
基于K2算法的精准营销研究
2019-07-15 11:18赵会群李子木慕善文
计算机应用与软件 2019年7期
赵会群 李子木 郭 峰 慕善文
(北方工业大学计算机学院 北京 100144) (大规模流数据集成与分析技术北京市重点实验室(北方工业大学) 北京 100144)
0 引 言
“数据画像”是指通过对用户属性、行为、偏好等信息的分析,从中抽象出标签化的模型。“数据画像”不仅有助于理解数据分布并评估数据质量,还有助于发现、记录和评估企业元数据。分析结果用于确定候选数据系统的适用性,通常为早期决策和后期解决方案的设计提供支持。大多数情况下,数据在不知时间、地点何种形式、何种手段被收集在一起,通过“数据画像”可以有目的地收集整理,为决策提供精准的服务。数据画像”的概念在很早就有提出,但由于之前的数据量级、维度和对数据的分析能力有限,分析得到的“数据画像”价值普遍不高。如今大数据时代来临,MapReduce和Spark这样的大数据处理框架日益成熟,再加上电商平台越来越受到人们的青睐,使得企业、专家和学者开始将目光投向了电子商务的大数据分析,而“数据画像”作为数据分析的重要一环,再次进入了人们的视线。
对于“数据画像”,目前的研究多是从“数据画像”的呈现方式和“数据画像”与推荐算法结合这两个方向开展的。“数据画像”的呈现方式多种多样,可以使用文字、语言、图像甚至视频的方式将用户的多维度特征展现出来。而“数据画像”与推荐算法结合的研究则可以将数据画像应用到产品中,使得推荐算法得到更好的优化。这两个热点研究领域确实有很大的研究价值,但它们的主要研究重点都没有放在“数据画像”的构建上,而是在“数据画像”生成的基础上进行研究。本文着重于如何构建用户画像模型,如何定义用户画像模型,如何优化用户画像模型的表达,如何适配不同的推荐算法是一个挑战,是目前研究中很少关注的问题。
同时,推荐算法和服务推荐系统的研究已经有很长的历史,也衍生出多种推荐算法,这些算法在不同的领域各自发挥着优势,但也存在一些不足。
• 基于内容推荐:冷启动问题和语义处理困难。
• 协同过滤推荐:冷启动问题、数据稀疏问题。
• 基于规则推荐:规则抽取难、耗时、个性化程度低。
• 基于效用推荐:效用函数构建难,灵活性差。
• 基于知识推荐:知识难获取。
目前推荐算法与“数据画像”相结合的研究越来越多,而推荐算法的这些不足也会给“数据画像”的构建带来挑战。本文从用户画像建模入手,构建独立于推荐算法的用户画像模型。把用户行为的期待解释成用户画像出现的概率,这样可以用概率论方法计算行为发生的可能性,为行为分析和预测奠定基础。鉴于传统的推荐算法存在诸多缺陷和处理困难,本文探讨一种更加完善的推荐算法。根据本文对用户画像模型的定义,提出了一种基于贝叶斯网络模型的用户行为预测推荐算法,该算法是通过基础的贝叶斯网络演变而来,并与实际业务相结合,可以更加精准地完成对用户的画像和用户行为的预测。
1 数据画像模型
本节主要阐述数据画像概率分配模型的概念,描述不同数据标签发生的关系,从而建立数据画像模型。
1.1 标签定义
首先给出标签定义。
标签用于表现用户的属性、行为或者特征,可以通过一组标签来描述一类人群的属性特征和行为方式,标签主要包含以下几个维度的信息:
1) 数据标签的名称,用于描述行为特征,并与其他标签进行区分;
2) 数据标签所在的问题域,例如房地产销售,信用卡销售等;
3) 事件发生的时刻;
4) 标签触发行为对象,如浏览建设银行信用卡中的“建设银行信用卡”是标签对象;
