
时间规整耦合线性判别分析的动作识别算法
2018-11-17 01:47方云录
计算机工程与设计 2018年11期
方云录,苗 茹
(河南大学 民生学院,河南 开封 475000)
0 引 言
近年来,众多学者对动作识别[1-3]开展了深入的研究,得到了一些动作识别算法。例如傅颖等[4]提出了基于DTW的动作识别算法。徐向艺等[5]提出了一种DTW优化直方图动态捕获动作识别算法。但是基于DTW算法中时间结构变化较大,对光照变化敏感。Wang等[6]基于密集采样的基础上,提出了一种有效的基于密集轨迹特征。其利用光流场密集采样的兴趣点捕抓曲线,分别计算曲线位移向量与其曲线子时空块的3个组成直方图为动作特征。但在复杂的环境中,由于经常受到光照变化、晃动或者遮挡等影响,使其对动作特征提取难度增大,降低了算法性能。邵延华等[7]定义了一种特征融合的动作识别方案。其主要通过背景差分对显著区检测,并提取显著区的剪影直方图与光流直方图,再通过的融合技术形成新的特征,最后,利用SVM进行分类学习。该方法能较好对行为动作完成识别判断。但是该算法提取的特征会受到数据本身的噪声干扰,动作类别中存在语义鸿沟。
虽然DTW在序列分析中应用广泛,但在多序列分类时存在一些局限性。例如:由于动态规划是一种简单的确定性方法,所得到的解对于包含时间结构内变化大的序列数据可能不是最优的。其次,DTW没有消除或忽略影响分类结果的无关变化的内在机制。例如,在语音数据中,视频数据或扬声器中的光照条件的变化会显著地降低DTW的分类方法的性能,对这些不良影响较敏感。
为了解决这些问题,本文提出了一种基于随机时间规整与线性判别分析的动作识别算法。通过对DTW进行了改进,构造了随机时间规整(RTW)机制。与动态规划来寻找最相似的规整模式不同,RTW是逐步生成一组规整的时间模式,称为时间弹性(TE)特征。通过反复随机抽样子序列,保留原始时间顺序。利用这种策略,可确保TE特征集包含足够的高概率判别帧,并联合PCA与线性判别分析技术,对序列进行分类学习,完成动作识别,最后,测试了所提动作识别算法的鲁棒性与精度。
1 动态时间归模式
