
代价敏感的目标客户选择半监督集成模型研究
2018-11-23 05:44刘潇潇刘敦虎
中国管理科学 2018年11期
肖 进,刘潇潇,谢 玲,刘敦虎,黄 静
(1.四川大学商学院,四川 成都 610064;2.成都信息工程学院管理学院,四川 成都 610225; 3.四川大学公共管理学院,四川 成都 610064)
1 引言
随着大数据时代的来临,企业掌握的客户数据越来越多,一些企业开始利用数据库营销(Database Marketing)来避免传统营销中存在的低效率,高成本等弊端,用以从海量客户数据中快速挖掘出客户多样化和个性化的需求。作为数据库营销中最重要的问题之一,目标客户选择建模用于从潜在客户中识别出企业的目标客户,即对企业营销手段最可能做出响应的客户,从而帮助企业制定营销战略。
目标客户选择建模实质上是属于客户分类的范畴[1],即将客户分为两类:对企业产品的营销宣传活动(如发送邮件或者短信等)做出响应,进而购买产品的客户和不响应的客户。目前,常用的目标客户选择模型主要包括人工神经网络[2](Artificial Neural Networks, ANN)、遗传算法[3](Genetic Algorithm,GA)、数据分组处理(Group Method of Data Handling,GMDH)神经元网络[4]和支持向量机[5-6](Support Vector Machine, SVM)等。许多现实的客户数据的类别分布往往是高度不平衡的,即会对企业的营销活动做出响应的客户比不响应的客户少很多[7]。在这种情况下,上述传统的分类模型可能会将所有的客户预测为不响应的客户,难以取得令人满意的目标客户选择性能。为了解决这一问题,目前常用的方法是重抽样技术(如随机向上抽样和随机向下抽样)来平衡训练集的类别分布,再训练分类模型。
上述研究对目标客户选择建模都做出了重要贡献,但通过仔细分析,还存在以下不足:1)重抽样技术存在缺陷。随机向上抽样将导致少数类中重复样本太多,而随机向下抽样得到的结果就是最终的训练集样本数量往往很少,它们均可能会影响目标客户选择建模的性能。2)目前,国内外关于目标客户选择的研究大都采用监督式分类建模的研究范式[8],即仅使用原始含类别标签的训练集来训练分类模型,进而预测新的客户样本的类别。而实际上,企业往往只针对少量客户进行营销宣传活动,并赋予响应或不响应的类别标签。而剩下大量未进行营销宣传的客户,则无法标记它们的类别[9]。此时,如果仍然采用监督式客户分类建模研究范式,通常都会由于训练样本个数太少而造成过拟合,反而导致模型性能的下降[10]。实际上,无类别标签的客户数据也可为构建模型提供有用信息[9]。因此,如何有效地使用大量没有类别标签的数据提高模型的学习性能,是目标客户选择建模中亟待解决的问题。
事实上,在目标客户选择领域,不同类别客户的错分代价相差很大,如果把一个不响应的客户误分成响应的客户给企业造成的损失仅仅是很少的邮寄相关宣传资料的营销费用,而如果把一个响应的客户误分成不响应的客户,那么企业就不会对该客户邮寄宣传资料,从而失去该客户因购买了产品或服务而给企业带来的利润。代价敏感学习(Cost Sensitive Learning,CSL)恰好能够很好地处理这种分类问题[11],它在训练模型时为少数类样本赋予比多数类样本更高的错分代价,从而让模型更多地关注少数类样本。如Xiao Jin等[12]利用代价敏感学习机制,提出了动态集成客户分类模型,实验分析表明该模型分类的正确率更高。
