中超球体密度描述的是超球体内的空间中数据点数量的多少,连接度描述的是两个在空间中相交的超球体间的余弦距离. FHCAD算法的离群点检测过程分为如下两个步骤.
首先,FHCAD算法根据用户自定义密度阈值,在数据集中随机选择一个数据点作为球心,不断将周围的数据点纳入超球体中,并计算超球体的密度,当超球体的密度大于等于给定的密度阈值时,则完成一个超球体的聚类,并继续对剩余的数据点进行超球体聚类,直到将满足密度阈值的超球体全部聚类完成,不在任何一个超球体中的数据点被判定为离群点.
在聚类生成超球体后,FHCAD算法通过判断两个超球体之间的连接度,来进行超球体合并,如果其连接度大于给定的连接度阈值,说明两个超球体的距离足够接近,则这两个超球体被合并为一类,最终未能被合并的超球体,其包含的数据点被判定为离群点.
FHCAD算法通过两步计算,检测数据中的离群点,具有较好的召回率,但其密度阈值和连接度阈值设置困难,应用受到限制,并且其在超球体聚类过程中容易将离群程度较低的数据点纳入到超球体中,因此算法的精度较低.
2 SHCAD算法
2.1 相关概念和定义
假设原始数据集为X,其中的样本个数为n,x(x∈X)表示数据集X中的一个数据点.

聚集度c(x)是用来描述超球体类中包含的所有数据点的聚集程度,如果一个超球体内包含的数据点个数越多,则表明球心数据点的聚集度越大.
离群度s(x)描述的是一个数据点的离群程度,离群度越大则其为离群点的概率就越大.
定义1 假设在第k次数据划分中,一个超球体类中包含w(1≤w≤p)个数据点,则其球心数据点x的聚集度为
ck(x)=w/p.
(1)
SHCAD算法对原始数据集X进行L次数据划分,数据点x会产生L个聚集度,取均值作为最终的聚集度值,增强聚集度的鲁棒性,其计算公式为
(2)
定义2 假设对原始数据集共进行L次数据划分,则数据点x的离群度可表示为
s(x)=1-c(x).
(3)
2.2 算法思想
SHCAD算法的核心思想,就是通过多次数据划分,在每次数据划分中,通过数据采样,多次计算空间数据点的聚集度,取均值得到鲁棒性的聚集度,进而得到具有鲁棒性的离群度,从而描述每个数据点的离群程度,而不是定性地给出结论,一个数据点是否为离群点. 该算法实质上是描述了一个数据点在整个数据集上的密度情况,也即密度稀疏的数据点的离群度较大,密度稠密的数据点离群度较小.
新的聚类形式得到所有数据点的离群度的取值范围是在(0,1)区间,如图 1 所示.
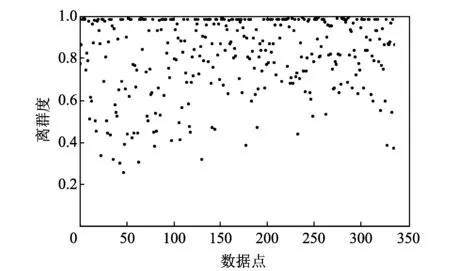
图 1 数据点的离群度Fig.1 Outlier degree of data points
2.3 SHCAD算法设计
2.3.1 数据划分
2.3.2超球体聚类
SHCAD算法在进行超球体聚类时,首先计算每个数据子集的超球体半径r,然后对于每个数据子集以半径r进行超球体聚类.
在原始数据集X中,将所有数据点表示为空间向量形式,设X表示原始数据集X中所有数据点的向量集合,故X=(X1,X2,…,Xn),Xi(1≤i≤n)表示一个向量,其中n为向量个数.
在一个样本子集中,取其中两个向量Xi和Xj,Xi=(xi1,xi2,…,xim),Xj=(xj1,xj2,…,xjm),其中m表示分量的个数,设Q=(q1,q2,…,qm),qm表示向量Xi和Xj的第m个分量之间的距离,表达式为
qm=1+|xim-xjm|,
(4)
向量Xi和Xj间的乘法距离可表示为MD(Xi,X),设E=(e1,e2,…,em),其中em是第m个维度上对MD(Xi,Xj)乘法距离的影响因子,所以乘法距离公式为
(5)
超球体半径r是由样本子集中所有数据点的之间的平均距离所得,可表示为
(6)
然后依次选择数据点为聚类中心,判断其与周围数据点之间的乘法距离,如果小于半径r则聚为一类,称每个类为一个超球体. 含有p条数据的数据子集中会聚类产生p个超球体.
