
基于多层感知机的技术创新人才发现方法
2019-07-15 11:18谢世博
计算机应用与软件 2019年7期
冯 岭 谢世博 刘 斌
1(华北水利水电大学信息工程学院 河南 郑州 450046)2(武汉大学计算机学院 湖北 武汉 430072)
0 引 言
作为一种重要的科技信息载体,专利数据中包含了丰富的技术信息。根据世界知识产权组织的统计,专利数据中包含了世界上90%~95%的研发成果[1]。从专利数据中不仅可以检索到最新的科技信息,更能通过专利分析和挖掘来发现当前各个领域的技术创新人才。专利数据是评价和发现技术创新人才的重要依据之一[2]。
当前已经存在了一些基于专利数据的技术创新人才发现方法。例如,文献[3]提出了一种基于合作网络的技术创新人才发现方法,通过网络中不同节点的点度中心度、中间中心度和接近中心度来找出团队中的技术创新人才。文献[4]分析了专利作为学术评价指标的选取,提出将专利的质量、授权状态、有效性以及许可和转让情况等作为评价技术创新人才的指标。文献[5]则构建了企业科技人才评价的指标体系,通过专利申请数量、专利被引次数、平均专利被引次数、著者总数、著者平均专利数等多个因素来评价技术创新人才。
然而,这些方法仅仅从各个特征的角度评估了各个发明人的技术创新实力,而没有给出统一的学习模型来发现专利集合中的技术创新人才。如何综合考虑专利数据中包含的各种专利特征,并建立统一、有效的学习模型来发现专利集合中的技术创新人才,仍是当前面临的一个重要问题。
多层感知机模型是最为常见的深度学习模型之一,它在车牌字符识别[6]、财务风险预警[7]和疾病早期识别[8]、竞争性的协同进化预测[9]等分类、识别和预测问题上得到了广泛的应用,并取得了较好的效果。因此,该模型可以用来构建技术创新人才识别的学习模型,以发现专利集合中的技术创新人才。
基于以上原因,本文在对专利发明人特征进行了充分分析的基础上,提出了一种基于多层感知机模型的技术创新人才发现方法。该方法首先从专利数据中抽取发明人的各个特征,然后基于抽取的发明人特征构建多层感知机模型,并通过训练数据集对该模型中的参数进行学习,最后采用学习所得的多层感知机模型在专利数据集合中准确地发现技术创新人才。
1 相关工作
当前的技术创新人才发现方法大体可以分为两种:一种是通过对人才合作网络中不同节点的中心性指标进行分析,以找出其中的技术创新人才;而另一种方法则通过构建专利指标体系来评估各个人才的技术创新实力。
基于合作网络的方法首先基于科技人才之间的合作关系构建合作网络,然后通过网络中各个节点的点度中心度、中间中心度以及接近中心度等中心性指标来找出其中的技术创新人才。在该方面,文献[10]提出将合作网络中点度中心度和中间中心度都较高的作者作为学术带头人的遴选指标;文献[3]则在构建的发明人合作网络的基础上,综合考虑点度中心度、中间中心度以及接近中心度等指标,以了解各个发明人对团队影响程度的大小,从而确定其中的核心成员。然而,尽管这种方法具有一定的合理性,但该方法仅考虑了人才之间的合作关系的相关特征来发现技术创新人才,技术创新人才识别的查全率与查准率不高,不能准确地评价和发现技术创新人才[11-12]。
与基于合作网络的方法不同,基于专利指标体系的方法则分析了专利数据中包含的一系列专利特征,并构建相应的专利指标体系来评估各个技术人才的创新实力。在该方面,文献[4]分析了专利作为学术评价的指标的选取,提出将专利的质量、授权状态、有效性以及许可和转让情况等作为评价技术创新人才的指标。文献[5]则等以丹麦维斯塔斯风电技术集团公司专利数据为研究样本,构建企业科技人才评价指标体系,通过专利申请数量、专利被引次数、平均专利被引次数、著者总数、著者平均专利数等多个因素来评价各个发明人的技术创新实力。然而,这种方法仅仅从专利特征的角度分析了各个特征对发明人技术创新实力的影响,但却没有给出统一的学习模型来发现专利集合中的技术创新人才。如何综合考虑专利数据中包含的各种专利特征,并构建统一、有效的学习模型来发现专利集合中的技术创新人才,仍是当前面临的一个重要问题。