为了解决第二个问题,近年来在机器学习领域发展起来的半监督学习(Semi-supervised Learning,SSL)为我们提供了一种很好的思路[13],其主要思想是研究如何综合使用有、无类别标签的样本来提高模型的学习性能。目前已有将半监督学习用于目标客户选择的研究[14],但已有的研究都只是构建了单一的半监督分类模型来进行目标客户选择。由于在现实中用于目标客户选择建模的数据往往包含了大量噪声,大大增加了分类难度。因此,单一分类模型难以实现在整个样本空间上的准确分类。若能够将多个单一模型进行组合,即引入多分类器集成技术(Multiple Classifiers Ensemble, MCE)[15],让每个分类器都能在各自的优势空间中发挥作用,进而提高模型的目标客户选择性能。
本文将CSL,SSL以及MCE中的随机子空间方法(Random Subspace,RSS)相结合,构建了代价敏感的目标客户选择半监督集成模型(Cost-sensitive Semi-supervised Ensemble Model, CSSE)。该模型融合了CSL,SSL和MCE的优势,既能够较好地处理类别不平衡的数据,也能够将无类别标签样本中包含的大量信息加以利用,同时还能利用集成方法RSS进一步提高模型的目标客户选择性能。在CoIL预测竞赛的目标客户选择数据集上进行实证分析,结果表明,与两种监督式集成模型、两种单一的半监督式模型以及两种半监督式集成模型相比,本文提出的CSSE模型具有更好的目标客户选择性能。
2 相关理论介绍
2.1 代价敏感学习
对于CSL的研究最早可以追溯到1984年Breiman等[16]提出的代价敏感学习研究框架。针对二分类问题,代价敏感学习技术的研究集中在以下两个方面[17]:(1)根据样本的不同错分代价来改变正类和负类占总样本数的比例来构建类别平衡的样本集,然后应用分类模型进行建模;(2)在不改变训练集的基础上,改造分类模型的内部结构,即改造分类模型的目标函数使其成为代价敏感的分类模型。由于该方法考虑了不同类型错分代价不同的情况,并基于最小化总体误分代价的原理来设计分类模型,进而能更好的适应目标客户选择问题。这其中代表性的方法就是代价敏感的SVM。
SVM是Cortes和Vapnik于1995年首先提出的,目前是机器学习领域的研究热点之一[18-19]。SVM的核心思想是通过某种事先选择的非线性映射(核函数)将输入向量映射到一个高维特征空间,该算法的目标是在这个空间里构建最优分类超平面,使正负两类样本之间有最大的间隔。

图1 支持向量机原理图
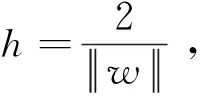
s.t.yi(wxi+b)-1+ξi≥0,ξi≥0i=1,2,…,n
(1)

s.t.yi(k(w,xi)+b)≥1-ξiξi≥0,i=1,2,…,n
(2)

2.2 RSS多分类器集成模型
分类问题是数据挖掘领域的基本研究问题,传统的分类学习常常使用单一分类模型来预测类别标签。由于现实中用于分类建模的数据往往包含大量噪声,单一的分类模型很难将全部样本正确分类。而MCE则是将多个分类器的分类结果通过某种方式集成起来,得到最终的分类结果。作为MCE中常用的模型之一,RSS[20]的基本思想是随机抽取特征子集形成不同的特征子空间,经过映射得到若干个训练子集,从而构造出不同的基本分类器。RSS一方面能够降低原始数据集特征空间的维数,另一方面由于每次抽取的特征子集不同因而映射形成的训练子集也不同,很大程度上增加了用于集成的基本分类器之间的多样性,有利于提高集成的效果。叶云龙等[21]提出了一种基于RSS的多分类器集成算法,实证分析发现该算法不仅优于单一分类器的分类性能,而且一定程度上优于Bagging算法。
2.3 半监督分类
