
基于卷积神经网络的脐橙果梗脐部检测算法及应用
2019-07-15 11:18杜雨亭李功燕许绍云
计算机应用与软件 2019年7期
杜雨亭 李功燕 许绍云
1(中国科学院大学微电子学院 北京 100049)2(北京微电子研究所 北京 100029)
0 引 言
我国是农业大国,也是水果生产大国,果品产业是我国种植业中位列粮食蔬菜之后的第三大产业,是我国农村经济发展的支柱产业之一,也是农民就业增收的重要途径。柑橘包括柑、橘、橙等,是世界第一大水果,占水果总量的1/4。2009年我国柑橘总产量是2 521.1万吨,但出口量仅占3.9%。一个关键原因就是我国水果商品化处理水平低,水果分级是其商品化处理的重要环节。
在水果分级中,水果表面瑕疵是作为分级的决定性判别标准之一,而瑕疵识别中,脐橙的果梗、脐部不能算作瑕疵,因此需要准确识别从瑕疵中去除。果梗、脐部仅通过颜色、形状等方法难以与瑕疵区分,李江波[1]采用直接利用硬件设备避免脐橙的果梗、脐部不会出现的所拍摄的图片中,这样对水果的固定要求高,拍摄面会有损失。胡焕发等[2]直接利用颜色分量区分果梗与瑕疵,该方法适用性较窄,并且最容易与瑕疵混淆的脐部没有被涉及。多数脐橙瑕疵识别相关研究都没有对脐橙的果梗、脐部进行识别,脐橙果梗、脐部识别是一个难点问题。相比于传统方法,近年兴起的卷积神经网络(CNN)能够直接从数据中自我学习特征,具有泛化性能好,适应性强的特点,能够很好地完成物体识别检测任务,已用于水果识别[2]和病虫害的检测[4]。朱冬梅等[5]直接利用卷积神经网络对脐橙进行分类,该方法利用了卷积神经网络能有学习深度特征的优点,由于脐橙是自然产物,直接对脐橙分类在制作数据集时难以定义分别数目,并且分级指标应该按照客户要求定义。Iandola等[6]提出的DenseNet是目前效果最好的特征提取网络,使用跳跃式卷积连接方式参数被重复利用,减少了网络参数量,提升网络训练效率。Ren等[7]提出基于CNN的Faster RCNN物体检测方法,该方法基于两步训练方法,首先利用RPN(Regional proposal network)网络提取覆盖所有物体的默认检测框,然后使用另一个卷积神经网络训练得到物体位置和坐标。该方法识别准确率高,但是时间效率极差,达不到实时要求。Redmon等[8]提出基于CNN的YOLO(You only look once)物体检测方法,该方法实时检测物体,是端对端的检测方法,按照7×7大小划分图片,每个划分的图片部分为默认检测框,对小物体检测效率极差,物体检测准确度效果较差。Liu等[9]提出基于CNN的SSD(single shot detector)深度学习物体检测方法,该方法在多尺度卷积层上设置不同大小默认提取框,兼顾速度的同时提高了检测的精度,但是针对本文问题模型参数冗余,时间达不到要求。Shen等[10]提取基于DenseNet的Dsod物体检测方法,该方法使用dense结构设计物体检测框架,使得检测准确度有所提升,但是时间效率较差。
