
基于评论数据的酒店服务质量的细粒度分析
2019-07-15 11:18孙长伟任宗来杨俊杰庞坤亮
计算机应用与软件 2019年7期
孙长伟 任宗来 杨俊杰 庞坤亮
(国网中兴有限公司 北京 100083)
0 引 言
目前,在电商服务网站上存在大量客户生成的数据,主要是评论数据,这些用户生成的评论数据已经成为消费者对商家的服务和商品进行隐式反馈的主要形式。针对商品的评论数据,不仅能帮助潜在消费者进行购买分析,还能帮助商家分析其提供的商品和服务的优缺点,进行优化决策,以便进一步提高其产品或服务的质量。在这方面,已经有大量研究得出结论:在线评论数据能显著地决定商品的销售情况和用户的购买意愿[1-2]。例如:研究表明网上关于书籍的评论能够对书籍的销售情况产生较大影响。在线评论具有多种形式,不仅有如“投票数量”、“打分”和“用户参与评论的数量”等数值属性[3-4],还有如“用户可读程度”和“文字量”等文本属性[5],所有这些影响因子都有可能影响用户的购买决策。目前,研究人员都较多地关注在如何更好地利用在线评论的数值评分[6-7],而研究如何更好地利用评论文本内容的工作相对较少[8-9]。
酒店作为一种特殊的商品,更多的是一种服务,可以通过问卷调查来获取用户的体验反馈。与传统商品不同的是,传统商品坏了可以有售后或维修服务,商家也能及时获得产品优缺点的反馈。然而,酒店这种特殊商品其获得用户反馈特别困难,周期特别长。幸运的是,由于电子商务的发展,目前绝大多数的酒店都已经上线,且具有大量的用户评论,依据这些评论,可以及时地对酒店服务进行分析,这有利于用户决策和帮助酒店及时提升自身服务质量。目前,已经有部分研究开始通过酒店评论数据去评价酒店服务质量,但已有工作粒度较粗,很难分析出酒店的细分服务质量好与不好。
