
基于过车速度分布的中观仿真模型参数校准*
2019-03-29 10:52杨昀霖何兆成王亦民
中山大学学报(自然科学版)(中英文) 2019年2期
杨昀霖,何兆成,王亦民
(1.中山大学智能交通研究中心,广东 广州 510275; 2.广东省智能交通系统(ITS)重点实验室,广东 广州 510275)
交通仿真是模拟道路交通流运行的有效方法,其模型的参数在投入应用之前需要利用相关场景的交通流检测数据进行校准,以保证仿真结果的准确性和可靠性。在当前的智能交通系统中,绝大部分场景的数据是靠视频、线圈等断面检测器来持续获取的,其粒度可以精确到车辆个体。为了更合理高效地应用交通仿真,需要充分考虑系统现有的数据条件,构建相匹配的仿真模型及参数校准方法。常见的交通仿真模型,按其对交通系统的描述尺度可以分为宏观、中观和微观模型三类。对于宏观仿真模型,如:CTM模型[1],以车流为研究对象,利用道路基本图关系来驱动车流的演变计算。其待定参数如:自由流车速、阻塞密度和饱和流量等,通过断面流密基本图散点数据进行最小二乘拟合即可标定[2-3]。但,这类模型缺乏对交通管控变化的考虑,不便于调控类的仿真应用。对于微观仿真模型,如:跟驰模型[4-5],以车辆个体为研究对象,通过引入反映驾驶员心理反应特性的参数去描述车辆的跟驰行为,其结构比较复杂,需要利用轨迹数据来校准参数[6-7]。但轨迹数据在当前的检测条件下难以大范围获取,模型的应用受阻。因此,有不少学者利用宏观交通流数据去校准微观仿真参数,并取得了较好的研究成果[8-9],但该方法因模型尺度与数据粒度不匹配,容易出现参数“过拟合”的问题[10]。对于中观仿真模型,如:车队模型[11-12],通过对路网描述和车辆运动进行一定的简化建模,在保留了交通流重要特征的同时,减少计算量和对校准数据的精度要求,就可利用宏观交通数据校准模型的参数[13-14],但这类研究只用到个体检测数据的部分特征,如:均值,没有充分利用个体数据的全局信息。因此,针对存在断面个体检测的道路场景,本文将选用与之匹配的中观仿真模型开展参数校准研究,并考虑个体检测数据的分布特性构建参数的优化问题;然后,通过求解算法校准模型的运动参数;通过与传统集计型的校准方法进行对比,验证该校准方法的可靠性和潜力。
1 中观交通仿真模型
本文以车队为对象,采用基础交通流模型组合来描述车队的运行。车队是指运行在相同的交通状态下,位置相邻的一组车辆。Yang等[15]基于车队这种群体特征建立了MesoTS模型,已被广泛应用在交通流仿真中。研究将在此框架基础上做模型组合,并进行了车道级运行的拓展。拓展后的框架将车队运动分为纵向运动与横向运动(车辆换道)两部分,整体运行框架如下。
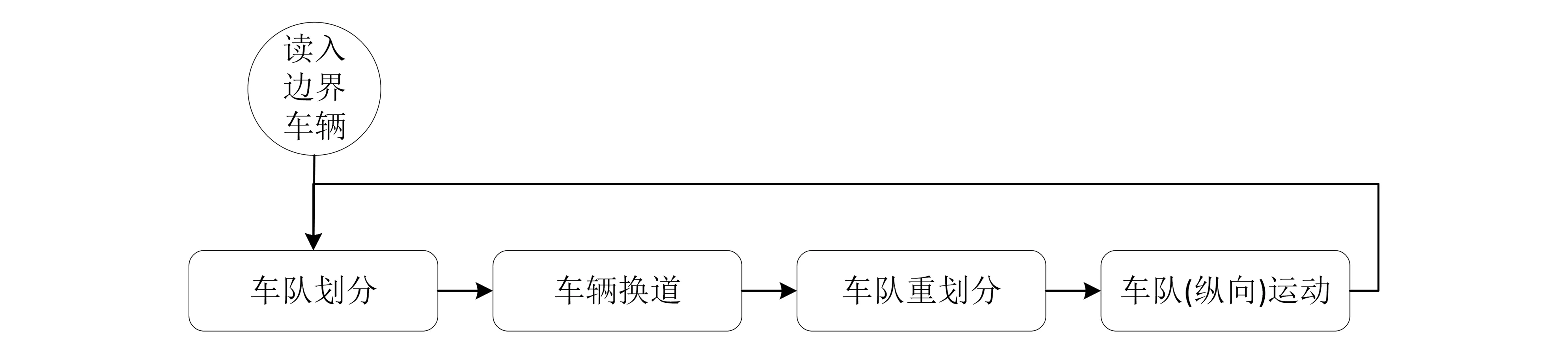