6) 标签发生的位置或是地点,如用户在APP中浏览房源,那APP就是发生浏览行为的位置信息。
一个事件的发生一定会有一组标签可以将它表现出来。
例1:用户办理信用卡的标签为:
1.2 标签维度的选择
当今的电商平台,用户在选择自己中意的商品时,往往会留下大量的访问痕迹,与此同时也会出现大量不同类型的标签。然而,并不是所有标签对“数据画像”的生成都有用,一些类似流量,跳转次数的数据统计对画像的研究价值并不高,有些甚至会对研究造成干扰。因此首先需要将冗余的数据进行清洗,保留最有用的标签来构造数据画像模型。一个好的“数据画像”能够清晰地呈现出用户的属性和偏好,与之最直接相关的维度便是用户的行为标签。以用户办理信用卡为例,通过“浏览信用卡”,“信用卡办理”等标签,可以将用户的行为习惯勾勒出来,通过对行为的分析更容易得到理想的“数据画像”。同时,用户关注的行为对象也十分重要,如信用卡中的免年费卡、高额度卡,汽车中的中型车、SUV等。这些是用户最关注的商品,通过这些标签可以让画像更加完善,而且也给后续的推荐指出了明确的方向。相比之下,流量、时间这类标签由于随机性较大,对于本次的研究帮助有限。因此本文主要对行为标签和偏好标签进行深入探讨。
1.3 数据画像概率分配模型
“数据画像”需要由标签来构建,而标签的出现是有概率的,例如当出现了浏览信用卡的标签,却并不一定会出现办理信用卡的标签。而当这些标签的概率产生变化时,由它们生成的画像也会有概率上的变化。设某一个数据画像LSP=
(1)
数据画像因果模型:设LSP=
(2)
式中:left(labi)表示标签labi左操作数,operj(labi)表示标签labi左算子。
数据画像概率分配模型与数据画像概念的不同之处在于,数据画像仅仅强调标签结构整体出现的随机性,而数据画像概率分配模型强调构成数据画像每一个标签出现的随机性,是对用户行为特征更加具体、深刻的表达。
例2:以信用卡申请中客户行为分析为例,分析客户在浏览了信用卡卡种之后,有可能会查看相关的同类信用卡,也可能会进行信用卡办理,使用“~”符号来表示行为之间因果关系。
A浏览信用卡~A浏览同类信用卡;
A浏览信用卡~A信用卡办理;
A浏览同类信用卡~A信用卡办理;
写成表达式的形式:
LS=A浏览信用卡~1A信用卡办理+1A浏览信用卡~2A浏览同类信用卡+
2A浏览信用卡~3A信用卡办理
数据画像概率分配模型中的P可以如下计算:
LSM=P(A浏览信用卡)×P(A浏览同类信用卡/A浏览信用卡) ×P(~1)×P(~1)×P(+1)×P(A信用卡办理/{A浏览信用卡,A浏览同类信用卡})×P(~2) ×P(~3)×P(+2)
推论:设数据画像因果模型LSM,当且仅当总可以有一个贝叶斯网络模型与LSM对应。
证明:【充分条件】 已知一个数据画像因果模型LSM,按照以下步骤构造贝叶斯网络:
步骤1:对每一个概率运算的操作数构造一对节点,对概率运算构造一个有向边,让左操作数对应的节点(父节点)指向右操作数对应的节点(子节点);
步骤2:如果有相同的父节点,或者相同的子节点,合并相同节点;
步骤3:重复上述步骤直到所有的概率运算被构建。
完成步骤1-步骤3后LSM对应的贝叶斯网络即可构造,定理的充分性得证。
【必要性】 完成充分性证明步骤的相反步骤即可证明定理的必要性证明。
步骤1:对每一对父子节点构造概率运算,父节点对应左操作数,子节点对应右操作数;
步骤2:如果有相同的父节点,或者相同的子节点,差分成单个因果运算;
步骤3:重复上述步骤直到所有的父子节点被差分完毕。
完成上述步骤1-步骤3即可完成数据画像的因果模型。证毕。