半监督学习最早由Shahshahani和Landgrebe[22]在1994年提出,目前已经成为数据挖掘领域的一个研究热点,并逐步形成自身的理论体系。半监督分类的基本思想就是综合利用少量有类别标签的样本和无类别标签的样本所提供的信息来建立分类模型,并利用该模型来预测新的样本的类别。它与监督式分类方法最大的区别在于,构建分类模型时加入了无类别标签的样本,而无类别标签样本中也包含了很多有用信息,因此半监督分类可望构建出更加准确的分类模型。目前,国内外学者提出了很多半监督分类模型,如王娇等[23]将RSS与半监督学习相结合,构造了基于RSS的半监督协同训练模型(RASCO),Hady和Schwenker[24]在模型中引入了协同训练的思想,构建了基于Bagging的半监督协同训练模型(CoBag),随后苏艳等[25]又提出了基于动态RSS的半监督协同训练模型(DRSCO),Li Yiyang等[26]在建模过程中利用K-近邻分类方法来提高对无类别标签数据集选择性标记的准确度,构建了基于Bagging的半监督集成模型(Semi-Bagging)。
3 CSSE模型
3.1 建模的基本思路
已有的目标客户选择模型多采用重抽样方法来解决数据集类别分布不平衡的问题,但是忽略了正负类样本错分代价相差很大的情况。同时,已有的研究大都采用监督式学习的研究范式,无法综合使用有、无类别标签的样本来提高模型的学习性能。此外,从少量几篇基于SSL的目标客户选择建模的研究来看,他们都构建的单一半监督分类模型。为了弥补这些不足,本文将CSL,SSL以及MCE中的RSS相结合,构建了代价敏感的目标客户选择半监督集成模型(Cost-sensitive Semi-supervised Ensemble Model, CSSE)。该模型融合了CSL,SSL和MCE的优势,既能够较好地处理类别不平衡的数据,也能够将无类别标签样本中包含的大量信息加以利用,同时还能利用集成方法RSS进一步提高模型的目标客户选择性能。
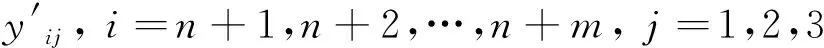
3.2 对U中样本的选择性标记
由于L一般包含的样本比较少,导致难以训练出分类性能很高的分类模型,使得CSSE模型在训练过程中可能会错误标记U中的一部分样本,如果将其加入到L中,无疑是人为地引入了更多的噪声,反而会降低模型的分类性能。因此,对U中样本的选择性标记是非常重要的,有利于取得更好的分类性能。为了达到这一目的,本文使用概率输出值Probi1作为衡量是否将样本加入L的指标,并针对正负类样本设置不同的阈值。
3.3 对类别不平衡数据的处理
在现实的目标客户选择问题中,用于建模的客户数据往往存在类别高度不平衡的问题,若采用传统方法建模会造成大量正类样本不能被识别。常用的解决方法是对原始不平衡数据集采用重抽样的方法,如随机向上抽样和随机向下抽样。区别于以上针对数据样本的方法,本文使用Davenport[11]提出的代价敏感的SVM作为CSSE的基本分类模型。我们可以在训练模型阶段调整SVM中的参数设置,增加损失函数C的值,赋予正类样本和负类样本不同的权重(W1,W2),同时选择合适的核函数t在克服数据类别不平衡的同时,提高正类样本识别的准确度。
3.4 详细建模步骤
输入:初始有类别标签训练集L,其样本个数为n,无类别标签数据集U,其样本个数为m,测试集Test,其样本个数为p,训练得到的基本分类模型的个数N,每次迭代中选择性标记正类和负类样本时选取的标记阈值θ1和θ2,U中选择性标记的样本的百分比k。
输出:测试集Test上的N个基本分类模型的集成分类结果。
初始化:L′=L,Q=Φ,s=1。
