
如何实现橄榄型分配格局?
——基于客观阶层标准的实证分析
2018-12-26 11:19杨天宇张令达
中国人民大学学报 2018年6期
杨天宇 张令达
一、引言
中共十八届三中全会决议提出,要“扩大中等收入者比重,努力缩小城乡、区域、行业收入分配差距,逐步形成橄榄型分配格局”。[注]《中共中央关于全面深化改革若干重大问题的决定》,46页,北京,人民出版社,2013。中共十九大报告进一步提出,要“扩大中等收入群体,增加低收入者收入,调节过高收入”。[注]习近平:《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利——在中国共产党第十九次全国代表大会上的报告》,46页,北京,人民出版社,2017。这表明,通过“增低、扩中、调高”形成橄榄型分配格局,已成为党和政府的重要政策目标。所谓橄榄型分配格局,就是一种“两头小”(低收入群体和高收入群体在社会阶层中均占少数)、“中间大”(中等收入群体占比最多)的收入分配结构。目前学术界对收入分配问题已经有了大量的研究成果,但已有文献中关于缩小居民收入差距的研究很多,对如何实现橄榄型收入分配格局的研究却不多见。从逻辑上说,仅仅缩小居民收入差距还不足以形成橄榄型分配格局,只有缩小居民收入差距带来低收入者比重缩小和中等收入者比重扩大,才能形成橄榄型分配格局。所以,我们首先需要弄清楚我国居民收入分配格局的现状和橄榄型分配格局的影响因素,并在此基础上合理地选择缩小居民收入差距的方向,才能找到实现橄榄型分配格局的可行途径。
目前学术界关于收入分配方面的文献,主要集中于研究收入分配差距,这些研究大都以基尼系数、泰尔指数、变异系数等收入不平等的测度为基础,但这些测度只能反映收入的总体离散程度,而无法反映居民内部各阶层的规模和收入变化,这显然不适合用来分析橄榄型分配格局。研究居民收入分配格局是不是橄榄型的,首先需要准确估计各个收入群体所占的比重,而这就需要为不同收入群体之间设定排他性的边界。迄今为止,关于这类边界的设定都有一定的主观性,不同学者有不同的分类方法。已有文献对不同收入群体的划分标准大体可以分为两类,即绝对标准和相对标准。绝对标准是通过一定的收入水平或消费支出范围来确定中等收入阶层。例如,世界银行将全球中产阶层划分为人均年收入落于巴西和意大利的平均收入水平之间,即年人均收入4 000~17 000美元。[注]World Bank.“Global Economic Prospects 2007: Managing the Next Wave of Globalization”.World Bank Publications, 2007(33): 190-192.伯兹奥尔(N.Birdsall)以2010年购买力平价的1 050美元作为8个拉丁美洲国家的中产阶层标准。[注]Birdsall, N.“A Note on the Middle Class in Latin America”.CGD Working Paper No.303, 2012.卡拉斯(H.Kharas)将每日人均支出10美元至100美元(购买力平价)作为发展中国家的中产阶层标准。[注]Kharas, H.“The Emerging Middle Class in Developing Countries”.OECD Developing Centre Working Papers No.285, 2010.森(A.Sen)用每日人均2美元以下的消费水平作为低收入阶层的衡量标准。[注]Sen, A.“Poor Relatively Speaking”.Oxford Economic Papers, 1983(35): 153-169.班纳吉(A.Banerjee)和迪弗洛(E.Duflo)将每日人均支出6~10美元作为中等收入阶层的衡量标准。[注]Banerjee, A., and E.Duflo.“What is Middle Class about the Middle Classes around the World?”.Journal of Economic Perspectives, 2008(22): 3-28.国家发改委课题组把家庭人均年收入2.2万~6.5万元作为中等收入者的标准,据此估算出2010年我国城镇中等收入者比重为37%。[注]国家发改委社会发展研究所课题组:《扩大中等收入者比重的实证分析和政策建议》,载《经济学动态》,2012(5)。李强和徐玲将家庭人均年收入3.5万~12万元的群体界定为中等收入群体,据此估算出2012年全国、城镇和农村的中等收入群体比重分别为17.9%、27.9%和6%。[注]李强、徐玲:《怎样界定中等收入群体?》,载《北京社会科学》,2017(7)。上述文献中关于中等收入群体的界定标准差别很大,得出的结论也不一致。