图1 仿真运行框架Fig.1 Flowchart of simulation process
在每个计算迭代中,首先依据每个车道前后车辆的车头时距与车速的差距进行车队划分[12]。然后,以车队为单位计算车辆的横向运动,并根据换道结果重新划分车队,最后进行车队的纵向运动计算。
1.1 车队纵向运动
车队的纵向运动可利用群体运动的特征进行简化,在本文描述的群体运动中,包括车队边界对外部应激运动、车队内部平均运动以及外部应激向内部的传递三个过程。由于交通流运行的前向性,即车辆主要受前车影响,故认为车队头车主要进行应激运动,受到车队内部影响较少;与之相反,车队尾车由于距离头车最远,其运动主要受内部平均运动影响。因此,本文对车队头车与尾车的速度分别建模,并根据车辆位置,对车队中间的车辆进行速度平滑,描述外部刺激的传递。跟驰模型作为一类应激—反应模型,能较好地刻画群体边缘对外部刺激的反应,本文利用跟驰模型描述车队头车的行为。为适配断面交通流数据的精度, 减少不可观测的模型参数引入,采用如(1)式所示的Newell形式的跟驰模型[16]。
(1)
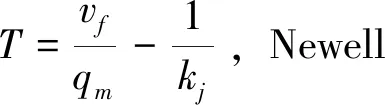
(2)
此时,跟驰模型可由断面数据提供的宏观观测参数vf、kj、qm唯一确定。对于群体平均运动,采用被广泛应用的速密函数,如下式所示:
(3)
其中,α、β为形状参数。同样的,由于其难以观测,通过引入稳态通行能力qm,可得到:
(4)
其中,速密模型r=α·β由形状参数r与宏观观测参数vf、kj、qm唯一确定。
1.2 车队横向运动
利用基于换道效用的logit模型来刻画车辆换道概率。换道效用主要由相邻车道附近区域密度降低的吸引、以及由于车道交通组织限制而必须进行换道的紧急性构成,分别称为自由换道效用与强制换道效用。其中,相邻车道附近区域是指邻近车道与该车队首尾对应的位置。在距离强制换道点x米的位置,车辆从车道i换道至车道j的概率为:
(5)

综上所述,由断面数据(流量/车速/密度)可以标定宏观基本图的自由流速度vf、通行能力qm、拥堵波速等主要参数,如下图所示。由于路段完全堵塞现象难以被检测到,且拥堵波速标定值的微小变化就能导致阻塞密度的标定值大幅增减,故阻塞密度不适宜直接由断面数据标定,而需要进行随机优化,其取值边界对应拥堵波速校准值边界的截距。因此,本文需要对阻塞密度kj、速密模型形状参数r、换道模型敏感系数γ1、γ2以及换道影响时间lb进行优化。

图2 基于断面数据的宏观参数标定Fig.2 Calibration of macroscopic parameters using aggregate data
2 模型参数校准方法
断面检测的个体信息主要有车头时距和速度,考虑到车速是交通运行状况的基本量度,在道路设计、交通规划和交通管理与控制等方面有着广泛的应用,选取车速作为仿真的评价参量。下面,将从拟合优度指标和优化求解算法两个方面介绍参数的校准方法。