本文将通过细粒度的情感分析方法,对酒店的各个细分服务进行评价,从而使得用户或酒店清晰知道细分服务的质量,为决策提供坚实的论据。
1 相关研究
1.1 评论内容对满意度影响的研究
基于在线用户生成的评论数据去研究酒店特征对客户满意度的影响,主要有基于领域专家意见的研究方法、基于语法的研究方法和基于模型分析的研究方法等三种研究方法。
(1) 基于领域专家意见的研究方法:主要根据酒店领域专家的意见对酒店特征进行筛选和评价。这类方法的缺点是专家意见难以全面反映消费者的真实体验,同时,专家意见带有较强的主观性色彩,存在偏见[8-9]。
(2) 基于语法的研究方法:主要假设拥有越多形容词修饰的特征词,这些特征就越重要。因此,该类方法主要依赖句法依存关系去识别出特征词的起到修饰作用的形容词个数,然后通过形容词的聚类,统计计算出判别特征的重要度[10-11]。由于方法依赖于形容词个数,因此应用范围受限。
(3) 基于模型分析的研究方法:主要通过机器学习模型从大量数据中统计学习出特征与目标之间的关系。这类方法由于在大量数据上进行学习,因此避免了主观因素干扰,同时具有较强的普遍适用性[12-16]。例如,文献[13]通过模型探索了情感极性对用户消费意愿的影响,该方法由于仅仅考虑情感极性而没有考虑情感的强度,导致结果并不令人满意。文献[14]提出首先识别出最频繁出现的名词,然后通过自然语言处理技术自动识别出产品的特征属性,同时采用近义词扩充特征属性进而提升了效果。文献[15]通过把亚马逊的相机产品对应的评论数据作为研究对象,采用计量模型的方法分析了消费者的购买意愿与产品特征评价的关系。
本文借鉴文献[15]的研究思路,结合酒店特征情感和分类模型,细粒度地分析了酒店服务类型,从而可以知道消费者的满意度与酒店特征评价之间关系。
1.2 情感分析
