
基于关键词学习的文本分类方法
2019-03-21 01:31
山东师范大学学报(自然科学版) 2019年1期
(1) 山东师范大学信息科学与工程学院,250358,济南; 2)山东超越数控电子股份有限公司,250013,济南)
1 引 言
计算机技术的发展和网络的普及,加速推进了信息化时代的进程,同时也造成了文本数据爆炸式增长、文本处理工作负荷加大等现象,为此很多学者开始关注文本分类问题.文本分类是指根据文档的主题、内容或属性,将大量的文本划分到一个或多个类别的过程.文本分类的主要方法包括传统的机器学习模型和神经网络模型[1,2].目前大量的机器学习方法应用于文本分类系统中,如基于贝叶斯定理与特征条件独立假设的朴素贝叶斯法[3-5]、建立在统计学习VC维理论和结构风险最小原理基础上的支持向量机方法[6,7]、运用概率与图论中的树对决策中的不同方案进行比较从而获得最优方案的决策树法[8],此外还有最小二乘法、K最近邻法[9]等.[10]上述算法虽然模型较为简单,但是对文本词语的上下文关系潜在语义关系考虑不够充分,分类效果仍有待提高.
为了更准确地将未知文本标记为正确的类别,不仅需要文本分类方法不断改进,还需要使文本表示方法更加合理,使关键词可以更全面地代表文本信息.近些年深度学习的不断发展为解决大数据问题提供了新方向,使用基于深度学习的方法可更好地挖掘蕴含在文本中复杂的语义关系,从而更好解决文本处理的相关问题.[11]本文引入卷积神经网络和BP神经网络的混合网络对文本的关键词进行学习,更好地发掘关键词的潜在语义关联.
2 基于关键词学习的文本分类算法
本文提出的文本分类方法首先利用LDA主题模型抽取关键词,构造关键词的词袋模型,然后根据词袋模型构造文本特征矩阵并进行降维操作,将低维样本矩阵输入由卷积神经网络和BP神经网络的混合网络进行训练学习,整个系统流程如图1所示.
2.1关键词抽取目前,关键词抽取技术主要是基于统计的方法和基于主题的方法.统计方法如TFIDF算法、TFIPNDF算法等虽然简单快速,但单纯以词频衡量一个词的重要性不够全面,为了尽量减少文本表示对文本分类效果产生的影响,本文采用基于主题的LDA模型抽取关键词.
LDA主题模型的主要基于两点假设:一是文档是若干主题的混合分布,二是每个主题是词语的概率分布.与其他主题模型(例如PLSA模型、TDCS模型等)相比较,LDA模型在前两者模型的基础上引入Dirichlet分布和超参数的概念,避免过拟合、计算难等问题的发生.LDA模型把每个文档都表示成它所对应的主题集,每个主题都是一个特定的多项式分布,主题与词汇对应的多项式分布就是主题与词语之间的关系.假设文档集合为D,包含M篇文档和k个主题,参数α和β分别为Dirichlet分布,φk表示第k个主题的词分布,θi是第i篇文档的主题分布,则LDA模型的图形表示如图2.