2.1 基于过车速度分布的拟合优度指标
假设交通流在一段时间T内的运行过程是平稳的,即交通状态不变。据此,传统方法以T为统计间隔,将间隔内个体车速样本的均值作为模型性能量度。值得注意的是,不同个体数据的分布可能具有一样的均值,以均值作为性能量度会对一些均值较好,但对个体数据偏差较大的非合理参数没有辨别能力。因此,参数优化时应尽可能多地考虑个体车速样本的分布特征。基于双样本K-S检验[17]的分布差异度量方法,本文构建了参数校准的拟合优度指标。双样本K-S检验的基本原理是以两个样本的经验累积分布的纵向最大差距(K-S距离)作为检验量,如下式所示:
Dn,m=max|F1,n(x)-F2,m(x)|
(6)
式中,F1,n、F2,m分别为第一、二个样本的累积经验分布,其样本容量分别为n和m。
相比其他分布差异度量方法,K-S距离具有以下几点优势:(1)对分布曲线的整体形状都敏感,不局限于均值、标准差或百分位数;(2)分布差距可直接从样本求取,无须对分布参数进行估计。这里需要特别说明的是,K-S距离只用作样本分布差异的度量,不对样本是否来自同一总体作检验,故车速样本不需要严格满足独立同分布的条件。因此,采用K-S距离来构造拟合优度指标,比起传统的均值残差能够保留更多的个体信息。同时,考虑到不同统计时段的检测样本量有所不同,基于过车数对不同间隔分布的K-S距离进行加权平均统计,最终得到拟合优度指标(W-KS),如式(7)所示:
(7)
2.2 基于差分进化算法的参数优化求解
因仿真过车速度与模型参数间的数学关系无法显式表达,优化目标关于参数的梯度信息也难以确定,故不能使用解析法进行求解。对于这类黑箱优化问题,选取差分进化算法作为参数寻优方法。差分进化算法是一种基于实数编码的具有保优思想的贪婪遗传算法[18],包含变异、交叉操作和淘汰机制。它可以对非线性、不可微、连续空间函数进行最小化,其强大的全局寻优能力已在大多数benchmark测试函数和工程应用中得到验证[18],其算法流程如表1所示。

表1 差分进化算法伪代码Table 1 Pseudocode of DE algorithm
3 案例分析
选取广州市内环路A线人民桥至工业大道出口段的道路作为实验区域。如图所示,路网包含两个进口和三个出口,其中的主线道路有三条车道,上游进口和下游出口前各架设了一组视频交通流检测器。这一类检测器记录了每一辆车经过断面时产生的信息,主要包括过车时刻、过车速度和所在车道。挑选2017年7月21日早高峰2 h的记录,作为参数校准的数据集。上游断面的过车数据组织成精准发车表,保证车辆驶入路网的时刻、速度与实测一致,同时按照浮动车的比例数据对驶入车辆进行路径分配。下游断面的过车记录以10 min作为统计间隔进行分组,便于后续统计分布差异。

