
基于逻辑斯蒂回归的恶意请求分类识别模型
2019-02-25 13:21陈春玲
计算机技术与发展 2019年2期
陈春玲,吴 凡,余 瀚
(南京邮电大学 计算机学院,江苏 南京 210003)
0 引 言
随着Web2.0的发展,Web应用的数量和覆盖面得到了极大的提升,然而Web安全性问题却越来越突出。根据Garter公司的报告显示,目前有75%的网络安全漏洞都是针对Web应用层的。目前常见的Web应用安全问题有跨站脚本攻击(XSS)、SQL注入、远程命令执行、目录遍历、PHP代码注入等等[1]。由于大部分Web应用攻击都选择避开传统防火墙,转而伪装成正常请求从OSI应用层[2-3]入侵,因此识别策略必须要理解请求内容,从中识别出恶意的请求并拒绝执行。目前对文本进行建模分类的常用方法是机器学习。Justin Ma等[4]提出了一种通过对URL的分类检测来识别恶意站点的方案,使用静态方法基于主机来发现恶意站点,但是一旦一些知名站点被挂马,这种方
法就无法检测出来。叶飞等[5]提出了一种基于支持向量机(SVM)分类算法的黑盒检测方法,能直接对URL特征进行检测,而无需了解请求的源代码,但是分类准确率还有待提升。马艳发[6]提出了一种与自学习ML模型相结合的新型入侵检测算法,能对PHP变异Webshell的代码进行分析,追踪程序执行中函数的执行情况,从而达到检测的目的。
现有文献都是基于对请求的内容进行分析建模,设计出对应的分类识别模型。但是存在适用范围小、分类准确率不高、训练时间长等问题。因此,文中提出一种基于逻辑斯蒂回归[7-8]的有监督学习模型,通过Python编程实现,在Secrepo安全数据样本库和GitHub代码仓库的大量真实样本上进行训练,找到似然估计最高的参数模型作为最终分类模型,并通过在测试集上进行实验来验证其分类准确率。
1 基础知识
1.1 逻辑斯蒂回归模型
设X是连续随机变量,X服从逻辑斯蒂分布是指X具有下列的分布函数和密度函数:
(1)
(2)
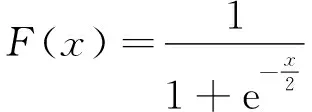
逻辑斯蒂回归是一种二分类模型,由条件概率分布P(Y|X)表示,形式就是参数化的逻辑斯蒂分布。其中自变量X取值为实数,因变量Y为0或者1。二项逻辑斯蒂回归的条件概率公式为:
(3)
(4)
ω即为要求解的模型参数,通常采用最大似然估计。即找到一组参数,使得在这组参数下数据的似然度达到最大。
设:P(Y=1|x)=π(x),P(Y=0|x)=1-π(x),则似然函数为:
L(ω)=∏[π(xi)]yi[1-π(xi)](1-yi)
(5)
式5的对数似然函数为:
(6)
对数似然损失在单个数据点上的定义为:
-ylnp(y|x)-(1-y)ln[1-p(y|x)]=
-[yilnπ(xi)+(1-yi)ln(1-π(xi))]
(7)
则整个数据集上的平均对数似然损失为:
(8)
因此求最小化对数似然损失函数和最大化对数似然函数是等价的。文中通过梯度下降法求解ω的估计值。梯度下降算法迭代步骤为:
(1)取初始值ω0∈Rn,令k=0。
(2)计算J(ωk)。
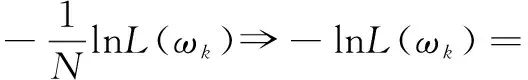
∑[yi(ωk·xi)-ln(1+eωk·xi)]
(3)计算梯度gk=g(ωk)=
若‖gk‖<ε,ω*=ωk,转步骤5。
否则,令pk=-g(ωk),求λk,使得J(ωk+λkpk)=min[J(ωk+λkpk)]。
(4)ωk+1=ωk+λkpk,计算J(ωk+1)。当‖J(ωk+1)-J(ωk)‖<ω或‖ωk+1-ωk‖<ω,ω*=ωk+1,转步骤5,否则,令k=k+1,转步骤3。
(5)算法结束,输出ω*。
正则化:当模型的参数过多时,很容易遇到过拟合的问题[9]。而正则化是结构风险最小化的一种实现方式[10-11],通过在经验风险上加一个正则化项,来惩罚过大的参数以防止过拟合。即:
J(ω)=>J(ω)+λ‖ω‖p
(9)
p=1或者p=2,表示L1范数或L2范数。L1范数是指向量中各个元素的绝对值之和;L2范数是指向量各元素的平方和的平方根。式9中λ的作用为λ权衡拟合能力和泛化能力对整个模型的影响,λ越大,对参数值惩罚越大,泛化能力越好[12]。文中使用L2范数对模型参数进行正则化。
1.2 TF-IDF方法
TF-IDF[13-14](term frequency-inverse document frequency)是一种用于资讯检索与资讯探勘的加权技术,是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数呈正比增加,但同时会随着它在语料库中出现的频率呈反比下降。
词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。对于在特定文档j中的词汇i来说,它出现的频率可表示为:
(10)
其中,ni,j为词i在文档j中的出现次数,分母表示在文档j中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语的文件数目,再将得到的商取对数得到:
(11)
其中,|D|是语料库中的文件总数;|{j:ti∈dj}|是包含词语ti的文件数目(即ni,j≠0的文件数目)。如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用1+|{j:ti∈dj}|,然后计算出单词i在文件j中的TF-IDF值:
fidfi,j=tfi,j*idfi
(12)
2 逻辑斯蒂回归分类模型的构造
逻辑斯蒂回归分类模型通过构造一个二分类逻辑斯蒂回归方程,对未知的请求进行分类。回归方程构造过程分为取样、特征选取、参数拟合、测试。首先训练样本的丰富性和可靠性是有监督学习中非常重要的基础,为了保证实验结果的可靠性,使构造的逻辑斯蒂回归方程准确率更高,选取了来自Secrepo安全数据样本库和GitHub代码仓库中的数据集合,且采集使用的样本量较大,以便覆盖多种恶意请求。然后基于给定的样本数据通过合适的分词策略后得到相应的特征矩阵,分词策略的选择应当充分考虑分类准确率和训练时消耗的时间,选取最合适的方案。最后以最大似然估计为约束拟合出分类准确率最高的回归方程系数组合,将其带入原方程,作为最终的分类模型对测试数据进行分类,见图1。
数据特征的选取方式对于逻辑斯蒂回归模型是至关重要的。文中采用了TF-IDF方法构造样本数据的特征向量。TF-IDF是一种用来衡量一个关键词对一个词库中一份文档的重要程度的统计方法,关键词的重要程度随着它在整个词库中出现的频率呈反比下降。TF-IDF的优势在于可以过滤掉一些对相似性检测毫无用处的词,即所谓的停用词。因为在式11中,一旦词库中的文档总数|D|与包含关键词ti的文档数相等,就会导致idf为0,这表明该类关键词与文档主题几乎没有关系。去掉这些干扰词后可以突出重要的关键词,以提高逻辑斯蒂分类回归模型的准确率。但是由于请求字符串文本具有长度极短、单词字符间关联度较低、语义不明确等特点,常规分词处理后的特征向量字典将会非常庞大,而单条请求的有效特征又非常少,结果将导致特征矩阵非常稀疏,不利于之后特征权重向量的构造。
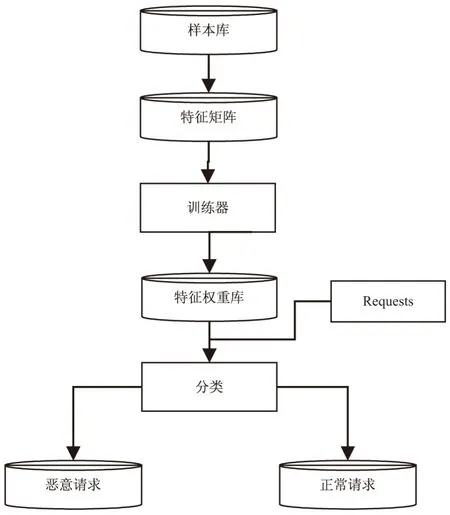
图1 逻辑斯蒂回归分类模型
为了减少请求文本的这种特性对构造最终模型可能产生的影响,在构造特征字典时引入了非重复的N-Gram[15-16]分词模型,表示为:|GN(s)|+|GN(t)|-2*|GN(s)∩GN(t)|。其中,|GN(s)|是字符串s的N-Gram集合。通过非重复的N-Gram分词,相邻的词会组合成新的分词,成为特征词典的一部分,既能隐性地增加文本长度,提高有效特征比例,又能将请求中某些暗含的固定字词联系发掘出来,成为潜在的重要特征。一般N-Gram分词中N取2或3,数值太高将导致衍生词过多,同样会导致特征矩阵系数,降低分类准确率。