步骤1. 计算选择性标记样本集Q与U的样本百分比b=size(Q)/m,size是用来计算Q中样本个数的函数,若b>k,转到步骤4;
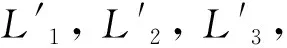
步骤3. 分别使用三个分类模型来预测U中全部样本的类别标签,并将预测一致的样本放置在候选集Uj中。若Uj为空,转到步骤2,否则从Uj中根据正负样本比例选取Probi1大于θ1的正类样本和Probi1小于θ2的负类样本添加到L’中,同时也将它们添加到Q中并从U中剔除;
步骤4. 使用随机子空间法(RSS)在L′上抽取一个特征子集,并映射得到训练子集,使用代价敏感的SVM训练得到一个基本分类模型Cs;
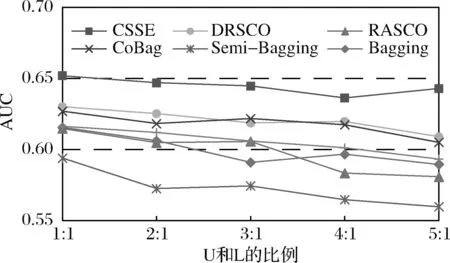
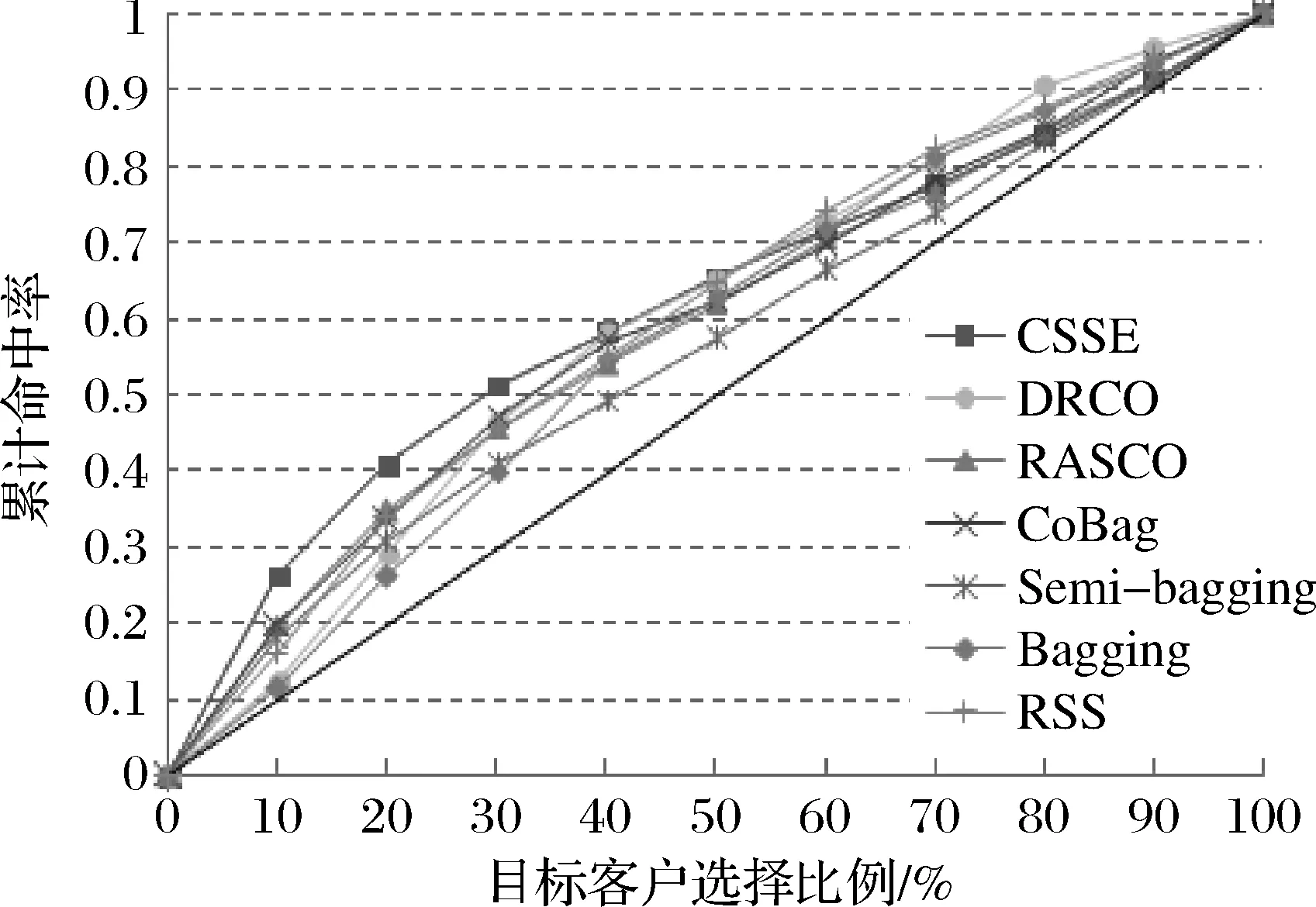
步骤5. 若s 步骤6. 使用N个基本分类模型分别对测试集Test中的样本进行分类得到分类结果R1,R2,…,RN; 步骤 7. 使用多数投票法集成N个基本分类模型的分类结果R1,R2,…,RN得到最终的分类结果。 图2 CSSE模型的流程图 为了分析本文提出的CSSE模型的目标客户选择性能,我们运用2000年的CoIL预测竞赛[27](CoIL2000数据集)中Benchmark保险公司推销大篷车保险的真实数据来进行实证分析。该数据集包含9822个样本,每个客户样本包含86个变量,其中1~85个变量是描述客户信息的特征变量,第86个变量是响应变量,表示客户所属的类别标签,该数据集将全部客户划分为会对企业营销活动做出响应的少数类客户(正类)和不会做出响应的多数类客户(负类),且正负类样本比例为1∶7.55,由此可知该数据集属于类别分布不平衡数据集。 为了进行实验分析,我们从数据集中随机抽取30%的样本作为测试集Test,然后将剩余70%的样本按照从1∶1、1∶2、1∶3、1∶4到1∶5的比例分为初始有类别标签训练集L和无类别标签数据集U,并且要保证L,Test,U中正负类样本的比例与原始数据集相同。 由于本文所使用的数据集的维度较高(包含85个属性),可能存在特征冗余的问题,而特征选择一方面有助于建立更易解释、具有更好泛化能力的目标客户选择模型,另一方面使用降维后的数据也可减少计算时间,从而降低时间成本。Kim等[28]首先将GA与ANN相结合对数据进行降维处理,然后训练ANN模型选择目标客户,并在与本文相同的数据集上进行实证分析。本文首先采取Fisher Score算法[29]在训练集L上进行特征选择。首先分别计算每个特征的得分,然后根据特征的得分从高到低进行排序,最后选取排在前面30%的特征来构建目标客户选择模型。 本文提出的模型运用了林智仁教授开发设计的libsvm工具箱,同时为了训练代价敏感的SVM,需要在建模阶段调整模型的参数使得模型在运行时发挥出最优分类性能。经过反复实验,对于初始标记训练集L的最优参数设置为:惩罚系数C=100,正类样本惩罚系数的加权值W1=100,负类样本惩罚系数加权值W2=10,t=2(核函数类型选择RBF核函数)。在CSSE模型中,θ1,θ2,N和k是四个重要参数,经过反复实验,当我们取θ1=1,θ2=-1,N=40,k=60%,此时模型能够取得较好的目标客户选择性能。 为了分析本文提出的CSSE模型的目标客户选择性能,将CSSE模型的性能与下面六种目标客户选择模型进行了比较:1)Ho[20]提出的监督式集成模型(Random Subspace, RSS);2)Breiman[30]提出的监督式集成模型Bagging;3)王娇等[23]提出的基于RSS的单一半监督协同训练模型RASCO;4)苏艳等[25]提出的基于动态RSS的单一半监督协同训练模型DRSCO;5)Hady和Schwenker[24]提出的基于Bagging的半监督集成协同训练模型CoBag;6)Li Yiyang等[26]提出的半监督式集成模型Semi-Bagging。