情感分析是指对文本数据进行情感极性分析,判断其情感极性是属于“积极、消极或中立”中的哪一种,或判断用户的观点是“赞同”或“反对”。这是目前NLP领域非常重要的研究方向之一[17]。情感分析技术已经大量地在很多领域或场景中使用[18-21]。例如:在2010年,文献[18]就开始运用情感分析技术对评论数据进行分析从而可以进行商品的排序;Tumasjan等[19]在2011年在推特数据上进行情感分析用于对政治选举的预计,也有研究在评论(Movie reviews)及Blog文本数据上进行情感分析以便预测电影销售情况[20-21]。为了对特征的情感进行预测,Liu等[15]提出的特征情感预测模型先辨别出评论数据中商品的特有特征,然后为各个特征识别出数据的情感极性。还有研究通过频繁名词挖掘方法识别出相关的特征,然后为每个特征计算得到情感分数,可以为城市的各个服务行业构建出观点挖掘系统,从而为商家提供决策依据[22-23]。本文将采用基于词典的情感分析方法[24-27],计算得到酒店细粒度服务特征的情感分数,为后面细粒度服务分析提供基础。
2 融入Word Embedding特征的分类方法
Word Embedding作为一种语义表示新方法,能把词通过低纬向量进行表示,从而使得词之间的相似性可以通过向量操作很简单地计算出来。本文利用开源的向量生成工具(Word2Vec)将各个词全部映射到一个低维向量空间,通常为150或300维度,从而通过计算两个向量的相似度能够表示所对应文本的语义相似程度[28]。具体来说,先根据Word2Vec工具获得评论数据所对应3大类各自的特征维度,然后识别出有效特征,通过情感分析方法去获得对应的情感分数。为了识别出特征,本文主要通过人工去标记特征词,再结合酒店领域的背景知识去决定所属大类,例如:酒店评论“酒店很干净”,通过各个类别所出现的特征词,可将其标为“酒店设施”类别;又如评论“酒店在市区,交通很方便”,通过领域背景知识可将其归为“交通情况”类别。为了实现上述设想,本文通过图1所示的框架进行研究。