本文以脐橙果梗、脐部为研究目标,对自然环境下采集的脐橙进行识别检测研究,提出结合注意力机制以SSD为基本框架的改进模型,以达到实时准确检测脐橙果梗、脐部的目的。
1 神经网络模型
为了实时准确检测脐橙果梗、脐部,利用较少的参数以及计算量在保持检测精度的同时提高时间性能,设计如图1所示网络模型。本文模型在衡量时间效率以及准确度的基础上,使用SSD为基本框架,借鉴DSOD网络模型物体识别准确度高的优势,简化DSOD模型,在该框架基础上提升物体检测时间,为进一步提升准确度,加入注意力机制。本文网络模型相比其他检测框架,专门为脐橙数据集设计,根据脐橙果梗、脐部实际大小设计检测层的层数,网络结构设计加入更多检测实时性的考虑,预测时,加入Merge BN操作进一步提升时间效率。
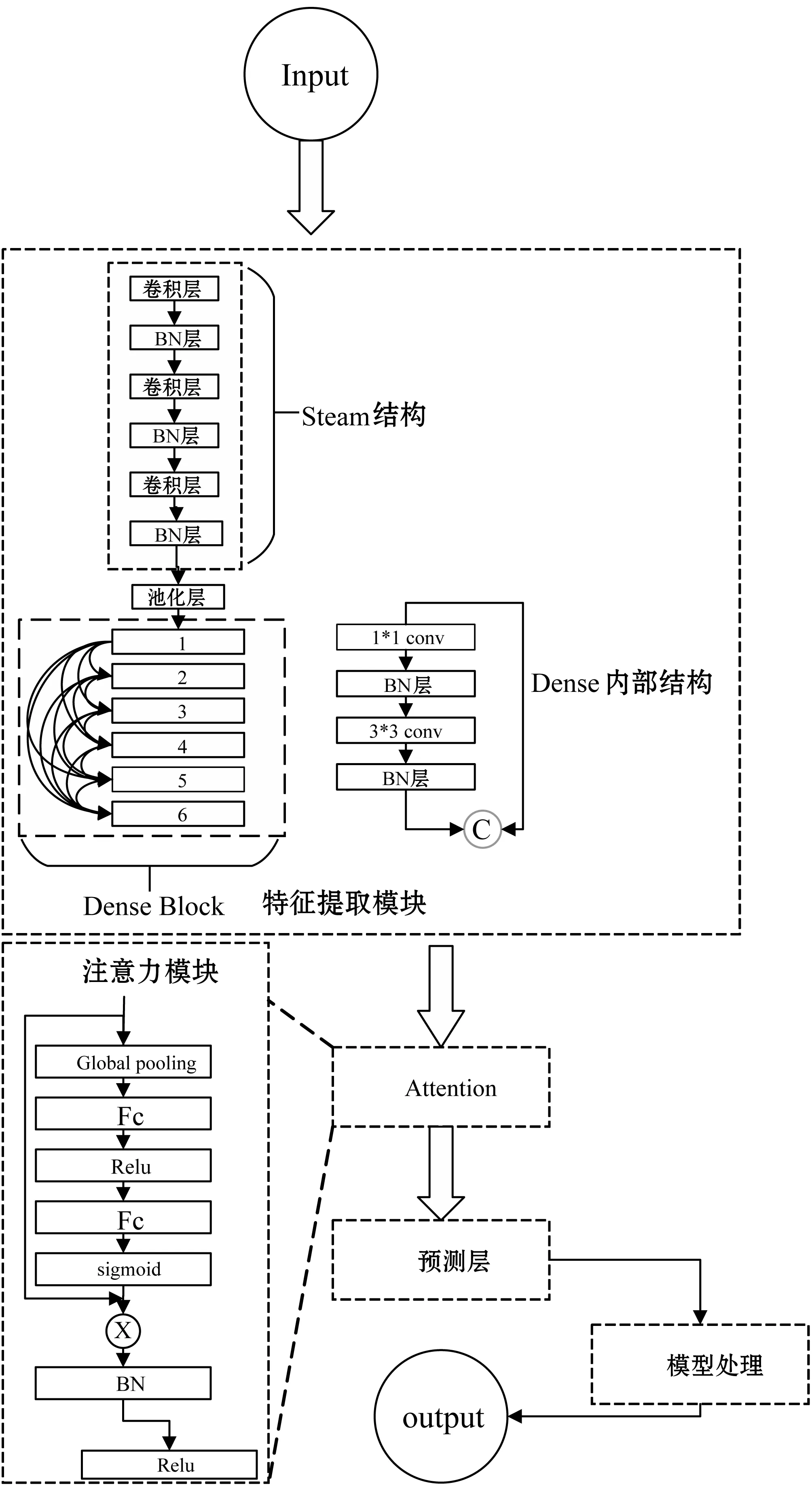
图1 模型结构图
1.1 特征提取网络
本网络结构的特征提取层利用线性结构与跳跃式结构融合的方式共同提取特征。首先,使用一个线性堆叠的steam结构,利用3个3×3卷积,进行初步的特征提取。多个3×3的卷积既能减少卷积的参数量,又能与7×7卷积有相同的感受野,是目前特征提取卷积层最常用的大小。后接一个6层的Dense Block进一步特征提取,Dense Block的特点是网络中每一层都直接与前面层相连接,实现特征的重复利用。这样的设计使得Dense Block结构比其他网络结构效率更高,它每一层只需要学习很少的特征,参数量和计算量显著减少。Dense Block内部结构是采用一个1×1卷积加上一个3×3卷积,先用1×1卷积的作用是进行维度缩小,然后利用3×3卷积进行特征提取。此结构降低了计算量以及参数量,有利于网络快速训练以及模型简化。网络结构见图1特征提取模块,特征提取层网络的参数设计结构如表1所示。
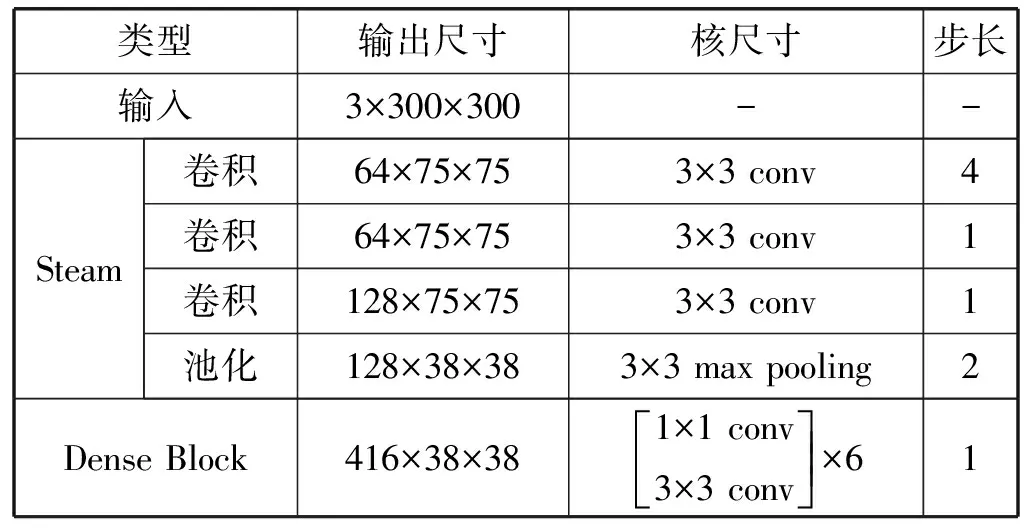
表1 特征提取网络参数表
在参数设计上,在第一层使用步长为4,直接将300×300的输入尺寸降低为75×75,接下来的卷积层提取浅层特征时,计算量和参数量都比较小,池化处理后的特征层作为多尺度预测的第一层,用最小的参数量和计算量实现浅层特征预测的目的。
1.2 注意力结构