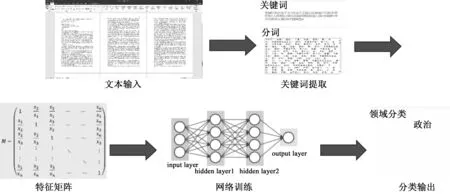
图1 基于样本关键词的文本分类流程
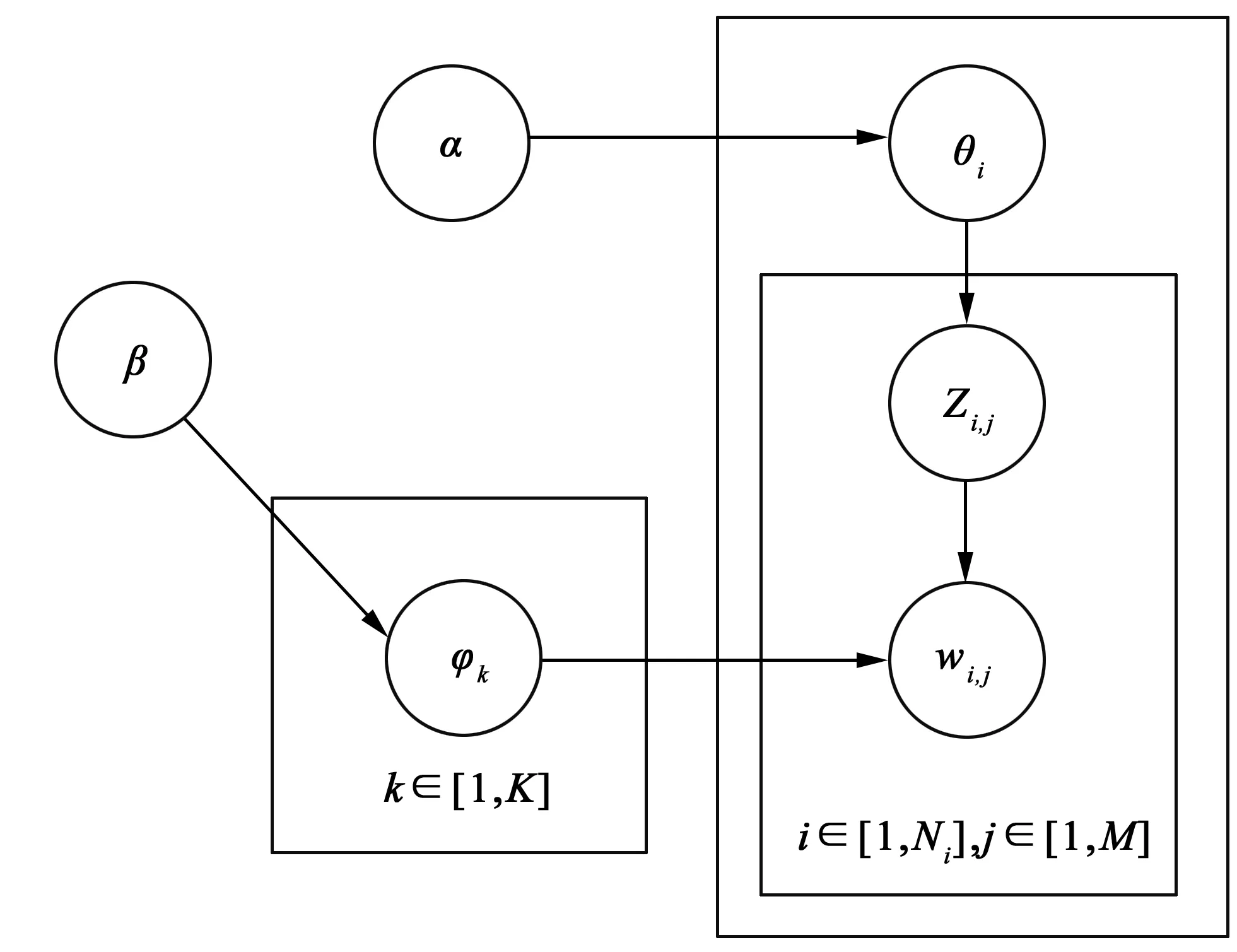
图2 LDA模型的图形表示
LDA模型的生成过程如下:
1) 按照先验概率P(di)选择一篇文档di;
2) 从Dirichlet分布α中取样生成文档di的对应的主题分布θi;
3) 从主题的多项式分布θi中取样生成文档di第j个词的主题zi,j;
4) 从Dirichlet分布β中取样生成主题zi,j对应的词语分布φzi,j;
5) 从词语的多项式分布φzi,j中采用最终生成词语wi,j.
生成过程中使用的主题特征值及其总和的计算公式如下:
(1)
(2)
其中φ′k是φk的前N个值,K是主题的数量,ti是含有wordi的主题个数,f(t)是待定函数.
2.2文本特征提取要采用卷积神经网络对数据集进行优化和处理,首先构造文本的特征矩阵,整个过程包括文本关键词词向量的构造、文本特征矩阵的构造、文本特征矩阵的降维三个阶段.
2.2.1 文本关键词词向量的构造 构造词向量需先将大量文本中的关键词组成词袋(BOW),词袋是指假定对于一个文本,忽略其词序、语法和句法,将其仅仅看作是若干词的集合.利用2.1节中基于主题的关键词抽取技术得到的文本关键词,构造出一个词袋模型.
