
一种基于栈区内存模型的C程序别名判断算法
2019-02-15 09:21罗奇鸣李薛剑陈意云
小型微型计算机系统 2019年2期
常 欢,罗奇鸣,李薛剑,陈意云
(中国科学技术大学 计算机科学与技术学院,合肥 230026) (中国科大先进技术研究院 中国科大国创高可信软件工程中心,合肥 231283)
1 引 言
C语言因灵活高效的特性广泛应用于系统软件的开发中.C语言的指针操作没有任何保护,这给C语言带来很多不安全因素,导致C语言程序容易出现缺陷.在军事、航天、医疗设备、交通、能源、金融等安全攸关的应用领域, 任何软件缺陷都可能导致灾难性的后果,软件工程的历史上多次出现了这样的案例.对于这些领域用C语言开发的软件系统,保障其质量(尤其是正确性和安全性)是至关重要的.
目前在软件产业界,主要的质量保障方法包括软件测试、静态分析和形式化验证.软件测试和静态分析只能发现软件中存在的错误而无法验证程序功能的正确性.在静态分析中,指针分析是一个不可判定问题[1,2].形式化验证可以验证程序的正确性,主要包括两种方法:模型检测[3]和演绎推理[4].模型检测的应用被限制在状态空间有穷的系统.在演绎推理中,通常用断言表示程序中每条语句处的状态,由断言根据Hoare逻辑[5]、分离逻辑[6]等规则推理得到验证条件交由Z3[7]等自动定理证明器进行证明.演绎推理的优点是无误报,不要求状态空间有穷,并且可以模块化地进行验证.
C语言采用相对底层的内存模型,指针可以指向内存的任意位置,并可以在不同类型之间自由转换.C语言提供多种内存操作,如多级指针间接访问、任意指针算术、数组和结构体数据类型.因此C语言程序可能发生空指针、 野指针、数组越界等多种内存安全问题.上述原因使得在验证工具内建立C的内存模型较为困难.
我们之前实现了一个PointerC[8]语言程序验证工具,该工具基于形状图逻辑[9]对堆指针程序进行验证.目前我们正在研发一个基于Hoare逻辑和形状图逻辑的安全C语言(以下简称为Safe-C)程序验证工具. Safe-C是C99的一个子集,是在C99的基础上所设计的面向验证的C语言.
Hoare逻辑的核心是Hoare三元组,其形式如下:
{P} C {Q}
(1)
这里的P和Q是断言而C是命令.P称为前断言,Q称为后断言.断言中不同的左值表达式代表不同的存储对象,而C的编程语言的语义允许存在别名,即不同的左值表达式可以代表同一个存储对象.在使用Hoare逻辑的赋值规则前必须消除断言中的别名,否则会得到错误的推理结果.动态检测[10-11]可以通过编译和运行程序来获取内存对象的运行时地址,但在程序验证中无法做到.如何在验证工具中消除断言中的别名是一个技术挑战.
本文的贡献在于:第一,根据C语言的语义提出了一种栈区内存模型,使程序验证工具能够精确地跟踪栈区的多种类型的表达式,包括取地址、多级解引用、指针关系运算、结构体和数组等;第二,基于上述内存模型,本文提出了一种判断别名的算法,使得验证条件生成器在应用Hoare赋值规则前准确完成别名替换.
2 Safe-C验证工具
2.1 安全C语言与程序标注
Safe-C在不牺牲C语言灵活性的前提下,对C语言的各种类型增加一些编程约束,使得程序对这些类型的变量的操作表现得较为规矩.约束大都针对指针类型,要点如下:
1) 把堆分配类型及其指针和非堆分配类型及其指针进行区分,尽量不出现可同为两者的类型和指针.
2) 简化堆和其他数据区的关系,尽量避免出现从堆指向其他数据区的指针,不滥用从其他数据区指向堆的指针.
3) 禁止对不是指在数组区间(包括动态分配的某类型的若干个元素构成的区间)的指针使用指针算术运算.
被验证的程序由安全C语言源代码和写在注释中的程序标注两部分组成.程序标注是对于程序行为的形式化说明,可用来生成验证条件.程序标注需要符合形式化的语法和语义规范,为此我们参考ACSL[12]设计了面向程序验证的Safe-C语言的程序标注规范SCSL.