图3 实验场景Fig.3 Test site layout
3.1 仿真模型校准结果
为了保证算法的全局搜索能力,设置种群个体数量为20,变异步长F=0.5,交叉概率P=0.5,迭代的最大次数为500[19]。进一步地,为了测试和分析新指标的性能,引入基于平均车速的RMSE指标进行对比。最后,对两种指标进行优化求解,得到参数的校准值,如表2所示。

表2 仿真参数校准值Table 2 Value of the calibration parameters
3.2 结果分析
3.2.1 校准效果 分别使用W-KS和RMSE两种优化目标的最优参数进行仿真计算,输出过车速度并与实测数据对比。过车速度分布和平均车速时间序列分别如图4和图5所示。
通过比较发现,本文提出的W-KS优化目标可以使仿真过车速度分布与实测基本一致,融入了个体信息后明显优于基于平均车速的RMSE校准参数。而在平均车速的时间序列方面,尽管W-KS校准方法在这种集计性能上的表现不如RMSE,但是差距较小,说明W-KS校准的参数在确保个体分布相似的基础上,能够在一定程度上兼顾均值统计的性能。
3.2.2 参数的合理性 由于两种拟合优度指标得到的参数差异较大,需要对参数的合理性做进一步的验证。这里选取了车辆个体的基本图散点作为考察指标,分别以车头时距和车间距的倒数作为流量和密度,按不同车道对比两种拟合优度指标所产生的二维散点与实测散点的重合情况,如图6所示。
图6中,两种拟合优度指标校准出来的模型在车道2上的表现基本相同;但,在车道1和3上,RMSE优化的仿真散点与实测散点基本不重合,产生了过多不合理的非稳态点。这是因为RMSE优化出来的换道参数不合理,换道的影响时间过长,导致这两个车道形成了与真实不符的排队现象。这说明由于没有个体信息输入,基于车速均值的优化目标只会一味偏好一些均值误差更小的非合理解,容易导致模型“过拟合”。
3.2.3 优化算法的收敛效率 为了测试两种拟合优度指标对算法寻优效率的影响,记录算法在迭代过程产生的所有参数解。中观仿真模型的阻塞密度和速密函数参数是影响模型特性的重要参数。在迭代一定次数后,两种算法中这两个参数的分布情况,如图7所示。
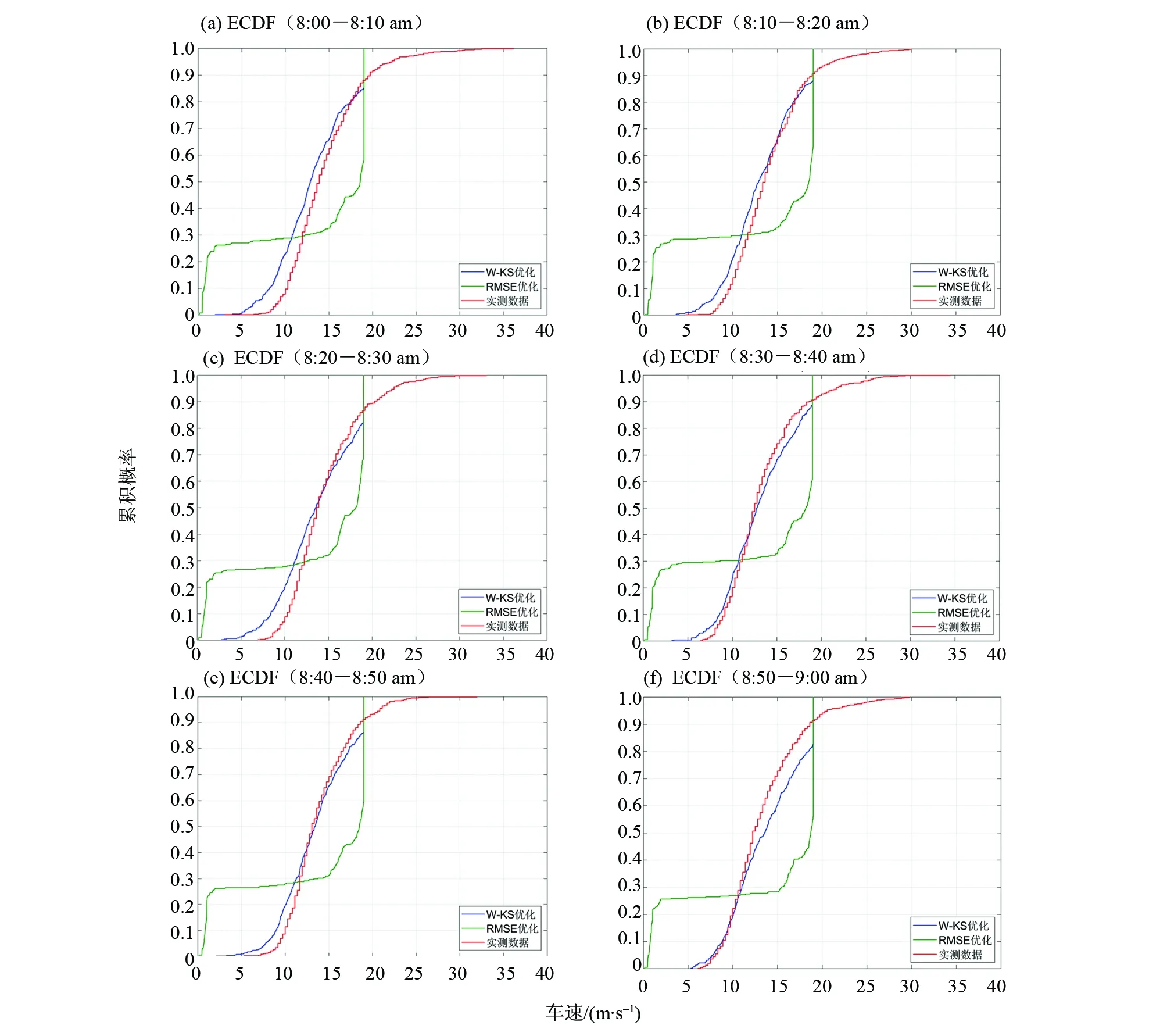
图4 W-KS与RMSE优化的车速分布(8:00-9:00 am)Fig.4 Comparison of observed and simulated speed distributions optimized by W-KS and RMSE methods (8:00-9:00 am)

图5 W-KS与RMSE优化的10 min平均车速序列(8:00-10:00 am)Fig.5 Comparison of observed and simulated time series of 10 min average speeds optimized by W-KS and RMSE methods (8:00-10:00 am)