例3:例2中构建的数据画像因果模型为:
LSM=P(A浏览信用卡)×P(A浏览同类信用卡/A浏览信用卡) ×P(A信用卡办理/{A浏览信用卡,A浏览同类信用卡})
对应的贝叶斯网络模型如图1所示。

图1 对应的贝叶斯网络模型
2 算法研究
本节讨论基于数据画像模型的用户行为分析算法,包括:用户数据画像模型构造算法,用户行为预测算法。
2.1 用户画像因果模型
上一节中提到,一个数据画像因果模型总可以用一个贝叶斯网络模型表现出来。下面给出基于K2[1]算法的贝叶斯网络模型概率求解算法。
算法1贝叶斯网络模型求解算法
input:一组标有次序的n个标签节点(数据记录),贝叶斯网络中父节点的上界。
output:输出P(x1,x2,…,xn)数据画像概率
算法过程如下:使用评分函数:g(i,ρi)=max(∏(di-1)!/Hij+Di-1)∏Hijk),将每个标签节点与其所有的上层节点进行计算,将分数最高的上层节点或上层节点结构作为该标签节点的父节点。按顺序遍历完所有节点后,所有标签组成的结构即为一个用户画像因果模型,而它的输出则是该数据画像形成的概率。
算法1的时间复杂度是O(N×M),其中N是输入标签流的长度,M是标签属性长度。空间复杂度也为O(N×M)。算法1是对基于传统K2算法的改进。
2.2 用户行为预测算法
这里把用户行为分析和预测大体分两种,一种是可能消费用户的预测,另一种是消费可能性比较小的预测。即,分别计算出消费可能性,如果小于预测阀值,则不是消费用户,否则就是可能的消费者。预测阈值可以根据行业专家的经验设置。
为了预测可能消费者的行为,可以设置一个称为是“成功”的标签,加入到贝叶斯网络中,通过计算相关的后验概率即可求出消费的可能性,即计算P(lab1,lab2,…,labn,labn+1)和P(x1,x2,…,xn,xn+1)。为此,用贝叶斯网络求解消费可能性的算法如算法2所示。
算法2基于贝叶斯网络用户行为预测。
Input: 贝叶斯网络模型
Output:P(x1,x2,…,xn,xn+1)。
begin
1.ρi+1:=0;
2.g(i+1,ρi+1)=max(∏(di+1-1)!/Hi+1j+di-1)∏Hi+1jk);
3.Pold:=g(i+1,ρi+1);
4. OK:=true;
5.dowhileOKand|ρi|<μ
6.g(i+1,ρi+1∪ {z})=max(g(i+1,pred(xi+1)});
7.Pnew:=g(i+1,ρi+1∪ {z})
8.ifPnew>Poldthen
9.Pold:=Pnew;
10.ρi+1:=ρi+1∪ {z}
11.P(xi+1/pare(xi+1))=Pnew
12.P(x1,x2,…,xn,xn+1)=P(xi+1/pare(xi+1))
13.else
14. OK:=false;
15.enddo
16.ifP(xn+1/(x1,x2,…,xn))>Psuccthen
17.printP(xn+1/(x1,x2,…,xn))+″是可能用户″
18.else
19.print″不是潜在的用户″
20.endif
21.end
算法2的时间复杂度和空间复杂度与算法1相同。
3 实 验
本节以信用卡销售的真实场景作为实验背景,对提出的算法进行实验,包括:(1) 基于数据画像模型的用户行为预测分析;(2) 基于贝叶斯网络模型的用户行为预测分析。给出了用户画像模型的构造效率和行为预测算法的成功率对比。
3.1 信用卡营销应用场景