对于这六种对比模型,我们选择传统的SVM作为基本分类算法,且基本分类器个数与CSSE模型中设置一样,N=40。值得一提的是,这六种模型都没有考虑类别分布不平衡对模型性能的影响,因此考虑到比较的公平性,本研究采用随机向上抽样来平衡数据集的类别分布,再构建相应的模型。此外,在RASCO模型中,有一个重要参数q,表示模型在每次循环中标记的样本个数,而在CoBag模型中也有一个重要参数θ,表示该模型在每次循环中标记的样本个数。通过反复实验,并以AUC值作为评价标准,我们发现当q=100,θ=200时,两个对比模型均可取得最优性能。 最后,每一种方法的分类结果均是取10次实验结果的平均值,所有实验均是在MATLABR2010b软件平台上编程实现。 为了对目标客户选择模型的性能进行评估,本文采用四个评价指标: (1)AUC准则 由于现实的目标客户选择数据集的类别分布都是高度不平衡的,正负类样本比例差距较大,此时若选择总体分类精度作为评价指标并不太实用,而ROC(Receiver Operating Characteristic)曲线恰好能够很好地评价面向类别不平衡的分类模型的性能。为了更好的说明ROC曲线,我们首先引入目标客户选择混淆矩阵,如表1所示。其中,TP表示正确分类的正类样本个数,FN代表实际为正类预测为负类的样本个数,FP指实际为负类预测为正类的样本个数,TN表示正确分类的负类样本个数。针对两类问题的ROC曲线是一个真正率——伪正率图,其中横坐标表示伪正率=FP/(FP+TN)×100%,纵坐标表示真正率=TP/(TP+FN)×100%。由于直接比较不同模型的ROC曲线比较困难,因此使用AUC(Area Under the ROC Curve)值来评价模型性能。 表1 目标客户选择混淆矩阵 (2)命中率 在现实的目标客户选择中,企业最关注的是会对企业营销行为做出响应的客户,因此命中率[4]是一个常用的评价指标。首先使用模型预测得到测试集中所有客户做出响应的概率,然后依据概率将其从大到小进行排序,最后选择前面r%的客户作为目标客户。命中率的计算公式如下: (3) 其中,N表示所有潜在的目标客户数,即测试集中样本个数,Nr表示根据模型选择的目标客户数,Nr(y=1)表示选择的目标客户中真正会响应的客户数。 (3)提升图(Lift Chart) 提升指数衡量的是与不利用模型相比,当我们使用目标客户选择模型时,对潜在客户的正确预测能力“提升”了多少。本文所使用的数据集的客户响应率是6%,即在不使用模型时目标客户的命中率是6%,那么当我们选取r%的客户作为目标客户时,提升指数lift=Hit rate/6%。提升图[9]的横轴表示将客户依据预测出的响应概率从大到小排序后抽取的客户比例,纵轴表示的是与之对应的提升指数(lift)。显然,提升指数越大表明模型的目标客户选择性能越好。 (4)洛伦兹曲线(Lorenz Curve) 作为另一个常用于评价目标客户选择模型性能的准则,洛伦兹曲线[4]能够线性直观的展示出各个模型的比较结果。它的横轴表示选出的目标客户占所有客户数的比例r%,纵轴表示选择比例为r%时与之对应的累计命中率。图中的对角线仅表示在不同比例下随机选取的目标客户对应的累计命中率,并不涉及任何模型的使用。当洛伦兹曲线越凸向左上角,即与对角线围成的面积越大,则说明该模型的目标客户选择性能越好。 