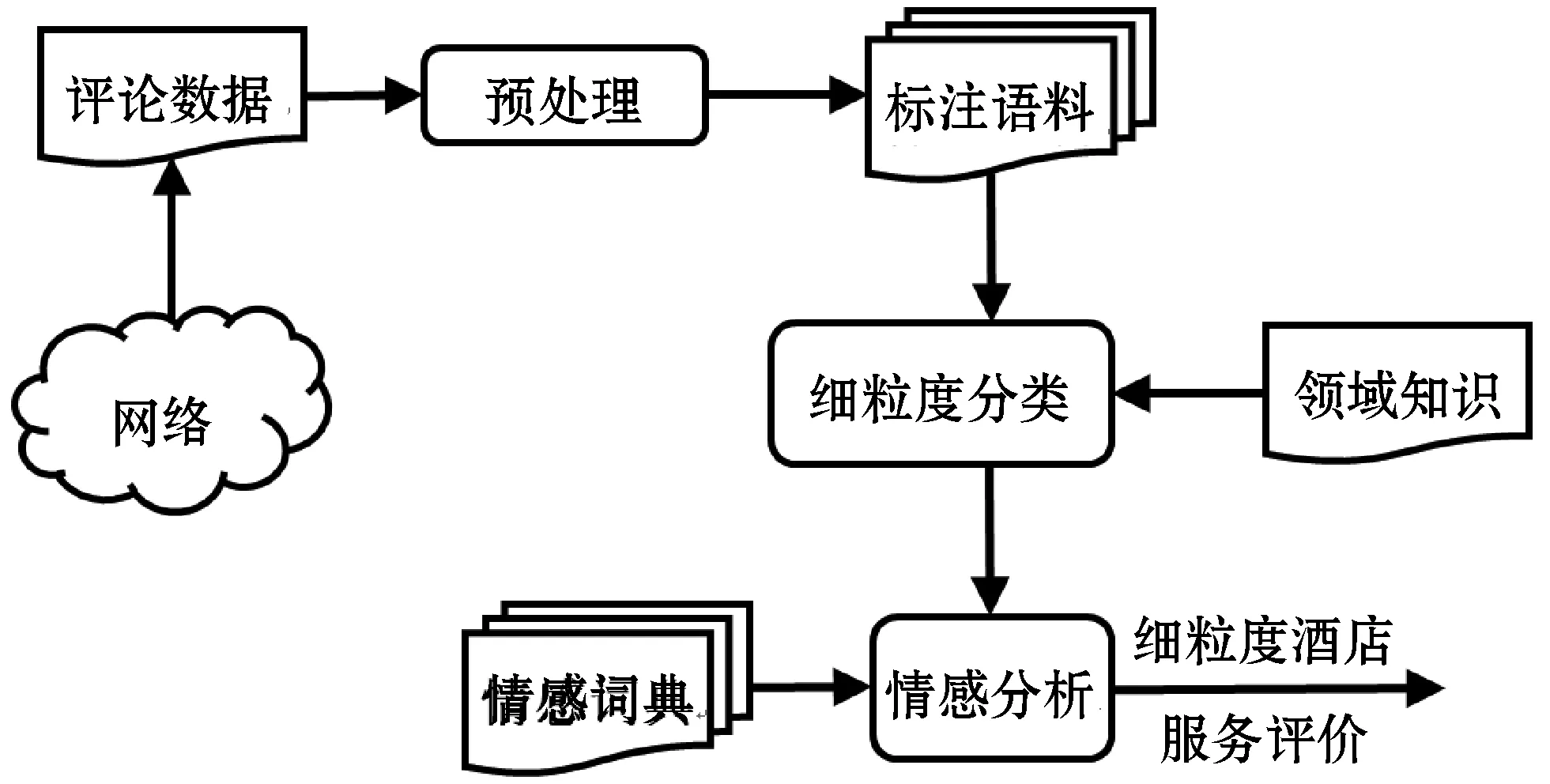
图1 研究框架
2.1 酒店细粒度服务
为了针对酒店评论数据进行细粒度挖掘,我们对评论中可能针对的酒店服务进行了细粒度的分析,如表1所示。主要从酒店设施、服务和周遭环境三个方面分别进行细分,体现了一家酒店的主要服务细类。

表1 酒店服务的细粒度分类
2.2 预处理
对于酒店评论数据,按句子进行分词和去除停用词,包括连词、介词以及人称代词等。这里保留按照句子进行索引和存储,即以句子为后续分类和情感分析处理方法的基本单元。
2.3 融入Word Embedding特征的分类
为了对数据进行细粒度分类,需要标注数据、选择合适的特征和分类算法,下面分别对这三方面进行论述:
(1) 数据标注 为了将酒店评论数据分成句子,然后运用分类算法将句子进行分类。本文首先不仅根据标点符号“,、.、!、”等来区分,还按照名词实体作为区分点,例如“… 热水充足,空调给力,但wifi一般,甚至是不够好,门口就是58路…”将被分为“热水充足”“空调给力”“但wifi一般,甚至是不够好”“门口就是58路”等短句子。然后,去掉完全没有出现积极或消极情感词的客观句,如“两个大人一个小孩”,接着去掉未包含酒店特征词的句子,如“四合轩老北京菜 味道正宗 一个人干掉半只烤鸭很过瘾”。通过对10 000条评论数据进行人工标注,平均评论数据有11个句子,共产生了110 326的标注句子。标注的时候将进行两个层次标注,首先是针对大类进行标注,主要区分评论句子是酒店设施、服务、周遭环境和其他四大类中的哪一类,“其他”类别指与酒店服务类别无关的句子;其次,对句子进行细粒度标注,标明是否是各个大类中的一个细类。