某银行与无线通信网络运营商建立了业务合作协议,在协议条款下,银行可以根据通信网络运营商提供的日志文件分析用户行为。日志文件样本及处理后的数据如图2、图3所示。

图2 APP运行日志数据
手机号|APP|行为|每小时发生多少次|卡种
136234|001|1|7501
136465|003|001|3|8745
136965|006|004|2|7323
136932|007|002|11|6979
137543|004|003|3|8436
137534|005|007|4|7866
134703|007|003|9|8546
138654|003|002|7|7605
136568|002|004|3|8603
图3 经过一次预处理的APP运行日志数据
其中,电话号经过加密处理,APP和行为做了简单的分类编码。
上述日志文件中的数据有多种标签,同时也可能会有我们感兴趣的标签结构,就像图4中的信用卡用户申请因果关系图。
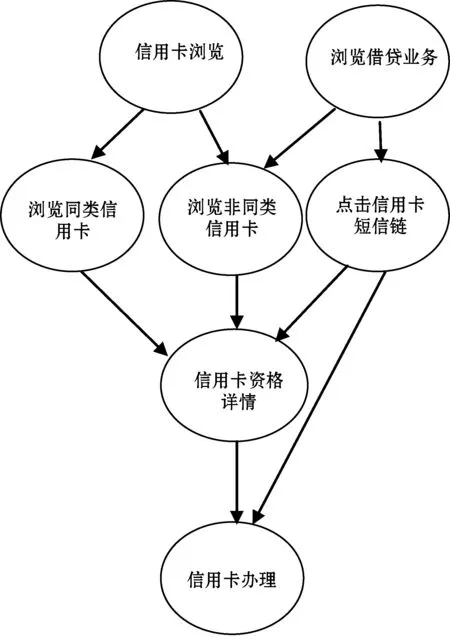
图4 信用卡用户申请因果关系图
如果加注各个节点的概率,父节点产生子节点的概率,图4可以看作是一个信用卡申请的贝叶斯网络模型。如果把“信用卡办理”节点看成是“成功”节点,图4也是一个贝叶斯网络预测模型。
3.2 算法实验
本实验使用的数据来自某银行信用卡的APP运行日志文件,如表1所示。实验选取了5个样本数据集。

表1 实验数据集
实验环境配置参数如表2所示。这里使用了两种实验环境。
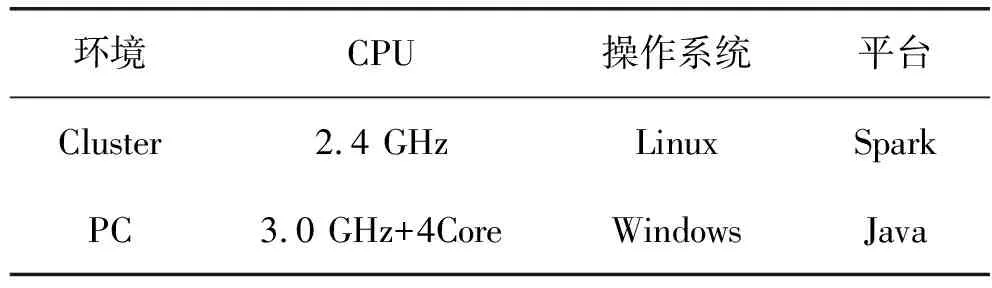
表2 实验环境参数表
实验为使用贝叶斯网络构造算法构建数据画像模型,即利用算法1实现图4信用卡营销贝叶斯网络模型。
实验中对父节点个数不断调整,对比实验结果后,使用最合适的父节点个数,通过K2算法构建数据画像模型,运行界面如图5所示。

图5 算法1的Spark运行界面
表3为实验的运行结果。

表3 算法1输出结果
算法2的运行时间如图6所示。

图6 贝叶斯网络求解时间图
通过图6可以看出,基于贝叶斯网络的数据画像模型和大数据的处理架构,运算时间会逐渐趋于平缓。
第二组实验是用户行为预测算法实现,包括算法1和算法2。
图7是基于贝叶斯网络的预测效果和传统预测效果的比较。纵轴是预测成功率,横坐标是两种预测算法运行的数据集。

图7 两种不同途径预测成功率比较
从图7可以看出,基于贝叶斯网络的预测方法有较高的预测成功率。其原因是采用了算法2对各个节点的概率进行了分析,分析得更为全面。
4 相关研究
本节从数据画像模型构建、推荐算法、消费者行为预测等方面综述相关研究工作。
数据画像(用户画像)模型的专项研究并不多见。文献[2]提出网络群体和个体画像的方法,通过收集群体属性和个体属性,发现传播内容、挖掘兴趣特征收集数据画像。提出的数据画像构造方法只适合社交媒体中的群体划分和网络新闻的真伪辨析。文献[3]提出一种基于本体的数据画像模型,通过分析网页使用者的行为数据,提用户属性和兴趣特征,从而构建一类用户的本体模型,为用户推荐提供支持。同类研究还有文献[4-5]。上述研究中一般把数据画像简单地看作特性标签的数据集合,数据画像的构建与推荐算法密切相关。
推荐算法与系统研究是近年来的热点研究课题,与客户行为预测相关的研究也很多。文献[6]提出一种基于贝叶斯推断的推荐算法。通过对影视作品评价历史,统计一对伙伴对该作品评级的条件概率。根据直接伙伴/间接伙伴关系,用户通过社交网络传播评价反馈从而构造贝叶斯网络,通过贝叶斯网络预测新作品的可能评价等级。实验表明该系统可以有效地克服冷启动和数据稀疏问题。