2.3.3 离群度计算与离群点检测
SHCAD算法通过多次计算得到稳定的离群度,其可以定量描述数据点的离群程度,为离群点检测提供了有力支持.
由式(1)~(3)可知,每个数据点的离群度实质上描述的是这个点周围数据在整个数据集中的相对密度,离群度越大,说明这个点周围的数据点稀疏,则其为离群点的概率就越大,如果一个点的离群度越小,就说明这个点周围的数据点稠密,则其为离群点的概率就越小.
离群点的检测根据所有数据点的离群度大小来确定,首先,需要自定义一个离群度阈值δ(0<δ<1),然后判断数据点x的离群度s(x)与δ之间差值V(x),其判别公式为
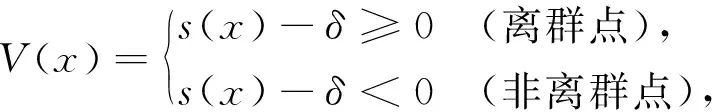
(7)
V(x)值越大,表明数据点离群程度越大,越偏向离群点.V(x)值越小,表明数据点离群程度越小,越偏向正常点,而V(x)取值取决于离群度阈值δ,所以离群度阈值δ取值是否准确将直接影响算法的精度和召回率,所以在实验中将会对δ的取值给出建议.
3 实验及结果分析
3.1 数据来源
实验采用了分别采用了Beijing,Ecoli[11],KDDCUP-99Finger[12]和KDDCUP-99Other[13]四组公开数据集. 其中Beijing为从2013年12月到2017年4月期间的北京空气质量数据集,来自中国空气质量在线监测分析平台(http:∥www.aqistudy.cn),Ecoli是不同亚种的大肠杆菌类别数据集,KDDCUP-99Finger和KDDCUP-99Other数据集为1998年美国国防部高级规划署在MIT林肯实验室收集的网络入侵数据. Ecoli、KDDCUP-99Finger和KDDCUP-99Other三个数据集都来自UCI(http:∥archive.ics.uci.edu/ml/datasets.html)公开数据.
实验中为了训练采样率v,数据划分次数L和离群度密度阈值δ,将每一个数据集通过随机采样均分为两个等量的数据集,分别为训练集和测试集,并分别命名为Ecoli_train, Ecoli_test, Beijing_train, Beijing_test, Finger_train, Finger_test, Other_train和Other_test. 实验设置乘法距离中的维度影响因子et=1(1≤t≤m),在每个数据集中,每个维度对数据点间的距离的影响能力是相同的.
每个数据集包含的数据条数、维度、离群点的标记和离群点比例如表 1 所示.

表 1 实验数据集的基本信息Tab.1 Essential information of the experimental dataset
3.2 参数L和v的训练与分析
为了提高SHCAD算法对离群点检测的精度和召回率,应选择出适当的数据划分次数L和合适的采样率v. 用F1作为衡量L和v取值好坏的指标,F1是精度P和召回率R调和精度值,公式形式为F1=(2×P×R)/(P+R). 根据文献[11]和文献[14]中的数据采样建议,分别取采样率v为0.04, 0.08, 0.12, 0.16和0.20,并设置L初始值为10,步长为10,累加到500停止,观察在不同采样率下随着L值的增加F1值的变化情况. 取训练集中数据量差异较小的两个数据集Beijing_train和Other_train训练参数L和v,使训练结果具有代表性,防止因数据集过大或过小而导致的参数训练不准. 训练结果如图 2 和图 3 所示,从图 2 和图 3 中可以看出,当采样率v为0.04到0.12之间时F1值已基本达到最大值. 数据划分次数为100时,不同采样率下的F1值都已收敛. 所以根据实验结果,数据划分次数L取值100次,采样率v取值0.08较为合理.