2.2 验证工具的主要模块与验证流程
图1显示了验证工具的主要模块和验证流程见图1:
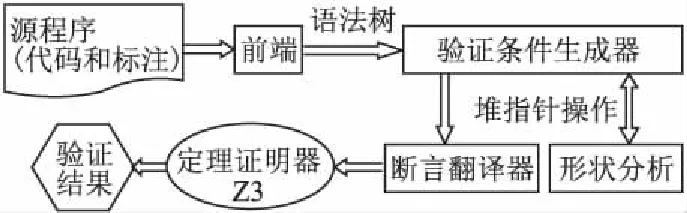
图1 验证工具的主要模块和验证流程 Fig.1 Modules and procedures of the Safe-C verifier
1) 前端检查源程序中的代码和标注是否符合Safe-C的要求,同时收集一些必要的全局信息,然后生成语法树.
2) 验证条件生成器遍历语法树,首先根据程序入口处的标注产生入口处的断言,随后根据每条语句的演算规则进行演算,产生当前程序点的断言.遇到有程序标注的地方,会产生验证条件验证当前程序点断言是否满足程序标注.另外在每条语句的演算规则内,验证工具还会适时检查程序是否可能出现内存泄漏、空指针解引用、越界访问、运算溢出等C语言程序中常见错误.对于栈区变量与栈区指针的操作在验证条件生成器中处理,而将堆指针相关的操作交由形状分析模块处理,并将验证结果返回给验证条件生成器模块.
3) 验证条件生成器模块产生的验证条件由断言翻译器模块翻译为定理证明器Z3可以识别的smt2文件,最终交由Z3验证得到验证结果. ·
3 栈区内存模型
3.1 Hoare逻辑赋值规则与别名
在使用Hoare逻辑对高级语言程序进行演绎推理的过程中,每当使用赋值规则
{Q[E/x]}x=E{Q}
(2)
时必须保证后断言Q和赋值语句x=E(E是表达式)中没有潜在的别名,否则Q[E/x]是最弱前断言的结论不可靠.例如,对于赋值语句p→data=3和后断言p→data+q→data== 6使用Hoare逻辑的赋值公理,可得到该语句前断言q→data== 3;但该语句的最弱前断言是p== q‖p!= q&&q→data== 3.在此用赋值规则未能得到最弱前断言的原因是,访问路径p→data和q→data被认为是代表不同的程序对象,而实际上若p等于q时,访问路径p→data和q→data互为别名,它们代表同一个程序对象.当对p→data赋值时,q→data的值也被修改了.由此可见,程序中出现别名增加了程序验证的难度,跟踪每个程序点的别名信息对基于演绎推理的程序验证是重要的.考虑如下的C语言代码:
int a[3]={1,2,3};
int *p=a;
a[2]=4;
*(p+2)=5;
在这段代码中,指针p指向了数组a的首地址.指针导致了别名的出现,也就是两个左值表达式可以代表同一个内存地址.这里*(p+2)与a[2]互为别名.
3.2 栈区内存模型
堆分配和堆指针的处理采用形状图逻辑处理[9],本文仅讨论栈区分配的变量与指针.在编程语言的语义中,通常用环境和状态来表示变量名称到值的映射.环境表示将名字映射到存储单元的函数,
Env=Var→loc
(3)
而状态表示将存储单元映射到它所保存值的函数.
Store=Loc→Value
(4)
C语言标准 将表达式分为左值表达式和右值表达式.代表内存对象的表达式是左值表达式,其余的是右值表达式.左值相同的表达式在内存中的存储位置相同,即互为别名.因此消除别名的关键是精确记录内存对象的左值,从而判断表达式的左值是否相同.
根据以上思路,我们对式(3)和式(4)分别进行扩展,用如下两个映射定义Safe-C的栈区内存模型.第一个映射
Env=LExpr→LValue
(5)
表示将左值表达式映射到左值的函数,LExpr表示代表内存对象的左值表达式的集合,LValue表示左值的集合.在验证工具内,左值不仅表示抽象的内存地址,也包含了左值表达式的类型(type)和长度(length)信息.第二个映射
Store=LValue→RValue
(6)
表示左值所代表的存储单元到右值的映射,RValue表示右值的集合.这里的右值和C语言中的右值含义相同,在验证工具内用断言表示.
