
图正则化稀疏判别非负矩阵分解
2019-02-27 08:56徐慧敏陈秀宏
智能系统学报 2019年6期
徐慧敏,陈秀宏
(江南大学 数字媒体学院,江苏 无锡 214000)
有效的数据低维表示不仅能够发现数据集中的潜在信息,还能去除原始数据中的冗余特征,快速处理高维数据,其中最具代表性的方法包括主成分分析[1]、线性判别分析[2]及非负矩阵分解[3]。然而PCA 和LDA 得到的数据低维表示中可能会包含负值元素,这在实际的应用中缺少合理的解释;而NMF 是一种非负约束下的矩阵分解方法,仅允许原始数据的加法而非减法组合,因此它有利于稀疏的且基于部分的表示,比非稀疏的全局表示更稳健。
经典的NMF 是一种无监督学习算法,不能充分利用原始数据的类别信息。为了提高NMF 的判别能力,Wang 等[4]提出了Fisher-NMF(FNMF),而Zafeiriou 等[5]和Kotsia 等[6]在NMF 的目标函数中增加了散度差项,建立起判别子空间法。由于LDA[2]中Fisher 准则的比值形式很难处理,集成在NMF 模型中会出现“小样本问题”。为此,可考虑最大间距准则(max margin criterion,MMC)[7-8],该准则是以类中心及类散度为度量依据,使得降维后不同类样本之间距离越远而同类样本之间距离越近,在充分使用原始数据类别信息的基础上使得改进后的NMF(如NDMF[9])具有良好的判别性质。
另外,为了揭示和利用数据的内在几何结构,出现了许多基于流形特征的NMF,例如GNMF[10]、GDNMF[11]、LCGNMF[12]和NLMF[13]等,这些方法通过添加图拉普拉斯正则化项达到了提高图像聚类或分类性能的目的。Shang 等[14]同时考虑数据流形和特征流形,提出了图对偶正则化NMF(DNMF)。而Meng 等[15]则在图对偶模型中加入了稀疏性(DSNMF)和正交性的约束[16],有效地简化了高维计算,揭示数据和特征之间的双流形结构。
由于NDMF[9]具有良好的判别性质,而NLMF[13]又利用了数据的图结构来提升其分类性能,故本文将两种方法结合起来提出一种基于图正则化的稀疏判别非负矩阵分解算法(GSDNMFL2,1),在充分利用数据的类别信息的同时,不仅保持了数据样本之间的局部流形结构,而且能提取稀疏的特征,进而提升了其分类性能。若干图像数据集上的实验结果表明,该方法在特征提取与分类性能等方面优于其他各对比算法。
1 相关工作
1.1 非负矩阵分解(NMF)
假设由n个非负样本数据xi∈Rm(i=1,2,···,n)组成的非负数据矩阵X=[x1x2···xn]∈R+m×n,非负矩阵分解[3]的目标是将非负数据矩阵X分解为基矩阵W=[w1w2···wr]∈R+m×r和系数矩阵H=[h1h2···hn]∈R+r×n的乘积,即X≈WH,当r≤min(m,n)时,矩阵X就达到了有效压缩。NMF 可表示为以下最小化问题:

其中 ∥·∥F表示Frobenius 范数。该问题的求解采用以下乘性迭代规则:

1.2 图正则化非负矩阵分解(GNMF)
图正则化非负矩阵分解(graph regularized non-negative matrix factorization,GNMF)[9]考虑了数据样本之间的流形结构,希望数据样本在低维空间中尽可能多地保持其近邻结构,从而寻找数据在低维空间中的紧致嵌入。该问题可用以下优化模型表示:

其中L=D-S为拉普拉斯矩阵,S是权矩阵,D为对角矩阵
求解该问题的乘性迭代规则为

1.3 最大间距准则(MMC)
设有C类样本,最大间距准则的主要思想是寻找一个投影矩阵P使得投影后同类样本之间的散度最小而不同类样本之间的散度最大,达到保持原始数据判别信息的目的,它可表示为以下优化问题:

2 本文算法
根据流形学习的图嵌入思想[17-19],数据在高维空间中的局部邻域关系在低维样本空间中应得到保持,同时也希望原始数据集的散度关系得到保持,因此在NMF 的目标函数中通过添加图正则化约束和判别约束可达到提高算法分类性能的目的。
2.1 构建权重矩阵
基于图嵌入的流形学习法其前提是构建相应的邻接图及权矩阵。传统的流形学习方法通常是利用k-近邻法或ε-邻域法来构建图和权矩阵,但此类方法的性能依赖于参数k或ε。本文利用基于同类样本的稀疏表示方法选择邻域样本,该方法是自适应且与参数无关的,对噪声数据具有鲁棒性。
图1 比较了两种方法选择的邻域样本。其中,k-近邻法选择的邻域样本包含了数据集中不同类别的人脸,人脸角度变化与标注图像一致。相比而言,本文方法所选的样本不仅和标注人脸具有相似角度,而且最接近其正面的人脸图像,且相应的稀疏表示系数越大,越接近标注样本。所以,基于同类样本的稀疏表示方法构建的权重矩阵不仅包含了样本的类别信息,而且还包含了样本间的局部邻域结构,从而具有良好的判别性质。

图1 k-近邻法与稀疏表示法确定的近邻Fig.1 Neighbor samples determined by k-nearest neighbor method and sparse representation
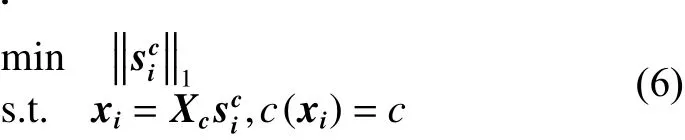
式中:Xc为第c类所有样本组成的矩阵,表示系数向量中的每一个分量描述了与同类的其他相应样本在表示时的贡献大小,从而可以用来表示样本之间的相似性。c(xi) 表示样本的类标签,nc表示第c类样本的数量,且从而,有以下基于稀疏表示的样本权矩阵:

2.2 正则化约束
图正则化是基于邻域保持嵌入的,它将训练样本之间的局部邻域关系通过权矩阵S在由NMF的系数矩阵H的列向量hj所张成的子空间中得到保持,因此得到以下图正则化约束项:

式中:SH为权矩阵;LH=DH-SH为拉普拉斯矩阵;DH为对角矩阵且对角元素为
以NMF 中的基矩阵W为投影矩阵,使得投影后同类样本之间的散度最小而不同类样本之间的散度最大[19],以保留训练样本的判别特征,从而有以下基于MMC 准则的判别约束项:

为满足NMF 的非负约束的要求,式(9)可改写为

式中:SB表示由所有训练样本的类间散度矩阵;和分别表示SB的正元素和非正元素的绝对值构成的矩阵;SW表示类内散度矩阵;和分别表示SW的正元素和非正元素的绝对值构成的矩阵。
对于图像数据,其特征维度和冗余程度都很高,基于稀疏编码的思想[20],将样本xi表示为基图像的稀疏线性表示,可以减少高维样本的计算量,得到更具鲁棒性的特征:

通常使用L0范数对系数矩阵进行稀疏性约束,但L0范数的求解属于NP 难问题,常用L1范数作为其凸近似进行近似求解:

系数矩阵H的每一列可看作原始数据X在子空间中的低维表示,L1范数使得系数矩阵H整体保持稀疏,本文使用L2,1范数对系数矩阵H进行列稀疏约束,使得每一个低维表示hj保持稀疏,能够在特征空间中用尽可能少的特征重构原始数据:

其中hj为矩阵H的第j列向量。
2.3 优化模型与求解
由以上分析,利用图正则化约束来保持样本之间的邻域结构;以最大间距准则保持数据集的判别性;以L2,1范数进行稀疏性约束[21],建立优化模型:
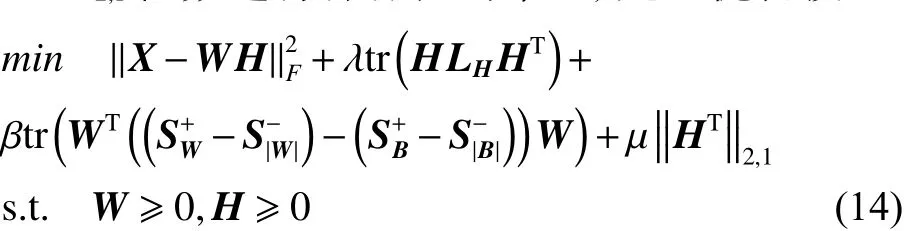
令 Φik与 Ψk j为拉格朗日乘子,构造拉格朗日函数:

式中:Q为对角矩阵,且为系数矩阵H的转置的第i列。
使用交替迭代方法求解。先固定H,更新W;然后固定W,更新H。式(15)对W求偏导并令导数等于0,得:
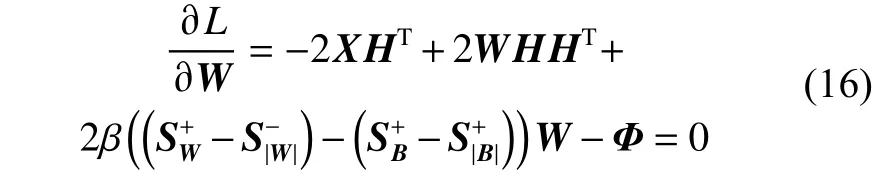
于是,有以下关于W的更新规则:


同理,得到关于H的更新规则:

在每次迭代得到基图像矩阵W后,对其每一列进行归一化处理,使非负矩阵分解得到的结果保持缩放不变性。设置最大迭代次数T0,使算法在最大迭代次数下收敛。
综合以上讨论,得到图正则化稀疏判别非负矩阵分解法:
算法1图正则化稀疏判别非负矩阵分解算法(GSDNMF-L2,1)
输入训练样本X∈Rm×n,样本类别Y,特征
+数r,正则化参数λ、β、μ,最大迭代次数T0。
1)利用式(6)和式(7)计算权重矩阵SH;
2) 利用式(9) 计算类内散度SW和类间散度SB;

利用式(18) 得到更新后的W,并对W的每一列进行归一化处理,利用公式(19)得到更新后的H;
End
输出基矩阵W和系数矩阵H。
2.4 算法复杂度
设m为样本维度,n为样本个数,k为特征数。算法GSDNMF-L2,1主要由1)、2)和4)组成,其(中步) 骤1)是构建数据图的权矩阵,其复杂度为On2m;步骤2) 则是(计算)类内散度SW和类间散度SB, 其复杂度为Om2;对步骤4),一次迭代计算W和H的复杂度O(mnk) ,假设算法在T0次迭代后收敛,则整个步骤4)的复杂度为O(T0mnk)。综上可知,GSDNMF-L2,1算法的总体时间复杂度为O
3 实验分析
为了说明GSDNMF-L2,1算法在图像特征提取中的有效性,分别在ORL 和AR 人脸数据集和COIL20 实物数据集上进行实验,并将之与NMF[3]、GNMF[10]、NDMF[9]等算法进行比较,同时比较利用L1范数进行稀疏约束的模型(GSDNMF-L1)。将数据集按0.5 的比例随机划分为训练集和测试集,利用训练集进行特征提取,获得基矩阵W。利用测试集计算分类精度:测试样本x∈Rm在低维子空间中的表示为y≈W+x∈Rr,其中W+=(WTW)-1WT为矩阵W的Pseudo 逆,使用传统的k-近邻分类器(k-NN)预测类标签。每次实验独立随机,重复20 次取平均识别率和方差作为最后实验结果。
3.1 数据集
ORL 人脸数据库包含了40 个人的人脸图像,每个人有10 张,图像具有不同面部表情(睁/闭眼,笑/不笑)、面部细节(眼镜/无眼镜)及不同光照条件。
AR 数据集包含了120 个人的人脸图像,每个人有26 张图像,图像具有不同的面部表情、照明条件和遮挡(太阳眼镜/围巾)。
COIL20 数据集包含了20 个不同的物体(玩具小鸭、招财猫、杯子等),其中,每个物体在水平面上每隔5°拍摄一张图片,因此每个物体一共有72 幅图片,整个数据集共计l 440 幅图片。
实验中,所有图像均压缩成32×32 大小的灰度图,将其每列相连构成大小为1 024 维的向量,并做归一化处理。如图2 所示。