4.4.1 模型的AUC值比较 图3展示了本文提出的CSSE模型与其它六种模型在CoIL2000上的AUC值,其中横坐标表示U和L中的样本比例从1∶1变化到5∶1。仔细分析图3,我们可以得到以下结论: 图3 七种模型在不同比例下的AUC值 (1)CSSE模型在五种不同比例下均具有最大的AUC值,因此,CSSE模型的整体目标客户选择性能要优于其他六种模型。六种对比模型均采用随机向上抽样的方法来平衡数据集类别分布,但它们的AUC值均低于CSSE模型,这说明与这六种模型相比,本文提出的代价敏感的目标客户选择半监督集成模型CSSE可以更有效地解决目标客户选择数据集中存在的类别分布不平衡问题。AUC 值通常被用于评价模型在类别分布不平衡数据集上的总体分类性能,CSSE模型在该评价指标上表现优异,这也说明了和已有的模型相比,CSSE模型将CSL,SSL和RSS方法进行融合确实具有更好的整体性能。 (2)在七种模型中,CSSE、DRSCO、CoBag、RASCO以及Semi-Bagging模型都属于半监督分类模型,而RSS和Bagging模型属于监督式分类模型。从图中可以看出大多数半监督分类模型如CSSE、DRSCO和CoBag的AUC值均大于两种监督式分类模型RSS和Bagging。然而,也有一些半监督分类模型的目标客户选择性能比较差,如RASCO模型和两种监督式分类模型的AUC值不相上下,而Semi-Bagging模型的AUC值更是低于两种监督式分类模型的AUC值。这表明,在多数情况下从大量无类别标签的数据集中选择性标记一部分样本加入到训练集中,确实能够提高目标客户选择的性能。但是如果模型的选择性标记的机制不够合理,导致大量被错误标记类别的样本加入到训练集中,从而很难提高模型的性能,有时甚至会损害模型的目标客户选择性能; (3)随着U和L中的样本比例不断增大,半监督分类模型中的CSSE、DRSCO和CoBag的AUC值虽然存在较小波动,但总体上保持较高水平并优于监督式分类模型RSS和Bagging,因为后面两种模型的AUC值大体上呈现出逐渐减小的趋势。特别地,本文提出的CSSE模型,当U和L中的比例不断增大时,它的AUC值与监督式分类模型的AUC值的差距在逐渐变大。这表明,当数据集包含大量无类别标签的样本时,相比于传统的监督式分类模型,本文提出的半监督分类模型CSSE更具优势。 4.4.2 模型的命中率比较 图4给出了本文提出的CSSE模型和其他六种对比模型的命中率,其中,(a)~(e)分别表示U和L中的样本比例从1∶1变化到5∶1的结果,同时,在每个子图中,我们还给出了目标客户选择比例(r%)从10%增加到50%时,各个模型的命中率比较。 根据图4,我们可以得出以下结论: (1)当U和L中的样本比例从1∶1增加到5∶1时,CSSE模型的命中率在各种不同的目标客户选择比例时均大于其他模型,这说明CSSE模型的目标客户选择性能是优于对比模型的; (2)在每个子图中,随着目标客户选择比例的增加,各个模型的命中率虽然存在一些波动,但是总体上均表现出逐渐下降的趋势。分析其原因,可能是因为我们是根据每个模型预测得到的测试集中所有客户做出响应的概率从大到小进行排序,最后选择前面r%的客户作为目标客户。因此,目标客户选择比例越小,就越可能选中那些真正的响应客户,命中率自然相对就越高; (3)大多数半监督式集成模型的命中率要高于2种监督式集成模型,而且随着U和L中的样本比 图4 七种模型命中率的比较 例增大,半监督模型的命中率仍能保持在较高水平,而RSS和Bagging的命中率值则呈下降趋势,这说明当数据集包含大量无类别标签的样本时,半监督分类模型具有明显优势。