
个性化高校新闻分类推荐的应用研究
2019-07-15 11:18毕曦文纪明宇段仁翀郭鹏鑫
计算机应用与软件 2019年7期
毕曦文 纪明宇 吴 鹏 方 静 段仁翀 郭鹏鑫
(东北林业大学信息与计算机工程学院 黑龙江 哈尔滨 150040)
0 引 言
近年来,网络技术迅猛发展,在中国互联网信息中心2018年8月发布的报告中显示:我国网民规模已达8.02亿,互联网普及率已达57.7%。在众多的网民当中,高达80%的用户均使用网上新闻资讯服务来满足获取新信息的需求。然而对于新闻信息,因其种类繁多且相应的信息获取平台缺乏高效、准确和智能的特性,用户难以快速捕捉到想要的内容,体验感较差。
为了提高网络信息浏览过程中的用户体验,数据挖掘技术被越来越多的专家学者们所研究。其中,聚类是数据挖掘技术中的一个重要分支。它是来满足用户要求的簇的集合,在没有任何先验知识的前提下,从海量数据中提取出未知但有价值的数据。早在1976年MacQueen就使用Epannechnikov核函数首次提出了K均值聚类算法(K-means算法)[1]。近年来,一些学者根据寻找最优初值的思想将卡斯克鲁尔算法、贪心算法等思想引入到K-means算法[2]中,一些改进的K-means算法又被应用到了公共推荐平台社区当中,也取得了一定的效果[3]。数据挖掘技术的另一重要分支是推荐技术,目前主要的个性化推荐算法包括基于内容的推荐、协同过滤推荐、基于知识的推荐、基于关联规则的推荐和混合推荐[4]等。其中基于内容的推荐算法是一个简单但十分重要的推荐思想。因为推荐效果受特征权重的选取方法影响明显[5],所以一些学者将项目语义应用于个性化推荐技术,亦取得了较好的成效[6]。最新还有一些研究如通过分析项目属性关系将项目粒度化,进而提出基于内容的加权粒度序列推荐算法等[7]。