特征矩阵构造完成后,将其带入二分类逻辑斯蒂回归模型中,求解模型的损失函数,通过梯度下降法递归地求解出最优拟合参数ω,将ω带入之前的模型中,得到该样本下的最优逻辑斯蒂回归分类模型。对于待分类的样本,只需要先通过特征字典获取样本对应的特征列表x,然后计算g(x)=simgod(∑ω·x)-0.5的结果即可,若g(x)≥0,则样本为正例,否则为负例。文中所指的正例即判断为恶意请求的样本。
3 实验结果与分析
3.1 特征选取
使用Python3.6语言编程环境,选取Secrepo安全数据样本库和GitHub代码仓库中的数据进行实验。选取的数据集包含了8万条正常请求以及4万条恶意请求。恶意请求包括XSS、SQL注入、远程命令执行、目录遍历、PHP代码注入等多种类型,比较全面地覆盖了常见的恶意请求类型。
首先对采集到的样本数据进行预处理。文中使用的是Python的Scikit-Learn包中的TfidfVectorizer类,该类实现了基于TF-IDF的特征词典的构造和特征向量的计算。通过设定该方法的ngram_range参数以及analyzer参数为char,可实现在构造特征字典时引入非重复的N-gram分词且分词基于字母而非单词。最终得到的特征字典大小为73 405。以/rss.php?page[path]=XXpathXX?&cmd=ls为例,该文本在特征矩阵中非零参数有85个,这意味着TF-IDF分词算法将该词条分割成了85个非重复特征单元,并计算了每个特征对于本词条在全部样本中的影响力。由于请求字段长度短、非语义化等特点,如果采用基于单词的分词方法进行特征选取和TF-IDF的计算,容易出现单个样本特征稀少而特征词典过于庞大,导致特征矩阵过于稀疏的情况,不利于提高模型分类的准确性。在以单词为单位的特征字典中,案例文本仅能获得17个非零参数,而特征字典大小达到了惊人的260 095。
3.2 实验结果
将样本按指定的分词策略进行分词后得到的特征矩阵按4∶1分成两部分,分别为训练集A和测试集B,其中A作为训练样本带入逻辑斯蒂回归方程进行训练,将训练完成后得到的最终模型用于测试集B,检验该模型的分类准确性。通常评估模型好坏的指标为准确率(accuracy)、精确率(precision)、召回率(recall)和F1-Measure。假设TP为正类中判定为正类的数量,FP为负类中判定为正类的数量,FN为正类中判定为负类的数量,TN为负类中判定为负类的数量,则可以定义为准确率=(TP+TN)/总样本数,精确率=TP/(TP+FP),召回率= TP/(TP+FN),F1=2TP/(2TP+FP+FN)。
测试结果如表1所示,其中前四条数据是不同参数的TF-IDF分词方法通过逻辑斯蒂回归得到的结果,第五条数据为在分词标准char、N-Gram系数为3的情况下通过SVM训练得到的结果。