动态时间归(DTW)的思想是将测试时序和参考时序数据伸长或缩短,使其长度相同,再通过Euclidean距离测量两个时序间的距离[8]。通过对长度不一的时序完成非线性规整,寻找两者间的最优对应位置。随后,测量对应位置的Euclidean距离,得到曲线的相似性。该技术在计算机视觉、语音识别、数据挖掘等具有较强的生命力[9]。
设两个时序为A、B,其对应长度为n、m,表示如下
(1)
为使时序A、B非线性对齐,根据时序A、B的距离建立一个代价矩阵C=[c(i,j)],矩阵中的元素为ai、bj之间的距离,表示为
(2)
为寻找两个时序最优匹配,从矩阵中搜索一个路线,使时序A、B的累积距离最小。对于计算C的过程,如果n=m,直接计算时序A、B的距离。如果n≠m,需要进行对齐操作。A、B间的规整路线p的累积代价方程设为cp(A,B),定义为
(3)
其中,规整路线,l∈[1,L],p为A、B的映射序列。A、B间的最佳规整路线p*为累加代价方程取最小值的路线。因此,DTW度量表示为
DTW=cp*(A,B)=min{cp(A,B)}
(4)
最佳规整路线p*可根据函数获得
(5)
(1)边界条件:从p1=(1,1)开始,到pk=(n,m)终结。
(2)连续性:设pk-1=(a′,b′),那么下个点pk=(a,b)符合a-a′≤1,b-b′≤1。表示无法越过某点来匹配,只允许与自己相邻点对齐。确保A、B的所有坐标出现在p中。
(3)单调性:给定pk-1=(a′,b′),下个点pk=(a,b),需符合0≤a-a′,0≤b-b′。路线p无法返回。
通过一个累加距离,将矩阵中的所有元素得到的距离相加,获得了最后的总距离,即时序A、B的相似度,定义为
γ(i,j)=d(ai,bi)+min{γ(i,-1,j-1),γ(i-1,j),γ(i,j-1)}
(6)
2 本文动作识别算法
本文提出的算法包含了测试阶段和训练阶段。分别通过计算测试与训练阶段的TE特征,然后利用PCA将得到的TE特征变换为子空间,再测量参考子空间与测试子空间的正则角,根据正则角的大小来衡量相似性。最后,根据LDA进行分类学习,完成动作识别过程,整个过程如图1所示。在图1中,R为TE特征向量的数量,Kc为类别c中图像序列的数量。