图2 数据集示例Fig.2 The instances of datasets
3.2 参数选择
GSDNMF-L2,1算法包含了图正则化约束参数λ、判别约束参数 β 和稀疏参数 µ 等3 个关键参数。为说明3 个参数对识别率的影响,分别在两个数据集上采取固定两个参数来确定另一个参数的方法进行讨论,设参数的取值范围为[0,1],取数据集的类别数作为基图数(ORL 取40,AR 取120,COIL20 取20),最大迭代次数为300 次,实验所得的平均识别率与正则化参数的关系如图3 所示。

图3 参数对识别率的影响Fig.3 The influence of parameters
3.3 实验结果及分析
由图3 可知,图正则化参数λ对识别率的影响较大,在[0,0.01]的范围内,识别率随参数的增大而增大,在[0.01,1]的范围内,识别率随参数的增大而减少。判别约束参数和稀疏参数对识别率的影响较小,在[0,1] 范围内一直保持较高识别率。经过多次实验,最终确定算法的最优参数组合为λ=0.005,β=1,μ=0.5。
取基图数分别为3、4、5、6、7、8 的平方,在3 种数据集上独立随机地进行20 次实验,计算平均识别率及方差。表1~3 给出了5 种算法在3 种数据集上的平均识别率随基图像个数的增加而变化的情况。在大多数情况下,GSDNMF-L2,1的识别率要优于其他几种算法,且方差更小,说明在NMF 的目标函数中结合图正则化约束和判别约束能够有效提高图像特征提取的准确率和稳定性。图4 比较了在ORL 数据集上5 种算法的训练时间(取类别数40 作为基图数目),可以发现NMF 和GNMF 的训练时间较短,NDMF 训练时间最长,GSDNMF-L2,1和GSDNMF-L1比NDMF 时间短。可知,利用稀疏编码的思想对系数矩阵H添加稀疏性约束,在每一迭代更新的过程中能够尽可能少地选择基图像重构训练样本,提高了运算速度。

表1 ORL 数据集上的平均识别率(方差)Table 1 Average recognition rate (variance) on ORL dataset

表2 AR 数据集上的平均识别率 (方差)Table 2 Average recognition rate (variance) on AR dataset

表3 COIL20 数据集上的平均识别率 (方差)Table 3 Average recognition rate (variance) on COIL20 dataset
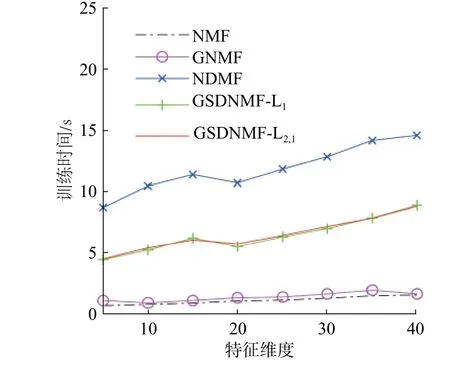
图4 训练时间随基图数变化的曲线Fig.4 Variation curve of training time
图5 给出了GSDNMF-L2,1算法在3 种数据集上的收敛情况,当迭代次数小于10 次时损失函数值迅速下降;而当迭代次数大于100 时,随着迭代次数的增加其损失函数值的下降趋于平缓,并收敛于一个固定值。本文所有实验均设置最大迭代次数为300 次,以保证算法收敛。
为了刻画和评价基图像矩阵的特点,Hoyer[20]提出采用向量的 L1范数和 L2范数的差异来度量向量的稀疏度,其计算方式为