本文主要针对聚类和推荐技术在新闻领域方面的应用来进行研究,结合K-means算法及混合推荐技术,改进已有的技术方法,以期望提高获取新闻时的准确性和时效性。
1 算法基础
1.1 原始的K-means聚类算法
K-means算法作为经典的聚类方法,由于可以快速计算以及拥有可靠的理论支撑等优点被应用在许多实践中[8]。
K-means的基本算法描述如下:首先从所有的数据集中随机选取K个对象作为初始的聚类中心。然后计算剩下的对象到这些聚类中心的距离(称之为欧氏距离),把每个对象分配给距离它最近的聚类中心。之后再选择每个新聚类的聚类中心,即计算该聚类中所有对象的均值,取该点作为新的聚类中心。然后不断重复这一过程,直到平方误差满足相应的精度为止[9]。
K-means算法的流程图如图1所示。
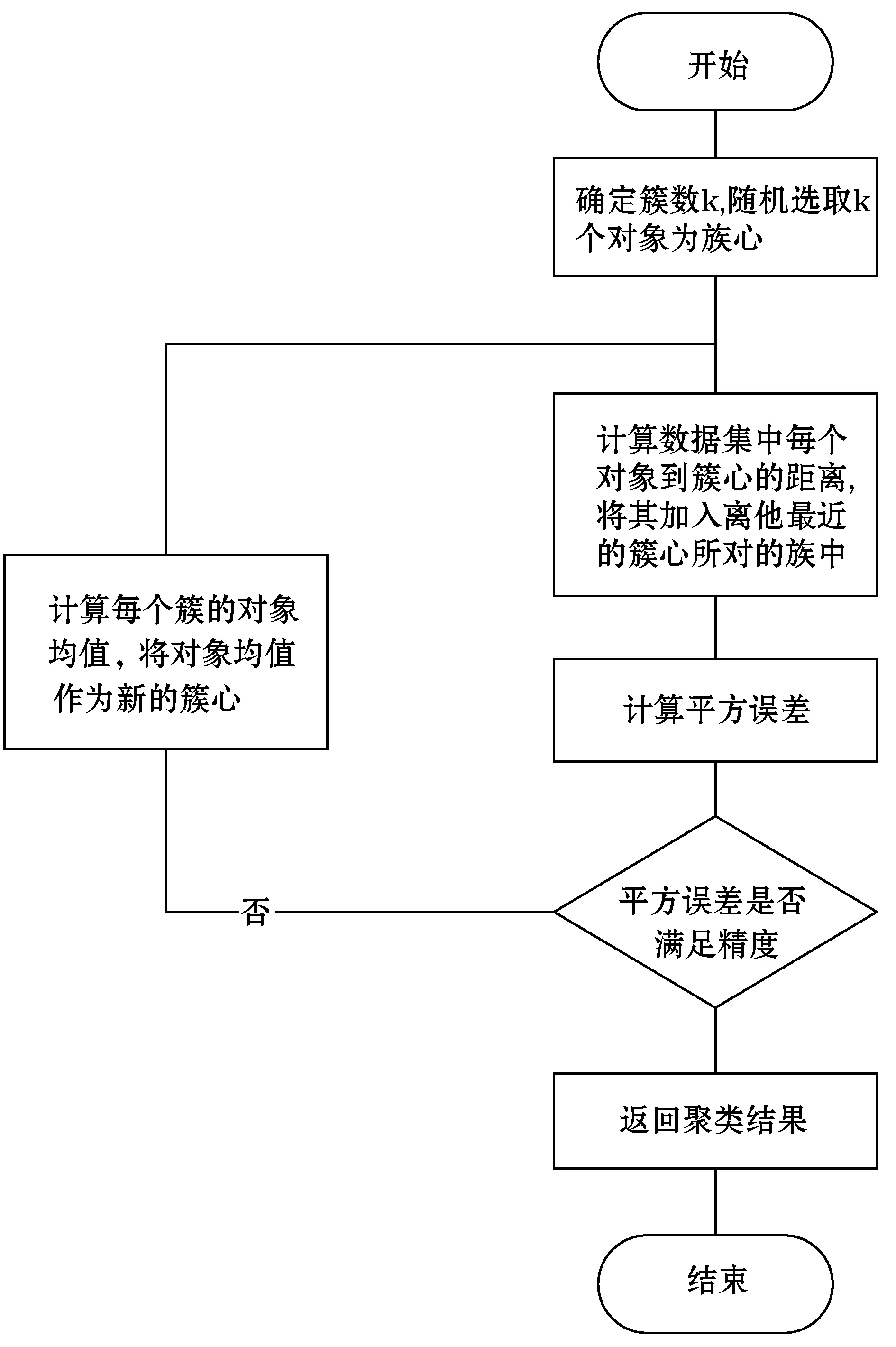
图1 K-means算法流程图
K-means算法也存在一定的局限性,它更适用于簇密集但簇与簇之间差异较大的数据,因此K-means算法对聚类数K的选取十分敏感。初始聚类中心的数量不同可能会导致产生不同的聚类结果[10],聚类的结果对K的依赖性也会导致聚类结果十分不稳定。针对这些问题,一些学者针对难以确定聚类中心数目进行了具体的研究[11],对数据进行了分割及合并处理,但并没有对K的取值作出深入讨论和验证,这一点将是本文主要的研究工作之一。
1.2 协同过滤与基于内容的推荐算法
协同过滤推荐技术是现阶段最为成功的推荐技术之一,它的基本原理是根据所有用户对物品或内容的偏好,来分辨出某类顾客可能感兴趣的东西。通过记录用户浏览信息以及用户对这些信息的评分,利用协同过滤的方法对用户喜好和文章内容建立模型,再将模型整合后对数据进行处理,进而拟合出协同过滤矩阵[12]。