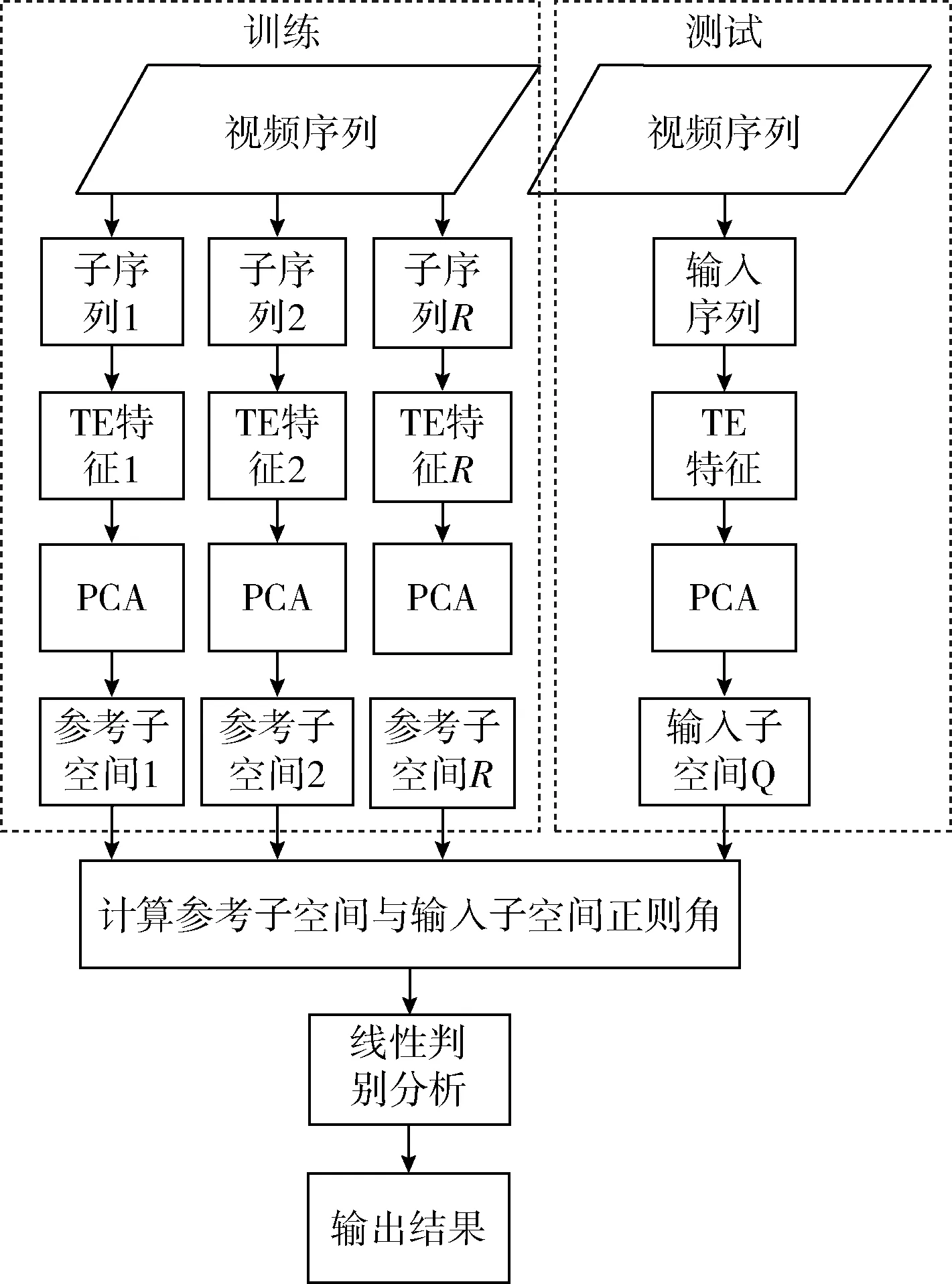
图1 本文算法流程
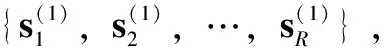

2.1 TE特征提取
为了处理时间结构突变问题,利用TE特征来表示时间结构的局部和全局信息。其中全局信息适应总体时间结构;局部信息处理时间结构的片断。

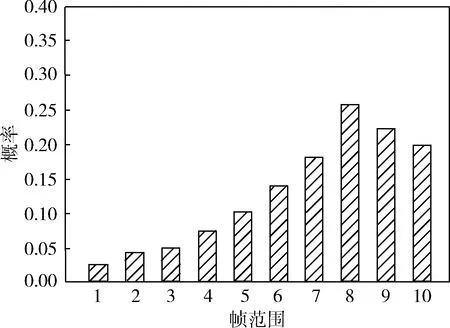
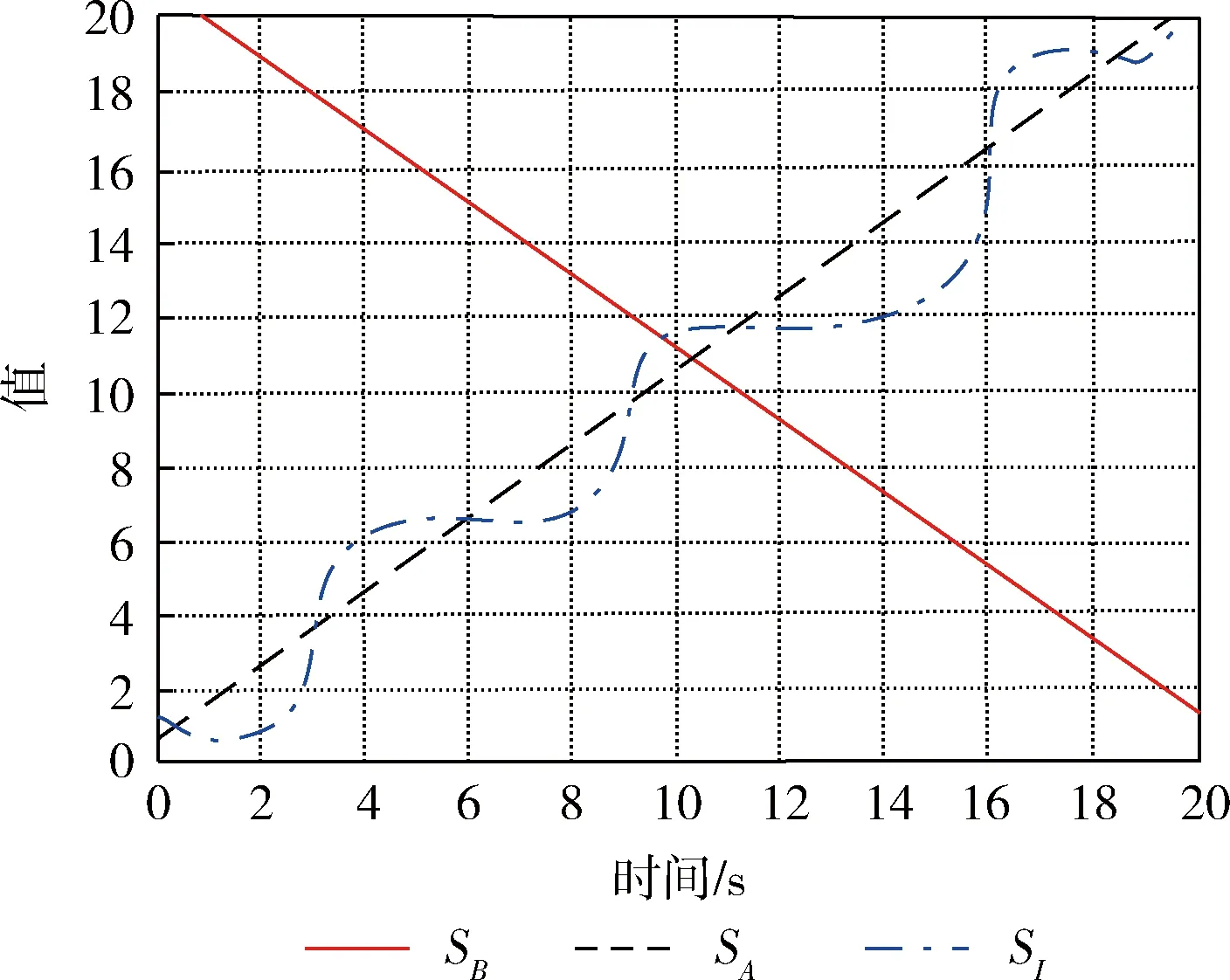
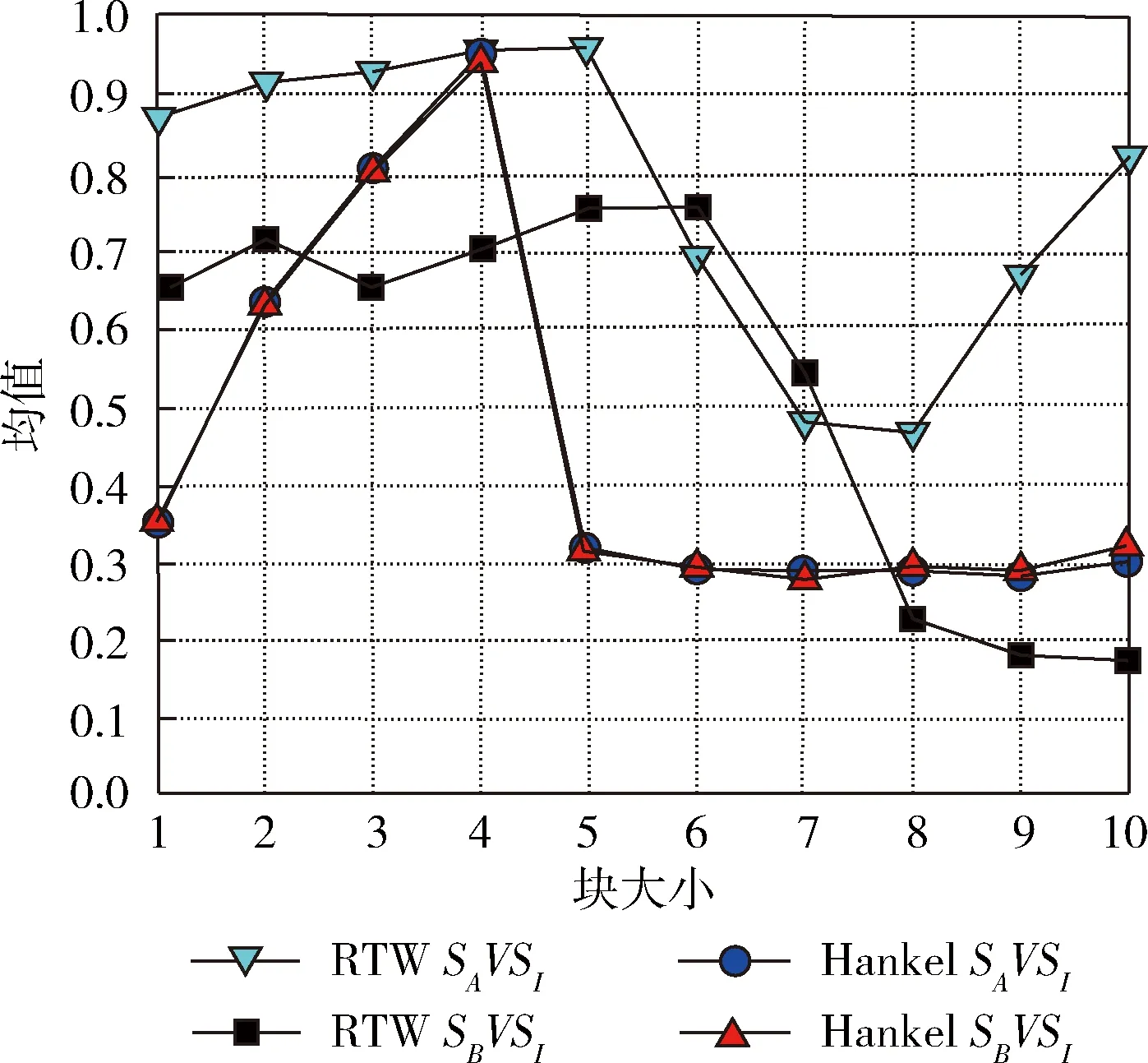
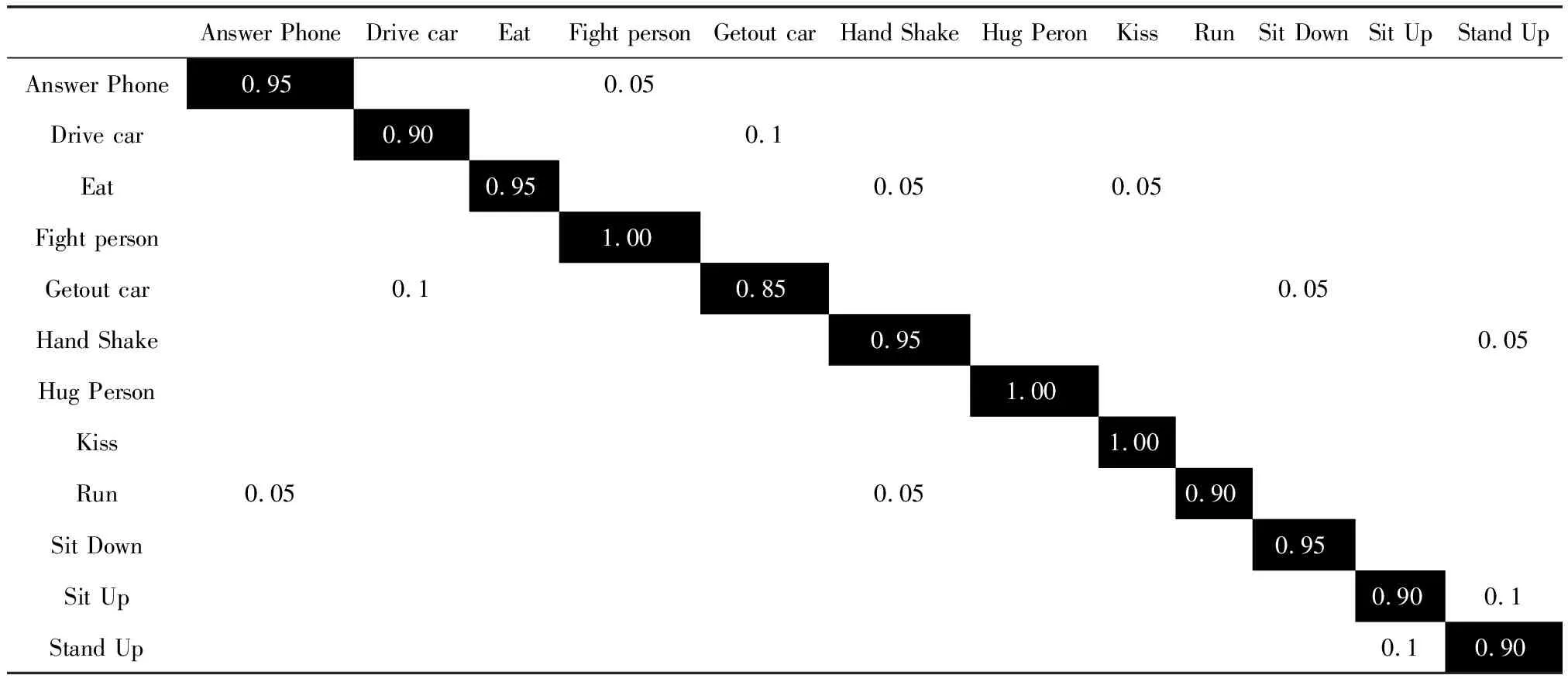
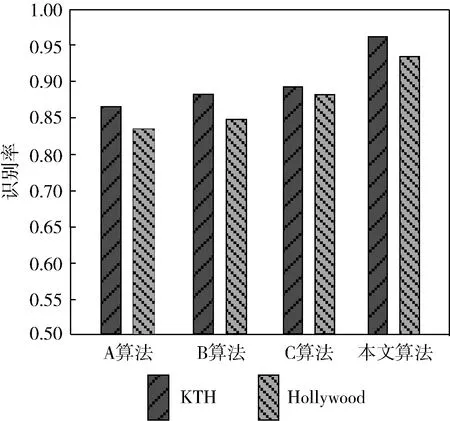
y1,y2,…,yn={x1,x2,…,xN},t(y1)<… (7) 其中,t(·)表示图像的原始顺序。n为构造TE特征所选择的图像个数,对应于识别所需的有效帧的数目。 在统计过程,t(y1)为在s中选定的n个图像的最小图像顺序,t(yn)为最大的顺序。令t(yj)为TE特征的第j个顺序统计,通过以上描述,t(yj)=k的概率可定义为 (8) 当n=5,N=10时,t(yj)的概率质量函数(j=1,2,…,n)如图2所示。图2描述了提取TE特征的统计机制,能适用于整个序列而不只是约束于局部邻域。位于运动边缘附近最有可能被选作TE特征的开始和结束块。这表明TE特征能够收集时间信息的局部时间结构和全局结构。 图2 随机选择TE特征概率 对于包含r帧范围的TE特征的概率P(t(yn)-t(y1)=r),r=n-1,…,N-1为 (9) 图3显示了从一个包含10个运动图像中产生的n=5个TE特征的帧范围的概率分布。例如,TE特性包含1,2,3,4,5和2,3,5,9,10有序的图像,其帧范围分别为4和8。 图3 不同帧范围的概率分布 通过重复随机抽样,确保TE特征集包含足够的高概率判别帧。然而,由于TE特征具有随机性,集合中并非所有选定的特性都包含判别信息。