相对标准通常是以中位数收入为中心上下浮动一定比例,以得到某群体的收入上下限。由于不同年份的收入中位数不同,收入上下限的具体数值也是经常变化的。美国经济学家索罗(L.Thurow)的论文是这方面较早的文献,他选取中位数人均收入的75%和125%作为划分中等收入群体的上下限。[注]Thurow, L.“A Surge in Inequality”.Scientific American, 1987(256): 30-37.伯兹奥尔等把收入介于中位数50%~125%之间的人界定为中等收入群体[注]Birdsall, N., Graham, C., and S.Pettinato.“Stuck in Tunnel: Is Globalization Muddling the Middle?” .Brookings Working Paper No.14, 2000.,普雷斯曼(S.Pressman)采用中位数收入67%~200%的标准来界定中等收入群体[注]Pressman, S.“Defining and Measuring the Middle Class”.American Institute for Economic Research Working Paper No.7, 2015.。汤森德(R.Townsend)用收入均值的50%以下作为低收入阶层的衡量标准。[注]Townsend, R.“A Sociological Approach to the Measurement of Poverty—A Rejoinder to Professor Amartya Sen”.Oxford Economic Papers, 1985(37): 659-668.国内也有很多文献采用相对标准。李培林和朱迪用收入分位值代替中位数,把中等收入群体的上限确定为城镇居民收入的第95 百分位(含),下限确定为城镇居民收入的第25百分位,据此计算出2006—2013年我国城镇中等收入者比重在24%~28%之间波动。[注]李培林、朱迪:《努力形成橄榄型分配格局——基于2006—2013年中国社会状况调查数据的分析》,载《中国社会科学》,2015(1)。龙莹将中等收入群体的上下限界定为中位数收入的75%~125%之间,她发现中国的中等收入群体比重自1988年的27.9%下降到2010年的21.1%。[注]龙莹:《中等收入群体比重变动的因素分解——基于收入极化指数的经验证据》,载《统计研究》,2015(2)。张媛(Zhang Yuan)等同样将中等收入群体的上下限界定为中位数收入的75%~125%之间,得出中国农村中等收入家庭的比重从1988年的37.3%下降到2007年的32.7%。[注]Zhang,Y., Wan,G., and N.Khor.“The Rise of Middle Class in Rural China”.China Agricultural Economic Review, 2012(4): 36-51.相对标准与绝对标准相似,都需要主观地确定收入的上下限,而且对于像中国这样存在大量低收入人口的发展中国家,按此方法归类的一部分中等收入群体成员实际上是低收入者。[注]李春玲:《中国特色的中等收入群体概念界定——绝对标准模式与相对标准模式之比较》,载《河北学刊》,2017(2)。
可见,无论是绝对标准,还是相对标准,都需要人为地确定某个收入群体的收入上下限。这种做法虽有一定参考价值,但主观判断的色彩过强,结果差别较大,难以对收入分配格局进行客观评价。本文试图为居民内部各阶层的界定找到一个相对客观的评价标准,在此基础上对橄榄型分配格局的影响因素和实现途径进行实证分析。我们首先运用社会科学中最新发展的有限混合模型(Finite Mixture Model)来测算包括中等收入群体在内的居民内部各阶层规模。有限混合模型本质上是一种聚类分析方法,它不是根据某种主观设定的标准来划分各个群体,而是依照某种准则把一个数据集划分为若干个群体(可称为类或簇),使同一个群体中的个体具有较高的相似性,不同群体中的个体则没有相似性。这一过程是无监督的,即在这一过程中没有任何关于各个群体分类的先验知识,仅靠群体间的异质性作为划分各个群体的分类准则,这保证了分类结果的客观性。分类的标准由我们所观察到的个体行为所决定,在居民收入分配格局的分析中,我们可以用居民收入水平作为群体异质性的分类标准。通过聚类分析,我们可以计算出每个类(即群体)的分布参数和权重,这样就可以得出不同收入群体的主要特征和比重,而不必诉诸主观设定的群体收入标准。