多层感知机模型是最为常见的深度学习模型之一,它在车牌字符识别、财务风险预警和疾病早期识别、竞争性的协同进化预测等分类、识别和预测问题上得到了广泛的应用,并取得了较好的效果,因此可以用来构建技术创新人才的学习模型,以评估人才的技术创新实力。尽管我们也可以采用传统的机器学习模型(如朴素贝叶斯分类器、支持向量机和决策树等)来发现专利集合中的技术创新人才,但传统的机器学习模型只能基于人工定义的浅层特征用于模型的学习,而多层感知机模型通常具有多个隐藏层,可以抽取深层特征用于模型的学习,其准确率更为精确。因此,本文将采用多层感知机来构建技术创新人才的学习模型,以发现专利集合中的技术创新人才。
2 基于多层感知机的技术创新人才发现方法
基于专利数据的技术创新人才发现即在专利集合中识别技术创新实力较强的发明人。本文提出了一种基于多层感知机的方法来发现专利集合中的技术创新人才,该方法的主要步骤包括发明人特征抽取、多层感知机模型构建与学习以及应用多层感知机模型进行发明人的技术创新实力评估等。
2.1 发明人特征抽取
专利数据中包含了多种不同的特征信息。图1给出了一个专利的部分结构化特征的示例。可以看到,专利中不仅包含专利号、申请日、标题、申请人、发明人等信息,还包含了专利之间的引用信息。其中,发明人为撰写该专利的作者,而申请人则为专利权的所有者,通常为一个企业或组织。除了以上的结构化特征以外,专利数据中还包含了摘要、专利说明书、权利声明等文本信息。

图1 一个专利的部分结构化特征的示例
为了构建多层感知机模型来发现专利集合中的技术创新人才,我们首先抽取了反映各个发明人技术创新实力的专利特征。文中抽取的发明人特征包括专利申请量、专利总被引用量、合作发明人数量、合作发明人的平均专利申请量、申请人维持的专利数量以及所申请专利的文本特征等。
(1) 专利申请量 发明人所申请的专利数量反映了发明人的技术创新能力。一般来说,一个发明人申请的专利数量越多,则该发明人的技术创新实力越强。本文中,发明人所申请的专利数量用PN来表示。
(2) 专利总被引量 专利的被引用次数反映了专利的质量和价值。一个发明人所申请专利的总被引量越高,则该发明人更可能为一个技术创新实力的发明人。对于专利集合中的任意发明人I,其专利总被引量SumCitedNum的计算公式为:
(1)
式中:P(I)为发明人I所申请的专利的集合,CitedNum(pi)为专利pi被引用的次数。
(3)合作发明人数量 发明人之间的合作关系反映了发明人在特定领域中的影响力和技术创新实力。一个发明人所合作的发明人数量越多,则该发明人的影响力越大。本文中,我们将与发明人I存在合作关系的发明人数量用CoNum来表示。
(4) 合作发明人的平均专利申请量 合作发明人的专利申请量反映了所合作发明人的技术创新实力。如果与发明人I存在合作关系的发明人的技术创新实力都较强,则通常发明人I的技术创新能力也较强。我们用与发明人I存在合作关系的所有发明人的平均专利申请量CoPatNum来度量其合作发明人的平均技术创新实力,其计算公式表示为:
(2)
式中:m为与发明人I存在合作关系的发明人的数量,PN(Ii)为与发明人I存在合作关系的第i个发明人的专利申请数量。