我们用一张表来表示内存模型所表示的映射关系,称作内存表.在验证工具内部,非指针的右值和指针的右值通常分开存放,这样方便将栈区变量的赋值与栈区指针的关系运算分开处理.非指针的断言用符号断言Q来表示,内存表用M来表示.我们在具有左值的表达式名字前面加上@作为对应表达式的左值的名称.非数组类型左值@x的长度默认为1,表示在内存中占据1个x类型的长度.对于不同的左值表达式,其左值和右值有不同的产生规则,以下分别举例说明:
1) 对于非指针类型的变量x,为其产生左值@x,@x保存有x的类型信息和长度(默认是1),x的右值保存在符号断言Q中,不出现在内存表M中.
2) 如果是一个指针类型变量p,则除了为其产生其左值@p外,还会根据其指向产生不同的右值.如果p是空指针或野指针,则其右值为 ull.如果p指向某个存储对象,则指针的右值为存储对象的左值,用函数形式的三元属性来表示.三元属性的定义是
pointer(name,length,offset)
(7)
在前期工作[13]基础上进行改进,name不再是程序变量的名字或者是任意的虚拟名字,而是指针所指向变量的左值,length表示该左值的长度,offset表示指针的偏移.这样可以更清晰地记录指针的指向信息和层级关系,从而支持多级指针间接访问.另外,在对指针的处理中有两种特殊的情况:
1) 将数组名看成指向自身所在内存区间首地址的指针.数组名本身并不是左值,不能出现在赋值表达式的左边.但可以被用于取地址操作符&,所以这里将其视作特殊的左值表达式,产生的左值表示数组所占的内存区间,其长度是数组长度.另外数组名可以像指针一样出现在指针关系运算中,为处理方便,设置数组名右值为三元属性.其三元属性所对应的name是其自身对应的左值,length为数组长度,由于数组名代表数据块首地址,故offset固定为0.
2) 为函数入口处的形参指针额外产生一个特殊的左值表示其指向的存储单元.这是因为验证工具以函数为模块进行验证,实参并不出现在函数内,实参所指向的存储单元也不在本函数栈内.即需要为位于函数栈外的形参所指向的存储单元产生一个特殊的左值,以避免信息的丢失.在本文中,在@和形参名之间加上符号#来表示形参指针所指向的存储单元.特别的,如果有多个形参指针指向相同的存储单元,需要在函数的前条件中加以说明,以确保相同的存储单元只产生一个左值.
3) 对于结构体变量赋值需要将结构体展开,看作对其每一个域的赋值.因此除了为结构体变量产生左值外,还会根据每一个域的类型,递归地为其每一个域产生左值和右值.
4) 对于数组下标表达式如a[i]产生数组名a的左值和右值信息,但并不会为a中的每一个元素产生左值和右值.这里我们采用一种延迟插入的方式,仅当a中的某一元素出现在断言中,我们才为其产生左值.这样可以减少验证工具内插入和查询的开销.
5) 对于解引用表达式,可以将其转化为上述的某一种左值表达式,故不再单独讨论.
考虑如下的代码片段:
int x=5;
int a[100];
int* p=a;
int* q;
struct {
int d
} s;
则为其产生的符号断言Q和内存表M如下:
Q:x== 5
M:

LExprLValueRValuex@xa@apointer(@a,100,0)p@ppointer(@a,100,0)q@q ulls@s s.d@s.d
3.3 验证点断言与内存表的构造
验证点是程序代码中函数入口处、循环入口处以及其他有程序标注的地方.当验证工具演算到验证点时,需要验证当前程序断言是否满足验证点的标注,然后根据标注产生验证点的内存表和程序当前点的新断言.函数入口、循环入口与其他验证点略有区别.