另一种较为成功的推荐算法为基于内容的推荐,它根据用户过去喜欢的产品,为用户推荐符合他过去喜好的产品。该算法首先对数据内容进行整合,分析得到该产品的结构化描述。再利用过去用户喜好的物品特征数据学习出该用户的喜好特征画像,即用户模型。最后通过比较用户特征画像与候选物品的特征,进而为用户推荐出一组相关性最大的产品[13]。
基于内容的推荐算法工作流程如图2所示。

图2 基于内容的推荐算法流程图
协同过滤和基于内容的推荐技术已经广泛应用于很多领域,但它们都不能很好地解决新用户、物品的“冷启动”、用户关注度的变化、数据的稀疏性等系列问题,且随着用户数量和商品种类的增多,系统的性能将会变得越来越差[14]。在不断的研究过程中,有学者发现利用基于用户特征和商品特征的组合协同过滤算法,在改善相似度的研究中能够取得较好的应用效果[15]。下文将借鉴已有学者的工作,对原始的推荐聚类算法进行改进。
2 算法分析与改进
2.1 K-means算法的分析与改进
原始的K-means算法是随机输入聚类数K,由于一个文本中会有很多相近的词汇,那么一旦文本的类别数与K值不等,不同类别的文本就会被强行聚类到同一个簇中[16]。假设文本有7个类别,然而原始K-means算法将K设置为6,那么有1类将会被强行分散到这5个类别中,这样的聚类结果显然是不合理的。也有很多与K值的优化问题相关的研究工作,其中最常用的就是肘部法则,可以用它来估计聚类的数目,为K值的选取提供参照。