为了降低冗余度,对于TE特征集,引入主成分分析(principal component analysis,PCA)法生成子空间[11,12]。 根据2.1节描述,将随机选择过程重复R次,可得到s1,s2,…,sR。随后,得到一个相关矩阵A,对应于TE特征向量集,定义如下 (10) 通过计算A的特征向量[φ1,φ2,…,φN],利用PCA构造N维子空间。从一个序列中得到的TE特征集含有各种可能的规整模式,每种模式都对应一个假设,因此,由TE特征集生成的子空间称为序列假设子空间。通过子空间表示TE特征集的一个优点是可以处理多个序列。在属于同一类的多个参考序列的情况下,可在一个假设子空间中表示它们的特征集。因此,对未知序列的识别效率更高,因为不需要将未知序列与属于同一类的每个参考序列进行比较。 接下来,对两个子空间之间的相似性计算。基于正则角的相似度量也被称为互子空间法,是一种广泛应用于3D目标识别技术[13]。设类别c的N维参考子序列为ζc,υ为M维的输入子空间。第一次的正则角θ1计算如下 (11) 因此,可通过正则角cosθi的余弦来表示两个假设子空间的相似性。第一个正则角θ1对应于两组TE特征集之间最大的典型相关关系,可作为两个对应的子空间中两个最相似的规整模式之间的距离。第二个正则角θ2对应于两组TE特征之间的第二大正则相关,依次同理。只有第一个正则角的使用可能会导致不稳定的识别性能,在DTW方法中,只考虑最相似的规整模式。这表明需要多个正则角来考虑子空间中所有可能的规整模式,从而实现更稳定的性能。因此,本文利用所有正则角的平均相似性作为最终相似性 (12) 在RTW操作过程中,将TE特征构建一个矩阵,形成Hankel矩阵[14]。Hankel矩阵H被定义为一个矩阵,矩阵中其它所有元素都与其左下角相邻位置的元素相等 Hi,j=Hi-1,j+1 (13) 其中,i,j分别表示矩阵的行和列。 首先,Hankel方法中的最大特征数为i+n-1,但是,RTW的最大特征维数为N。 其次,Hankel矩阵的元素是通过式(13)生成。而在RTW中,TE功能是通过随机抽样产生的。 