3.3.1 函数入口处内存状态的构造
函数入口处的协议称为requires断言,其经过范式化后可以表示为:
R1‖R2‖…‖Rn
(8)
其中每个Ri(1≤i≤n)称为析取子式,每一个析取子式对应于演算过程中的一个分支,分支的程序状态构造如下:
1) 将所有全局变量,函数形参变量依次填入内存表中,并初始化所有变量的左值信息(包括变量类型,所在数据块大小等).
2) 非指针变量的右值信息不需要填入表中,仍然保存在断言中.需要修改时,直接遍历断言语法树修改即可.对于栈指针变量,需要找出程序标注中与其相关的断言,产生对应的三元属性,并填入内存表中.
我们将每一个分支的符号断言称作Qi,对应的内存表称作Mi,则入口处的程序状态可以用如下形式表示:
(Q1&&M1)‖(Q2&&M2)‖…‖(Qn&&Mn)
(9)
3.3.2 循环入口处内存状态的构造
在进入循环之前,首先要验证当前断言是否满足循环不变式.即对断言的每一个分支,产生如下的验证条件:
Qi&&GetAssert(Mi)== >Ii‖I2‖…‖In
(10)
其中GetAssert()函数获取表中的栈指针相关断言,I1‖I2‖…‖In是范式化后的循环不变式.
根据循环不变式生成循环入口处断言和内存表的方法与函数入口处的方法类似.不同的是在循环入口处需要将局部变量也考虑进去.其他验证点的构造和循环入口处类似,不同的是循环出口处需要再验证一次是否满足循环不变式,而其他验证点通常只需要验证一次.
3.4 栈区赋值语句规则
3.4.1 取地址和解引用操作
为了支持多级指针操作,需要根据内存模型和C的语义定义取地址和解引用的操作规则,规则定义如下:

LValueRValue&exprN/ALValue(expr)*exprRValue(expr)Store(RValue(expr))
&expr是一个右值表达式,不可作为左值表达式,计算该表达式的值得到的是expr的地址(左值).
*expr既可以是左值表达式,也可以是右值表达式,作为左值时其含义是获取expr指针所指向的存储对象,作为右值时其含义是获取指针所指向的存储对象所保存的值.在计算*expr表达式的值时,首先需要查询判断expr指针是否是空指针或野指针,若是则报错.其次需要判断访问是否越界.例如对于赋值语句int i=*(q+j); 而言,指针q的右值为pointer(@a,100,k),表示q指向数组a的第k个位置上.则需要产生如下验证条件:
Q&&GetAssert(M)== >0≤(k+j)<100
如果上述蕴含式成立,则表示访问合法;如果不成立,则表示访问越界.
3.4.2 栈区变量赋值
对栈区变量赋值,首先需要消除别名.需要消除别名的地方有三处,分别是保存符号断言的Qi、内存表中Mi中的length字段和offset字段以及赋值表达式的右子式.遍历上述三处的每一个表达式,根据本文第4节提出的判断别名的算法,将与被赋值表达式互为别名的表达式替换为被赋值表达式.随后对赋值语句使用Hoare逻辑赋值规则在每一个分支上进行演算,演算规则为:
{Qi&&Mi}
x=E
{(Qi′&&Mi′)[x′/x]&&x== E′[x′/x]}
(11)
其中,Qi′、Mi′和E′分别表示消除别名后的符号断言、内存表和赋值表达式的右子式.x′是和x同类型的虚拟变量, [x′/x]表示将x替换为x′.如果被赋值的表达式是结构体变量,那么需要递归的对每一个域做别名替换操作.
3.4.3 指针关系运算
指针关系运算可以统一表示为以下形式:
p=q+e;
其中p和q是有左值的指针类型访问路径,e是整型表达式,"+"泛指加减运算符.把p=q看成p=q+0的特例.
在演算过程中,我们将指针的状态保存在内存表M中,符号断言中Q不出现指针相关的断言,从而简化指针赋值的处理.只需要将右表达式中的栈指针p的三元属性的前两个属性复制并替换左表达式q中对应的属性,将右表达式指针指向的偏移与表达式e的计算结果填入左边指针的偏移中.推理规则是:
{Mi={…p== pointer(@v1,length1,offset1),
q== pointer(@v2,length2,offset2)…}}
p=q+e
{Mi′={…p== pointer(@v2,length2,offset2+e),
q== pointer(@v2,length2,offset2)…}}
(12)
其中Mi和Mi′表示赋值前后的内存表状态,@v1和@v2分别表示语句执行前p和q指向的内存对象的左值.