(2) 特征选择 为了准确地对酒店评论中的句子进行细粒度分类,本文拟采用如下特征去表示数据:
• 词是否出现,0/1特征。
• 词的tf-idf特征:词的词频(tf)和在数据集合中的频率(df)是衡量词重要性的重要方式,tf×idf(tf-idf)综合衡量了词的重要性。
• 利用Word2Vec工具对本文爬取的 7 183 763条酒店评论数据进行训练(参数向量维度是150,训练窗口为10),得到所有词的词向量。通过该训练好的词向量库,采用取平均值的方式计算每条数据记录的向量表示,计算该向量与所要分类的类别的距离,形成距离向量,维度为所要分类的类别个数。
• 从酒店评论标注数据中依据词频为每个类别抽取出相关词,构建了关联字典;对评论数据进行分词,判断是否有词汇属于某个类别对应的集合,形成判断向量,向量的维度为所要分类的类别个数。
(3) 分类算法 为了选择合适的分类算法,本文拟选择朴素贝叶斯和支持向量机两种分类器进行分类。
① 朴素贝叶斯:
假设有K个类别的数据,朴素贝叶斯根据下式去判断一个数据x=(x1,x2,…,xn)所属的类别:
(1)
② 支持向量机:
给定训练数据集合{(xi,yi);i=1,2,…,N},支持向量机的核心思想是认为选择最大化边白的曲面可以最大可能地区分开数据点,如图2所示。
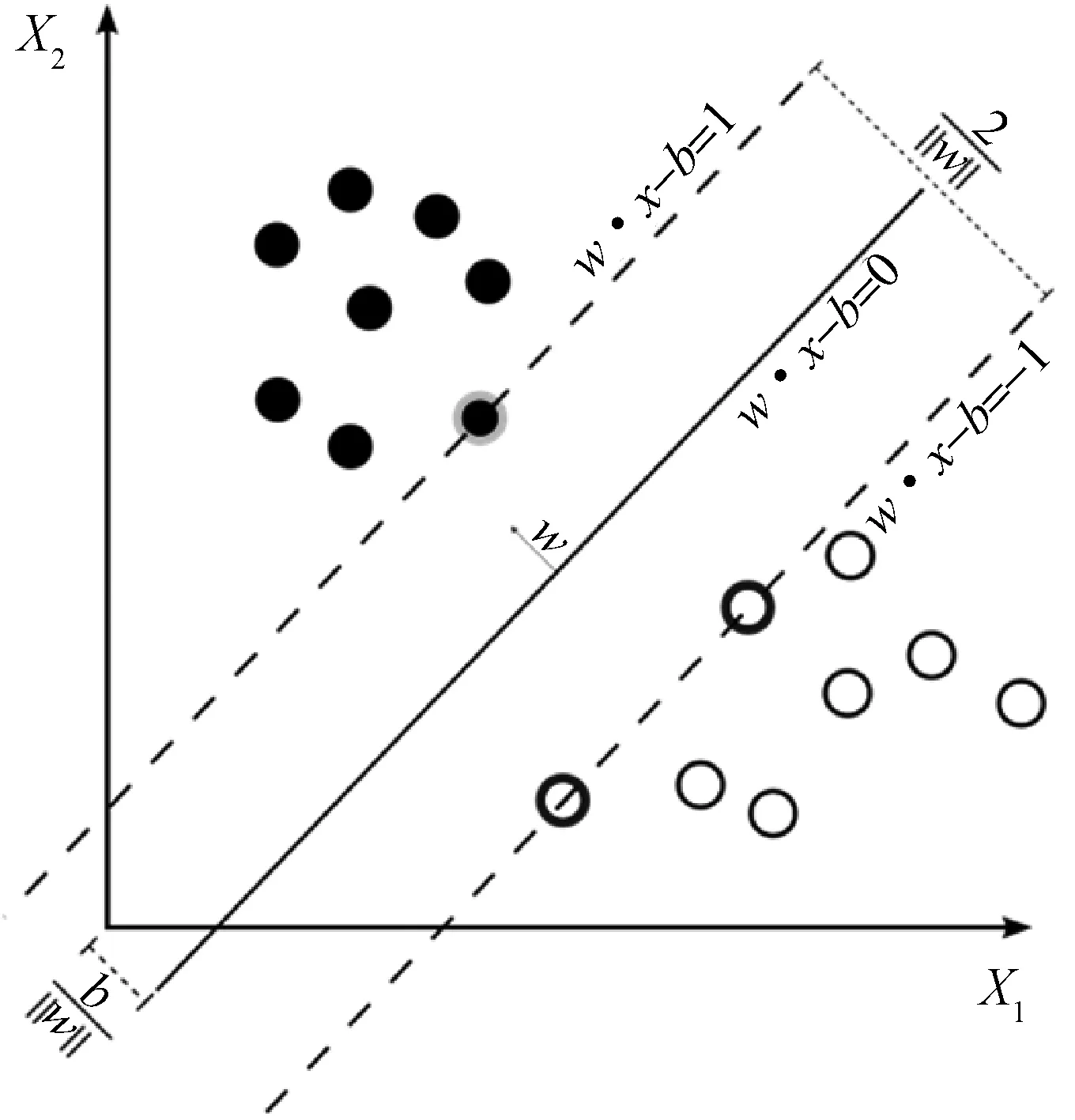
图2 支持向量机算法的核心原理
为了求取最大边白(Margin),可以归结为下述的优化问题:
(2)
s.t.yi(ωTxi+b)≥1i=1,2,…,m
通过求取该优化问题,可以把最大边白曲面的参数求取出来,从而实现分类功能。
由于我们的分类是二级分类,本文将首先对大类进行分类,然后再对细分类别进行分类,在实验部分将详细展示分类效果。