注意力是一个非常常见的,但是又容易被忽略的东西。在人眼的视觉系统中,人会把注意力放在自己感兴趣的事物上。注意力机制将特征层的权重重新分配,待检测物体权重变大,背景权重变小。本文利用了通道域注意力机制,先对函数进行一个全局均值化,即把通道内的所有特征值相加再平均。公式如下:
(1)
式中:W、H分别代表feature map的宽和高,uc(i,j)表示feature map像素点的值。然后,利用两个全连接来训练通道间的相关性,第一个全连接把C通道压缩成C/r通道来降低计算量,后面跟RELU激活函数,第二个全连接恢复成C通道,后连Sigmoid激活函数。最后将经过Sigmoid函数产生的结果与原始特征进行点乘操作,增加待检测物体的权重。注意力结构示意如图1中注意力模块所示。
1.3 多尺度特种融合预测层
本网络结构采用的是多尺度融合的预测结构,所谓多尺度就是采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者池化来降低特征图大小,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标。利用上下层信息融合,预测的结构改变成dense的连接方式,该结构在大量减少需要学习的模型参数的同时,进一步提升模型性能。预测模块结构如图2所示。
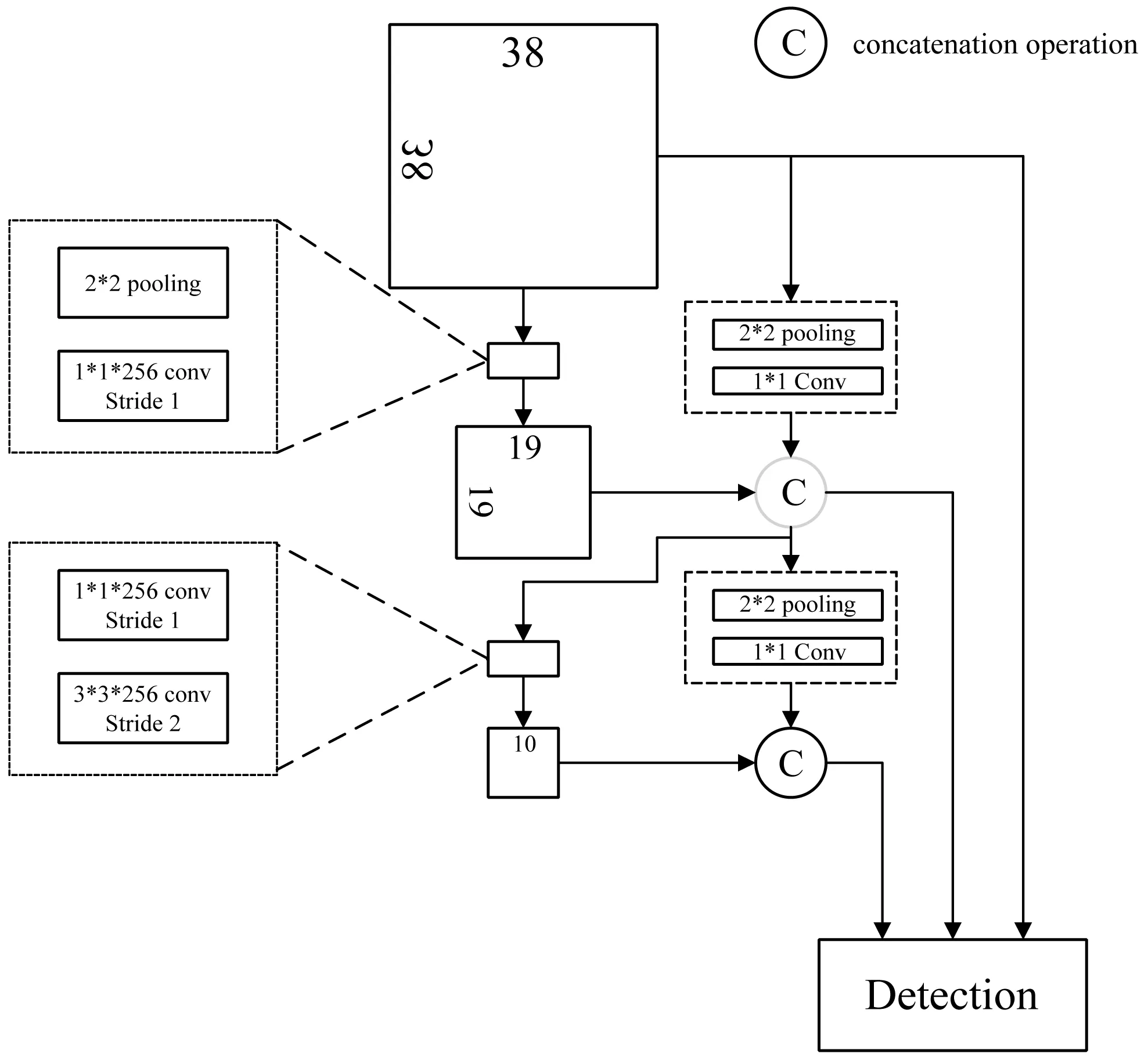
图2 预测层结构图
在脐橙数据集中,果梗、脐部在图片中的大小最大不超过图片的1/3,因此在多尺度检测中仅使用38×38、19×19、10×10的尺度足以检测物体,余下的尺度例如5×5、3×3、1×1对脐橙数据集是多余的。为了网络的时间效率,在不影响精度的前提下,本文仅采用三个较大尺度进行检测,用较大尺度feature map检测较小的物体。使用dense的形式从上到下融合相邻尺度,能够进一步利用参数,并且更好地利用上下信息。Down-sample结构是利用1×1卷积和3×3卷积,1×1卷积作用是维度缩小,减少计算量和参数量,设置stride=2的3×3卷积来降低特征图大小,利用组合操作,连接相邻feature map,在此组合的feature map上提取默认框进行训练。
1.4 Merge BN
BN层[11]是对数据进行归一化处理。对于每个隐层神经元,把逐渐在非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。BN层的使用给网络带来很大的益处,如网络收敛速度加快、开始学习率可以设置较大等。BN层处理的步骤如下所示:
(1) 计算一个mini-batch的均值:
2)模孔堵塞严重。发生模孔堵塞,与物料本身特性、调质质量、输送速度和模辊间隙等有关。模孔堵塞不但影响正常生产,降低生产率,还会影响成型颗粒质量,降低环模寿命。但是,目前如何很好地预防和及时处理模孔堵塞的问题还未得到解决。
(2)
(2) 计算一个mini-batch的方差:
(3)
(3) 利用均值以及方差对数据归一化:
(4)
(4) 利用自学习参数γ、β得到BN操作后的数据结果:
(5)
式中:B={x1,x2,…,xm}表示一个mini-batch的数据,yi是输出结果。
本文中所使用的深度学习框架如图1所示,每个卷积层基本与一个BN层相连,BN层使得训练过程中不用关注太多参数调整问题,并且数据的归一化带来了训练的速度增加,但是同样也带来了额外的参数以及多余的网络层数。因此,图像的检测时间会有所增加。本文采用Merge BN操作将BN层与卷积层合并,显著提升了图像检测的时间性能。根据式(4),可以反向推导BN层合并到原来卷积层权重和偏差的公式如下:
(6)
(7)
首先把卷积层权重以及BN层的参数读取出来,根据式(6)和式(7),将BN层参数汇合到卷积层中去;其次将模型结构中的BN层去掉,得到的新模型就是最终检测所需要的模型。
2 实验结果分析
2.1 实验环境与数据
实验的硬件环境为:CPU:56 Intel(R) Xeon(R) CPU E5-2683 v3@2.00 GHz;GPU:NVIDIA TITAN Xp,12 GB显存。软件环境为Ubuntu 16.04以及caffe框架。
本文采用深度学习物体检测方法检测果梗、脐部。目前没有相关的数据集是脐橙检测的,因此需要自己制作相关数据集的标注工作。本研究共标注19 760幅图片,按照随机交叉验证准则,30%作为测试集(共5 928幅),剩下的作为训练集。数据集标注借助开源标注工具LabelImage,直接生成类似于Pascal VOC数据集的标注结果,标注过程如图3所示。

图3 标注过程图
目前衡量检测问题的主要指标是mAP(mean Average Precision)和前向预测时间,本文主要从这两个指标衡量本文使用的模型与原始模型,在尽可能不损失精度的情况下,降低检测时间,能够正确实时检测脐橙的果梗、脐部。
2.2 脐橙数据集实验
采用本文网络结构进行参数训练,训练过程中学习率的设置非常重要,如果学习率过大,很容易导致误差震荡,无法收敛到全局最优值,如果学习率过小,网络收敛又很慢,并且容易收敛到局部最优值。在整个学习过程中,采用multi-step动态调整学习率大小的策略,开始的时候设置较大的学习率,在step为8 000、16 000的时候分别降低学习率,可以使得网络达到最优状态。