这些差异表明,Hankel矩阵比RTW矩阵需要一个较长的序列和一个更大的训练序列来生成丰富的时空运动词典。此外,Hankel矩阵只能包含关于运动的有限全局时间信息,全局程度取决于Hankel块的大小。 为了说明Hankel矩阵的优势,设SA={1,2,…,20},SB={20,19,…,1}为两种不同动态学的反向单变量序列数据。SI为与SA相似的含有噪声的输入序列,如图4所示。 图4 不同矩阵的性能对比 因此,由TE特征集生成的子空间包含比Hankel矩阵更丰富的信息,子空间表示也适用于捕捉嵌入在TE特征集中的信息。在本文算法中,利用Hankel表示和TE特征集SA、SB、SI来生成子空间,随机抽样的RTW数设置为1000。图5为利用PCA的99%累积能量比确定子空间维数时的相似度值。从图5中得到,当利用Hankel时,SA和SI、SB和SI得到的相似值基本相同。主要是跨越SA和SB轨迹的满秩子空间彼此重叠。在RTW的随机化中,SI与SA更相似。 图5 不同结构下的相似度比较 线性判别分析(LDA)是一种简单、有效的模式辨别算法[15]。LDA的主要是从高维特征中挑选出辨别力最强的低维特征,选出的特征能使同类的数据簇类一起。对于不同种类的数据分别聚集,从而选择训练特征与测试特征最相似的对象,以达到抽取分类信息和压缩特征空间维数的效果。设Rn空间中m个数据x1,x2,…,xm,x为一个n行的矩阵。设有c个类别,数据中的类内、类间散布矩阵为Sw与Sb,表示为 (14) (15) 其中,ui为第i类样本均值;u为整体样本均值;ni为第i类样本数量;xk为第k个样本。 LDA作为一个分类算法,希望其类间耦合度低,类内的耦合度高。即Sw的值要小,而Sb的值要大,这样分类的效果最佳。对此,引入Fisher判别函数J (16) 其中,ψ为一个n维列向量。Fisher判别通过选择使J(ψ)中最大的ψ为投射方向,投射后数据间的具有最大Sb和最小Sw。 通过对Fisher判别函数最优化,寻找一组最优判别矢量形成的投射矩阵W,定义如下 (17) 为了保证Sw的非奇异性,通过PCA进行降维处理,消除冗余信息。 LDA的步骤如下: (1)样本收集。