这一方法已被应用于社会科学中的多个学科。例如,梅特拉(Maitra)利用有限混合模型测算了印度社会各阶层的规模,但他划分印度各阶层的标准是耐用品消费而不是居民收入。[注]Maitra, S.“The Poor Get Poorer: Tracking Relative Poverty in India Using A Durable-Based Mixture Model”.Journal of Development Economics, 2016(119): 110-120.安德森(G.Anderson)等用有限混合模型测算了中国1992—2001年城镇居民各阶层的规模,但他们所用的数据过于陈旧,而且由于缺乏城乡统一的微观家庭数据,他们的测算结果仅限于城镇居民。同时,他们也没有分析居民收入分配格局的影响因素。[注]Anderson, G., Farcomeni, A., Pittau, G., and R.Zelli.“A New Approach to Measuring and Studying the Characteristics of Class Membership: The Progress of Poverty, Inequality and Polarization of Income Classes in Urban China”.University of Toranto Working Paper No.521, 2014.本文所要考察的橄榄型分配格局,其含义是居民收入的分配格局,因此我们采用收入而不是消费作为各收入群体的分类准则。而橄榄型的分配格局,应该是全国性的,而不是只局限于城镇或农村地区的居民收入分配格局。国家统计局在2012年底进行了城乡住户调查一体化改革,常规住户调查大样本库中的数据是城乡统计口径一致的居民收入数据。本文利用统计局大样本库的子样本,即中国家庭收入调查(CHIP)2013年的微观数据,根据有限混合模型估算出全国各个收入群体的规模,然后再利用回归分析估计家庭特征等因素对形成橄榄型分配格局的影响,在此基础上得出实现橄榄型分配格局的可行途径。
本文与已有文献的差异表现在三个方面。第一,本文没有主观设定各群体的收入上下限,而是利用有限混合模型得出更具客观性的分配格局;第二,本文估计了全国层面城乡收入口径统一的居民收入分配格局;第三,本文利用计量方法估计了家庭特征对实现橄榄型分配格局的影响。
二、研究方法和数据
(一)研究方法
本文应用有限混合模型测度我国的居民收入分配格局。我们不想采用主观确定的收入上下限来区分各个群体,所以需要弄清楚各个潜在群体(与外生干预无关)的内生异质性,然后再用这种内生的异质性来对全部人群进行分类,分类后的结果自然就是组成全部人群的各个群体。而有限混合模型的优势恰恰在于它能够区分潜在子群体的(未被观测的)内生异质性,因此适用于本文的研究主题。
在统计方法上,我们首先假定全部人群的数据可以分为i个存在内生异质性的子群体,每个子群体都有各自的分布特征。这样,全部人群的数据就可以看成是一个由多种统计分布组成的“混合”分布,有限混合模型就是对这种包含多种统计分布的混合分布进行建模。假定全部人群的收入数据是来源于i个不同的子群体,那么有限混合模型的条件密度分布函数可以用以下公式描述:
(1)
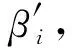
我们已经指出,运用有限混合模型估计居民各阶层的规模,不需要人为确定某个阶层的收入上下限,不需要知道任何关于群体分类的先验知识,这保证了分类结果的客观性。对(1)式来说,这意味着我们既不知道每个子群体的分布参数θi,也不知道每个家庭属于某个子群体的先验概率θi,这增加了求解(1)式的难度。因此,我们采用最大期望值算法( EM algorithm)估计(1)式的所有参数。该方法由两个步骤构成。第一步,先给出每个子群体分布的初始估计参数,然后估计每个家庭属于群体i的后验概率(posterior probability)πj,并通过最大化后验概率将数据归类为组,就可以将每个家庭归入不同的阶层。最大化后验概率用以下公式表示:
(2)
得出后验概率πj之后,我们可以根据(2)式推算出先验概率πi。
第二步,以先验概率πi为权重,分别对每个组成部分的对数似然函数求最大化,求解各子群体分布的估计参数:
θi=argmax∏πiP(θi|x)