假定在所有数据集文本中抽取出来的关键词为key1,key2,key3,…,keyn,(keyi≠keyj,i,j=1,2,3,…,n且i≠j),则关键词词袋为{key1,key2,key3,…,keyn},该词袋中包含n个关键词,每个关键词有唯一的索引,因此数据集中的任一文本可以用一个n维的向量来表示,即
xi=T(keyi).
(3)
其中T(·)表示对keyi求主题特征值,对于任一文本的词向量表示为{x1,x2,x3,…,xn}.
2.2.2 文本特征矩阵的构造 将文本的n维词向量转换为n*n维特征矩阵.文本的特征表示为V={x1,x2,x3,…,xn},其中xi代表关键词i在该文本中的主题特征值.由词向量生成的特征矩阵M为

当数据集中文本数量不断增加时关键词的数量也将不断增加,这将导致生成的词向量和特征矩阵变成高维矩阵,因此先对高维矩阵进行降维处理.
2.2.3 文本特征矩阵的降维 文本特征矩阵的维度为词袋模型的大小(通常达到105),高维特征空间存在许多与文本类别有弱相关性或无相关性的特征,并且存在强相关性的冗余特征,这导致计算复杂度增高,分类模型训练消耗增大,容易出现过拟合问题.CNN本身可以进行降维,但是CNN的降维能力有限,因此特征矩阵在输入CNN前进行若干次主成分分析(PCA)降维以提高计算速度和效率.根据2.2.2节可以得到文本的n*n维特征矩阵,采用PCA对特征矩阵分别进行行和列的降维处理.
首先对n*n维矩阵M进行列降维,使其转化为一个n*k维矩阵.具体步骤如下:
1) 将矩阵M的每一列进行零均值化,即每一列减去该列的均值,得到矩阵M1;
2) 求出矩阵M1的协方差矩阵M2;
3) 求出协方差矩阵M2的特征值及对应的特征向量;
4) 按特征值大小将对应的特征向量从左到右按列排列成矩阵,取前k列组成矩阵S;
矩阵S为利用PCA降维之后得到的n*k维矩阵.对矩阵S进行转置得到k*n维矩阵记为T,对矩阵T进行PCA降维,使其转换为一个k*k维矩阵.具体步骤如下:
1) 将矩阵T的每一行进行零均值化,即每一行减去该行的均值得到矩阵T1;
2) 求出矩阵T1的协方差矩阵T2;
3) 求出协方差矩阵T2的特征值及其特征向量;
4) 按特征值大小将其特征向量从上到下按行排列成矩阵,取前k行组成矩阵K,得到k*k维的低阶特征矩阵.
2.3文本分类学习
2.3.1 CNN训练网络 卷积神经网络核心在于输入矩阵与不同过滤器之间进行卷积运算,并且通过池化映射提取数据特征.本文中的卷积神经网络模型由输入层、卷积层、池化层、全连接层、输出层等部分组成.
两次卷积运算中所用卷积公式为
h=f(W*Cl+b),
(4)
其中f(·)为tanh激活函数,W为输入矩阵,C为高度为l的卷积核,b为偏置.
两次池化运算中所用池化方法为max-pooling,池化公式如下:
hmax=max(hi).
(5)
全连接层的每一个结点都与上一池化层的所有结点相连,用来把提取到的特征综合起来.具体的卷积神经网络模型如图3所示.