(5) 申请人维持的专利数量 在技术创新能力强的企业工作的发明人往往创新能力也很强。因此,发明人所属的企业或组织(通常称为专利的申请人或专利权人)的技术创新实力也是影响发明人技术创新实力的一个重要因素。我们用发明人所属的申请人(即发明人所属的企业或组织)维持的专利数量来度量该申请人的技术创新实力,在文中用AplNum来表示。
(6) 专利文本特征 专利文本中记录了重要的技术情报信息,直接反映了发明人研究主题、研究领域和技术创新实力。技术创新能力较强的发明人,其研究的主题和采用技术手段都较为新颖。而技术创新能力较弱的发明人,其所申请专利的研究主题和技术手段较为普通。因此,专利文本是影响发明人技术创新实力的又一重要因素。本文中,我们根据发明人所申请的专利文档集合,用一组关键词的空间向量来表示发明人的专利文本特征。对于专利集合中的任意发明人I,其专利文本特征表示为(w1,w2,…,wn),其中n为关键词的个数,wi对应于第i个关键词在发明人I中的权重。wi的计算采用类似TF-IDF公式的方法进行度量,即如果某个关键词在一个发明人申请的专利文档中出现的频率高,并且在其他发明人所申请的专利文档中很少出现,则认为此关键词在该发明人的空间向量中的权重越高,其计算公式为:
(3)
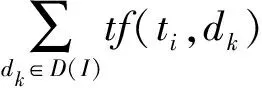
2.2 技术创新人才发现方法
根据以上抽取的发明人特征,我们采用基于多层感知机的技术创新人才发现方法来评估各个发明人的技术创新实力,以发现专利集合中的技术创新人才。如图2所示,该多层感知机模型共包括4层:第一层为输入层,该输入为从专利集合中提取的特征向量,即2.1节中抽取的各个发明人特征的权重;第二、三层为隐藏层,用来从输入层的基本特征中抽取更高层次的特征信息;第四层为输出层,用于输出各个发明人是否为技术创新人才的概率。其中,每一层神经元节点的输出都是前一层神经元节点的函数。

图2 采用的多层感知机模型的网络结构
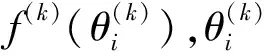
(4)

对于多层感知机模型中的第一至三层,我们选用选用修正线性单元ReLU(Rectified linear unit)作为该层的激活函数,即f(z)=max{0,z}。
对于多层感知机模型中的第四层,由于我们的输出是发明人为技术创新人才的概率,即需要将输出映射到取值范围为(0,1)的区间,因此我们采用sigmoid函数作为本层的激活函数,即:
(5)
模型参数学习:
为了能够基于构建的多层感知机模型来发现专利集合中的技术创新人才,我们首先需要对该多层感知机模型进行学习。多层感知机模型的学习主要是对各层节点之间的连接权重进行学习,其学习过程通常采用基于随机梯度下降原理的误差反向传播(BP)算法[13]来进行实现。即首先给多层感知机的初始权值设置一个小的随机数,然后将训练样本集输入到多层感知机网络,采用基于随机梯度下降原理的误差反向传播(BP)算法对该网络进行训练,调整网络参数,从而使得采用多层感知机模型运算后的实际输出值尽量接近期望输出值。在文中即为使得计算出的发明人为技术创新人才的概率值与发明人是否为技术创新人才的标签尽量接近。我们采用均方误差作为训练过程中的损失函数,该损失函数J(w)可以表达为:
(6)
式中:hw(x(i))是采用文中的多层感知机模型计算出来的第i个发明人为技术创新人才的概率;yi是预先标记好的第i个发明人的标签,用来表示该发明人是否为一个技术创新人才(如果yi=1,表示该发明人是技术创新人才,如果yi=0,表示该发明人是技术创新人才);m为专利集合中发明人的总数量。
通过BP算法,我们可以对多层感知机中的参数进行有效的学习。从而,在测试阶段,我们即可使用训练得到的多层感知机模型来计算各个发明人为技术创新人才的概率。