(3)
第一步和第二步是一个循环重复迭代过程,通过不断迭代,最终一个最优的参数值会稳定下来,(1)式的参数估计结果也就算出来了。这样,我们就可以把全部人群按照后验概率的不同划分为不同的收入群体,并计算出不同收入群体的各项参数,从而得出居民各阶层的人口份额、收入份额和收入来源。
为了确定模型中的子群体个数,可以采用信息评价指标AIC和BIC值来判断有限混合模型的拟合效果。这两个指标的含义是通过比较期望值与实际值差异来判断拟合效果的优劣,指标值越小表示拟合得越好。根据大部分实证研究的经验,大多使用BIC值作为模型拟合效果指标,选择BIC值最小的模型作为最佳模型。[注]王孟成、毕向阳、叶浩生:《增长混合模型:分析不同类别个体发展趋势》,载《社会学研究》,2014(4)。在本文中,我们使用Python软件中的SKLEARN软件包,对多个子群体的有限混合模型依次进行拟合,并重复 100次, 由此计算出每个模型的BIC值, 最后选取BIC值最小的模型。
为了考察家庭特征对居民收入分配格局的影响,我们根据计算得出的每个阶层的分布参数,得到不同收入值属于这一阶层的概率。这样,我们就可以在全部样本中识别出那些最有可能属于这一阶层的家庭,然后再通过回归分析,得出家庭特征因素对该家庭属于某个阶层的概率之影响。我们构造以下回归方程来估计家庭属于某个收入群体的影响因素:
lnYi=β0+β1x1i+β2x2i+…+βnxni+ε
(4)
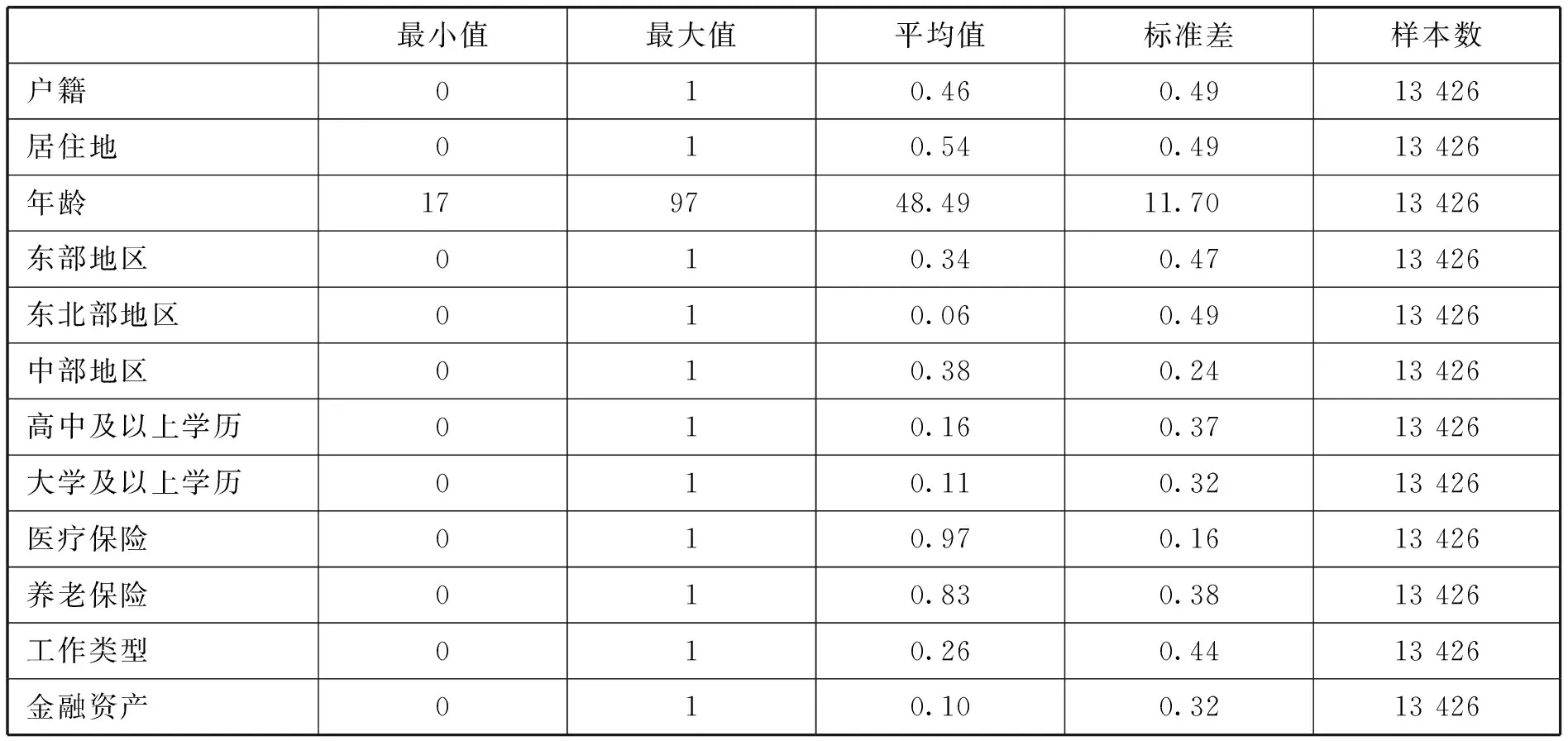
xni为影响家庭所属收入群体的家庭特征因素,β0是常数项,ε是误差项。Yi为个体家庭属于某一收入阶层的概率密度的对数。在这里,我们使用的是概率密度,而不是后验概率。这是因为概率是通过概率密度在分布函数上积分得出的,而在利用分布函数求概率时,如果求取某个收入点属于某个阶层的概率,由于点的长度无限小,因此概率为0。为了解决这个问题,我们可以用概率密度值近似地表示概率值。[注]从微分的角度来看,我们将某一点的长度取微分dx,再用概率密度值f(x)乘以微分dx,可以得到极小区间(x0, x0+dx)上的概率近似值,也就是说,P(x “中国家庭收入调查(CHIP)2013”是由北京师范大学中国收入分配研究院联合国内外专家共同完成的项目,具体的调查过程由国家统计局城乡一体化常规住户调查办公室执行。CHIP 2013数据的样本来自国家统计局2013年城乡一体化常规住户调查大样本库,该样本库覆盖了全部31个省(市、自治区)的16万户居民。CHIP 2013的样本是对国家统计局的大样本库按居民收入的高低排序后,采取等距抽样的方法得到。样本覆盖了从15个省份126城市234个县区中抽选出的18 948个住户样本和64 777个个体样本,其中包括7 175户城镇住户样本、11 013户农村住户样本和760户外来务工住户样本。调查数据提供了城乡各阶层住户个人层面的基本信息、就业信息,以及家庭层面的基本信息和主要收支信息,包括收入、支出、住户成员个人情况、2013年劳动时间安排、就业情况、住户资产等内容。本文的研究目的是考察全国层面的居民收入分配格局,因此我们将城镇样本、农村样本和外来务工样本合并为全国样本,并应用有限混合模型测算全国居民各收入群体的规模。通过对问卷数据进行整理,去除掉缺省值和负值,样本中共有6 637个城镇家庭、10 442个农村家庭、719个外来务工家庭,合计17 798个家庭。 在估计居民收入分配格局时,我们采用了调查问卷中家庭层面的“2013年住户可支配收入总额”数据。可支配收入是指家庭所有成员获得的可自由支配的家庭总收入,包括工资性收入、经营净收入、财产性收入和转移性收入,是在支付个人所得税、财产税及其他经常性转移支出后所余下的实际收入。考虑到在家庭整体可支配收入总额相同的情况下,家庭人数规模的不同会带来生活水平的显著差异,因此本文通过调查问卷中个人层面的住户成员代码,统计出每个家庭的人口数,用住户可支配收入总额除以人口数,得到2013年住户人均可支配收入,本文将使用这一数据进行有限混合模型和回归方程的估算。 我们首先考虑模型参数数量,即根据我们的样本数据特点,将全部家庭按人均可支配收入划分为几个阶层最为合理。为了确定模型中的子群体个数,我们使用Python软件中的SKLEARN工具包,对于样本中给定的17 798个家庭人均可支配收入样本值,使用贝叶斯信息标准(即BIC值)进行了评估。我们对从1到5个子群体的有限混合模型依次进行拟合,并重复100次, 由此计算出每个模型的BIC值, 最后选取BIC值最小的模型。