分析其原因,可能是因为监督式模型只使用少量有类别标签的数据集L来建模,而半监督分类模型则能够同时使用L和大量无类别标签数据集U中的样本来建模。 4.4.3 模型的提升图比较分析 图5展示了CSSE模型和其他六种模型的提升指数,其中,(a)~(e)分别表示U和L中的样本比例从1∶1变化到5∶1的结果。同时,在每个子图中,我们还给出了目标客户选择比例(r%)从10%增加到100%时,各个模型的提升指数的比较。 仔细分析图5,我们能够得出与4.4.2小节类似的结论: (1)当U和L中的样本比例从1∶1增加到5∶1时,CSSE模型的提升指数在不同的目标客户选择比例时均明显大于其他模型的,这说明该模型具有最好的目标客户选择性能; (2)在每个子图中,随着目标客户选择比例的增加,各个模型的提升指数虽然存在一些波动,但是总体上均表现出逐渐下降的趋势; (3)大多数半监督式集成模型的提升指数要高于2种监督式集成模型,而且随着U和L中的样本比例增大,半监督模型的优势更加明显。 4.4.4 模型的洛伦兹曲线比较 由于篇幅所限,我们仅给出了U和L中的样本的比例为5∶1时七种不同分类模型的洛伦兹曲线,见图6。从图中可以看出,当目标客户选择比例为10%、20%和30%时,CSSE模型的洛伦兹曲线均在其他模型的曲线上方,此时CSSE模型的累计命中率明显高于其他六种模型。在现实企业的目标客户选择问题中,企业的潜在客户通常很多,但由于营销预算的限制,我们往往只能选择排在前面的很小一部分的客户作为目标客户,从而向他们邮寄宣传资料,即目标客户选择的比例通常比较小。因此,与其它模型相比,本文提出的CSSE模型可望在现实企业的目标客户选择中取得更好的性能。 近年来,数据库营销成为客户关系管理领域的研究热点。而目标客户选择是数据库营销的重中之重,它能帮助企业提高客户响应率,增强核心竞争力,同时节约大量营销成本。在现实的目标客户选择建模中,往往只能获取少量有类别标签的样本,而剩下的大量样本都无法获取类别标签。已有研究大都使用监督式建模研究范式,仅在少量有类别标签 图5 七种模型的提升指数比较 图6 七种模型的洛伦兹曲线比较 样本集L上建模,很难取得令人满意的效果。为解决这一问题,本文引入SSL技术,将其与CSL和多分类器集成中的RSS方法相结合,提出了代价敏感的目标客户选择半监督集成模型CSSE。该模型使用代价敏感的SVM来解决目标客户选择建模中样本数据类别分布不平衡问题,还能够同时使用有、无类别标签的客户样本来建模。进一步地,该模型利用RSS方法训练一系列基本分类模型,并通过集成得到最终的分类结果。为了分析本文提出的CSSE模型在目标客户选择方面的性能,本文在某保险公司目标客户选择数据集上进行实证分析,同时将其与两种监督式集成模型、两种单一的半监督模型以及两种半监督集成模型相比较。我们选取AUC值、命中率、提升图和洛伦兹曲线作为模型评价准则。实验结果表明,CSSE模型具有更好的目标客户选择性能。
4 实证分析
4.1 数据集描述
4.2 实验设置
4.3 模型性能的评价准则

4.4 模型性能比较分析

5 结语

猜你喜欢
陶瓷学报(2021年4期)2021-10-14
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
少儿画王(3-6岁)(2020年4期)2020-09-13
初中生世界·九年级(2020年2期)2020-04-10
电子制作(2018年17期)2018-09-28
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
现代防御技术(2014年6期)2014-02-28