3 实验结果与分析
为了验证文中所提出方法的有效性,我们将提出的基于多层感知机的技术人才发现方法与文献[3]中的基于合作网络中心度的方法以及传统的机器学习方法(包括支持向量机、朴素贝叶斯和决策树分类算法等)进行了对比。实验中采用的专利数据集为从欧洲专利局Espacenet系统下载的“华为科技有限公司”和“电动汽车”领域的专利数据,两个数据集的细节描述如表1所示。
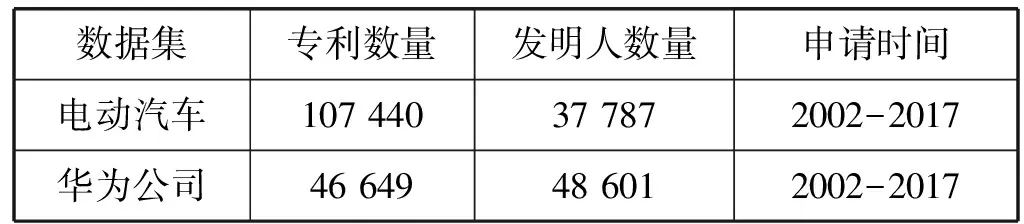
表1 使用的专利数据集的描述
3.1 实验设置
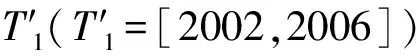

图3 技术创新人才发现方法的实验设置
在测试阶段,同样地,根据基于T2时间间隔中申请的专利集合对各个发明人申请专利的数量进行统计,并将申请专利数量最多的前百分之k个发明人标记为技术创新人才,其他发明人标记为非技术创新人才。然后,我们基于T1时间间隔内申请的专利来抽取各个发明人的特征,采用训练阶段得到的多层感知机模型来计算各个发明人为技术创新人才的概率,并将概率最大的前百分之k个发明人标记为技术创新人才,其他发明人标记为非技术创新人才。最后,我们将基于T1时间间隔内的专利文档计算得到的各个发明人的标签与基于T2时间间隔内的专利文档预先标记的各个发明人的标签进行对比,以验证所提出方法的效果。
3.2 评估方法
我们根据采用文中方法计算得到的发明人标签的准确率来验证所提出方法的效果。该准确率可以用公式表示为:
(7)

3.3 结果与分析
我们从企业(“华为科技有限公司”的专利数据集)和研究领域(“电动汽车”专利数据集)两个维度对文中提出的基于多层感知机的技术人才发现方法进行实证分析,以验证所提出方法的有效性。
表2给出了基于多层感知机的方法(Multi-layer Perceptron,MLP)与基于合作网络中心度的方法(Network Centrality,NC)以及传统的机器学习方法,包括支持向量机(Support Vector Machine,SVM),朴素贝叶斯(Naive Bayes,NB),决策树算法(Decision Tree,DT)等,在“华为科技有限公司”的专利数据集上进行技术创新人才发现的准确率。
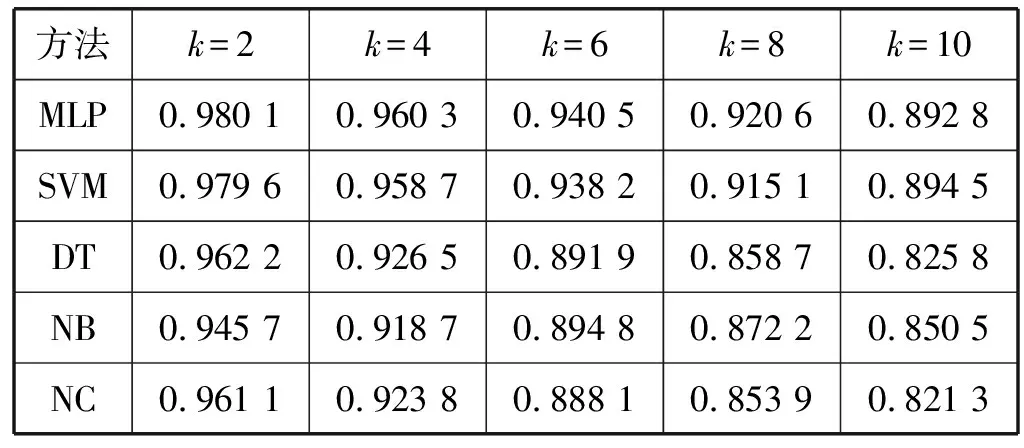
表2 “华为科技有限公司”数据集上各个方法的准确率
在该专利数据集上,我们给出了在不同的k值下五种方法的准确率。其中,k为被标记为技术创新人才的发明人在整个发明人集合中的所占的比例。
我们首先分析了同一种方法在不同k值下的准确率变化。由3.1节可知,当k较小时,采用文中方法标记为技术创新人才的数量和预先标记的技术创新人才的数量都较少,而同时被标记为非技术创新人才的数量都较多(即两种方式都有大量的发明人被标记为非技术创新人才)。因此,对于任意发明人,其通过文中方法计算得到的标签值与预先标记的标签值有较大的概率相等(即都有较大的概率都被标记为非技术创新人才)。根据式(7)可知,此时各个方法的准确率一般都较高;而当k增大时,同时被标记为非技术创新人才的数量减少,其通过文中方法计算得到的标签值与预先标记的标签值相等的概率也相应的减小。此时,各个方法的准确率一般也会随之下降。从表2中各个方法的准确率可以看到,同一种方法的准确率都随着k值的增大而减小。