根据BIC计算的结果,5个子群体的有限混合模型是拟合效果最好的模型,其BIC值在每次重复计算中都是最小值,因此可以认为,将全部家庭分成5个阶层最为合理。 在计算出有限混合模型的分类后,我们假定全部家庭的人均可支配收入数据是来源于5个不同的子群体,然后利用公式(2)和公式(3),估计5个子群体的规模特征。具体估计结果如下: 表1 居民各阶层规模的测算结果 注:均值和标准差都以元为单位,人口份额表示每个阶层的家庭数量占全部家庭数量的比重,收入份额表示每个阶层的收入总和与全部居民收入总和的比值。 表1列出了2013年城乡全部居民各阶层特征的测算结果。从中可以看出,各阶层的收入均值、收入份额和人口份额都有显著差异。根据各阶层的人口份额特征,我们可以把这5个阶层分别视为低收入阶层、中低收入阶层、中等收入阶层、高收入阶层和超高收入阶层。第一阶层称为“低收入阶层”,家庭人均可支配收入均值仅为9 189元,这部分家庭占到全部家庭的54.04%,已经超过半数。第二阶层称为“中低收入阶层”,家庭人均可支配收入均值为22 787元,占比33.43%。第三阶层称为“中等收入阶层”,其均值为43 159元,占比仅10.63%。第四阶层称为“高收入阶层”,其均值达到83 568元,已经是中等收入阶层的近两倍,占比只有1.78%。最后,第五阶层称为“超高收入阶层”,这部分人群的家庭人均可支配收入均值为273 943元,已经远远超过了其他收入阶层,但占比极少,仅有0.01%。 李培林和朱迪曾经估算2013年城镇低收入、中低收入、中等收入和高收入阶层分别占比为18%、55%、25%和2%。[注]李培林、朱迪:《努力形成橄榄型分配格局——基于2006—2013年中国社会状况调查数据的分析》,载《中国社会科学》,2015(1)。与他们的估计结果相比较,本文估计的低收入阶层比重偏高,中等收入以上的各阶层比重偏低,而且呈现明显的金字塔型分配格局。产生这个差别的原因很可能是样本范围的不同。李培林和朱迪使用的调查数据样本仅限于城镇居民,而本文的样本则是城乡统计口径一致的全体居民。为了揭示样本范围不同对研究结果的影响,我们用1 000元作为分组单位,以家庭人均可支配收入作为分组标准,分别统计了城镇居民和全体居民各个收入分组的家庭数量,统计结果见图1。其中左图为城乡全体居民的收入分组,右图为城镇和农村居民的收入分组[注]国家统计局没有公布外来务工家庭的城乡分类标准,因此我们在进行城乡对比时剔除了外来务工家庭。由于外来务工家庭只占本文样本容量的4%,所以,本文的做法对分析结果影响不大。。 图1 家庭人均可支配收入分布状况 注:(1)统计的数据为家庭人均可支配收入总额,统计单位为家庭。(2)收入的分组单位分别为1 000元。纵轴表示收入的分组,“0”表示“0~1 000元(不包含1 000元)”,11 000表示“11 000~12 000元(不包含12 000元)”。横轴表示处于某一收入分组的家庭数量。 从图1可以看出,如果把城乡全体居民视为一个整体,那么集中于底部的家庭数量相当多,收入越高则家庭数量越少,呈现明显的金字塔型分配格局,这与本文对居民收入分配格局的测算结果是吻合的。但如果我们分别统计城镇和农村的收入分组,则可以发现,农村居民的收入分组仍然呈现与城乡全体居民相似的金字塔型分配格局,但城镇居民的收入分组却已经接近橄榄型,特别是处于中等偏下收入的家庭数量最多,而这与李培林和朱迪所发现的中低收入阶层比重最高、低收入阶层比重较低的测算结果也是吻合的。换句话说, 由于农村的低收入家庭数量较多,如果我们考虑城乡口径统一的全体居民,而不仅仅是城镇居民,那么金字塔型分配格局会更加明显,与橄榄型分配格局的距离也更远。这也提示我们,城镇化可能会促进橄榄型分配格局的形成。 在估计出居民各阶层的人口份额之后,我们通过计算每个阶层的收入份额(该阶层收入总和/全体居民收入总和)来大致估算总收入在不同阶层的分配情况。占有全部人口54.04%的低收入阶层,其总体收入份额却只有24.72%。中低收入阶层占有社会收入份额的比例最高,为40.24%,是收入份额与人口份额最接近的阶层。中等收入阶层与低收入阶层的收入份额接近,但是其人口份额只有低收入阶层的1/5。而高收入阶层和超高收入阶层的收入份额之和只有1.79%,其收入份额却达到了10.34%。总的来看,中低收入以上阶层的收入份额都超过了人口份额,唯有低收入阶层的收入份额大大低于人口份额。这说明,中国人均收入水平较低,主要是因为低收入家庭过多造成的。减少低收入家庭的数量,不但可以改善金字塔型的收入分配格局,还可以提高总人口的人均收入水平。 