4 判断别名的算法
3.1节指出在使用Hoare逻辑的赋值规则前必须消除断言中潜在的别名,否则可能导致推理的结果不正确.要正确的消除别名,首先要判断两个表达式是否为别名,即判断两个表达式的左值是否相同.但是内存表中并非存有所有的左值表达式的左值,所以我们基于3.2 节的栈区内存模型提出一种判断两个左值表达式是否别名的算法,如图2 所示.

图2 判断别名的算法Fig.2 Algorithm for judging aliases
1) 复杂访问路径是含多个域访问符的表达式,如p→a.b.其中域访问符包括.和→两种.但其实p→a是(*p).a的语法美化,所以可以将→表示成.来统一处理.若两个复杂访问路径的最后一个域相同,则判断两个访问路径的前缀是否别名.如p→a.b和q.c.b这两个表达式的最后一个域皆为b,则判断(*p).a和q.c的左值是否相同,若不相同则两个表达式不为别名.
2) 如果两个表达式是分别是解引用和数组表达式,可以将二者统一为数组表达式,通过比较数组名、数组表达式的维数以及每一维的索引来判断两个表达式是否别名.假设p和q是栈指针,a是数组,需要比较两个表达式*(p+3)与q[4]是否别名.内存表中有断言p== pointer(@a,10,1)、q== pointer(@a,10,0)和a== pointer(@a,10,0),此时可以将两个表达式统一成数组表达式均为a[4].通过比较数组名称以及第一维的索引,可以判断出两个表达式互为别名.
3) 如果两个表达式都是简单变量,则直接比较二者左值是否相等.简单变量在此处包括全局变量、函数形参变量、局部变量、以及结构体变量的域等.在每个程序点处构造内存模型时已经将其加入内存表,故可以直接通过查表判断二者左值是否相同.
4) 如果两个表达式是其他类型,则不会互为别名.
5 验证实例
我们以一个含有结构体和二重指针等复杂数据结构的函数为例介绍本文提出的栈区内存模型.该函数的功能是查找一个数组中的最大值和最小值并返回,代码显示在图3.我们将重点放在介绍内存表的创建、赋值语句的规则以及如何利用内存表来实现多级指针的访问和别名消除.

图3 包含二重指针和结构体的函数Fig.3 Function with double pointer and structure
在第8行函数入口处,根据函数前条件构造函数入口处的断言Q和内存表M.本例中函数前条件(requires)中的标注为size > 0 && length(a) == size.根据3.3.1小节中的规则,得到函数入口处断言和内存表:
Q:size>0
M:
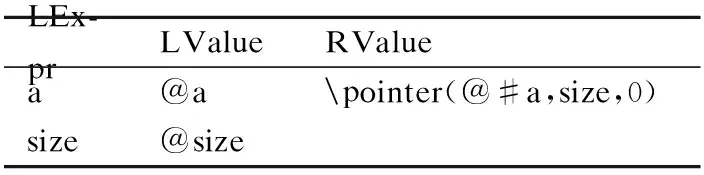
LEx-prLValueRValuea@apointer(@#a,size,0)size@size
第9行处理变量s的声明,对其左值进行初始化.第10行首先声明一个指向结构体的指针p,并用s的地址来初始化p.第11行声明一个二重指针q,并对数组名a取地址来初始化q.带有初始化的声明语句可以首先处理声明,再按赋值语句规则处理.对于取地址表达式,利用3.4节提出的规则获得表达式左值信息并产生三元属性作为被赋值指针的右值.
第12行和13行是两条栈区变量的赋值语句,第14行是带有初始化的声明语句.对于被赋值的表达式,如果没有出现在内存表中且内存表中有与之别名的表达式,则产生的符号断言用该别名表达式;如果没有出现在内存表且没有与之别名的表达式,则加入内存表中.