我们也比较了不同方法在同一k值下的准确率。可以看到,在表2中,当k=2,4,6,8,10时,采用基于合作网络中心度的方法和朴素贝叶斯方法和决策树方法计算得到的技术创新人才的准确率均低于文中提出的基于多层感知机的方法。而对于采用支持向量机的方法,当k=2,4,6,8时,该方法的准确率同样低于基于多层感知机的方法,仅在k=10时,两个方法的准确率基本相等。由此可知,在“华为科技有限公司”的专利数据集上,采用多层感知机的方法进行技术创新人才发现的准确率在绝大多数情况下都高于采用合作网络中心度的方法和传统的机器学习方法。即相对于其他方法,文中所提出的基于多层感知机的技术创新人才发现方法具有更好的效果。
在表3中,我们给出了在“电动汽车”专利数据集上五种方法的准确率。可以看到,对于同一种方法在不同k值下的准确率变化趋势上,同表2中的结果,大多数方法的有效性都随着k值的增大而减小,仅朴素贝叶斯方法在k=10时,其准确率与k=8时相比略有上升。而对于各个方法在同一k值下的准确率对比上,当k=2,4,6,8,10时,采用文中提出的基于多层感知机的技术人才发现方法的准确率均高于基于合作网络中心度的方法、朴素贝叶斯方法和决策树算法。即在不同的k值下,采用多层感知机的技术创新人才发现方法比以上三种方法具有更好的效果。对于采用支持向量机的方法,当k=2,4时,该方法的准确率与基于多层感知机的方法相等;当k=6,10时,基于多层感知机的方法的准确率略低于采用支持向量机的方法;而当k=8时,基于多层感知机的方法的准确率略高于采用支持向量机的方法。即在总体上,采用基于多层感知机的方法进行技术创新人才发现的准确率与采用支持向量机的方法总体上相差不多。总而言之,在“电动汽车”专利数据集上,基于多层感知机的技术人才发现方法的效果仍好于基于合作网络中心度的方法和大多数传统的机器学习方法。

表3 “电动汽车”数据集上各个方法的准确率
由以上两个数据集上各个方法的准确率对比可以看出,文中提出的基于多层感知机的技术创新人才发现方法在绝大多数情况下都比其他方法具有更好的判别效果。产生该结果的原因是,对于基于合作网络中心度的方法,该方法仅仅考虑了发明人之间的合作关系对发明人技术创新实力的影响,而忽略了发明人的其他专利特征,如专利申请量、专利总被引量、合作发明人的平均专利申请量等,造成该方法的效果不佳。而对于传统的机器学习方法,如朴素贝叶斯,支持向量机和决策树算法等,尽管综合考虑了发明人的各种专利特征,并构建了相应的机器学习模型用于技术创新人才的识别,但这些方法只能基于人工定义的浅层专利特征用于模型的学习,其准确率仍有待提高。而文中采用的多层感知机模型则具有多个隐藏层,可以从人工定义的浅层专利特征中进一步抽取深层的特征用于模型的学习,因此采用多层感知机模型来进行技术创新人才发现的结果更为精确。综上所述,在技术创新人才发现的问题上,与已有的技术创新人才方法相比,基于多层感知机的技术创新人才发现方法具有更好的判别效果。
4 结 语
本文提出了一种基于多层感知机的技术创新人才发现方法,该方法不仅抽取了反映发明人技术创新实力的多个发明人特征,而且构建了统一的模型对各个发明人的技术创新实力进行评估。与传统的机器学习方法只能通过人工定义的浅层特征进行模型学习的方式相比,文中提出的基于多层感知机的方法可以通过加入多个隐藏层来抽取更为深层的特征用于技术创新人才发现模型的学习,在技术创新人才发现问题上具有更好的效果。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
法制博览(2020年36期)2020-11-30
中外文摘(2020年18期)2020-09-30
赢未来(2019年29期)2019-12-07
金桥(2018年1期)2018-09-28
科学与财富(2018年32期)2018-01-02
中外玩具制造(2017年12期)2017-12-08