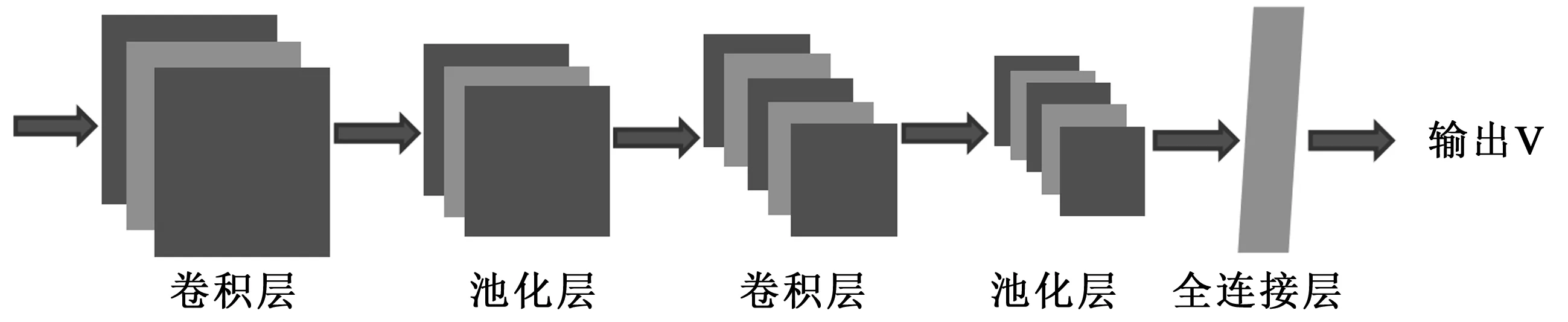
图3 卷积神经网络模型
将低阶特征矩阵输入上述模型进行卷积映射和池化映射,在对文本特征优化的同时进一步降维,最后利用全连接层将分布式特征表示映射到标记空间.
2.3.2 BP神经网络 BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,其原理主要是先给出输入信息通过输入层,经过隐含层逐层处理并计算单个单元的实际输入值,然后检验输出层得到的输出值,如果不能得到期望的输出值,那么逐层递归地计算实际输出与期望输出的差值,以便根据差值调节权值.
由于传统的BP神经网络随着网络深度的增加,训练的过程将会变慢,同时不适当的参数选择将导致网络收敛于局部最优.因此随机初始化参数会使BP网络训练效果降低,本文采用多个受限玻尔兹曼机堆叠构造的深度信念网络(DBN)对BP网络参数进行初始化[12,13].具体过程如图4所示.

图4 BP网络的初始化和训练
每个受限玻尔兹曼机(RBM)有n个可见单元和m个隐单元,用向量v和h分别表示可见单元和隐单元的状态,则能量函数为
(6)
其中θ={Wij,ai,bj}是RBM的参数,Wij表示可见单元i与隐单元j之间的连接权重,ai,bj分别为单元i,j的偏置.
由式(6)可以得到(v,h)的联合概率分布函数和似然函数为
(7)
p(v|θ)=∑hP(v,h)=∑he-E(v,h|θ)/Z(θ).
(8)
其中,Z(θ)=∑v,he-E(v,h|θ)为归一化因子.
3 实验结果与分析
本文实验基于公开数据集和自定义数据集两种.公开数据集采用的是复旦大学语料库(以下简称FDU)、中科院计算所自然语言处理语料库(以下简称ICT)和谭松波分类语料库(以下简称TSB).上述三种公开语料库由于文本数量和类别较多,在实验时将随机选取语料库中部分文本进行训练和测试.具体实验文本数量和类别设置如下:
FDU语料库中选择C3-Art,C7-History, C19-Computer,C31-Enviornment, C38-Politics和C39-Sports六类文本类型共6 000篇文章进行实验.将6 000篇文章随机分为FDU_1、FDU_2、FDU_3三个数据集,其中每个数据集均含有2 000篇文章.实验室在每个数据集中选取1 500篇文章作为训练文本,剩余的500篇文章作为测试文本.
ICT语料库中选择政治、经济、军事、工业四类文本类型共4 800篇文章进行实验.将4 800篇文章随机分为ICT_1、ICT_2、ICT_3三个数据集,其中每个数据集均含有1 600篇文章.实验室在每个数据集中选取1 200篇文章作为训练文本,剩余的400篇文章作为测试文本.
TSB语料库中选择财经、科技、体育、娱乐、人才五类文本类型共5 100篇文章进行实验.将5 100篇文章随机分为TSB_1、TSB_2、TSB_3三个数据集,其中每个数据集均含有1 700篇文章.实验室在每个数据集中选取1 300篇文章作为训练文本,剩余的400篇文章作为测试文本.
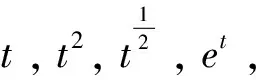
(9)
其中P为文本分类准确率,T为测试文本正确分类数,A为测试文本总数.