上述语句执行结束后,得到的断言和内存表如下:
Q: size>0&&s.min== (*q)[0] &&s.max== (*q)[0]&&i== 0
M:

LExprLValueRValuea@apointer(@#a,size,0)size@sizes@ss.max@s.maxs.min@s.minp@ppointer(@s,1,0)q@qpointer(@a,1,0)i@i
对应的函数的栈区状态可以如图4所示.

图4 栈区状态Fig.4 State of the stack area
验证到第17行循环入口处,我们将栈区的所有非指针变量和指针变量的断言合并,并将断言中的解引用表达式替换成数组表达式,验证是否满足循环不变式.在循环入口合并后的断言如下:
Q:size>0 &&s.min== a[0] &&s.max== a[0] && i== 0 && a== pointer(@#a,size,0) && p== pointer(@s,1,0) && q== pointer(@a,1,0)
当验证完成后,依据循环不变式产生循环后的断言和内存表,此时的断言已经存在分支.在此我们以第一个分支为例继续向下演算,这里不再展示此处的断言和内存表.
第18行是一个条件语句,这里将产生分支.符合条件语句的分支将会在断言中加入s.max < (*q)[i]这个断言.在第19行赋值语句前,首先找出断言中与被赋值表达式p→max别名的表达式.利用第4节提出的判断别名算法可以判断出s.max和p→max是别名,产生虚拟变量@v1替换断言中所有的s.max.因为s.max与p→max左值相同,且s.max已经出现在内存表中(内存表中不会出现两个互为别名的左值表达式),故用s.max替换赋值语句中的p→max.随后执行赋值语句.执行完后的本分支的符号断言和内存表为:
Q: size >0 && i M: LExprLValueRValuea@apointer(@#a,size,0)size@sizes@ss.max@s.maxs.min@s.minp@ppointer(@s,1,0)q@qpointer(@a,1,0)i@i 第20行的条件语句会再产生两个分支.执行完第22行的赋值语句后,验证各个分支的断言是否满足循环不变式.然后以循环不变式作为程序断言继续演算.第24行是return语句,验证函数的返回值是否满足函数的后条件. 因为验证C语言相对困难,所以国际上成熟的的C语言验证工具也相对较少.在学术界,相对有影响力的研究成果有VCC[14]、Toccata[15]和VeriFast[16]等.VCC专注于发现C并发程序的中的问题,而Toccata则将重点放在了精度验证上,二者对C的数据类型的支持不够完善.VeriFast相对成熟,该工具基于分离逻辑,支持丰富的断言数据类型和用户自定义谓词.而我们的验证工具基于Hoare逻辑和形状图逻辑,理论路线与之不同.有些比较有影响的验证工具如Spec#[17]只支持验证C#等没有指针的面向对象语言. 如何消除C语言中的别名以及支持C语言中种类众多的表达式是验证C程序的困难之一.文献[13]提出了一种三元属性的栈指针表示方法,支持带有一级栈指针程序的验证,但其对多级指针间接访问以及复杂数据结构没有支持.本文与[13]的区别在于提出了一种适用于C程序验证工具的栈区内存模型,使程序验证工具能够精确地跟踪栈区多种类型的表达式,包括取地址、多级解引用、指针关系运算、结构体和数组等.另外本文还给出了基于该内存模型的别名判断算法,使得验证条件生成器在应用Hoare赋值公理前准确完成别名替换. 目前该内存模型已经在Safe-C验证工具内实现.限于篇幅,本文只介绍了一个验证实例.Safe-C验证工具已经验证通过了一维数组、二维数组、二重指针、易变数据结构、栈指针、字符串等77个经典C程序,其中包括快速排序、冒泡排序、字符串匹配等经典算法.这些程序已经上传至以下网址:https:.github.com/huanGG/Safe-C.6 相关工作对比
7 结束语
猜你喜欢
初中生世界(2020年47期)2021-01-07
软件学报(2020年6期)2020-09-23
初中生世界·九年级(2020年12期)2020-03-10
现代计算机(2019年6期)2019-04-08
广东第二课堂·小学(2017年9期)2017-09-28
中学生数理化·高一版(2017年1期)2017-04-25
中学生理科应试(2016年7期)2016-05-14
理科考试研究·高中(2016年9期)2016-05-14
软件工程(2014年3期)2014-03-15
数学教学(2013年9期)2013-12-12