文献[7]针对事件推荐中一般假设各种因素有相同影响度,而造成推荐的准确性的质疑问题,研究不同影响因素权重的评估方法。把事件发生的地点、时间和社交偏好等因素转化为相关的条件规约,通过计算相关条件的敏感密度函数给出各种因素影响的事件排名,从而实现个性化推荐。提出了实现上述思想的推荐系统框架SoCaST,通过真实数据集检验了上述框架的有效性。文献[8]提出了一种关联规则挖掘与本体语义分析相结合的推荐算法。首先采用OWL建立本体语义信息字典和模型,然后再利用关联规则挖掘算法Apriori进行关联分析,从而找到与产品相关的带有语义信息的产品推荐。创新之处是把语义模型与关联规则挖掘相结合,从而直接给出产品推荐,不需要对推荐信息的再解释。文献[9]通过分析比较Apriori和FPGrowth在数据流在线执行效率后,给出FPGrowth算法更适合作为在线推荐算法的结论。把FPGrowth应用到音乐推荐中,取得了比较好的效果,但文中没有具体介绍如何在线分析的细节,没有对流式大数据的处理难度进行分析,没有给出数据如何过滤和筛选的算法。文献[10]提出了一种基于统计相关性度量的算法,通过统计相关性给出蕴含关系的概率,在两个样本集上测试了算法的有效性。该算法可以用于基于关联规则的推荐系统。该工作与Apriori算法相似,而且仅仅在样本集上进行实验,缺少使用效果的评估。文献[11]针对协同过滤算法的冷启动问题和内容推荐算法的语义瓶颈问题,提出了一种多内容协同过滤模型。采用多视图聚类挖掘网页中相关和相似的数据项,并应用于协同过滤中,从而解决了数据稀疏问题。文献[12]针对社会化推荐系统的需求,推荐算法的冷启动和数据稀疏问题,对社会化推荐系统的研究进展进行综述,对信任推理算法、推荐关键技术及其应用进展进行前沿概括、比较和分析。最后,对社会化推荐系统中有待深入研究的难点、热点及发展趋势进行展望。同类研究还有文献[13-15]。
5 结 语
由于不同领域有不同的数据画像表述,所以给出一个普遍适用的数据画像模型显得十分困难。本文在标签概率分布的基础上构建数据画像模型,提出基于该模型的用户行为分析和用户推荐算法。本文的主要贡献如下:
1) 提出了数据画像概念和数据画像概率分配模型,提出了标签结构提取、基于数据画像概率分配模型的系列推荐算法,形成了完整的推荐算法技术。
2) 提出了基于贝叶斯网络模型的推荐算法。通过增加成功节点或失败节点,构建贝叶斯网络预测模型,对大概率后验概率进行排序,从而给出推荐。
本文所述研究工作还有需要完善的地方,如进一步增加贝叶斯网络的结构,建立更复杂的网络,给出更完备的数据画像模型等。在推荐算法方面还需要进一步验证在更大、更复杂的数据集下算法的运行效率。另外,还需要扩展数据画像模型的应用领域,在不同应用场景下验证该模型的适用性。这也是下一步的研究工作重点。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
非公有制企业党建(2020年10期)2020-10-27
中国航海(2019年2期)2019-07-24
时代金融(2018年22期)2018-10-09
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
瞭望东方周刊(2017年35期)2017-09-22
数学学习与研究(2017年10期)2017-06-22
瞭望东方周刊(2017年7期)2017-03-01
党的生活(黑龙江)(2015年10期)2015-10-20