收集含有不同类型的样本c个,将样本分为训练、测试两类。 (2)选择判别方法。根据样本的不同特点,选择不同的判别分析手段。对训练样本定义判别方程,并给出假设检验。 (3)训练样本考核。将样本训练所有目标的属性代入到建立的判别方程,进行类别判断。测量训练样本的判别误差,衡量判别方程的性能。 (4)测试样本考核。当训练目标的判别误差较小时,将测试目标的属性输入到判别方程,得出测试目标的判别误差值。 为评估提出算法的性能,在两个公开的数据库:KTH数据集与Hollywood数据集,通过在KTH与Hollywood中进行实验与统计分析。实验环境为:Core I5,3.50 GHz CPU,4 GB运行RAM,32位的Win7系统。借助MATLAB7.0进行仿真分析。为了突出本文技术的优异性,将文献[5]、文献[6]、文献[7]作为对照组,定义为A、B、C算法。本文采用的数据集与方法见表1。经过多次实验,参数设定如下:最短序列长度为36,最长序列长度为120;参考自空间维度范围为[1,60],输入子空间维度范围为[1,50];R=30。 KTH数据集[16]:是由瑞典皇家理工学院建立的动作识别数据集,KTH包括:走路(Walking)、慢跑(Jogging)、跑步(Running)、拳击(Boxing)、挥手(Hand waving)和拍手(Hand clapping)6个常见的动作类型,其通过25个人在4种不同的简单场景中完成。如图6所示。 表1 实验数据集与方法 图6 KTH数据库 Hollywood数据集[17]主要由10个场景中的12种不同动作组成的3669个动作序列。这12个类别分别为:Answer phone、Drive car、Eat、Fight person、Getout car、Hand Shake、Hug Person、Kiss、Run、Sit Down、Sit Up、Stand Up。其从69个Hollywood影视中获取形成的。在Hollywood包含了各种不同的情绪、服饰、运动,并且会有相机运动、光照变化、遮挡、背景等干扰,较接近于真实生活。因此,对于Hollywood中的动作识别具有一定难度。