
基于稀疏邻域的主动不平衡学习算法
2019-07-15 01:52古平凌照
现代计算机 2019年16期
古平,凌照
(重庆大学计算机学院,重庆 400044)
0 引言
不平衡学习是机器学习中一种重要的分类问题,其中包含样本数目较多的为多数类,而样本数较少的为少数类。在许多实际应用中都存在不平衡问题,例如网络入侵检测[1]、信用卡欺诈检测和垃圾邮件检测。自不平衡学习问题被提出以来,已有大量的学习方法被开发用于解决该问题,这些工作大多分为两类:重采样技术和代价敏感学习技术[2]。重采样是一种重新平衡类分布的技术,它通过对少数类进行过采样或对多数类进行欠采样而实现。代价敏感方法则为每个类提供不同的错误分类代价,而且一般少数类的分类错误的代价较大。与现有的方法不同,Ertekin等人提出了基于主动学习[3]策略的不平衡学习算法[4](AL-SVM)来处理虚拟样本合成以及信息量的度量问题。最近,P Vateekul等人提出了一种基于G-means的主动学习模型来解决不平衡问题,并发现尤其适用于大规模数据集[5]。
直觉上主动学习在不平衡学习中的应用是从未标记的数据集中主动选择可能的少数类样本,然后标记并添加它们到初始训练集中以产生平衡的数据集。不幸的是,该技术可能会在不平衡的设定下遭受标记成本较大的风险,也就是说,由于初始数据分布是倾斜的,所以未标记的多数类样本将比少数类样本更频繁地被查询和标记,最后导致主动学习在降低不平衡率的效果上将受到较大的限制。
经过对主动学习和半监督学习[6]的研究启发,我们通过计算样本的少数类置信度,提出了一种新的针对不平衡学习的主动学习算法:基于稀疏邻域的主动不平衡学习算法(ASS-SN)。它有效地克服了虚拟样本合成的局限性,并且具有针对少数类样本有效查询的优点。其基本思想是仅使用小规模的有标记数据和大量未标记数据计算出未标记样本的少数类置信度,然后选择置信度最高的未标记样本作为迭代查询的标准。其中我们利用半监督学习技术来确定每个未标记样本的少数类置信度,受稀疏编码的启发,与其他基于图结构的半监督方法不同,我们通过求解一个L1最优化问题来计算出图结构的顶点与边权重信息,从而不需要预先设定相关参数的大小。
1 算法过程及框架
1.1 相关概念以及动机
给定不平衡数据集X={x1,x2,…,xm+n},xi∈Rd,1≤i≤m+n,其中d为维数。可以将该不平衡数据集X划分为XL和XU,其中XL=(x1,y1)…(xm,ym)是有标记的数据集,而且每一个样本包含有独一无二的属于(0,1)的样本标签,yi代表其类别标签。XU=(xm+1,ym+1)…(xm+n,ym+n)代表未标记的数据集,其类别标签未知。在有标记的数据集XL中,IR代表该数据集的不平衡比率。
我们所提出的问题是如何在以下情况使用未标记数据来提高监督学习算法的准确性:①只有少量有标记的样本可用。②有大量未标记的数据。③在有标记的数据集中,少数类样本数量远远少于多数类。经过AL-SVM算法的启发,我们发现该方法存在一个主要的缺点:直接将SVM算法应用到不平衡的数据集会导致该超平面存在偏倚,并且偏向于多数类样本,因此该算法并没有考虑查询有效性的问题,即希望不平衡学习算法能够有效地查询未标记的样本尽可能为少数类样本以达到均衡数据集的目的,从而降低人工标注成本。为此,我们采用了一种完全不同的主动采样策略,其目标是尽可能多地标记少数类样本,从而均衡初始的有标记数据集并提高分类性能。因此该策略包含本文的核心问题定义:少数类置信度。
定义1少数类置信度(MC):对于任意未标记样本xi∈XU,假设其属于少数类或者多数类的概率为yui mi或yui ma,那么该样本xi的少数类置信度(MC)可以通过以下公式计算:

Mci越大,表示该样本属于少数类的可能性就越高。如果我们根据少数类置信度相应地对未标记的样本进行主动采样,则更有可能正确地选择并标记它们为少数类样本。
1.2 半监督学习技术求解少数类置信度问题
根据定义1,我们的主动采样策略是根据未标注样本的少数类置信度选择最可能的少数类样本,也就是说,这个问题可以转换为求解未标记样本分别属于多数类和少数类的概率。为了解决这个问题,在机器学习中我们知道半监督学习旨在对标记样本和未标记样本进行学习,尤其是基于图的半监督学习方法。大多数现有的半监督学习方法是基于k最近邻(knn)图提出的,但k值在实际应用中难以预先确定,且尤其是在不平衡数据集中。受稀疏编码的启发,我们通过求解L1最优化问题来构建稀疏邻域图[7],这避免了在不同场景中预先定义k值的难题。最后通过在样本的稀疏邻域中实现标签传播来测量未标记样本的少数类置信度。
(1)构建稀疏邻域图
假设定义一个线性方程组:xi=Xiαi,其中xi是要表示的样本,αi是重建系数的向量,Xi是除了xi的其他样本,可以表示为:Xi=[x1…xi-1,xi+1…xm+n]。通过稀疏编码的启发,激励我们通过解决以下最优化问题来寻求xi=Xiαi的最稀疏的解决方案:

通过求解结果我们发现在系数重建过程中某些距离表示样本较远的“坏的”样本的重建系数一般较小而且会对标签传播起到负面作用。为了解决这个问题,我们定义了给定样本xi的稀疏邻域。
定义2稀疏邻域(SN):给定参数ε,样本xi的稀疏邻域定义为:如果重建过程中样本xj,i≠j的重建系数αj满足αj>ε,则认为样本在xj给定样本xi的稀疏邻域中,或者xj∈SN(xi)。
根据定义2,对于给定的样本xi,我们删除了那些所谓的“坏的”样本,即这些样本的重建系数很小。也就是说,我们强调那些在稀疏邻域中的样本的作用并且认为这些样本与被表示的样本“相似”。因此,构造的稀疏邻域图的目标函数由下式给出:
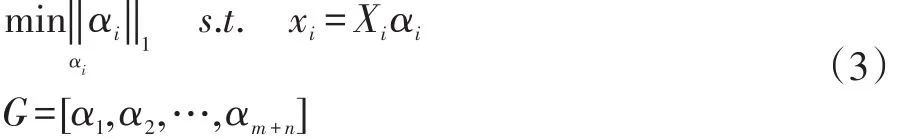
其中G表示稀疏邻域图,如果αij<ε,则αij=0。这表明如果样本xj不在样本xi稀疏邻域中,则重建系数将为0。
(2)基于稀疏邻域的标签传播
假设对于样本xi,xi的标签可以由来自xi的稀疏邻域的那些样本标签线性重建。并且我们假设标签空间和样本空间共享相同的局部线性重建权重,因此通过以下式子估计所有样本的标签:

基于基本的代数知识,可以很容易地推断出:
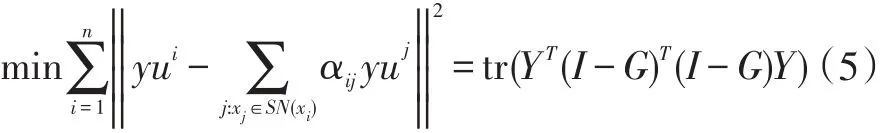
I是一个单位矩阵,令W=(I-G)T(I-G),我们可以得到结论:tr(YTWY),tr(·)表示矩阵的迹。将Y进行划分:Y=[YL;YU],YU表示待求解的未标记样本的标签矩阵,YL表示有标记样本的标签矩阵。将矩阵W划分为四个部分:

通过结论(5):tr(YTWY),我们求出关于Y的偏导数:

最后求解上式,获得所有未标记样本的标签概率矩阵:

通过将上述推导过程应用于训练数据集,每个未标记样本将分别获得属于少数类和多数类的概率,该求解结果可以表示为因此跟据定义1,我们可以计算每个未标记样本的少数类置信度,即
1.3 算法框架
基于稀疏邻域的主动不平衡学习算法(ASS-SN)包括两个关键步骤。首先我们通过求解L1最优化问题的方式构建稀疏邻域图,并在其基础上进行标签传播,以计算每个未标记样本的少数类置信度。其次,通过主动学习技术结合这种查询策略进行迭代学习,并在每一次迭代中更新标签传播矩阵,直到数据集几乎平衡。ASS-SN算法的框架如下:
输入:XL:有标记的数据集
XU:大量的未标记数据集
输出:XL:有标记数据集
(1)根据定义2以及公式(3)求解以下最优化问题,并构建稀疏邻域图G:
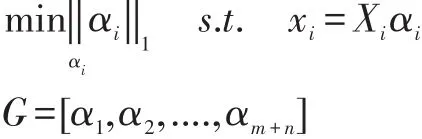
(2)while(IR>1):
①根据图G,构建传播矩阵W:W=(I-G)T(I-G),基于W进行标签传播,并计算出未标记样本的标签矩阵
②对每一个未标记样本xi∈XU,根据定义1和标签矩阵计算样本xi的少数类置信度,Mci:
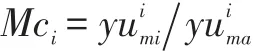
③根据Mci,选择其中少数类置信度最大的ul个样本交与专家标注,并将其中标注的少数类样本添加到过渡集V中。最后让XL=XL⋃{V},XU=XU{V}
④基于贝叶斯分类器重新训练XL并跟新标签传播矩阵W
(3)end while
2 实验结果与分析
实验主要在来自UCI机器学习库的数据集上进行,即Prima数据集。为了深度分析不平衡数据集对ASS-SN算法的影响,我们通过随机删除Prima数据集中样本的标签来获得主动学习中所需的未标记样本。表1显示了在这种情况下选择的数据集。为了评估不同算法在不平衡问题上的分类性能,我们采用了针对不平衡问题的经典评估方法,即F-measure[8]。在本文算法第1.2小节中,需要对是否处于稀疏邻域中的样本进行判定,我们根据经验和稀疏表示的特征选择ε的值,并且将稀疏邻域ε的半径固定在0.02。本文算法与两种流行的主动学习算法进行比较,即AL-EN[3]和AL-SVM,其中AL-EN是一种基于信息熵测量的主动学习方法。

表1 实验所采用的数据集
从图1可以看出,对于每种主动学习技术,每次查询的样本中少数类样本的数量都受到不平衡数据集的强烈影响。例如,如果查询284个未标记的样本,通过本文算法可以有效地标记181个少数类样本,而在AL-EN和AL-SVM中则只能标记98和73个少数类样本。从算法整体来分析可以看出由于本文算法有效地利用稀疏标签传播算法使得在主动学习采样的过程中,少数类未标记样本的采样概率大幅度提升。因此在每一轮标注占比上,本文算法完全优于其他主动学习算法,并且会提前完成对大部分少数类样本的标注。
从图2中,可以看到在每次的迭代过程中,F1值随着主动采样过程而逐渐增加,但是可以观察到,ASSSN的F1值优于AL-EN和AL-SVM。例如,AL-EN和AL-SVM的最佳 F1值分别为 0.6278和 0.5098,而ASS-SN算法可以达到0.7107。总之,这种性能提升是由于通过这种有倾向性的主动学习算法在少数类上具有强大的搜索能力,特别是当这些样本远离最初的少数类群体时;传统的主动学习算法倾向于丢弃这些样本,而本文的标签传播机制可以有效地找到它们。
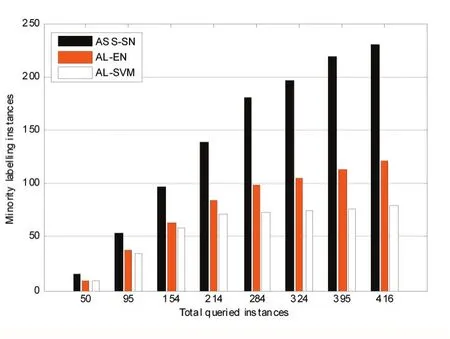
图1 少数类的标记效率
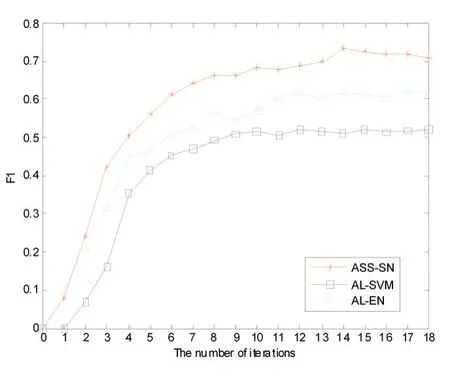
图2 每次迭代采样后的分类性能
3 结语
本文中我们提出了一种自适应的主动学习方法针对不平衡学习问题,本文算法的一个优点是利用稀疏邻域的标签传播策略计算未标注样本的少数类置信度,并专注于采样其置信度较高的样本,从而有效地解决不平衡问题并降低标记成本。其次通过引入主动学习技术的迭代过程,使得本文算法能够有效地提高不平衡数据集的分类性能。虽然ASS-SN算法在大多数情况下都能获得更好的性能,但仍有许多问题需要解决,例如我们所提出的算法比其他算法消耗更多的时间。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
大数据(2022年4期)2022-07-25
农业工程学报(2022年7期)2022-07-09
小型微型计算机系统(2022年4期)2022-05-09
逻辑学研究(2021年3期)2021-09-29
读与写·教育教学版(2017年10期)2017-11-10
中国科技纵横(2016年20期)2016-12-28
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