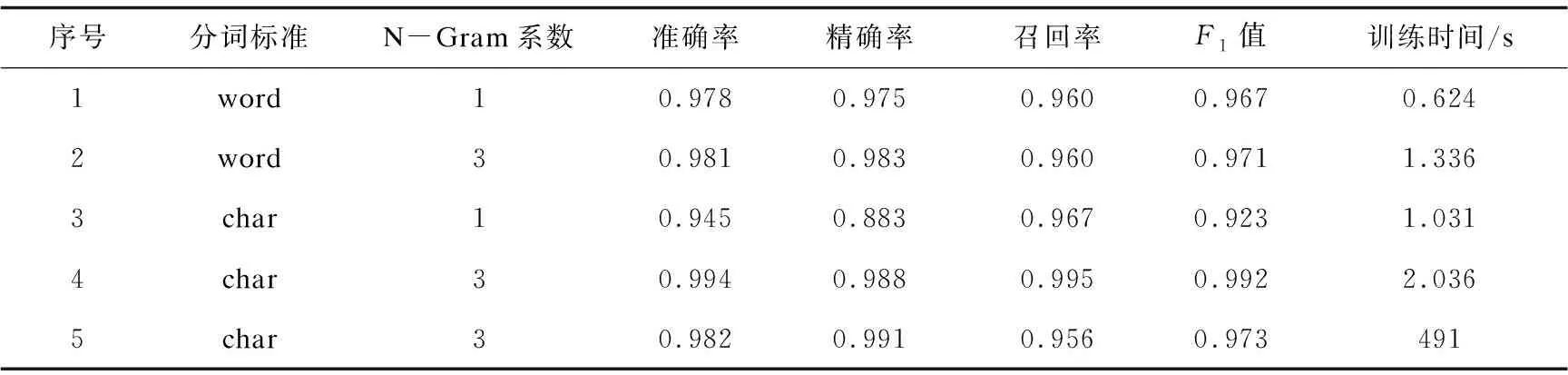
表1 不同分词对应模型的分类结果
图2为不同分词情况下模型的分类结果的对比。
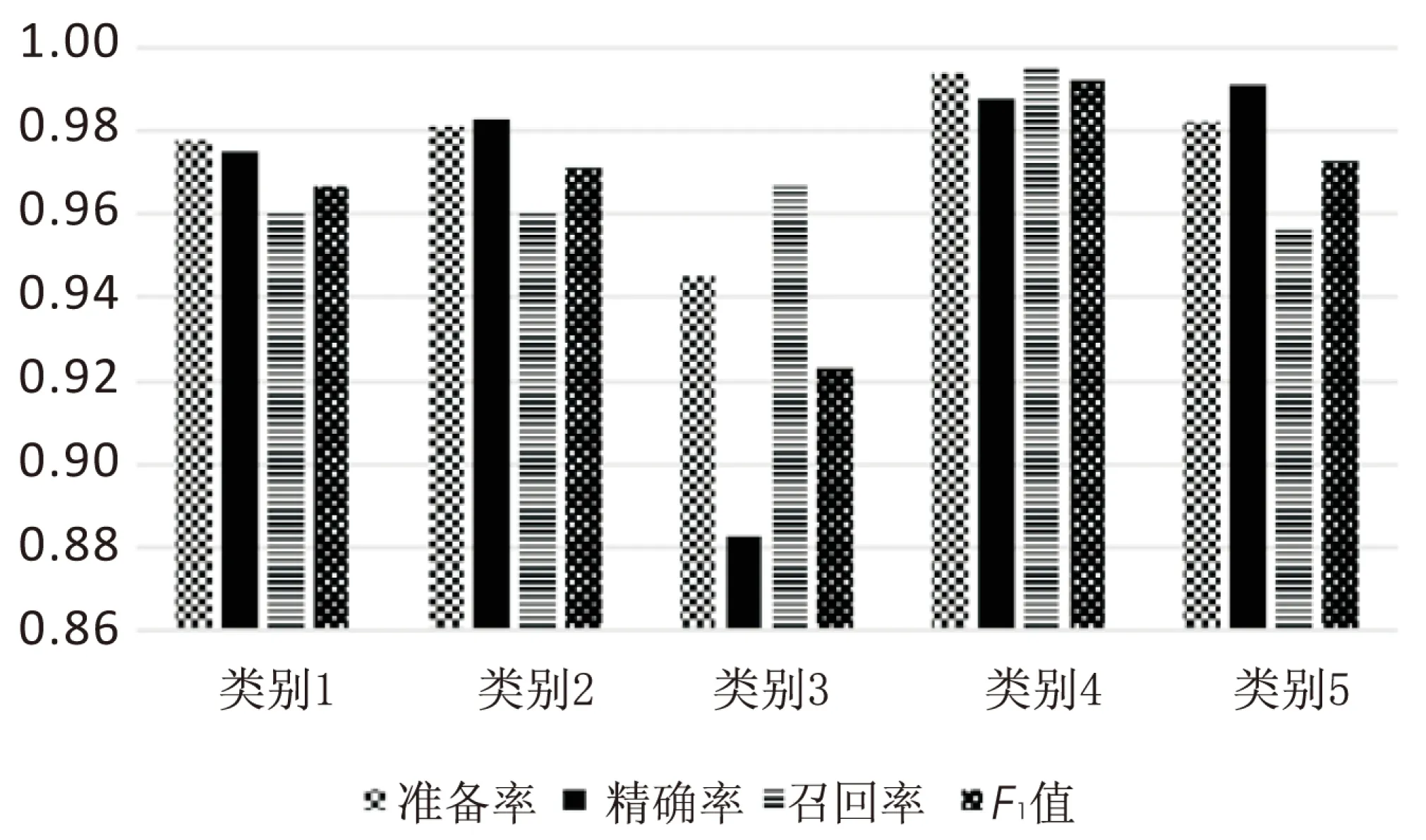
图2 不同分词情况下模型的分类结果对比
3.3 结果分析
由实验结果可知,同为逻辑斯蒂回归模型的四种情况中,类别四分词策略取得了最好的效果,四种指标都超过了99%,其中召回率的数据超出其他策略很多,而分类模型中召回率越高,正类被漏判的概率就越低,这也意味着对正常用户请求的误伤概率降到了最低。既保障了最高的分类检出率,也不会过于影响用户体验。对比SVM的训练模型指标,类别四也有一些优势。
而在训练用时方面,由于使用字母和较高的N-Gram系数分词策略,使得每条样本的非零特征增多,在训练时会增加一些时间。从实验结果来看,增加的时间在可忍受范围内,但是提高了模型的分类准确率,因此是可取的。
从表1中能发现SVM模型的训练用时相对于逻辑斯蒂回归模型多了很多,这可能是由于SVM会将全部特征进行空间映射,从而找出一个线性可分的超平面作为分类的标准,即所谓的支持向量,然而文中特征选取的策略会导致特征空间非常庞大,导致SVM模型的训练时间很长,而逻辑斯蒂回归模型在这种情况下效率仍很高。总之,实验结果表明,类别四的分词策略配合逻辑斯蒂回归模型对于文中的请求分类具有最好的结果。
4 结束语
提出的二分类逻辑斯蒂回归分类模型通过使用基于TF-IDF的非重复N-Gram分词,有效避免了对请求文本进行分词时遇到的诸多不利因素,使训练出的模型能有效分类新遇到的请求,识别其中的恶意请求,从而弥补了传统安全防御模式在应用层上的不足,提高了服务器端的安全水平。该模型以样本的最大似然估计为训练目标,使用L2范数达到最大泛化效果,避免模型出现过拟合现象。在从Secrepo安全数据样本库和GitHub代码仓库采集的数据集下进行实验,结果表明该分类模型的分类准确率、精确率、召回率和F1值都较高,且训练时间开销不大,可在极低的误判下有效识别出恶意请求。但是该模型基于有监督学习,面对形式新颖、变化较大的恶意请求攻击模式可能无法做到有效识别,因此还需要对机器学习算法、恶意请求形式进行更深入的研究。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
校园英语·月末(2021年13期)2021-03-15
健康体检与管理(2021年10期)2021-01-03
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