Hollywood数据集如图7所示。 图7 Hollywood数据集 表2显示了在KTH数据集中的混淆矩阵。从表2中可看出,本文方法在KTH中对大部分动作具有良好的识别效果,能够各动作完成识别。如“Hand clapping”的识别率高达1。“Wave”的识别率为0.98,主要是“Hand clapping”、“Wave”动作与其它5种行为较明显。此外,“Walk”动作识别率最低,为0.91,其主要易被误识别为“Run”动作。 表2 KTH数据集的混淆矩阵 表3为在Hollywood数据集中得到的混淆矩阵。从表3中得出,在Hollywood中,对大部分动作具有较高的识别率。对“Hug Person”、“Kiss”、“Fight person ”的识别率高达1。但有些动作的识别率不高,如“Getout car”识别率为0.85,“Drive car”、“Run”、“Sit Up”识别率为0.90。其中“Getout car”易被误识为“Drive car”动作。主要一些动作的相似度较高,从不同的视角或者受到环境的影响,导致了误识别的产生。 图8为在KTH与Hollywood数据集中,利用3个常见算法和本文算法得到的平均识别精度。从图8中看出,在KTH中的识别率高于Hollywood。相对A、B、C算法,提出的方法在KTH与Hollywood数据集中取得良好表现。主要是本文算法通过RTW反复随机抽样提取序列数据的TE特征,保证了TE特征包含足够的高概率判别帧。然后,根据提取的TE特征形成了低维子空间表示,计算两个子空间的正则角表示两个图像序列之间的相似性。再引入LDA进行分析学习,根据参考序列与测试序列的相似性分类器判别,降低了信息冗余和噪声干扰。而A算法中基于DTW算法容易导致时间结构变化较大,算法性能不稳定。B算法中密集轨迹特征,在复杂的环境中,由于经常受到光照变化。C算法采用了特征融合与SVM分类学习技术,由于噪声的影响,容易会出现语义鸿沟。 表3 Hollywood数据集混淆矩阵 图8 不同算法的识别精度对比 表4为在KTH与Hollywood数据集中统计的不同算法的时间成本。