2.4 基于词典的情感分析

(3)
(4)
(5)
式中:WCi是句子Si的词个数。而对某个类别的情感分析通过下式来计算:
Ci=∑Si
(6)
式(6)计算之后所得的情感分数就是消费者群体对相应酒店某个类别的细粒度服务的情感评价。因此,通过汇总酒店的各个类别的情感分数,得到酒店细粒度服务的情感矩阵,由此可知消费者对于特定酒店三大类及其22个细粒度服务的情感分数。
3 实 验
3.1 数 据
从2018年1月至2月,通过对携程和去哪儿网站的酒店目录进行数据爬取,抓取了包括酒店名字和对应的评论数据,评论数据包括用户评分、评论编号、标题和评论正文。经过去除噪音、删除无效数据等数据清洗操作最终整理得到632家酒店和总共7 183 763条酒店评论数据。同时,针对所有酒店评论数据通过Word2Vec工具进行训练(150维,窗口大小设置为10),得到每个词对应的向量用于后续分类等分析模块中。最后,还在7 183 763条酒店评论数据集中随机选取,然后人工标注了10 000条评论数据。通过统计,评论数据平均有11个句子,因此共产生了110 326的标注句子,具体的标注过程见3.3节。
3.2 分类效果评价
对大类别和小类别分别采用两个分类算法进行分类,每次分类都将数据集合按照80%~20%进行划分,80%的部分作为训练数据,而20%的部分作为测试数据,实验结果如表2所示。表中所有结果均是采用10倍交叉验证所获得的平均值。
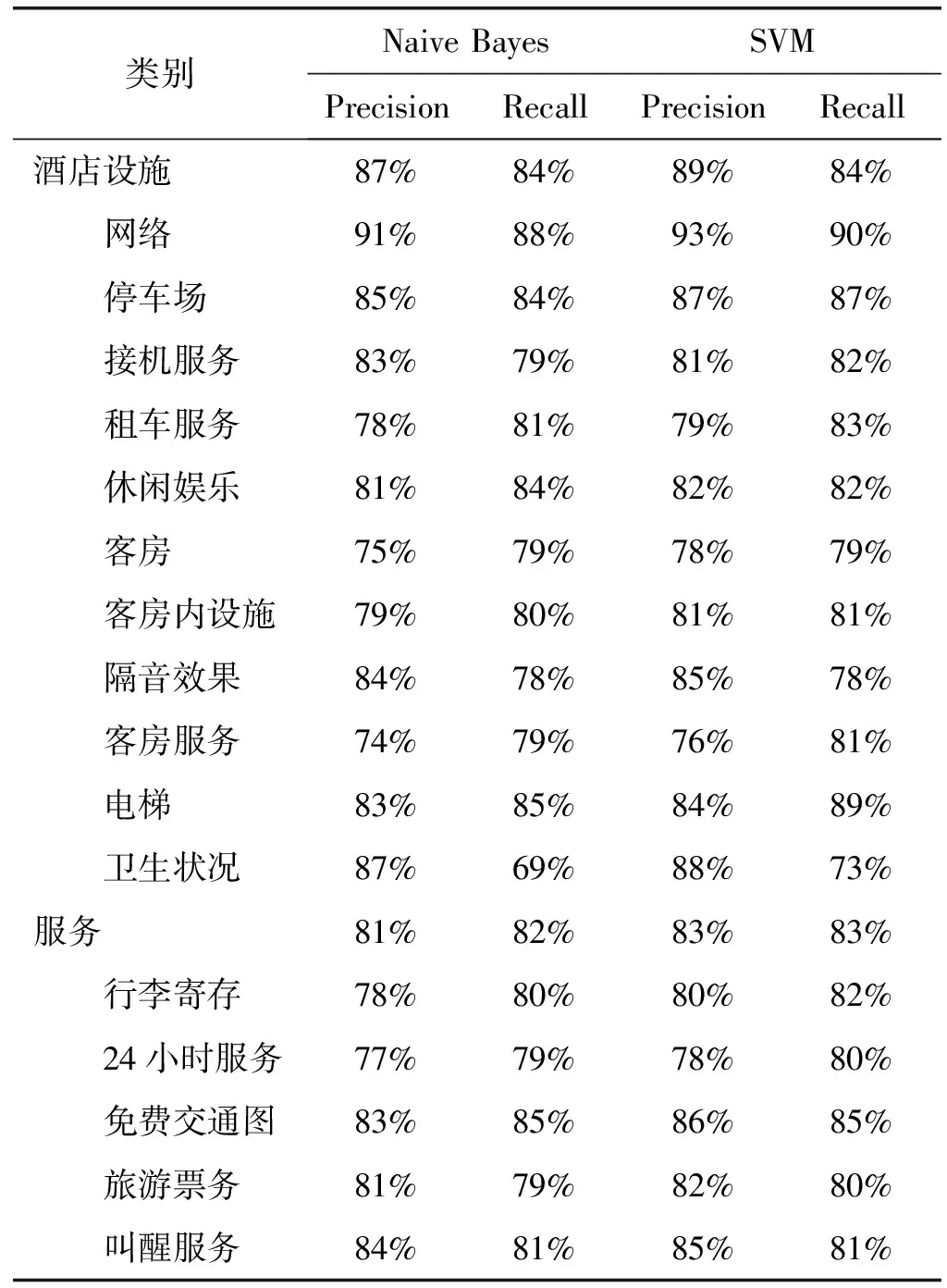
表2 基于机器学习的特征分类效果比较
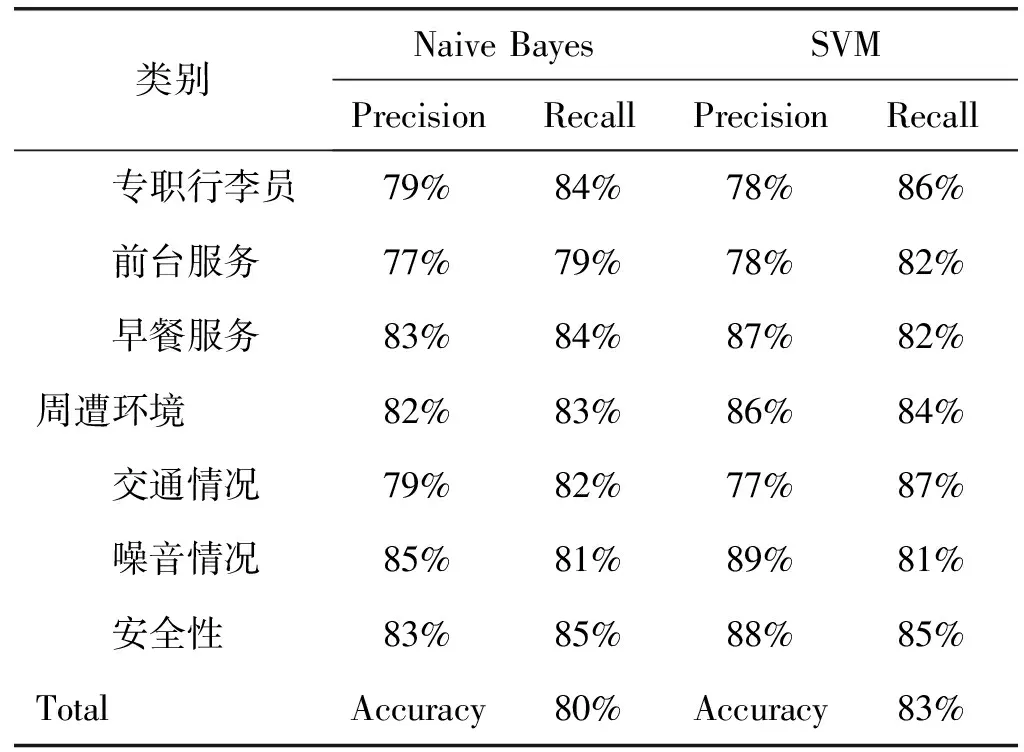
续表2
从表2中可以看出,支持向量机比朴素贝叶斯取得了更好的实验结果,后续将以支持向量机训练得到的分类模型作为后续模块的支撑。