利用肘部法则来优化K值,是为了使成本函数的目标值最小化[17],其中成本函数是指各个类的畸变程度之和。该法则首先要画出不同K值的成本函数图像。由图像可以看出,随着K值的不断增大,每个类中所含有的样本数量会不断减少,样本离重心的距离会不断接近,平均畸变程度也会随之不断减小。然而若K值继续增大,平均畸变程度减小得将不再明显,改善效果会不断降低。在K值增大的过程中,成本函数下降幅度最大的位置就是“肘部”。从肘部法则的描述中可以发现,只有选取最佳的K值,才能避免算法陷入局部最优解[18]的问题。
2.2 内容和协同过滤组合推荐算法
通过分析、比较现有的多个推荐算法的优缺点,本文采用协同推荐与内容推荐合并的混合推荐方案,将两种推荐算法结合,从而满足对用户喜好的相关预测分析。
混合推荐算法流程图如图3所示。
图3 内容和协同过滤组合推荐算法流程
在上述流程中,本文采用下式来计算用户偏好的矩阵向量:

(1)
式中:u表示用户数量,r表示新闻阅读记录表,θ(j)表示用户j的新闻观看向量,xj表示i新闻的内容,y(i,j)表示j用户是否看过i新闻,n表示特征数量,m表示新闻数量。
基于式(1),得到文章的内容矩阵向量表示:
(2)
通过对式(2)的结果进行拟合计算和筛选排序,选出拟合度最高的K篇文章,同时搭配内容推荐系统对用户进行混合推荐。
对于用户需求信息的拟合,本文主要依靠代价函数来求出相似度,进而求出对于文章用户拟合效果比较好的x和θ,代价函数如下:
(3)
协同过滤的代价函数如下:
(4)
3 实验分析
3.1 实验准备
本文用于实验的硬件环境为Intel(R) Core(TM) i5-7200U CPU @ 2.50 GHz 2.70 GHz,内存为8 GB。软件环境包括操作系统为64位的deepin,编程软件为pycharm。实验所采用的数据为东北林业大学新闻网站上爬取到的数据。
3.2 评价指标