为了更好地比较各阶层的差异,我们对各阶层的收入构成进行对比。从表2可以看出,各阶层的收入构成有较大差别。中等收入阶层和中低收入阶层都以工资性收入为主,经营性收入和财产性收入比重不高;而高收入阶层和超高收入阶层的工资性收入比重明显低于中等收入和中低收入阶层,经营性收入和财产性收入比重则高于中等收入和中低收入阶层,这反映出高收入和超高收入阶层的经营和投资活动比较活跃,回报也较高,这也成为高收入和超高收入家庭与中等收入家庭区别的标志。对中等收入和中低收入家庭来说,由于缺乏多样化的收入渠道,工资性收入占比较高,这意味着,对这两个阶层的工资性收入实行一定程度的税收减免,有利于提高中低收入和中等收入家庭的收入,特别是有利于中低收入家庭更多地进入中等收入阶层。从低收入家庭的情况来看,本文测算的低收入家庭工资性收入比重偏低。例如,李培林和朱迪测算出2013年城镇低收入家庭工资性收入在家庭总收入中占比为59%[注]李培林、朱迪:《努力形成橄榄型分配格局——基于2006—2013年中国社会状况调查数据的分析》,载《中国社会科学》,2015(1)。,而本文测算的结果只有45.11%。相反,本文测算的低收入阶层经营性收入比重却偏高,达到28.26%,接近了高收入阶层的经营性收入比重。这其中的原因仍然在于城乡差别。本文的样本范围是城乡全体居民,自然也就包括了大量从事第一产业经营的低收入农民家庭,从而拉高了整个低收入阶层的经营性收入比重,工资性收入比重也因此而降低。所以,要提高低收入家庭的收入水平,除增加工资性收入之外,努力使农村低收入家庭的经营性行为由分散的个体经营转型为规模经营,由低端的第一产业转型为第二、三产业,也是不应忽视的。 表2 各收入阶层收入结构的对比 综观以上对居民各阶层的规模测算和分析,可以发现,中国居民收入分配仍然呈现明显的金字塔型格局,不同群体之间的收入差距较大,中等收入阶层比重过低,低收入阶层比重过高,尤其是农村低收入阶层数量巨大,导致目前的居民分配格局距离橄榄型还有很大差距。 我国居民收入分配格局能否从金字塔型转变为橄榄型,归根结底取决于制约分配格局的各种因素能否改变。本节将利用(4)式研究不同阶层的家庭特征,从微观层面分析居民收入分配格局的影响因素,以得出橄榄型分配格局的实现途径。 本文使用户主的相关信息来描述居民的家庭特征。剔除没有家庭可支配收入和存在缺失值的家庭,我们使用13 426个家庭的数据进行相关研究,见表3。限于数据的可获得性,本文考察的家庭特征变量大多为离散变量。 表3 变量含义说明 *:由于CHIP数据库中缺乏住户的住房信息,因此,本文忽略了家庭拥有的不动产因素。 在13 426个家庭中,户主为非农业户口的有6 207个家庭,户主为农业户口的有7 219个家庭。从居住地来看,居住在城市地区的家庭比重为53.71%。从统计的户主年龄看,主要集中在30~60岁,占比达到了78.28%。从家庭所在地区来看,样本中位于东部地区的家庭占比为34.15%,中部地区家庭占比为37.99%,西部地区家庭占比为21.53%,还有6.33%的家庭来自东北地区。从户主最高学历来看,受教育程度普遍不高,其中受过大专、大学本科或研究生教育的家庭仅占11.34%,受过高中、职高/技校或中专教育的家庭仅为16.28%,剩下72.38%的家庭户主为更低的受教育程度。从社会保障情况来看,在全部样本家庭中,社会保障覆盖范围已经达到了98%,其中参加医疗保险的家庭占比达到了97.38%,参加养老保险的家庭占比达到了83.02%。从户主从事的工作类型来看,有25.66%的家庭在国有部门工作。从拥有的资产状况来看,拥有股票、基金、国债等其他债券、期货这类金融资产的家庭占比为10.44%。表4提供了上述所有变量的描述性统计特征。 表4 变量的描述性统计 为了更全面地考察居民所属收入阶层的影响因素,我们对多个阶层方程的估计结果进行比较,以便更清楚地揭示各个影响因素的作用。从上文分析来看,我国低收入阶层占比达到54%,中低收入阶层和中等收入阶层合计占比44%,且本文的重点在于扩大中等收入阶层,因此我们重点分析低收入阶层、中低收入阶层和中等收入阶层的影响因素,并对各影响因素在不同阶层中的作用进行比较。我们使用固定效应模型和STATA 12.0软件对(4)式进行回归,各阶层模型的因变量均为个体家庭属于该阶层的概率密度。回归结果见表5。 表5 居民收入分配格局影响因素的回归结果 注:括号内为标准误差,*、**、***分别表示系数在10%、5%和1%的水平上显著。 从表5可以看出,不同阶层模型得到的回归结果有很大差别。户籍变量在三个模型中的回归系数均非常显著。