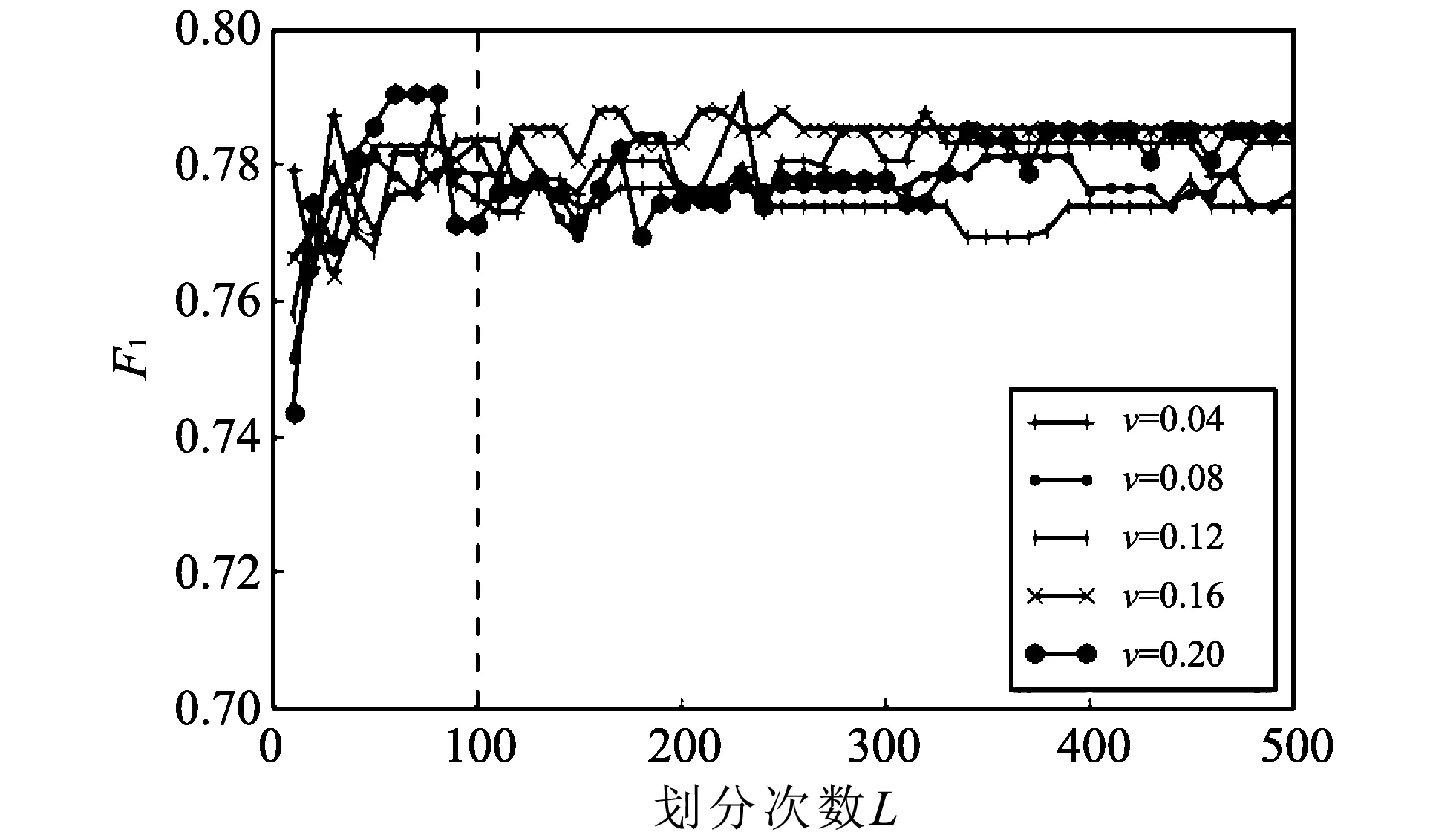
图 2 Beijing_train数据集在不同的L和v下的F1值变化情况Fig.2 Different L and v, the F1 value of Beijing_train
图 3 Finger_train数据集在不同的L和v对F1值的影响Fig.3 Different L and v influence F1 value of Finger_train
3.3 离群度阈值δ的训练与验证
δ值作为一个需要自定义的离群度阈值,在离群点判别过程中,有至关重要的作用. 这里使用Ecoli_train,Beijing_train,Finger_train和 Other_train四个数据集作为训练集,利用3.2节的训练参数L=100和v=0.08,训练出每种数据集对应的δ值,并用Ecoli_test,Beijing_test,Finger_test和 Other_test四个测试集对δ值进行验证.
δ值的训练过程:L=100和v=0.08作为四个训练集的输入参数,得到四个训练集的中数据点的离群度. 设置δ的初始值为0.01,步长为0.01,累加到0.99停止,根据式(7),计算出使得F1值最大的δ值.
训练结果如图 4 所示,四个训练集Ecoli_train,Beijing_train,Finger_train和 Other_train的最优δ值取值或者取值范围分别为[0.82,0.83], 0.81, 0.64, [0.65,0.84].