根据表4中得知,在KTH与Hollywood数据集中的平均时间为41.12 s、65.87 s,运算时间少于其它3种算法,具有明显的优势。主要是因为基于子空间,避免了所有可能TE特征之间的穷举匹配,消除和减少无相关特征的不良影响,从而提高分类效率。 表4 算法运行时间对比 为了能够在复杂环境下对各种动作进行准确快速识别,本文定义了一种RTWE耦合线性判别分析的动作识别算法。针对DTW在动作识别中的不足,对其予以改进,通过对图像序列随机抽样,提取序列TE特征,保证了TE特征包含足够的高概率判别帧。为了减少了冗余度,引入PCA将TE特征变换为子空间,避免了所有可能TE特征之间的穷举匹配。测量两个子空间之间的正则角,根据得到的正则角表示两个图像序列之间的相似性。为了完成动作的分类学习,借助线性判别分析LDA进行对图像序列特征进行分析学习。 通过在KTH与Hollywood数据集上进行算法测试,实验结果表明了提出的动作识别算法能够有效对各动作理解与分类,提高了识别率与算法效率,在两个数据集中的识别准确率均在90%以上,且时耗最短,分别为41.12 s、65.87 s。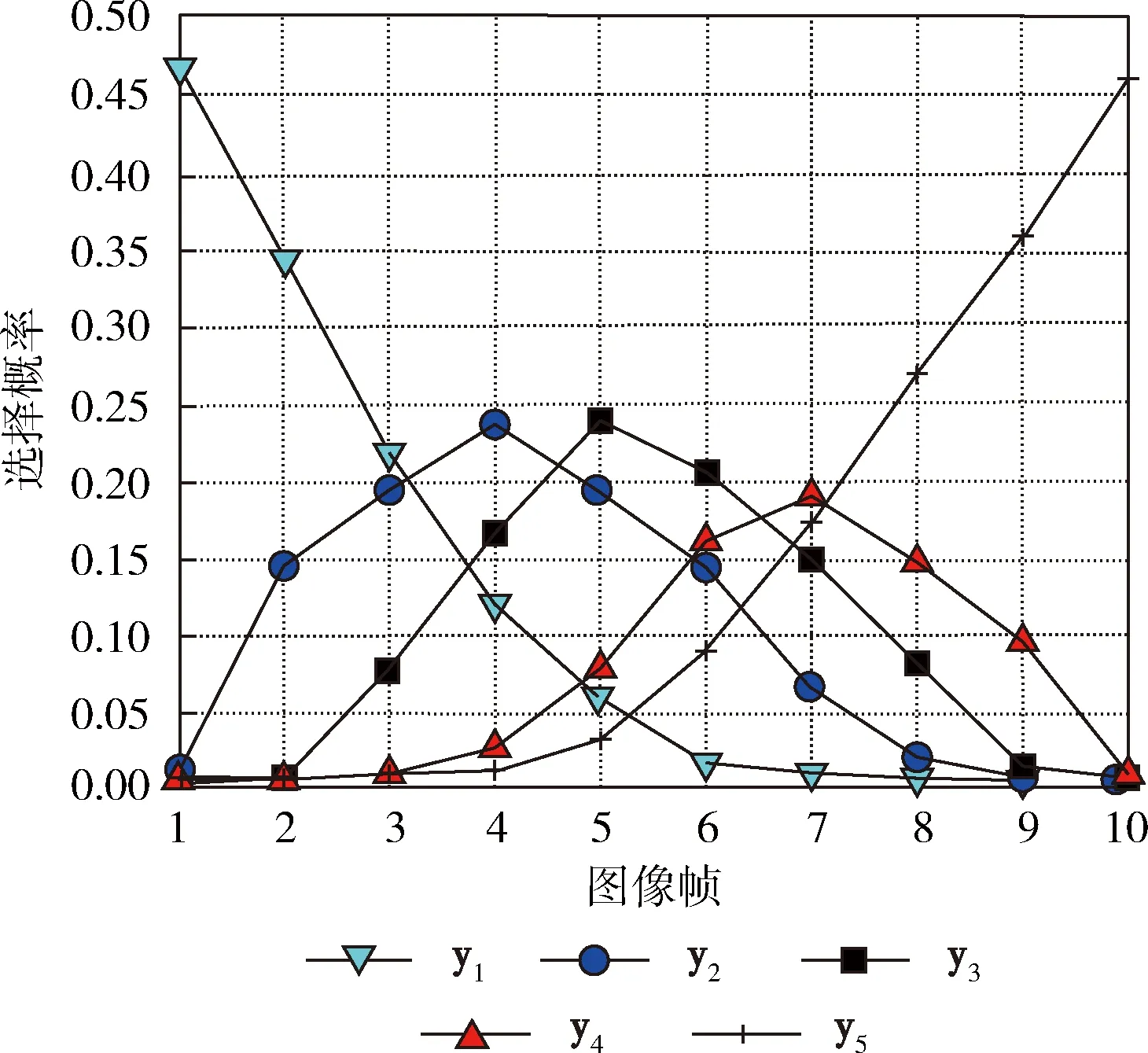
2.2 相似性度量

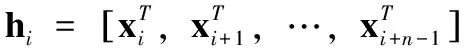
2.3 线性判别分析分类器
3 实验与分析
3.1 数据集



3.2 实验结果


4 结束语
猜你喜欢
民族文汇(2022年24期)2022-06-09
计算机工程(2020年3期)2020-03-19
中国化工贸易·下旬刊(2019年5期)2019-10-21
中国听力语言康复科学杂志(2019年3期)2019-06-24
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学杂志(2018年5期)2018-09-19
中国交通信息化(2018年3期)2018-06-13
佛山陶瓷(2016年11期)2016-12-23
大观(2016年9期)2016-11-16
中国交通信息化(2016年2期)2016-06-06