在低收入阶层和中低收入阶层的回归模型中,户籍的系数为正,表明农村户籍家庭属于低收入阶层和中低收入阶层的概率更高。特别是在低收入阶层的回归模型中,户籍的系数更大,即农村户籍家庭更有可能属于低收入阶层。与城市户籍家庭相比,农村户籍家庭属于低收入阶层的概率是城市户籍家庭的5.49倍。相反,户籍的系数在中等收入阶层模型中为负数,城市户籍家庭属于中等收入阶层的概率比农村户籍家庭高1.01倍。通过对比可以发现,城乡户籍间存在明显的阶层差别,反映出户籍歧视仍然是产生阶层分布差别的重要原因。 居住地变量的系数在低收入阶层和中低收入阶层的模型中显著为正,说明居住在农村的家庭更有可能属于这两个阶层。其中,低收入阶层的城乡居住地差别更加明显,居住在农村的家庭成为低收入阶层的概率是居住在城市的家庭的7.79倍。相比之下,居住地在中等收入阶层模型中的系数则显著为负,居住在城市的家庭属于中等收入阶层的概率比居住在农村的家庭高63.83%。这说明城市更好的就业机会和社会福利仍然是产生阶层差别的重要原因。这个结果也证实了我们根据图1提出的预言,即城镇化有利于建立橄榄型分配格局。值得注意的是,比较居住地变量与户籍变量的计量结果,我们可以发现,若农村户籍家庭不迁入城市[注]此处假定农村居住地家庭都是农村户籍家庭。,则该家庭与城市居住地家庭成为低收入阶层的概率差距(7.79倍)要大于该家庭与城市户籍家庭成为低收入阶层的概率差距(5.49倍),即农村户籍家庭迁入城市居住,将会降低成为低收入家庭的概率,这表明,常住人口城镇化为农村户籍家庭摆脱低收入阶层提供了更多的机会。相反,若农村户籍家庭不迁入城市,则该家庭与城市居住地家庭进入中等收入阶层的概率差距(63.83%)要小于该家庭与城市户籍家庭进入中等收入阶层的概率差距(1.01倍),即农村户籍家庭迁入城市居住后,这些家庭进入中等收入阶层的概率并没有提高。可见,要想提升农村户籍家庭进入中等收入阶层的概率,仅有常住人口城镇化是不够的,还需要户籍人口的城镇化。 年龄变量在低收入阶层模型和中低收入阶层模型中的回归系数非常显著,且均为正数。即户主年龄越大,就越有可能沦为低收入和中低收入阶层,这可能是因为年长者的家庭负担比年轻人更重,而就业机会却少于年轻人。 地区虚拟变量中东部地区的回归系数在三个模型中均非常显著,而中部地区和东北地区的回归系数均不显著。在低收入阶层和中低收入阶层模型中,东部地区的系数为负数,这说明与对照组(即西部地区)相比,东部地区家庭属于这两个阶层的概率明显偏低。特别是在低收入阶层的模型中,西部地区家庭沦为低收入阶层的概率是东部地区的7.2倍。而在中等收入模型中,东部地区的系数显著为正数,东部地区家庭属于中等收入阶层的概率比西部地区高39.88%。这说明地区差距也造成了阶层分布的差别。 两个学历变量的系数在低收入阶层模型和中低收入阶层模型中均非常显著,大学及以上学历的系数在中等收入阶层模型中也非常显著。在低收入阶层模型中,户主是初中及以下学历的家庭沦为低收入阶层的概率是户主为大学以上学历家庭的12.87倍,是户主为高中以上学历家庭的2.33倍。而在中等收入阶层模型中,相比户主是初中及以下学历的家庭,大学及以上学历家庭进入中等收入阶层的概率增加19.26%。由此可见,学历越低的家庭就越有可能陷入贫困,教育是扩大中等收入者比重的重要途径。 工作类型变量的系数在低收入阶层模型和中等收入阶层模型中均非常显著,但符号相反。在低收入阶层模型中,与户主在国有部门内工作的家庭相比,户主在非国有部门内工作的家庭成为低收入阶层的概率要高54.23%。而在中等收入阶层模型中,户主在国有部门工作的家庭更容易进入中等收入阶层,其概率比户主在非国有部门工作的家庭高20.77%,这表明国有部门更高的工资和福利待遇也是造成阶层差别的原因,这一结果与已有文献的发现是一致的。[注]陆正飞、王雄元、张鹏:《国有企业支付了更高的职工工资吗?》,载《经济研究》,2012(3)。 资产状况虚拟变量的回归系数在低收入和中低收入阶层模型中显著为负,在中等收入阶层模型中显著为正。有金融资产的家庭属于中等收入阶层的概率要比无金融资产的家庭高2.26倍,而无金融资产的家庭属于低收入和中低收入家庭的概率则要分别比有金融资产的家庭高11.27倍和2.27倍。可见,家庭财产性收入的多寡对于该家庭属于何种阶层也是至关重要的因素。 医疗保险变量和养老虚拟变量在三个模型中均不显著,这可能是因为在我们的样本中,医疗保险和养老保险的覆盖范围已经达到了97%和83%,不同收入阶层的家庭在此项上的区别较小。 综上,我们发现,户籍、居住地、区域、教育水平、工作类型和资产状况等家庭特征因素都会影响个体家庭属于某个阶层的概率,进而影响居民收入分配格局的形成。