δ值的验证过程: 在四个训练数据集训练结果存在多个值的情况,取中值作测试,所以四个训练集的δ分别取值为0.82, 0.81, 0.64, 0.75. 在这四个δ取值下,通过式(7)得到的四个测试集的F1值,称为测试F1值,与其对比的值为测试集的最大F1值. 最大F1值是测试集参照训练集的训练方式而得到的F1值,称为最大F1值.
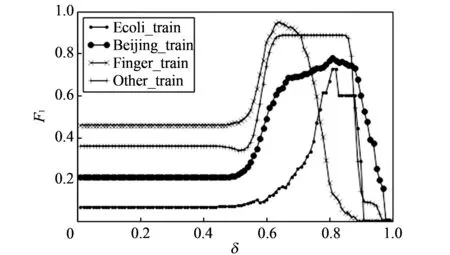
图 4 四个训练集δ取值 对F1值的影响Fig.4 Different δ influence F1 value of four train dataset
对比结果如图 5 所示,在Beijing_test,Finger_test和Other_test数据集上,测试F1值和最大F1十分接近. 在Ecoli_test数据集上两者相差较大,主要原因是Ecoli数据集的数据量较少,均分为两个数据集Ecoli_train和Ecoli_test时存在离群点分配不均的现象,导致测试F1值较低. 综合图 5 中的四个测试集,训练得出的离群度阈值δ分别取值为0.82,0.81,0.64,0.75是较为合理的.
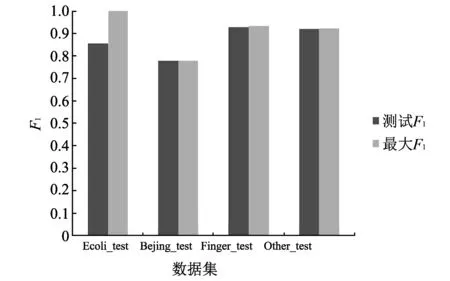
图 5 四个测试集上对比测试F1值和最大F1值Fig.5 Comparison of test F1 value and maximum F1 value in four test dataset
3.4 实验对比分析
实验采用精度P和召回率R作为算法性能的衡量指标. 设置L=100,v=0.08,离群度阈值δ分别取值为0.82,0.81,0.64,0.75,在四个测试数据集Ecoli_test,Beijing_test,Finger_test和 Other_test中进行对比实验,分别对比了SHCAD、基于分类的离群点检测算法One-class-svm和基于快速超球体聚类的FHCAD离群点检测算法的性能.
图 6 为不同算法在各个数据集上的精度对比. 从图中可以看出,在所有实验数据集上,SHCAD算法的离群点检测精度都要优于传统的离群点检测算法,尤其在Ecoli_test,Finger_test和Other_test三个数据集上,SHCAD算法精度明显高于其余两个算法. 在四个测试数据集上,FHCAD算法的精度要优于基于分类的One-class-svm算法.