图5 损失函数的变化曲线Fig.5 Variation curve of loss function
其中向量 xi是其第i 个分量。稀疏度值域是[0,1],值越大,说明向量越稀疏。表4 比较了5 种算法在3 种数据集上迭代300 次后生成的基图的平均稀疏度(基矩阵的每一列表示一个基图)。图6 比较了3 种具有判别性质的NMF 算法:NDMF[9]、GSDNMF-L1和 GSDNMF-L2,1得到的基图。对比发现,3 种算法都能得到的图像的局部化表示,且都包含了每类物体的判别信息,但GSDNMF-L2,1和 GSDNMF-L1得到的基图比 NDMF[9]得到的基图更稀疏。由实验结果可知,本文提出的算法,能够在保证稀疏性的条件下,保持良好分类水平,说明算法分解得到了更有效的基图特征。
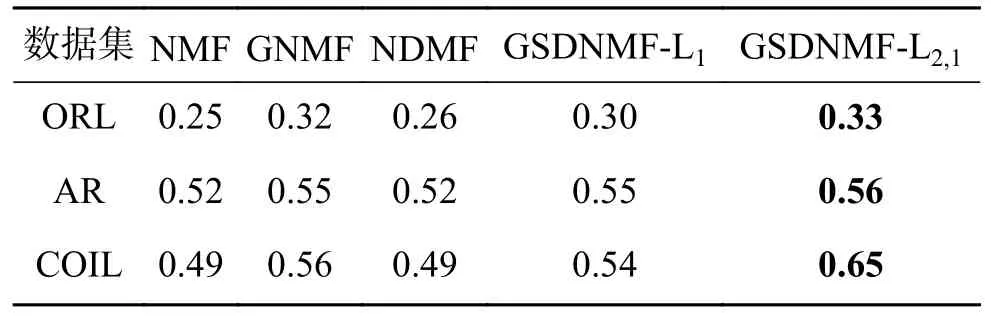
表4 比较基图像W 的稀疏度Table 4 Comparison of sparsity of the base matrix W

图6 比较NDMF,GSDNMF-L1 和GSDNMF-L2,1 算法在ORL、AR 和COIL20 数据集上得到的基图Fig.6 Comparison of basic images computed by NDMF,GSDNMF-L1 and GSDNMF-L2,1 algorithm on ORL,AR and COIL20 dataset
4 结束语
本文给出了一种新的图正则化稀疏判别NMF 算法(GSDNMF-L2,1)。该方法在对图像进行特征提取时,充分利用了数据集的标签信息来构造权重矩阵和判别约束项。与已有的图正则化方法不同的是,GSDNMF-L2,1算法用同类样本的稀疏线性组合来构建权重矩阵,很好地保持了样本内的相似性和样本间的差异性,在最大间距准则下使得类内离散性最小而类间分离性最大,从而获得很强的判别能力。另外,GSDNMF-L2,1在稀疏性约束条件下得到了稀疏系数矩阵,从而提高了矩阵分解的速度。下一步研究的方向是如何处理新样本,及自动选择最佳特征数量,使算法更加完善。
猜你喜欢
大学数学(2022年6期)2023-01-14
数学年刊A辑(中文版)(2022年1期)2022-08-20
四川大学学报(自然科学版)(2021年6期)2021-12-27
怀化学院学报(2021年5期)2021-12-01
四川大学学报(自然科学版)(2021年4期)2021-07-15
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
上海师范大学学报·自然科学版(2018年3期)2018-05-14
装甲兵工程学院学报(2017年3期)2017-07-05
文苑(2015年9期)2015-09-10