从回归系数来看,在影响个体家庭属于低收入阶层的各种因素中,最重要的是教育水平,其他各因素按照影响程度的大小排序,分别为资产状况、居住地、区域、户籍和工作类型。而在影响个体家庭属于中等收入阶层的诸多因素中,最重要的是资产状况,其他各因素按照影响程度的大小排序,分别为户籍、居住地、区域、工作类型和教育水平。 基于城乡收入口径统一的微观数据和有限混合模型方法,本文以聚类分析的客观标准代替人为确定收入上下限的主观标准,测算了全社会各阶层的人口规模、收入份额和收入来源,并对影响收入分配格局的诸多因素进行了实证分析,初步得出了我国居民收入分配格局的大致状况和影响因素。归结起来,本文有以下四点发现: 第一,我国居民收入分配呈现明显的金字塔型格局,与橄榄型分配格局的差距比已有文献的测算要更大,其原因在于农村的低收入家庭数量巨大。如果考虑城乡收入口径统一的全部居民,而不仅仅限于城镇居民,那么金字塔型分配格局将更加明显。 第二,中低收入以上阶层的收入份额都高于人口份额,唯有低收入阶层的收入份额大大低于人口份额,这表明,中国人均收入水平较低的主要原因是低收入家庭过多。若能缩减低收入家庭的数量,不但有利于实现橄榄型分配格局,还可以提高总人口的人均收入水平。 第三,中等收入和中低收入阶层工资性收入比重偏高,低收入阶层经营性收入比重偏高。所以,工薪税收的减免有利于扩大中等收入群体;推动农村低收入家庭的经营性行为转型升级,由分散的个体经营转型为规模经营,由低端的第一产业转型为第二、三产业,这将有利于提升低收入阶层的收入、缩减低收入阶层比重。 第四,要实现橄榄型的分配格局,可以分为两个方面。(1)我国的低收入阶层人口占比仍然较高,而橄榄型分配格局要求尽量缩减低收入人口比重。为达到这个目标,最重要的途径是提升低收入阶层的教育水平,其次是增加低收入者的财产性收入、推动农村人口城镇化,再次是提高欠发达地区低收入阶层的收入水平,缩小与发达地区的差距,此外还应推动户籍人口城镇化、缩小不同所有制之间的收入差距。(2)橄榄型分配格局还要求扩大中等收入群体,提高中等收入阶层比重。目前我国中等收入阶层的占比仍然较低,从本文计量结果来看,提升其比重的最重要途径是增加低收入和中低收入阶层的财产性收入,其他途径按照重要性排序依次为户籍人口城镇化、常住人口城镇化、缩小地区收入差距、缩小不同所有制之间的收入差距和提升教育水平。 自“逐步形成橄榄型分配格局”的政策主张提出以来,对于如何实现橄榄型分配格局已经有了大量的政策建议。但很多建议都缺乏实证依据,仅仅是测算出居民各阶层规模之后的推论。本文对橄榄型分配格局实现途径的讨论,则是建立在对微观数据进行实证分析的基础上。分析结果显示,实现橄榄型分配格局的各种途径,其重要性是不同的;推动低收入者脱离低收入阶层,和中等收入以下群体进入中等收入阶层,其实现的途径也是不一样的。本文对居民收入分配格局影响因素的实证分析,可能有利于对实现橄榄型分配格局提出更细化和更具操作性的政策建议。 依据本文对橄榄型分配格局实现途径的测算结果,我们认为合理的政策建议可能包括“制度改革”和“经济发展”两大类。例如,推动农村人口城镇化、户籍人口城镇化,都要求政府出台相关改革方案,消除农业劳动力自由流动的障碍;增加低收入者财产性收入,则要求保障居民合法的财产权、发展和完善资本市场,以提升低收入者的财富积累和财产性收入回报率;缩小不同所有制之间的收入差距,则需要推进福利制度等层面的改革,打破劳动力流动的制度性障碍。至于提升教育水平和缩小地区收入差距,则不是仅靠制度改革就能解决的,这需要合适的经济发展政策。政府可以对低收入阶层和欠发达地区实行必要的政策倾斜,以逐步提升其教育和收入水平。(二)数据来源
三、我国居民各阶层的规模估计
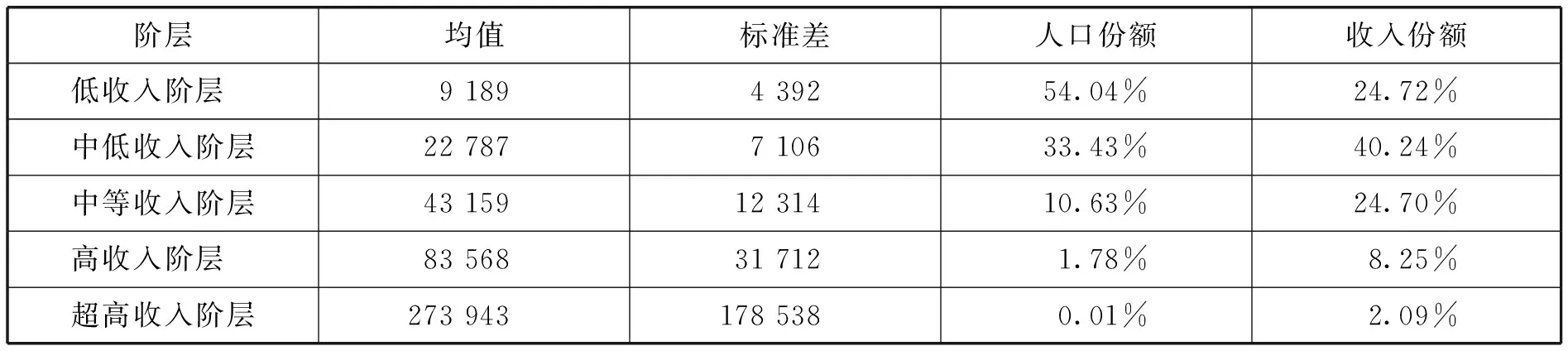
(一)各阶层规模的估计结果

(二)各阶层的收入构成分析

四、我国居民收入分配格局的影响因素


五、结论和政策建议
猜你喜欢
华人时刊(2022年15期)2022-10-27
华人时刊(2022年15期)2022-10-27
今日农业(2022年15期)2022-09-20
社会科学战线(2022年7期)2022-08-26
安徽农业科学(2022年6期)2022-04-11
今日农业(2021年14期)2021-11-25
当代陕西(2019年17期)2019-10-08
英语文摘(2019年7期)2019-09-23
妇女生活(2018年10期)2018-10-12
消费导刊(2018年8期)2018-05-25