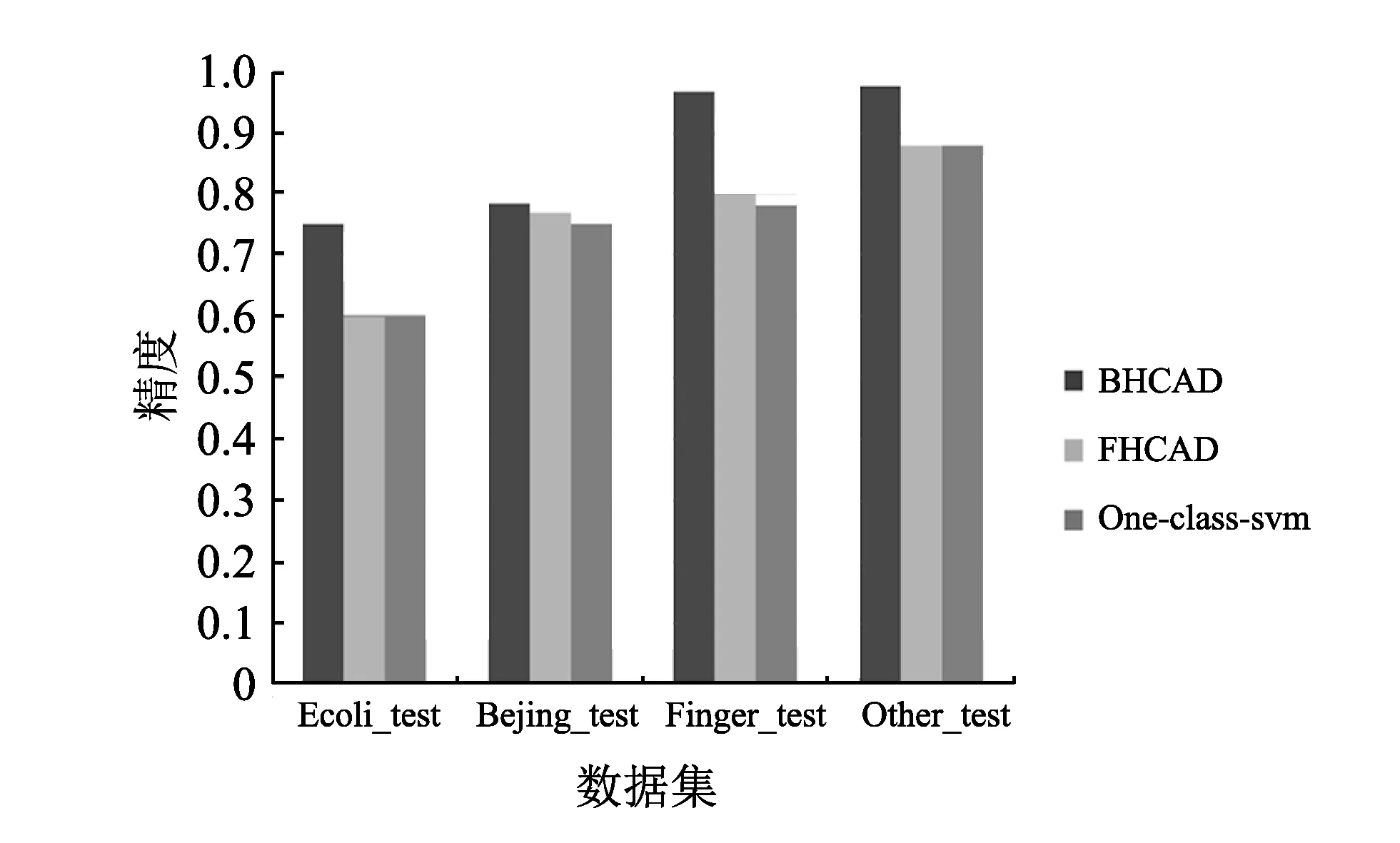
图 6 SHCAD算法与FHCAD算法、One-class-svm 算法精度对比Fig.6 Comparison of accuracy among SHCAD, FHCAD and One-class-svm
图 7 为三种算法在四个测试数据集上的召回率对比,从图中可以看出,在Beijng_test和Finger_test数据集上,SHCAD算法的召回率明显优于FHCAD算法和One-class-svm算法. 在Ecoli_test和Other_test数据集上,SHCAD算法的召回率也略高于其他两个算法.
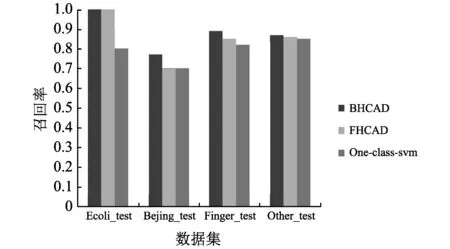
图 7 SHCAD算法与FHCAD算法、One-class-svm 算法召回率对比Fig.7 Comparison of recall rate among SHCAD, FHCAD and One-class-svm
由实验结果可知,改进后的SHCAD算法与FHCAD算法相比,在精度和召回率上有了很大的提升,同时对比了基于分类的One-class-svm算法,其性能指标远远优于基于分类的One-class-svm算法,实验证明了SHCAD算法的有效性.
4 结束语
针对快速超球体聚类离群点检测算法存在的问题,提出一种基于采样的超球体聚类的离群点检测算法,通过数据采样达到对数据点的定量描述的目的,采用自适应计算超球体半径方式,避免了人工设定超球体半径的盲目性,同时避免了原算法密度阈值和连接度阈值的设置问题,最后通过对离群度阈值的训练和测试,证明了算法的有效性.
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
四川大学学报(自然科学版)(2021年6期)2021-12-27
数学大王·低年级(2021年4期)2021-04-27
计算机应用(2020年12期)2020-12-31
消费电子(2020年5期)2020-12-28
兵工学报(2019年2期)2019-03-13
小型微型计算机系统(2018年8期)2018-09-07
环球市场信息导报(2017年36期)2017-12-24
阅读(中年级)(2016年4期)2016-11-19
文苑(2015年9期)2015-09-10