本网络采用脐橙数据集进行网络训练过程如图4所示。横轴表示的是训练迭代的次数,左边纵轴表示的是训练时的损失值,右边纵轴表示的是训练过程中验证集的平均正确率(mean Average Precision,mAP)。从图4可以看出在8 000、16 000处降低学习率时,损失有明显的下降趋势,在20 000迭代次数之前,网络收敛速度较快,测试的mAP也有明显的增加。在最后阶段loss和mAP趋于稳定,表示网络已经收敛到最优。在脐橙数据集上,mAP指标为90.6%。

图4 网络训练过程收敛曲线图
本文训练次数为30 000,在最优模型下测试前向时间为23 ms,经过merge BN操作后,前向测试时间为15 ms。本文基于SSD基本检测框架,借鉴使用DSOD网络的dense结构设计的模型结构。各网络对比结果如表2所示,本文方法与SSD与DSOD检测方法进行比较,所用的测试集是脐橙数据集,本文所采用的模型是在时间性能和准确度性能上都是最好的。由表2可知,注意力机制对准确度的提升有良好的效果。

表2 各网络对比结果
2.3 主观实验结果
图5为果梗、脐部检测效果,(a)、(b)、(c)三列图分别显示了使用本文改进的深度学习物体检测算法以及应用所建立的脐橙数据集对脐橙果梗、脐部以及各种瑕疵影响下的检测效果。从图中可以看出,在脐部与溃疡极度相似以及大脐部难以判别的情况下,依然可以准确地检测出果梗、脐部,本文的算法适用于脐橙的瑕疵检测系统。

(a) (b) (c)图5 果梗、脐部检测效果
3 结 语
在脐橙数据集中,本文网络结构加入注意力机制后,在保证实时的前提下依旧能够保证极高的精度,在时间以及精度上超过了SSD、DSOD模型。在加入Merge BN模型处理步骤后,进一步大幅度提高了时间,所以该结构能够满足脐橙的果梗、脐部检测的工作,从而进一步完成脐橙的瑕疵检测工作。但是目前本文所做的工作还有一些不足:所建立的脐橙数据集仅仅是脐橙的一个表面,在工业上一般是对脐橙整个表面进行检测,因此应用于工业还需要加入一些策略,所有表面形成一定的联系。
猜你喜欢
今日农业(2022年3期)2022-11-16
扬子江诗刊(2019年3期)2019-11-12
扬子江(2019年3期)2019-05-24
伴侣(2018年6期)2018-06-27
国外畜牧学·猪与禽(2018年4期)2018-05-14
天津诗人(2017年2期)2017-03-16
科普童话·百科探秘(2015年5期)2015-05-26
农产品市场周刊(2015年4期)2015-04-03
语文世界(小学版)(2013年8期)2013-08-26
保鲜与加工(2010年1期)2010-12-04