图6 断面各车道基本图散点Fig.6 Scatter plot of fundamental diagram on every lane of the monitoring section
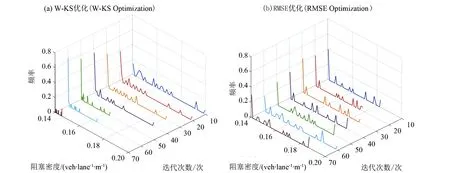
图7 阻塞密度kj随算法迭代搜索得到的取值分布Fig.7 Statistical distributions of kj at different iterations
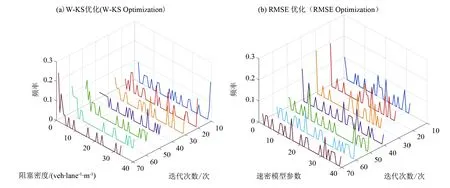
图8 速密模型参数r随算法迭代搜索得到的取值分布Fig.8 Statistical distributions of r at different iterations
在图7-8中,频率分布的宽窄反映了参数的离散程度。随着迭代次数的增加,W-KS模型两个重要参数的分布越来越集中,而RMSE模型参数的频率分布变化时而宽时而窄,没有呈现出明显的聚集趋势,意味着算法的收敛效率偏低。这是因为W-KS指标对均值较相似而分布偏差过大的解具有辨别能力,在一定程度上限制了优化算法不会轻易触碰到非合理解的“最优局部”,使得解的分布不那么分散。
4 结 论
本文选用了中观仿真模型作为研究对象,以过车速度的分布作为仿真的性能量度,提出了仿真模型参数校准的拟合优度指标(W-KS指标);并以广州市内环路的中观仿真为实例,通过与RMSE指标的对比,从模型校准效果、参数合理性以及优化算法效率三个方面,分析了新指标对参数校准的影响:1)新指标在较好还原个体车速分布特性的基础上,兼顾了统计均值指标的性能。2)新指标重现的整体交通流现象更符合实际观测,参数的合理性更强。3)新指标对个体分布不相符的参数具有甄别能力,可避免优化算法陷入到非合理“最优局部”的情况,从而使得解的分布更为集中,算法收敛效率更高。综上,本文方法在车队模型参数校准方面有较大的优势和潜力,进一步将在其它仿真模型如微观仿真模型上进行指标测试和推广。
猜你喜欢
汽车实用技术(2022年5期)2022-04-02
卫星应用(2021年11期)2022-01-19
汽车工程师(2021年12期)2022-01-18
科学大众(2021年9期)2021-07-16
汽车维护与修理(2018年1期)2018-04-04
车迷(2017年10期)2018-01-18
汽车与安全(2017年7期)2017-09-12
作文周刊·小学一年级版(2017年27期)2017-08-10
汽车维护与修理(2015年5期)2015-02-28
汽车电器(2014年8期)2014-02-28