为了分析所选特征所起到的作用,本文逐个减去某特征然后进行实验,采用Precision评价指标,限于篇幅,图3中只展示了一个大类和一个小类的实验结果,在其他类别上的实验结果的趋势类似。
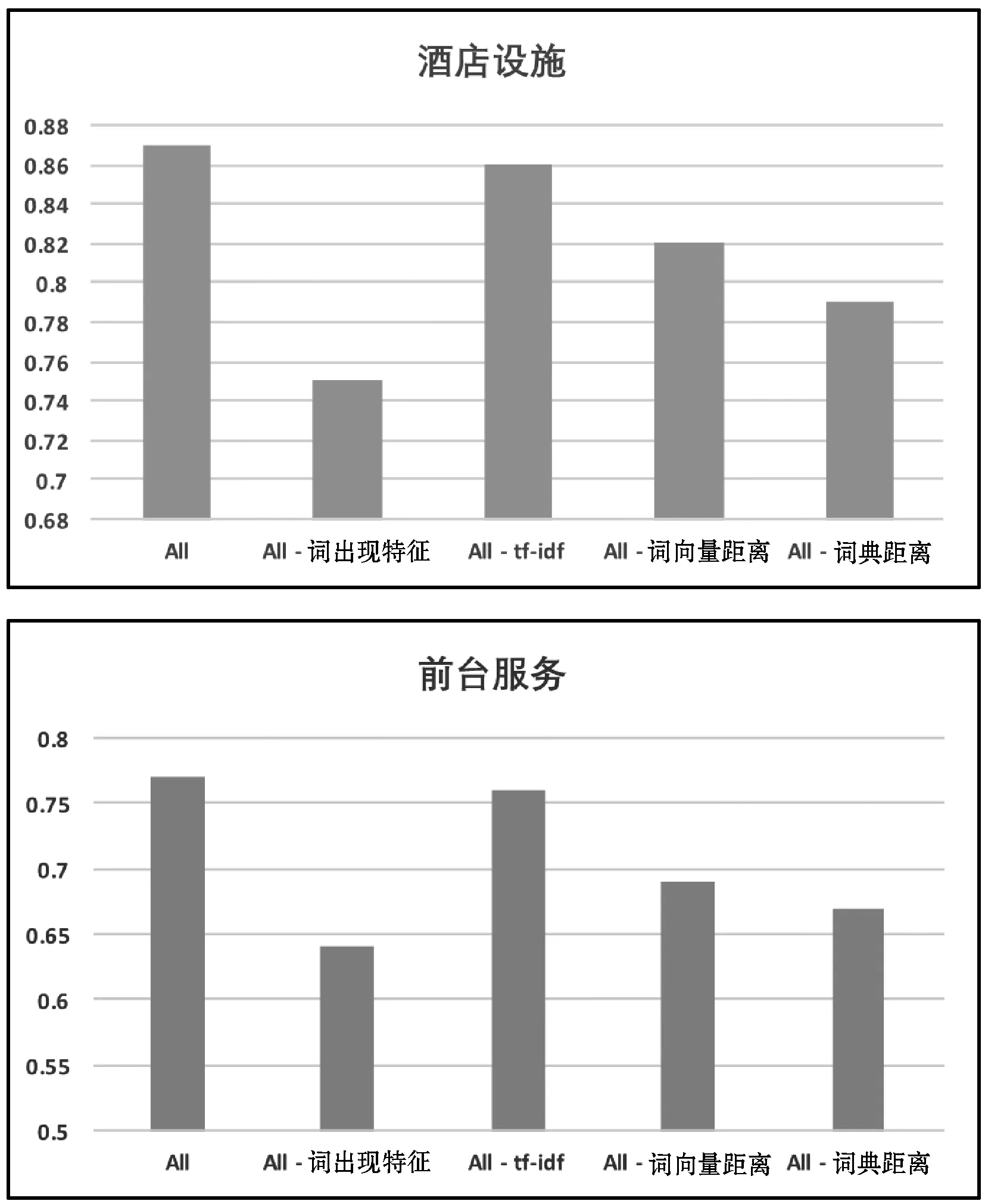
图3 大类“酒店设施”和小类“前台服务”在不同特征上的Precision值
该实验结果表明,tf-idf特征几乎没用,经过分析,这很可能是由于句子太短,词频几乎没有差别;最有用的特征是“词是否出现”这个特征;同时,可以看到,本文提出的两个新特征——词向量距离和词典距离特征也起到了重要作用。
3.3 细粒度情感分析
为了识别出消费者对酒店的服务的在意程度,本文分别对各个服务类别的评论极性进行了统计分析,结果如表3所示。可以看出,顾客对每个类别的情感表达有正有负,其中:客房服务的最小值为-4.02,最大值为12.42,不管是从消极情感的强度还是积极情感的强度,其绝对值均是所有服务中最大的,表明情感最强烈;前台服务的最小值为-4.82,最大值为14.37,情感强烈程度仅次于客房服务。在大类中,消费者首先重视的是酒店设施,然后是周遭环境,再次是服务,这和一般人的直觉有些不一致。通常会认为服务应该是最受顾客关心的,经过仔细思考,其实这个结果是合理的,设想顾客到了酒店之后如果酒店设施完备,体验极佳,其实顾客较少需要酒店人员的服务;反之,如果酒店设施问题很大,再好的服务都不会使得顾客满意。
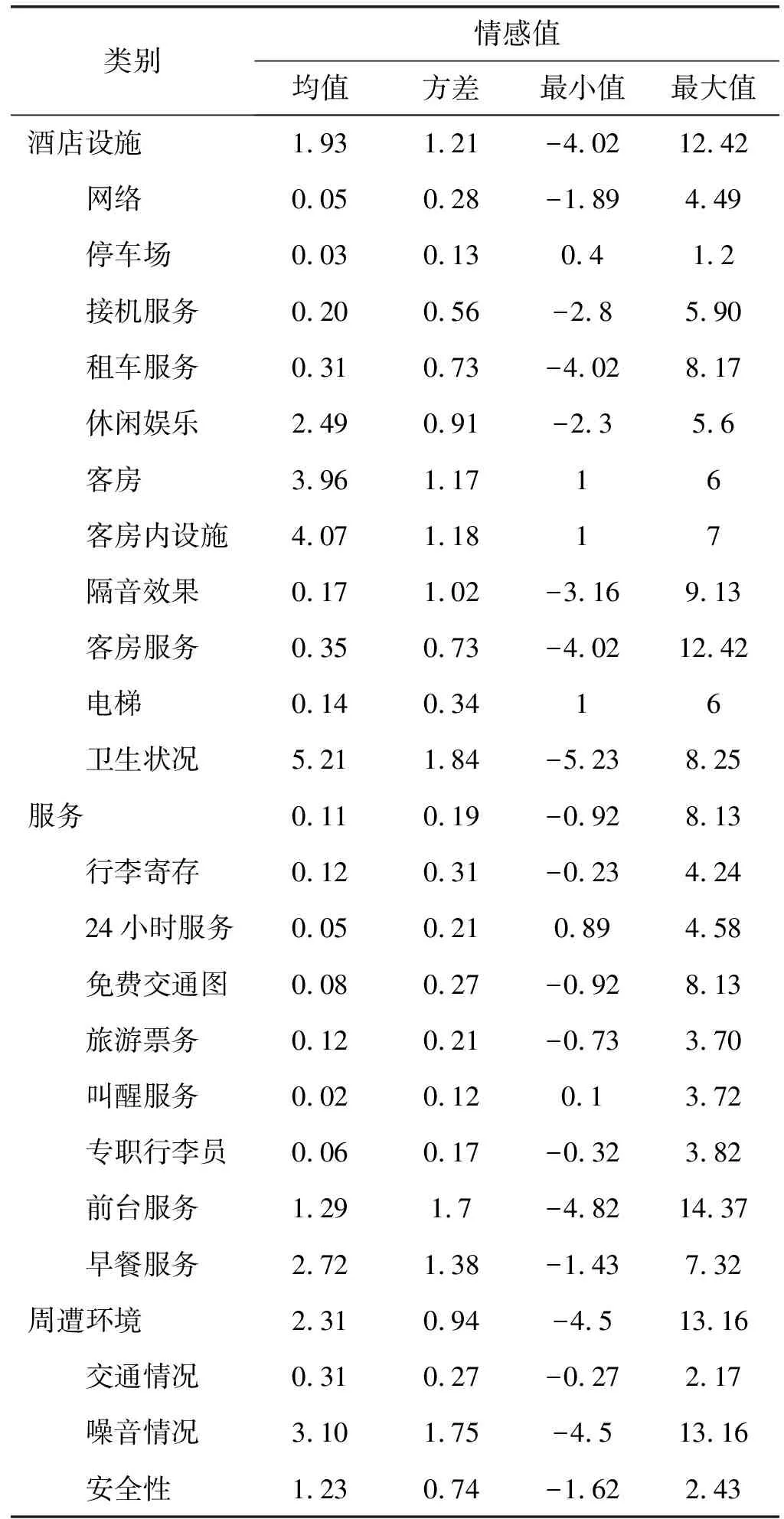
表3 细粒度情感分析结果
3.4 案例研究
从本文的情感分数计算方法(式(3)-式(6))可知,所计算出的情感分数理论上范围在(-∞,+∞),但是一个句子的词总数是有限的,因此,情感分数一般不会太大和太小。另外,情感分数的绝对值只表明用户对于该项的情感强烈程度,绝对值越大表明用户正面或负面的情感越强烈,反之越弱。