为了保证实验结果的准确性,我们选择F值作为评价指标[19]。F值定义如下:
(5)
式中:precision和recall分别为准确率和召回率,是广泛用于统计学分类领域和信息检索的两个度量值,可以用来对结果的质量进行评价。其中precision是检索出的相关文档数与检索文档总数的比率,即代表着检索系统的准确率;recall是指检索出的相关文档数和文档库中所有相关文档数的比率,即代表着检索系统的查全率。准确率和召回率的计算如下:
(6)
(7)
3.3 实验过程及结果分析
本文将实验数据分为5类,原始的K-means算法输入聚类数K的值为 4。我们利用肘部法则分析出的平均畸变程度与K值的关系图像如图4所示。通过对图中曲线分析可知,K=5时对应的平均畸变程度约为0.961,相对于其他K值,聚类数K的误差畸变程度减小,可以得到K=5是最佳分类数量。而在K=4时,很多数据被聚类到不正确的类簇中[20]。本文改进已有的聚类数4,把K值改进为5,提高了实验结果的准确性。
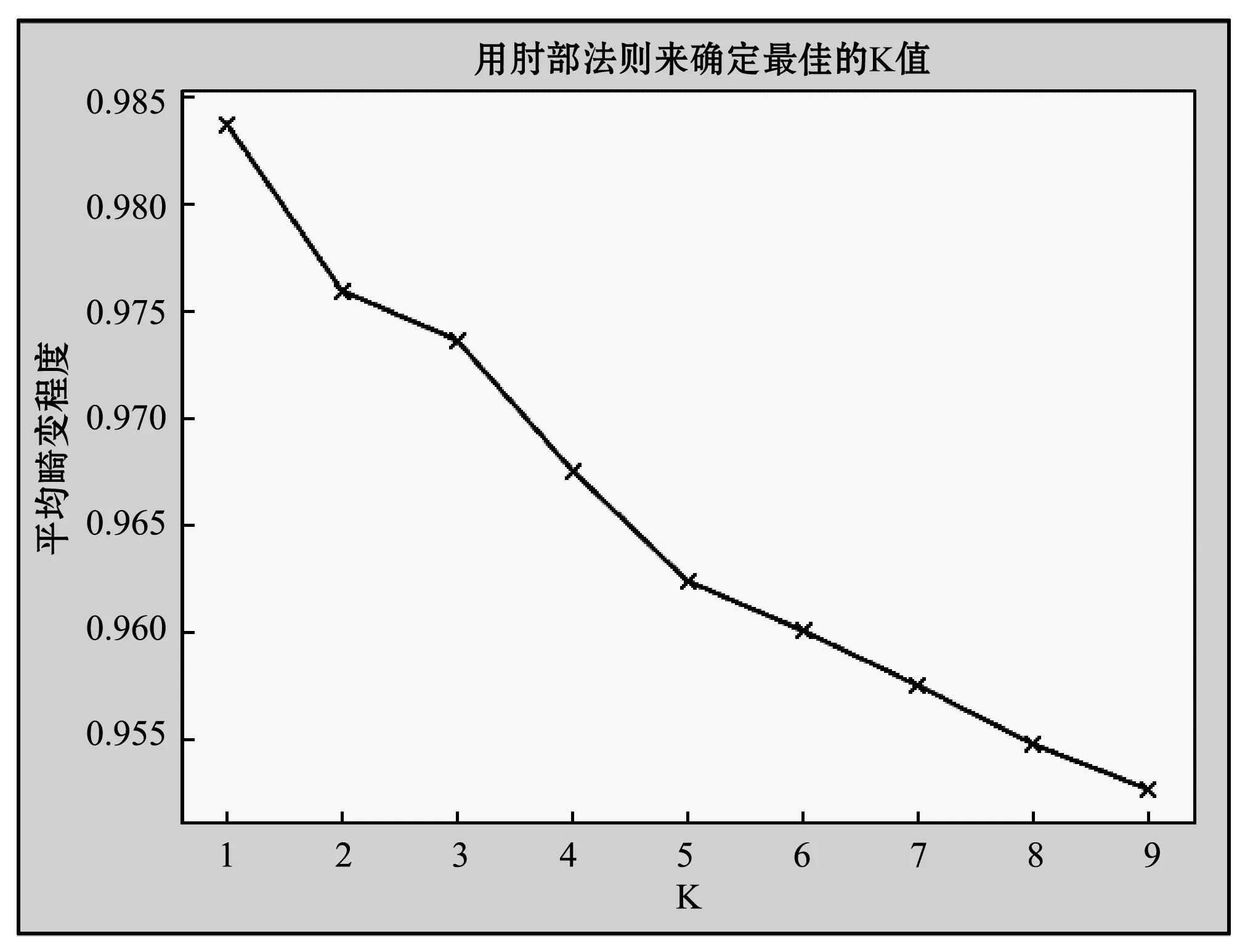
图4 平局畸变程度与K值关系图
在内容推荐方面,本文将纯粹的基于内容推荐和协同推荐方法与本文改进的方法在准确率方面进行了对比实验,关于准确率的对比实验结果分析如图5所示。
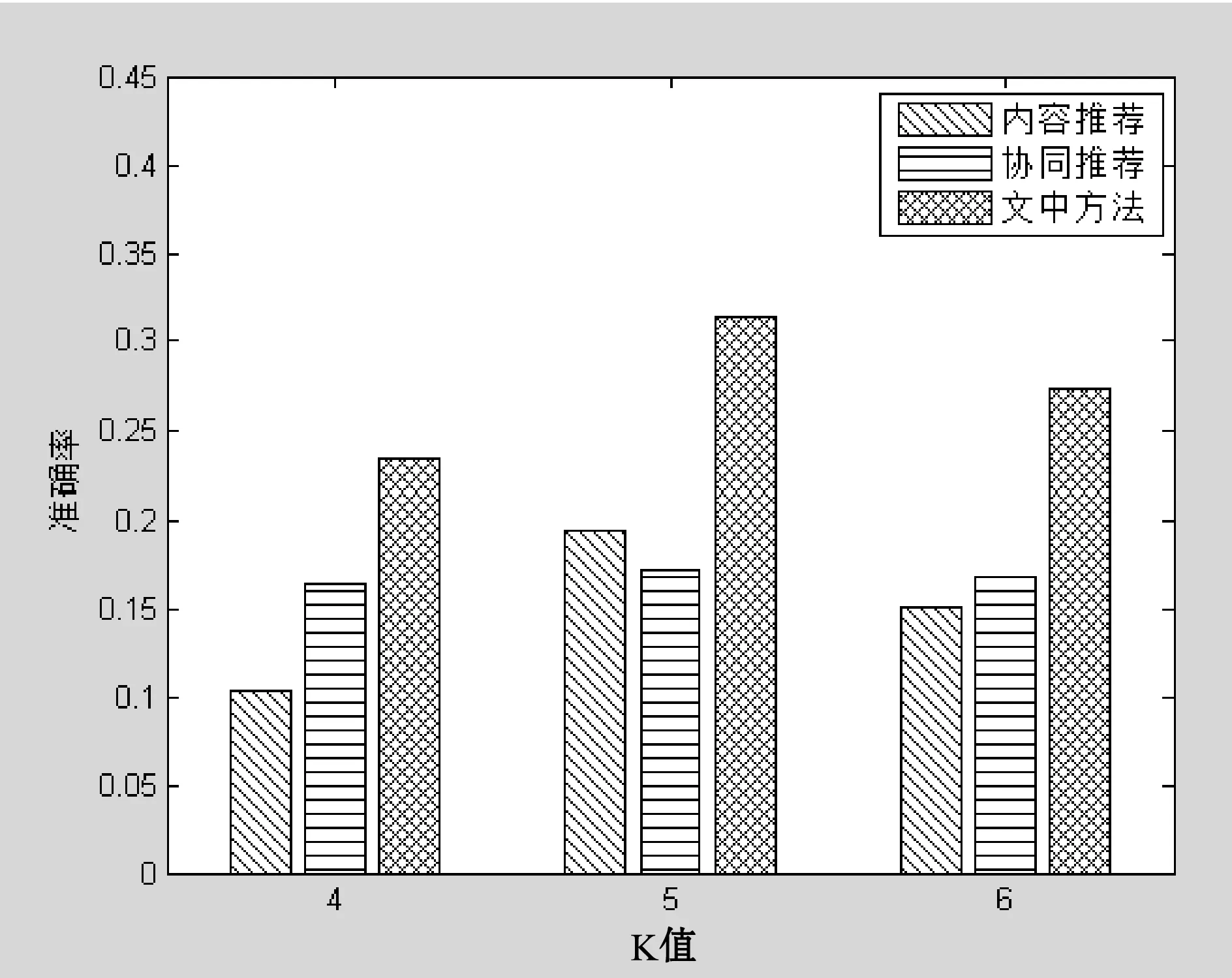
图5 准确率对比实验结果图
由图5可以看出,随着K值的变化,内容推荐和本文选取的推荐方法随K值影响较大,本文方法的准确率远远高于内容推荐算法和协同推荐算法。在K值等于5的情况下,本文的推荐算法准确率达到最高值约为0.32,内容过滤算法的准确率约为0.18,则本文的推荐算法比内容过滤算法高出约14%。在K等于5时本文的推荐算法准确率约为0.32,对比K为4、6时的0.24和0.27分别高约8%和5%。