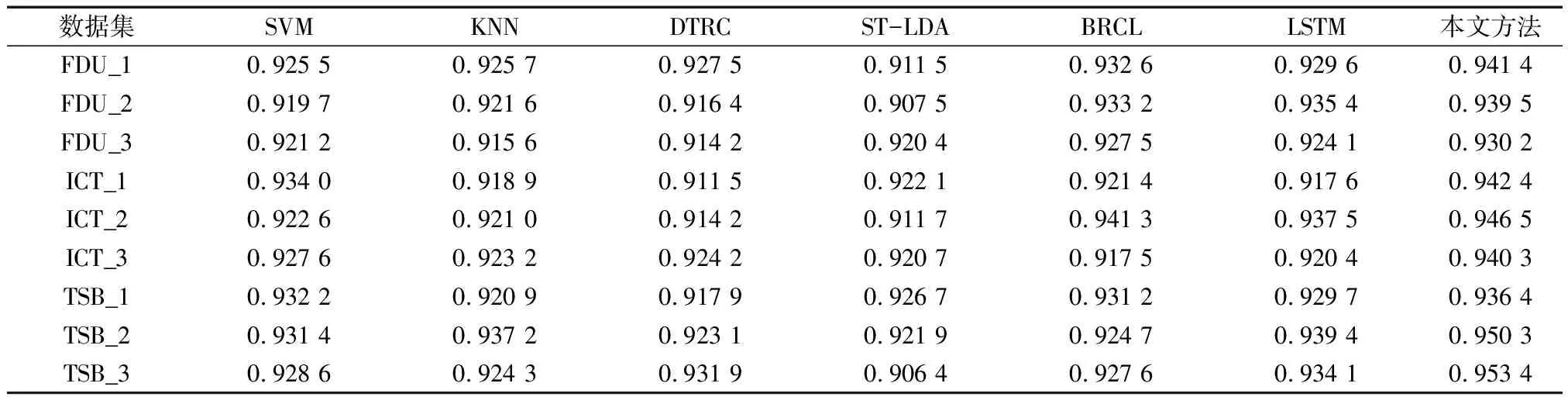
表1 公开数据集准确率表
自定义数据集(以下简称CDS)采用网络爬虫技术在万维网下载经济、政治、军事、文化四类文本共3 600篇.将3 600篇文章随机分为CDS_1、CDS_2、CDS_3三个数据集,其中每个数据集均含有1 200篇文章.实验室在每个数据集中选取900篇文章作为训练文本,剩余的300篇文章作为测试文本.实验结果如表2.

表2 自定义数据集准确率表
从整体上,SVM、KNN、DTRC等方法和本文方法在自定义数据集上的实验效果低于在公开数据集上的实验效果,原因可能是在万维网上利用网络爬虫技术获取文本时所下载文本类别不够准确和文本总量少两方面原因.
从表2中数据仍可看出在自定义数据集上本文方法的文本分类准确率明显较高其他几种方法.总之,在公开数据集和自定义数据集相比,本文的文本分类方法的准确率明显提高,表明本文方法更好地学习了文本语义潜在的语义关系,减少了有效信息的损失.
4 结 语
本文通过对原始文本进行特征提取,在文本表示方面利用基于主题的LDA模型进行关键词抽取,从文本源头和关键词相对词频方面改变了样本矩阵的构成,利用PCA将原有特征矩阵降维后引入卷积神经网络进行特征处理,以便描述关键词关系并进一步使矩阵降维,最后输入BP网络进行训练并利用测试文本进行学习,获取的实验结果说明基于关键词的文本分类方法取得了较好的效果.优化关键词的抽取技术和神经训练网络的构造是后续工作,该后续工作的意义在于进一步提高文本分类的准确率.
猜你喜欢
车主之友(2022年4期)2022-08-27
北京航空航天大学学报(2021年9期)2021-11-02
海峡姐妹(2019年12期)2020-01-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
能源(2018年4期)2018-05-19
北京航空航天大学学报(2018年1期)2018-04-20
新高考(英语进阶)(2017年2期)2017-04-16
火控雷达技术(2016年1期)2016-02-06