本节将展示一些分析案例来表明所提出的细粒度情感分析对于酒店的评估能起到重要支撑作用。从表4中的案例可以看出,该酒店部分服务没有停车场、接机和租车等服务,因此表格中这些服务的评价和情感分数为空。同时,也可以看出该酒店在卫生状况、前台服务和环境噪音情况等服务类别的情感分数分别是6.32、9.23和7.92,表明该酒店前台服务比较好,卫生情况也比较良好,同时整个酒店外界噪音较小。而该酒店在客房内设施的情感分数只有1.73,仔细查看评论“就是洗衣机用不了;电动的窗帘一个是坏了,关不上;就是卫生间的洁具相对来说感觉有点旧了,用起来不是很方便”,可知该酒店的哪些设施让用户感觉不好,有待提升。在房间隔音效果只取得了3.2的分数,仔细查看评论“房间隔音不好;环境一般,有吵声,很影响休息”,这表明该酒店隔音效果不好,有待提升。通过该案例的分析,表明本文提出的方法可以为酒店管理层提供一种快速的细粒度酒店质量评估,提升酒店服务水平。

表4 案例分析(犀客空间(北京国贸和乔丽致店))

续表4
4 结 语
本文针对目前酒店评论数据分析方法粒度较粗、缺乏细粒度情感分析的问题,首先对评论数据进行了细粒度分类,然后通过基于词典的情感分析方法对酒店评论进行极性判断,从而获得用户对酒店服务的细粒度情感评价。本文方法能让酒店管理层快速全面了解酒店服务质量情况,有效提升了酒店管理效率和服务水平,推动了酒店管理水平的提升。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
科技资讯(2017年7期)2017-05-06
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