4 系统实现
为了验证算法的有效性,本文利用Python语言,采用网络爬虫、改进的K-means算法、内容与协同过滤组合的推荐方法等技术,初步实现了一个面向个性化推荐的高校新闻分类推荐系统,系统主界面如图6所示。

图6 客户端系统操作界面
该系统可以使不同模块以动态持续更新的形式显示在主页最上端,能够根据用户的兴趣偏好,实时地推送给用户需要的高校新闻,提高新闻推荐的准确率和效率。个性化新闻推荐的具体展示页面如图7所示。
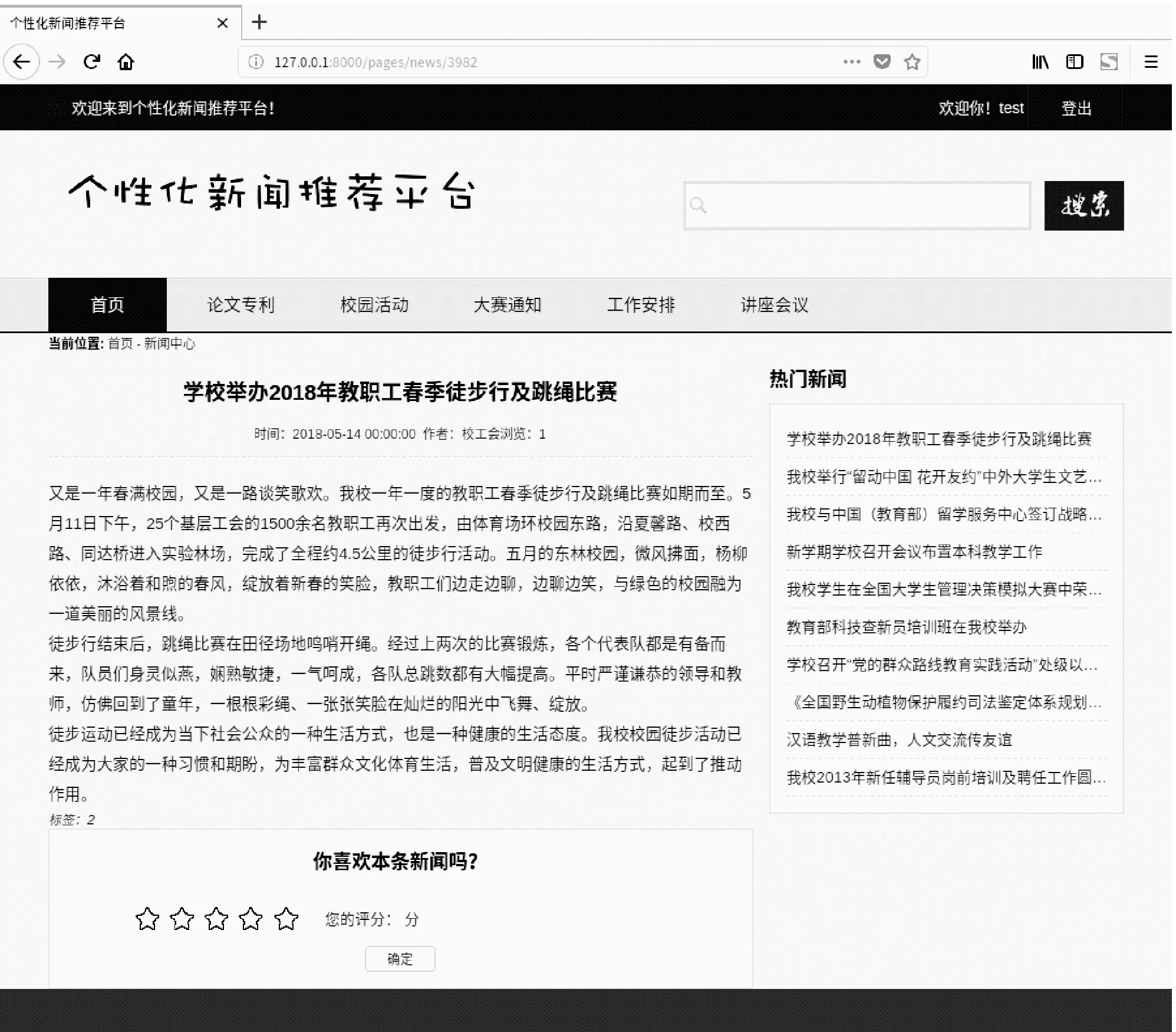
图7 个性化新闻推荐界面
5 结 语
本文提出了基于内容和基于协同过滤的一种全新的新闻混合推荐算法,通过与其他原始算法进行对比,验证了本文算法的有效性。与此同时,本文将相应的算法应用于校园新闻网站的个性化服务推荐系统当中,具有一定的实用价值。
例如在今后若运用到实际中,考虑到实时聚类推荐以及海量数据处理,将进一步优化处理模块。例如数据存储结构处理、预处理、聚类处理等方面,将采用Map-Reduce框架进行运算。
猜你喜欢
沈阳建筑大学学报(自然科学版)(2022年4期)2022-11-15
实验室研究与探索(2022年7期)2022-10-26
北京航空航天大学学报(2022年8期)2022-08-31
金属热处理(2022年3期)2022-04-09
计算机应用与软件(2021年7期)2021-07-16
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
健康体检与管理(2021年10期)2021-01-03
